前置き
コマンドモデルとリードモデルが、
①. 論理的にすら分離できていない泥団子状態の時。
②. 論理的には概念スキーマで、コマンドモデルとリードモデルが分離できているが、物理的には1つのDBを共有している、いわばデータに対するモジュラーモノリス状態。
③. 物理的にもコマンドとリードモデルは別のDBになっているが、連携は同期通信である、結果整合かつ同期連携の状態。
④. コマンドとリードが、別DBでありかつ非同期通信であるが、同じインフラ基盤を共有している状態。(コマンド側からのイベントメッセージによりリードモデルに更新されるイベント駆動型)
⑤. さらに分離が進み、コマンドとリードがインフラ基盤さえも分離された状態。
この①~⑤のそれぞれの状態におけるメリットとデメリットを考えてみましょう。
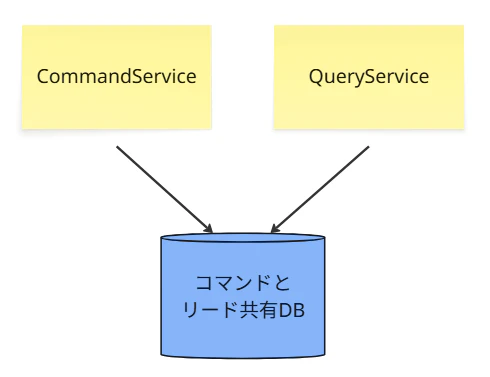
① 論理的にも物理的にも分離できていない(泥団子状態)
これはCQRSを適用する前の、伝統的なモノリシック な状態です。
単一のDB、単一のスキーマ(テーブル群)に対して、書き込み(INSERT/UPDATE)と読み取り(SELECT)の両方を行います。
メリット (Pros) ✅
強い整合性 (Strong Consistency)
書き込みが完了した瞬間に、そのデータは読み取り可能です。
そのため、データ不整合(ラグ)を心配する必要がありません。
アーキテクチャのシンプルさ
追加のDBやデータ同期メカニズム(プロジェクターなど)が不要なので、導入は最も簡単。
開発の容易さ(初期)
単純なCRUD(作成・読み取り・更新・削除)アプリケーションであれば、これが最速の開発手法です。
データ品質観点のメリット
データは単一のマスターに存在します。
アトミックトランザクション(ACID)により、データ品質(特に一貫性と正確性)は非常に高く保ちやすいです。
デメリット (Cons) ⚠️
スケーラビリティの欠如(最悪の欠点)
これがCQRSが生まれた理由です。
読み取り(Read)のための複雑なJOIN処理が、書き込み(Write)処理(UPDATEなど)をロックし、システム全体のパフォーマンスを低下させます。
しかも、書き込み負荷と読み取り負荷を 独立してスケールさせることが不可能 です。
パフォーマンスの妥協
スキーマ(テーブル設計)が、書き込みにも読み取りにも最適化されていない「妥協」の産物になりがちです。
保守性の低下
読み取りクエリ(SELECT)の要件変更が、書き込みのスキーマ(UPDATE)に影響を与えたり、その逆が発生したりします。 両者は全く関心が異なるのに、です。
データ品質観点のデメリット
CQRSの分離がないため、読み取り専用の「クレンジング済みデータ」を作るのが困難です。
