3つの推論による学習ループ
アーキテクチャをデータ駆動で科学的に改善していくための、学習サイクルとして、
以下のようなものを以前から考えてみていた。
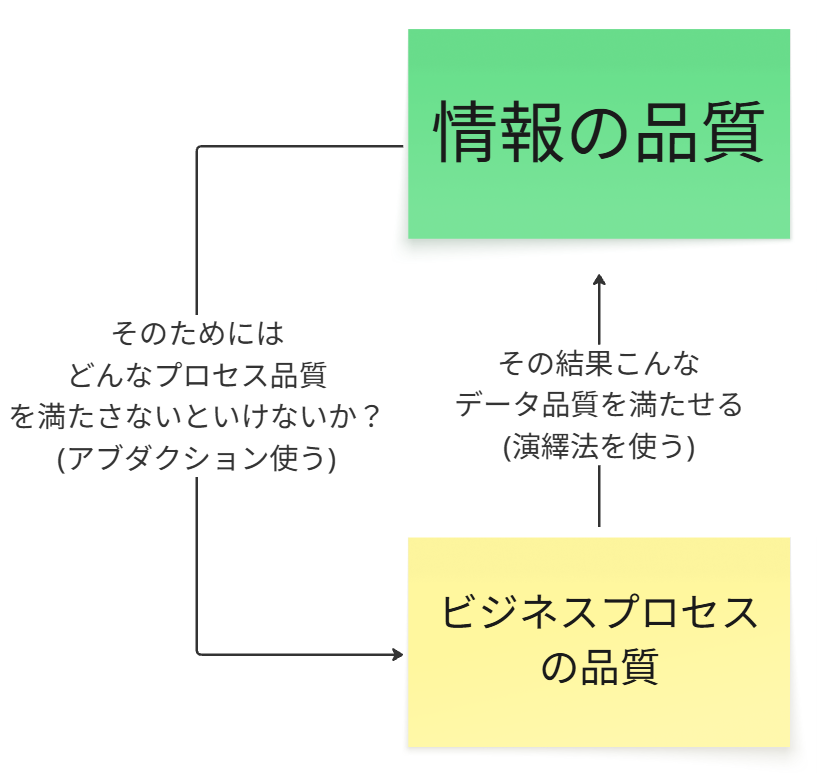
1. 演繹法:予測
役割
一般的なルール(あるいは設計上の仮説)から、具体的な結果を予測します。
思考
「このプロセスのレイテンシーを100ms未満にすれば(ルール)、データの鮮度は1秒未満になるはずだ(予測)」
2. アブダクション:仮説形成
役割
観測された結果(特に予測と反したもの)を、最もよく説明できる仮説を形成します。
思考
「データの鮮度が目標に達しない(結果)。
おそらく、プロセス品質としてレイテンシーだけでなく、スループットも満たす必要があるのではないか?(仮説)」
3. 帰納法:法則化
役割
複数の具体的な実験結果から、一般的なルールやパターンを導き出します。
思考
「レイテンシー改善の実験を5回行ったが、いずれもスループットも同時に改善しないと、データの鮮度は目標に達しなかった(複数の事実)。
どうやら、このシステムでは、データの鮮度はレイテンシーとスループットの両方に依存するらしい(新しいルール)」
この新しいルールが、次の演繹的予測のインプットとなり、サイクルが回り続けるって考えます。
Geminiに聞いてみたデータ品質とプロセス品質の代表的な関係性
いちいちググるのはめんどかったので、Geminiに
「一般的なデータ品質とプロセス品質の間の関係性をいくつか可視化してみて。さらにその理由も込みで。」と聞いてみました。
その結果を以下に貼っておきます。
1. プロセスの「低レイテンシー」 ⇔ データの「高い鮮度」
関係性
プロセスの処理時間が短ければ短いほど、データの鮮度は高くなります。
理由
データの鮮度とは、事象が発生してから、そのデータが利用可能になるまでの時間差です。この時間差の大部分は、データを処理するプロセスのレイテンシーによって決まります。
具体例
リアルタイムの不正利用検知システムでは、決済トランザクションを処理するプロセスのレイテンシーが極めて低くなければ、検知に必要なデータの鮮度を保てません。
2. プロセスの「高スループット」 ⇔ データの「高い完全性」
関係性
プロセスが単位時間あたりに処理できるデータ量が多ければ多いほど、データの欠損が起こりにくくなり、完全性が高まります。
理由
データパイプラインの処理能力(スループット)が、流入してくるデータの量を下回っている場合、処理しきれないデータは破棄(ドロップ)されるか、あるいは処理が大幅に遅延し、結果としてデータの完全性を損ないます。
具体例
IoTデバイスから毎秒数千件のデータが送られてくるパイプラインでは、高いスループットを維持できないと、データ欠損が多発します。
3. プロセスの「高可用性」 ⇔ データの「結果整合性」
関係性
