分散アーキテクチャにおける現代のトレードオフ分析と今後のソフトウェアアーキテクチャの展望
概要
アーキテクチャメトリクスの話はほぼなく、ハードパーツの話がメインで取り上げられていました。
複数のシナリオを想定し、モノリスのままでいるのか?
それともマイクロサービスにするのか?
マイクロサービスにしたとしてもどのような粒度感で分割するのか?
について、書籍の内容のざっくりした考え方についてお話しされていました。
分割の粒度感
マイクロサービスは、DDDでもよく語られている【境界付けられたコンテキスト】の考え方
を用いて、その境界内でトランザクションの範囲が完了することや、
変更頻度・変更理由がそのサービス内のものに関しては同じであるという
コンポーネントの凝集原則の1つ、CCPを意識した考え方をベースとして分けたくなる。
要はサービス粒度での単一責務てやつだ。
高度に物理的に分割され、疎結合を満たすことによって、スケーラビリティやアジリティを高めることができる。
しかしながら、それ以外の品質特性軸によるビジネスドライバによって、安易に単一責務のその単位で分けると判断してはならない。
繰り返し述べられていたこと
トレードオフ分析は継続的に行うものであるという、至極当たり前なことだけど、
難しいことを述べていました。
これはつまり、環境変化などによって、トレードオフ要素間の重みの比重が変化するからです。

ある瞬間上図のように、品質特性A(天秤の左側)、B(天秤の右側)の重みが定義されていたとする。
しかしそれは時間経過に伴うステークホルダーの要求の変化や、市場の変化などによって
天秤の傾き具合が変化してしまいます。
それを事実データを使ったりして、客観的にいまどのくらいのトレードオフ関係なのか?
それとも抜本的技術が登場したことによって、トレードオフ関係が解消されたのか?
などを継続的にモニタリングしろ、ということになります。
同時にそれは、大前提であるステークホルダーの要求の変化や関心の強さの変化にも
目を光らせなくてはなりません。
落とし穴
本にあるいくつかの非機能項目での評価マトリクスにおいて、
たとえば【セキュリティ】【パフォーマンス】などが重要な特性であり、
その軸でアーキテクチャを評価しなくてはならないとした場合に、
〇△×という3種類の定性評価だけでは、間違った意思決定になるということ。
なぜなら2つの特性の重みが同じである保証はないからである。
下図はハードパーツにおいて取り上げられていた、
再利用パターンのうち、共有ライブラリを使って静的な結合にするケースか、
共有サービスとして分離した上であとから動的に通信で結合させるケースを
7つの評価軸で比較検討している様子である。
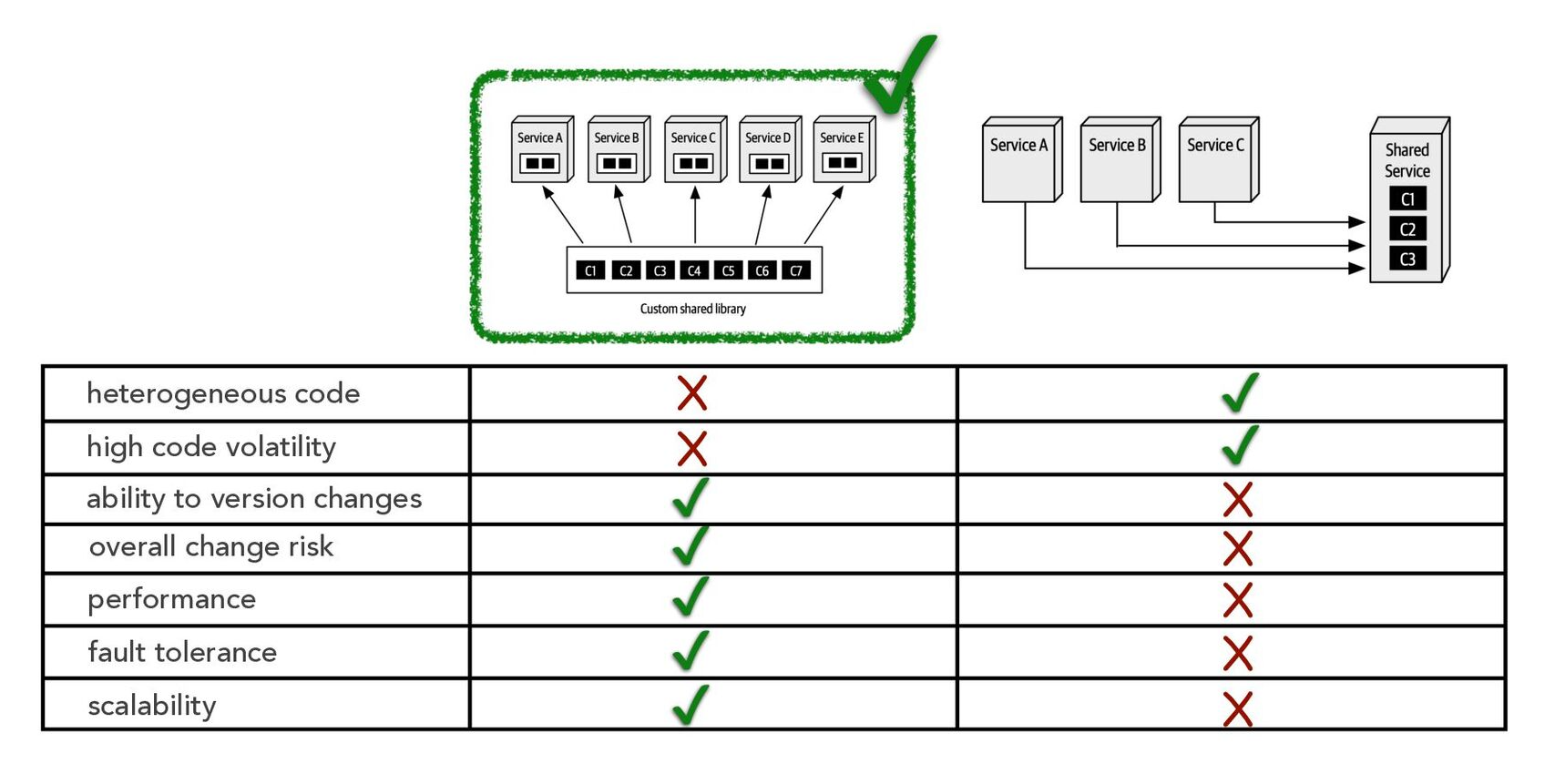
たとえばわかりやすくするために、10段階の定性的な重みのうち、
めちゃくちゃ強く求められる特性であるほど10に近づくという場合を想定し、
セキュリティが10、パフォーマンスが4程度であったとする。