② 論理的には分離・物理的にはDB共有(モジュラーモノリス状態)
アプリケーションのコード上は、CommandServiceとQueryServiceに分離されていますが、
物理的には1つのDBを共有しています。
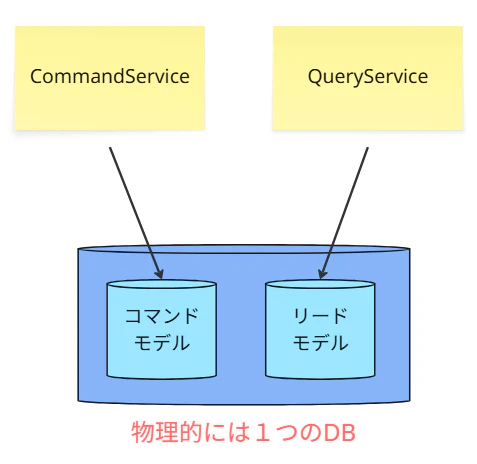
読み取りには(書き込みテーブルとは別の)SQLのView や Materialized Viewなどを使う段階です。
メリット (Pros) ✅
コードの保守性向上 (SRP)
アプリケーションの関心事が明確に分離されます。
「書き込みロジック」と「読み取りロジック」が別々のファイル/モジュールに存在するため、コードがクリーンになります。
限定的な読み取り最適化
Materialized Viewなどを使うことで、書き込みテーブルの構造を汚さずに、一部の読み取りクエリを高速化できます。
強い整合性(維持)
依然として単一のDBであるため、アトミックなトランザクションが(多くの場合)可能です。
データ品質観点のメリット
①と同様です。
データは単一のマスターに存在します。
アトミックトランザクション(ACID)により、データ品質(特に一貫性と正確性)は非常に高く保ちやすいです。
デメリット (Cons) ⚠️
物理的なボトルネック - インフラ競合問題(未解決)
ここが最大の欠点です。
Materialized View への読み取り負荷であっても、結局は同じDBインスタンスのCPU、メモリ、IOPSを消費します。
書き込み負荷と読み取り負荷は、依然として物理リソースを奪い合います。
限定的な技術選定
読み取りに最適な技術(例: 検索エンジン)を使えません。
すべてを単一のDB(例: PostgreSQL)の機能でまかなう必要があります。
スケーラビリティの限界
依然として、読み取りと書き込みを独立してスケールできません。
データ品質観点のデメリット
CQRSの分離がないため、読み取り専用の「クレンジング済みデータ」を作るのが困難です。
③ 物理的にDB分離・同期通信(結果整合かつ同期連携)
CommandDBとReadDBが物理的に分離されます。
しかし、コマンドサービスが「コマンドDB」に書き込んだ同じトランザクション(あるいは直後)で、同期的に「リードDB」にも書き込み(あるいはAPIコール)を行います。
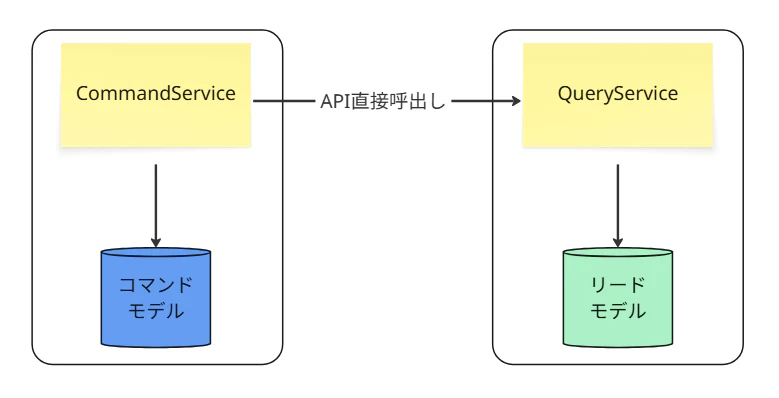
これは俗にいう、結果整合かつ同期通信の「おとぎ話サーガ」的状態です。
しかし、これは通常アンチパターンになります。
理由は別記事で。
メリット (Pros) ✅
物理的な分離の達成
これが最大のメリットです。
