背景
分散アーキテクチャにてデータをデータの側面での境界付けられたコンテキストである
データドメインごとに分割した後には、どのサービスがそのデータドメインを所有するか?
を考えないといけない。
これは分散アジャイル組織において、情報をどこに持たせるのがもっともベターか?
を考える際にも超重要になってくるので、組織設計を行う方とかは是非とも一度通っておくことをオススメします。
いきなり分散アジャイル組織をデザインするのではなく、
まずはどのチームにどのデータを所有させるとよりQCDを満たせる解として良いのか?を
考えられるので。
前提知識
データドメイン
端的に言うと、データの側面でのコンテキスト境界のこと。
トランザクション単位といったプロセスの側面から考えたうえで、
強い整合性の求められるような箇所(注文と注文明細とか)は、同じデータドメインにまとめるといったことを考えます。
このデータドメインは、データという側面からの考察だけでは十分に明らかになりません。
必ずトランザクションなどといったプロセスの側面とを行き来し、
データのコンテキスト境界を明らかにします。
概念スキーマで論理分割
データベースに詳しい方ならここはすっ飛ばしていただいて構いません。
今回扱うソリューションは、ソフトウェアアーキテクチャハードパーツにある代表的な解について、自分なりの見解を交えながら記載しますが、
いきなりサービスとして分割する前に、まずは物理的に1つのDBサーバーを基本として、
その中でデータのコンテキスト境界ごとに論理分割した上で、
各モジュールに所有権を割り振ったのちに、
「この境界の位置で物理的に切り分けて問題ない。切り分けた方がビジネス上の恩恵がデメリットより上回る」と判断した上で1つのサービス境界内に、サービスとデータをカプセル化してください。
情報エキスパート
この時、考え方の基本になるのは、GRASPの情報エキスパートパターンである。
テーブルに対して書き込みを行うサービスにその所有権を担わせる。
アナリシスパターン
また以下で出てくる共同所有におけるテーブル分割パターンでは、
アナリシスパターンで出てくる【知識レベルと操作レベルの分離】の思想が反映されている。
マスターデータである知識レベルが1つに対して、実体として手に取って扱える操作レベルの方が複数あるようなビジネス。
たとえば某ファストファッションビジネスなどで、各物理的な商品の方が、
どの顧客の手にわかっているのか?までシステムで管理したいスコープとする場合には、
操作レベルの方の商品を【在庫】と名前を表現して、
【商品】はマスターデータの方の知識レベルの方として表現することで、
マスターデータである商品の概念1つに対して、在庫は0以上であり、
在庫と顧客が注文などを通して関連づき、商品と顧客は紐づかないという概念モデルとして表現する。(以下の図を参照)
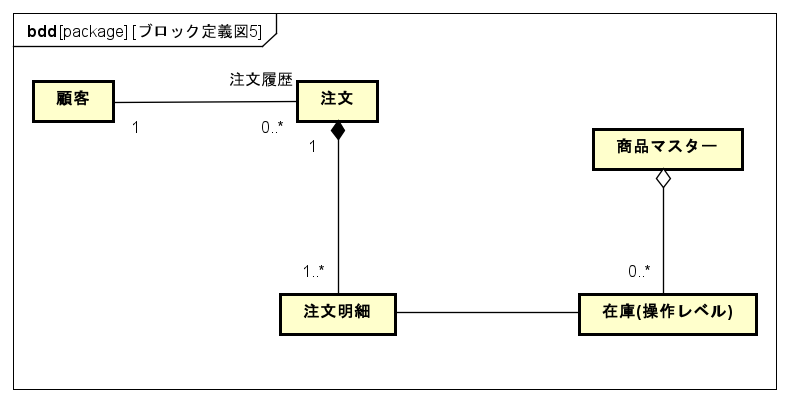
ただし、マスターデータである知識レベルが1つに対して、実体として手に取って扱える操作レベルの方が必ず0または1になるようなビジネスモデル。
たとえばオーダーメイドのようなビジネスなどでは、わざわざ知識と操作レベルの概念を分けるメリットはない。
諸注意