この場合、明らかにセキュリティの方が比重が重いため、
単純な〇△×という3種類の定性評価だけでなく、重みも意識した評価が必要。
たとえば重みポイントが10で〇なら、10×3で30 の評価ポイント
重みポイントが5で△なら、5×2 で10 の評価ポイント
といったようにしなくてはならない。
必ずしもこの計算方法が絶対的ではないので、そこだけ注意。
所感
今回のテーマであるハードパーツの書籍を私はグループディスカッション形式に
計3回ほど行ったことがあるが、何度読んでも前提となるステークホルダーマネジメント
をアーキテクト自身が行い、アーキテクチャを決める品質の軸の優先度がわかっている
必要があると感じています。
匠メソッドによるプラスの価値の考察と、脅威モデリングによるマイナスからの
両方による考察が必要であると感じます。
組織を支えるアーキテクチャの過去と未来
背景説明
登壇者の方の組織では、4年前に1チーム5名であった状態から、
今にかけて直線的に組織の人数とそれに伴うチーム数が増加したらしい。
図
組織の拡大に伴って、生産性を下げないようにするために、
またアーキテクチャの方針として、チームごとのマイクロサービスに分割することで、
各チームごとに素早く自律分散して開発ができるようにしたそう。
本来は、初期からのマイクロサービスに分割するのは、
アンチパターンとされているが、たまたま条件がそろって、初期からマイクロサービスで割と成功を収めた事例としてのお話であった。
設計方針
業務ドメインごとにサービスを分割し、マイクロサービスごとにデータも分割。
主要なマイクロサービスに対しては、同期的な通信による蜜結合状態を避け、
非同期通信による疎結合の徹底。
フロントエンドからは、BFFを経由してのアクセス。
当初のアーキテクチャと現在の比較
共有ライブラリを作成せずに、あえてサービス間でコードを重複しても、
DRY原則に反していてもいいとする方針であった。
重複コード部分を共有ライブラリに分けることによって、
不要な結合を排除して、サービスごとのコンテキスト境界 独立性を重視したかった
ために、あえてそのような設計にしたそう。
このあたりのお話は、以下の共有ライブラリのパターンに参考情報があります。
しかしながら、現在は共有ライブラリパターンを適用しているとのこと。
というのも、重複コード部分において、データベース周りやWeBフレームワーク、ユーティリティなどなど、共通で使いまわしたいものが固まってきたからだそう。
恐らく共有サービスパターンを使用しなかったのは、
動的に連携した際に、ランタイムエラーが起きる可能性が読めないことなどの
懸念事項が背後にあったからだと思われる。
感想
そもそもチームの境界を正しく発見するためには、
データのプロセスの両方の側面からLeSS的な組織一致団結活動によるモデリングによって
チームの責任境界などを継続的に議論しないと無理ゲーではと感じた。
ただし、BFFやら非同期通信を基本とした設計によって、疎結合を徹底されているのには非常に感心をしました。