リードDB(例: Elasticsearch)への重い読み取りクエリが、コマンドDB(例: PostgreSQL)の書き込みパフォーマンスに一切影響を与えません。
独立したスケーリング(一部)
リードDB(例: 50 Pods)とコマンドDB(例: 3 Pods)を、それぞれ異なるリソース要求に合わせて独立してスケールできます。
技術の最適化(Polyglot Persistence)
書き込みにはRDBを、読み取りには検索エンジンを、といった技術の使い分けが可能になります。
データ品質観点のメリット
コマンドDBとリードDBの両方への書き込みをアトミックなトランザクション(あるいはそれに近い制御)で試みることができます。
デメリット (Cons) ⚠️
時間的結合と可用性の低下(最悪の欠点)
同期通信がすべてを台無しにします。
もしリードDBへの書き込みが失敗・遅延した場合、その障害がコマンドサービスに伝播し、コマンドDBへの書き込み(=ユーザーの操作)自体が失敗します。
「読み取り」側の障害が「書き込み」側を停止させる、非常に脆い(brittle)アーキテクチャです。
書き込みレイテンシーの悪化
ユーザーは、コマンドDBとリードDBの両方への書き込みが完了するまで待たされるため、応答時間が悪化します。
分散トランザクションの複雑さ
両方のDBへの書き込みの原子性(Atomicity)を保証するには、2PC(2フェーズコミット)のような複雑な分散トランザクションが必要になり、これは現実的ではありません。
データ品質観点のデメリット
もしコマンドDBの書き込みが成功し、リードDBの書き込みが失敗した場合、
2つのDB間で即座にデータ不整合(品質低下)
が発生します。これを管理するのは非常に困難です。
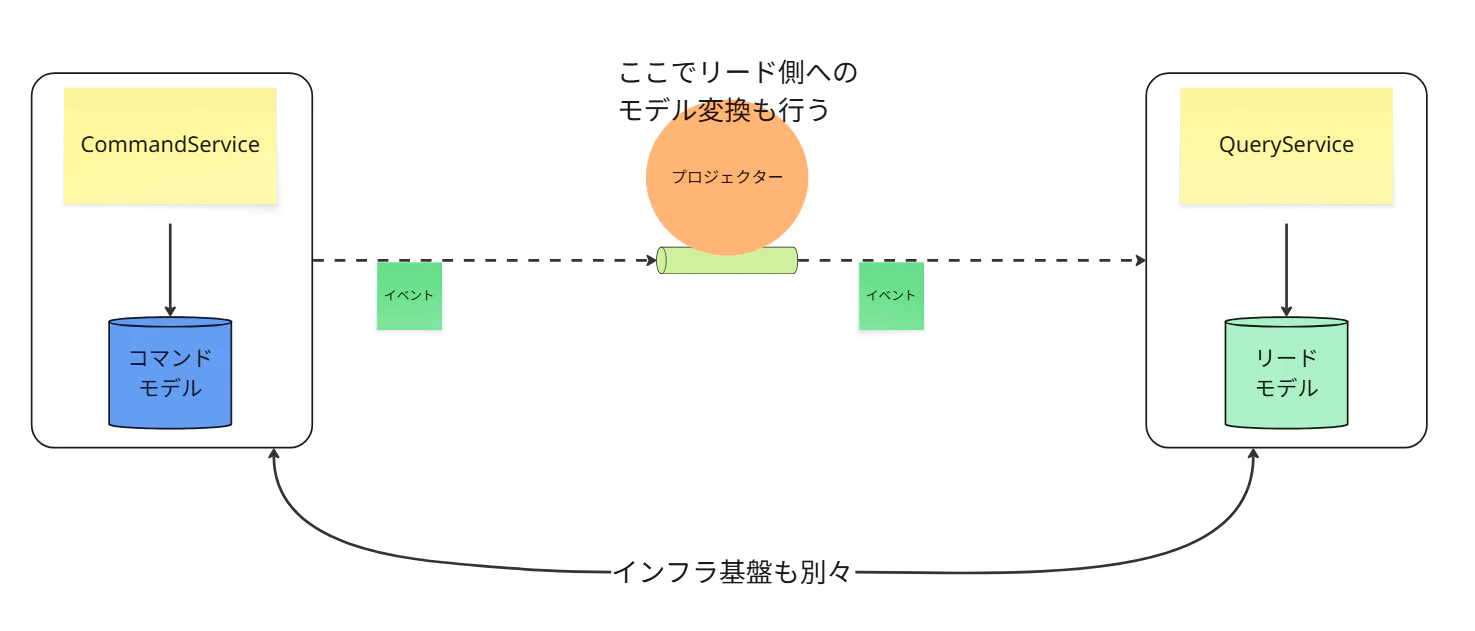
④ 非同期・共有インフラ(イベント駆動)
CommandDBとReadDBは分離されています。
コマンド側はイベントを発行し、プロジェクターが非同期でリードDBを更新します。
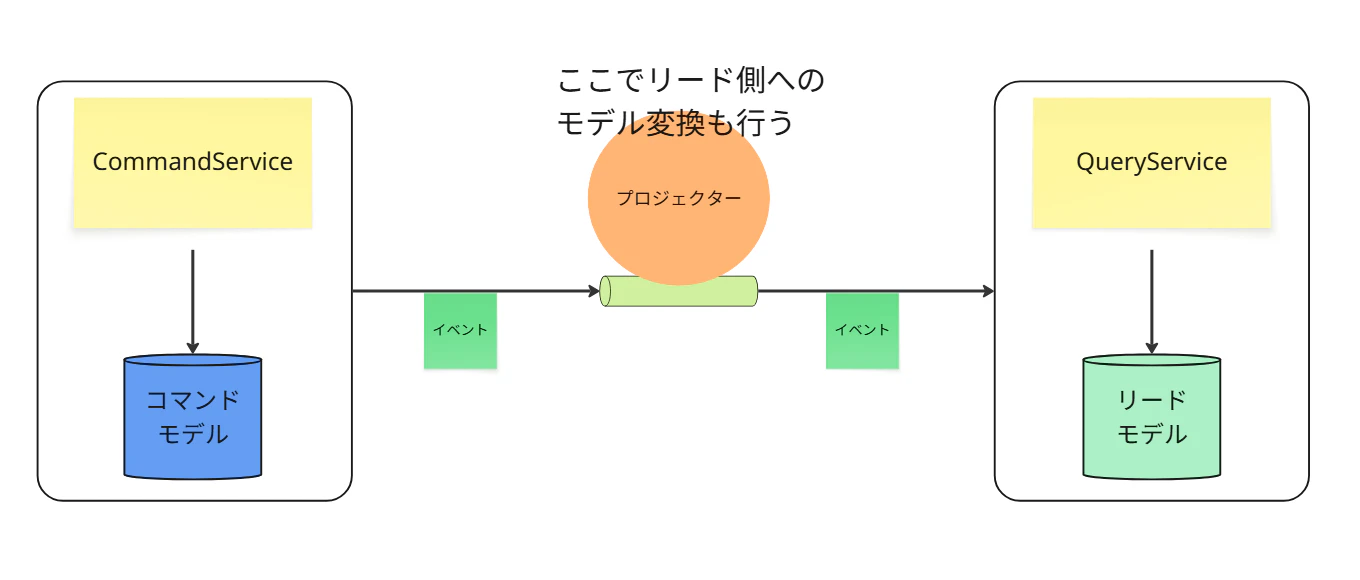
ただし、これら(コマンドサービス、リードサービス、プロジェクター、DB)は同じインフラ基盤(例: 1つのKubernetesクラスタ、1つのVPC)を共有しています。
メリット (Pros) ✅
時間的結合の解消(最大のメリット)
非同期化により、コマンドサービスはイベントを発行したら即座に応答を返せます。
書き込みレイテンシーは最小限です。
高い可用性(疎結合)
リードDBやプロジェクターが障害で停止しても、コマンドサービスは一切影響を受けず、書き込みを受け付け続けることができます。
拡張性 (OCP)
新しいリードモデル(例:分析基盤)を追加したくなっても、コマンド側を変更せず、イベントを購読する「消費者」を追加するだけで済みます。