プロセスの可用性を高める設計(冗長化、非同期化)は、多くの場合、データの即時的な一貫性を犠牲にし、結果整合性を採用することに繋がります。
理由
高可用性を実現するためにメッセージキューなどを導入すると、書き込み処理と読み込み処理の間に時間差が生まれます。この時間差が、結果整合性の本質です。
具体例
マイクロサービスアーキテクチャで、サービス間の通信にメッセージキューを挟むことで、片方のサービスが停止しても全体が停止しない(高可用性)ようになりますが、データがキューイングされている間は、システム全体で見てデータは即時には一貫しません。
4. プロセスの「低エラーレート」 ⇔ データの「高い正確性」
関係性
プロセスが処理を失敗する確率が低ければ低いほど、生成されるデータの正確性は高まります。
理由
これは最も直接的な関係です。データ変換ロジックのバグや、バリデーションの失敗といったプロセス上のエラーは、そのまま不正確なデータの生成に直結します。
具体例
売上集計バッチの通貨換算ロジックにバグがあれば、生成される売上レポートのデータの正確性は完全に失われます。
ツールを用いた推論サイクル
しかしながら、手作業でそのデータ品質とプロセス品質とを関連づける作業は、あまりにも骨が折れる💦
そこで、
データの品質を提供してくれるデータオブザーバビリティと、
サービスメッシュ / イベントソーシングの提供するプロセス品質とを関連付ける作業を自動化したら、かなりのスピードと精度でデータ駆動が実現できるのでは?
と考えました。
データオブザーバビリティ:「データの品質」という結果を客観的に観測。
サービスメッシュ / イベントソーシング:「プロセスの品質」という原因を制御・観測。
こいつらの組み合わせによって、データ品質(What)とプロセス品質(How) を双方向で結びつけ、継続的に改善していくための、推論モデル(学習ループ) が完成します。
具体例
①. 観測 (データ品質)
データオブザーバビリティが「顧客データの鮮度がSLO目標を超えて悪化した」と報告。
②. アブダクション (仮説形成)
「おそらく、プロセス品質に問題がある。
顧客データを生成するマイクロサービスのレイテンシーが増大しているのではないか?」
と仮説を立てる。
③. 検証 (プロセス品質)
オブザーバビリティツール(サービスメッシュのトレースなど)で、仮説通りに特定のサービスのレイテンシーが悪化していることを確認。
④. 改善
そのサービスを改善する。
⑤. 演繹 (予測)
「レイテンシーを改善したので、データの鮮度は目標値内に戻るはずだ」と予測。
⑥. 観測 (データ品質)
データオブザーバビリティで、鮮度が目標値に戻ったことを確認。
⑦. 帰納 (法則化)
「このシステムのデータ鮮度は、サービスXのレイテンシーに強く依存する」という新たな法則を得る。
このループこそが、データ駆動型アーキテクチャ運用の核心であり、
データプロダクトへのカオス実験と組み合わせることで、信頼性の高い分析データを持ってして意思決定がしやすくなる。