サービスを分割してからデータの所有権を考察するなんてことは絶対にしないでいただきたいです。
分散アーキテクチャにおける他のコンテキストへのデータアクセスやトランザクションの問題は相当やっかいです。
あらかじめ「もしも仮にサービスを物理的にも分割したら~」という仮定で、
嬉しいことと、それによって発生するデータの整合性リスクや、
所有権を適切なコンテキストに割り当てたとしても、その後に状況が変わって、
データの割当先を別のサービスコンテキストに変えた方がベターになる可能性だってあります。
それらの分割することによって発生する脅威を十分に考えたうえで、
それでもマイクロサービスとして切り分けた方が、ビジネス上恩恵があると判定された場合にのみ、最もリスクが低くて可逆性を担保できる場所から切り分けるというように考えます。
上記で書いたように、まずはモジュラーモノリス構造にて、
概念スキーマによってデータ群を論理分割し、各スキーマ内のデータドメインを
各モジュールに所有権を割り当てというようにすることを目指しましょう。
どのモジュールが概念スキーマによって分割されたどのデータドメインを所有すると思われるのか?は、チーム内で共通認識が持てるように、しておきましょう。
所有の仕方
所有の仕方には大きく分けて3種類存在する。
根底は情報エキスパートの考えだが、それだけでは全体所有や共同所有には対処しきれない。
まずは3つのそれぞれの概要について。
単独所有
下図のように
サービスAはテーブルXに対してのみ書き込みを行い、
サービスBはテーブルYに対してのみ書き込みを行い、
サービスCはテーブルZに対してのみ書き込みを行うという場合。

つまり1つのテーブルに対して、1つのサービスしか書き込みをしないという場合。
この場合には非常にシンプルである。
以下のように境界を定義し、カプセル化する。

まずはこの単独所有ができないか?を考える。
それができなかった時に、次の全体か共同所有を考えるようにする。
全体所有
1つのテーブルに対して、ほとんど(またはすべて)のサービスから書き込みが起きる際には、
全体共有が生じる。
問題点
数十、数百以上のサービスが1つのテーブルに対して書き込みを行う場合、
せっかくデータドメインごとに分割したのにもかかわらず、
データドメインごとに分割する前の問題点であった
・変更の制御
・データベースへのコネクション枯渇
・スケーラビリティ
・耐障害性
のすべての問題が再発してしまう。
ソリューション
たとえば以下のような図において、テーブルXは既存のすべてのサービスから書き込みをされているとする。
この程度のサービス数であれば問題ないかもしれないが、
実際問題これがより大量の数十などのサービスから書き込みをされていたとしたら、
今のままでは上記のような運用特性上の問題が起きてしまう。
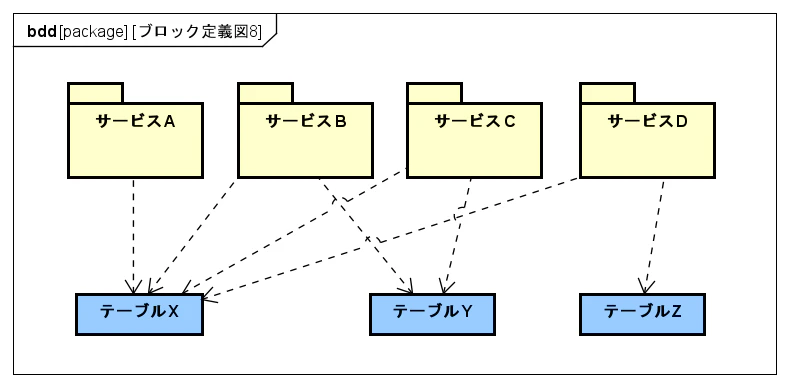
そこで以下のように、テーブルX専用の所有者であるサービスを設けて、
他のサービスAやBなどがテーブルXに書き込みを行いたい時には、
そのサービスに情報を送信して、Xの所有者(図のX所有サービス)自体が書き込みを行う。

図には描いていないが、永続的なキューを使用してメッセージを送る。