データ品質観点のメリット
「データ品質のパイプライン」を明確に構築できます。
プロジェクター(イベント消費者)が、イベントを受け取った際にデータ品質チェック
(検証、クレンジング) を行ってから、リードDBに書き込むというプロセスを組み込めます。
デメリット (Cons) ⚠️
結果整合性 (Eventual Consistency)
最大のトレードオフです。書き込みからリードモデルへの反映にタイムラグが生じます。
ユーザーが更新直後にリロードしても、古い情報が表示される可能性があります。
これがUX低下につながる可能性があります。
アーキテクチャの複雑化
メッセージブローカー(Kafkaなど)やプロジェクターの導入・運用が必要になります。
共有インフラのリスク
滅多にありませんが、もし共有インフラ全体(例:K8sクラスタ全体)が停止すれば、コマンド側もリード側もすべて道連れになります。
データ品質観点のデメリット
結果整合性が最大の課題です。上記で書いているので省略します。
⑤ 非同期・インフラ分離(完全分離)
④の非同期アーキテクチャに加え、コマンド側のインフラ(VPC-A, K8s-A)と、リード側のインフラ(VPC-B, K8s-B)を物理的に(あるいはアカウントレベルで)完全に分離します。
メリット (Pros) ✅
究極の障害分離(爆発半径の最小化)
これは、最大のメリットです。
仮にリード側のインフラ(VPC-B)が設定ミスや攻撃で壊滅しても、コマンド側のインフラ(VPC-A)は一切影響を受けません。
独立したセキュリティ
コマンド側(最重要)のセグメントに、より厳格なセキュリティポリシーを適用し、
リード側(公開APIなど)のポリシーと明確に分離できます。
究極のスケーラビリティ
それぞれのインフラを、互いのリソース(IPアドレス、CPUクォータ等)を一切気にせず、自由にスケールできます。
データ品質観点のメリット
④と同様ですので、省略します。
デメリット (Cons) ⚠️
最大の運用複雑性
複数のVPC、複数のクラスタ、それらを繋ぐネットワーク(VPC Peeringなど)、それぞれの監視...と、運用・管理コストは最大になります。
この状態をいきなり一足飛びに目指すのは、マジでやめましょう。
結果整合性
④と同じく、結果整合性のトレードオフは受け入れる必要があります。
データ品質観点のデメリット
④と同様ですので、省略します。
まとめ
最後に、①~⑤の比較表も載せておきますね。

アーキテクチャが分離・非同期化される(④、⑤に進む)ほど、
スケーラビリティは向上しますが、
データ品質(一貫性) の管理はより複雑になり、結果整合性
という新しい課題に対処する必要が出てきます。