そうすればメッセージ送る先とかに障害が起きたとしても送りたい情報は失われないことを保証できる。
共同所有
上記のすべてやほとんどのサービスがテーブルを所有するのではなく、
一部の複数のサービスが同じテーブルに対して書き込みを行う場合にこの共同所有がある。
この共同所有には、いくつかのパターンにわかれる。
ただし、その中でデータドメインパターンについては、
マイクロサービスとは言えないアーキテクチャスタイルに感じるため、
個人的にはあまりオススメできない。
テーブル分割パターン
書籍に書かれたパターンは、商品のマスタと、在庫概念に分割しているため、
アナリシスパターンの知識レベルと操作レベルの分割に近しい考え方である。
知識と操作の分離とは、たとえば対象のビジネスにおいて、
商品のマスターデータに関するものと、手に取れる物理的な商品とを分けて考えたいという場合に、概念モデル上でも分離して考えることである。
マイクロサービスでいうと以下の図のように
知識レベルの方の商品のコンテキスト境界である【カタログサービス】
操作レベルである方の商品コンテキスト境界である【在庫サービス】
もともと1つであった商品テーブルをこれら2つに分割することで対応する。
そうすることで、共同所有であった状態から単独所有にできる。
ただし、この場合には知識レベルの商品側と操作レベルの方の商品との間で、削除や更新時のデータの整合性などの問題点がどうしても避けられない。
また、データモデリング上で1つのテーブルに対して、
知識と操作が混在しているように、2つ以上のコンテキストが混ざっている
と言えるような時にしか有効とは言えない。
メリット
データの単独所有
なんといっても単独所有にできるので、非常にシンプルになることだ。
耐障害性
後続のサービスコンソリデーションパターンなどに比べて、ダウンしたりするリスクも低い。
境界付けられたコンテキスト維持
分割したテーブル間に強い整合性が求められないケースにおいては、
コンテキスト境界の維持、およびそのサービスを運用するチームにとって、
認知負荷が高まりにくい状態をキープできる。
デメリット
このパターンで非常に重要になってくるのは、分散アーキテクチャを選んだ場合に、
可用性と整合性の両方を取ることはできないということだ。(∵CAP定理)
ビジネスモデル上の品質として、どちらがエンドユーザーにとって嬉しいのか?
を選ばなくてはならない。
データドメインパターン
このパターンはマイクロサービスとはまだ言える状態ではない。
マイクロサービスにおける1つの境界付けられたコンテキスト内には、
オブジェクト指向のカプセル化と一緒の考え方で、
テーブルとそれに対する書き込みをするサービスプロセスをまとめ、
他コンテキストからのテーブルへの直接アクセスを禁止(データ隠蔽)すること。
事実
これに対して、データドメインパターンはマイクロサービスの量子としては、まだ未完成状態である。
テーブルしかないデータドメインのみを1つのコンテキスト境界内に定義しているからだ。
主張
よって、まだどのサービスにテーブルの所有権を持たせるのかがまだ不明といった場合に、
一時的にこのパターンを適用する際には構わないと感じている。
チームトポロジー書籍の物理本、P.89に「チームをまたぐ重要な情報を視える化することは~」という一文がまさにこのデータドメインパターンの組織構造を指していると思われる。
余談ではあるが、自分は案件の中でこのパターンのアーキテクチャを見たことがある。
それは超大規模エンタープライズであり、
あるビジネスプロセス群を管理する組織と、別のビジネスプロセス群を管理する組織が分かれていた。そしてデータ基盤をマネジメントする組織はまた別に存在していた。
ただし個人的には、サービスとして分割する前に、
上図でいうとカタログモジュールと、在庫モジュールに論理分割しておいて、
それらを含む1段階マクロなコンポーネントとして、商品サービスを定義し、
その内部に商品テーブルを持つというようにする方がベターと感じる。
この場合、在庫とカタログに関する計2つの責務が商品サービスには存在することになるが、そのデメリットを覆うだけの利点の方が上回る。
メリット
まず、「どちらがデータの所有者か決定しきれない。」という時であり、
しかも
デメリット
下図をご覧いただければお分かりかと思いますが、データスキーマが変更されたら
それに伴ってそれを使用するサービス側への変更時の問題である。
①データスキーマの変更によるサービス数の増加
境界を飛び越えての変更の波紋が伴うことから、
そのテーブルを使用するサービスをすべてマネジメントできていないと、
どれかのサービスが落ちるなどの問題が起こる。
なので、対象のデータドメインを使うサービス数が数個であればまだいいが、
数十とかってなってくるとどれか考慮漏れが起きたりしかねない。
②データスキーマの変更によるテスト範囲の増加
データスキーマが変更されたら、当然それを使用するサービスプロセス側もすべてテストし直す必要がある。
サービスが数個ならまだかわいい方だが、これが数十とかになってくると、
テストコストは絶望的に高くなることは定性的にも容易に想像がつく。
③ データ書き込み権限の統制を取るのがめんどう
サービスを開発する側からすると、
密なコミュニケーションがないと、「あ!ちょうどあのデータ使いたかったんだよラッキー」みたいなことが起こりかねないので、書き込みを行える制限をかけないととんでもないことになるのは自明である。
④データスキーマの変更によるデプロイコストの増加
データドメインの量子と、それを使うサービス量子のすべてで実質1つのデプロイ量子
であることから、その範囲が高くつきやすい。
そもそも境界付けられたコンテキストの範囲を超えてのデプロイを強いられるのが
個人的にはこのパターンが嫌いな理由の1つである。(完全に私個人の主観)
ネタバレ -データ基盤でよく見かけるパターン-
実は、このパターン、意外とよく使われているんです。
どこでかというと、アプリケーションが仮にマイクロサービス化されていても、
データ基盤まで分散化していないケースってありますよね?
下図のようになっているケース。
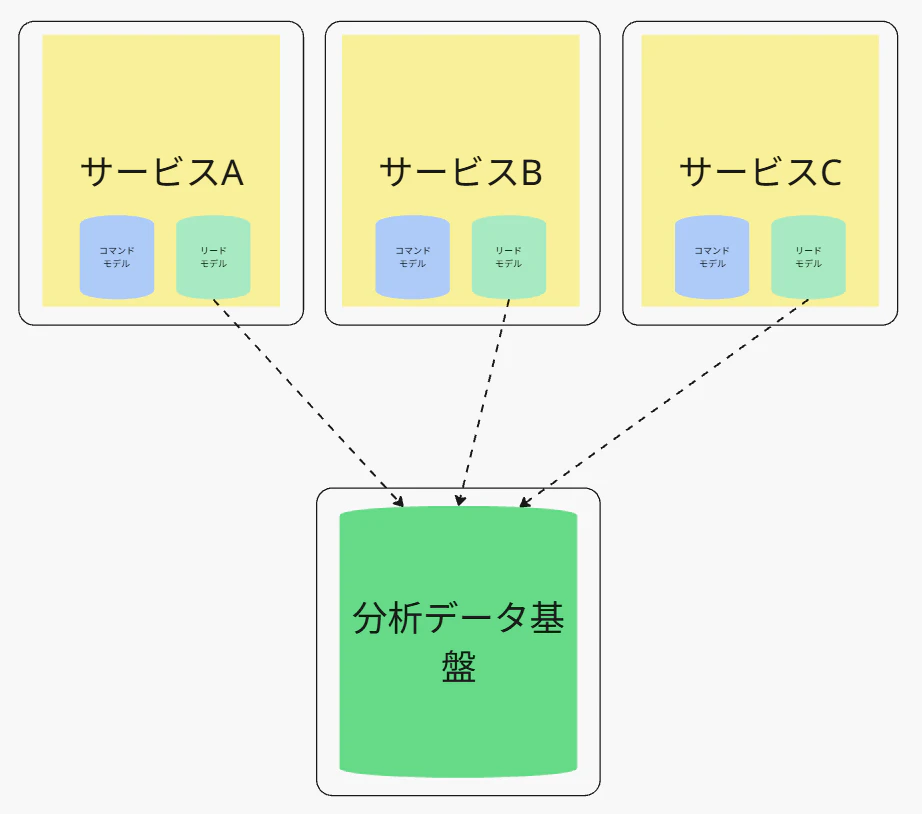
そう、各マイクロサービスは確かに分散化しているものの、
図のように、データ基盤までスコープを広げたら、まさにデータドメインです。
これもまさに、データ基盤の提供する
データプロダクトの所有権がどのマイクロサービスに割り当てられるのか?
がまだ不透明な時に、それでも各種サービスのデリバリー速度を維持したいとき、
一定期間このスタイルを取るというのは、非常に理にかなっています。
委譲パターン
これは代表のようなサービスがテーブルを単独所有し、
他のサービスからの更新は、その所有者に更新処理を送って代行するという思想である。
しかし、どのサービスを所有者とするのか?という課題がある。
メリット
テーブルの単独所有が可能
これも先ほどのデータ分割と一緒で、テーブルの単独所有権を実現できるのが最大のメリットである。
デメリット
①サービス間結合が密である
サービスコンソリデーションパターン
これは複数のテーブルの所有者サービスを1つに統合してしまおうという思想である。
つまり、意図的に荒い粒度のサービスにすることによって、単独所有にするということ。
一応単独所有にはなるものの、サービスの粒度感が大きくなってしまうことで、
他のマイクロサービスとの粒度不揃いや、デプロイ時のリスク問題などの問題が出てくる。
メリット
アトミックである
物理的に1つのサービスとしてまとまるので、アトミックトランザクションを維持できる。
強い整合性を必要とする場合には、この恩恵を受ける。
パフォーマンス性が高い
サービスが分かれている時に比べて、1つにまとめっている方がパフォーマンスが高いのは言うまでもない。
デメリット
認知負荷が高まる
もともとロジックとしてはわかれていたものを1つにまとめるので、
チートポ的にいうと、管理するチーム全体の認知負荷量が高まる。
テストコストの増加
図形的に見て自明なように、まとまることによってテスト範囲がその分広がる。
デプロイリスクが上がってしまう
テスト範囲の広がりに伴い、全体をデプロイする際のリスクが高くなってしまう。
耐障害性が低下
1つにまとまることによって、まとめた部分が一緒にダウンすることになるので、
まとめる前に比べて、それぞれの耐障害性は相対的に下がる。
対象コンテキスト内のDBに対して、単純計算でまとめる前に比べて倍のアクセスがなされるのだから、DBアクセスが集中してダウンするという可能性も高まってしまう
スケーラビリティの柔軟さ低下
もともと別々であったサービスを1つにまとめるのだから、必然的にそれら全体的にスケーリングすることになる。
一部分だけをスケールというように柔軟にはいかなくなる。
補足事項
最後にUAFと絡めた補足事項を記載しておきます。
今回扱ったデータの所有権は、ServicesビューにおけるInformation列の定義に役立ちます。

逆コンウェイ的にAA層で考えたデータのコンテキスト境界やデータの所有権の割り当てを
DA層やBA層に反映させるのです。
その際にUAFグリッドで十分に定義しきれていなかった、
Servicesビューにおける各サービスに対するデータの所有権をInformationビューに更新します。