前提
羽田空港にて開催されたデブサミ2024の初日のみに参加してきました。
そこでのメモと得られた気付きをここに残します。
個人的見解を多く含みます。発表者の意図とは異なる可能性大です。
参加してきた枠は以下の通り。
・ソフトウェアセキュリティはAIの登場でどう変わるか - OWASP LLM Top 10
・開発生産性?いや、Developer Joyについて語ろう。
・開発生産性の現在地点について~エンジニアリングが及ぼす多角的視点~
・マイナビの全社データ基盤のモダナイズ
・【イオンスマートテクノロジー】マイクロサービス導入により生まれた組織課題に対するソリューションとしてのTiDB
・7年間1000件の障害事例からわかった、障害対応の改善ポイント~協同で変えるシステム障害対応とは?~
・ゼロから大規模アジャイル組織への進化~推進者が語る立ち上げ背景と開発生産性~
この中でもっとも印象深かったもののみにフォーカスを当てていきたいと思います。
ちなみに今回のメイン目的は最近、耐障害性という品質に関心があるため、野村さんの講演が主目的でした。
そのため昼食をとると眠くなるから、腹すかせながら聴講していました。
ソフトウェアセキュリティはAIの登場でどう変わるか
講演者の岡田さんの脆弱性入門というYouTubeチャンネルも紹介に出たので、以下に貼っておきます。
セキュリティ=f(外部の脅威 , システムそのものの脆弱性)
この関数表現はわかりやすいですね。
この前者は自分達ではコントロールしようのないものだが、
後者に関してはアーキテクチャの選定ミスとか、品質を必要十分に担保しなかったこと
などなどコストなどの制約条件下において自分たちでコントロールできるものである。
OWASPでは、その他にもSTRIDEなど様々な便利なフレームワークを公開していますのでチェックしてみてください。私自身案件とかでも実際に使わせていただきました。
新たな脅威
またLLMセキュリティリスクとして、新たに以下の事柄が挙げられます。
過度な信頼をしてしまい、不用意に自動化や外部コンポーネントを使ってしまうこと。
円安といえどもクラウドを使う組織はありますが、これも極論外部リソースを信頼しきって使っていますよね。
トラブルが起こる確率は0%ではない。
勿論保証とかがあるわけだけども、リスクは考慮した上で使っているのか?
という思考が大切ですよね。
そう考えると、やっぱりビジネスサイドからの継続的な脅威モデリングによる、
脆弱性分析はより大切になってくると感じます。
機械学習における ヒューマン・イン・ザ・ループ
ヒューマン・イン・ザ・ループについては、以下を参照ください。
やっていることは、AIと人間がコラボしながら継続的にサイクルを回してるというシンプルな改善モデルです。
たとえAIによって便利になったとしても、
基本である、リスクベースアプローチがより主流になってきます。
リスクベースアプローチについての詳細な記事は別途コチラに記載します。
開発生産性?いや、Developer Joyについて語ろう。
去年から結構参加している開発生産性をテーマとした講演1つ目です。
本当に生産性って、従業員にとっての魅力的品質に紐づくと感じます。
まず冒頭に開発マネージャーの陥るアンチパターンの説明がありました。
マネージャーが陥るアンチパターン
(与えられた前提で)どのようにして生産性を測定しようかという方針
ではなく、
どのようにして生産性を高める手助けをするかという方針
上は完全に手段が目的化していますよね。
たとえば
「いやそれは方針だから~~~」「決められたルールだから~~」とか。
ここである絵画アーティストの事例を紹介されました。
才能ある画家は、絵具使えないなどの様々な意味不明な制約条件下で、
ストレスを感じながら、本来自分が出したいアウトカムを出せずに、
結果的に出来上がった成果物は、ク〇みたいな品質のものであり、かつ生産性も低いという物語。
アーティストの芸術性の最大の阻害要因が、マネージャーになっているパターンです。
そう、マネージャー自身が監視役みたいになっていて、
本来従業員たちが顧客の求める期待値以上のアウトカムを出せるような場づくりではなく、
定められた前提条件や制約条件をひたすらに守るための振る舞いをするという構図。
マネージャーが自分よりも上に気に入られたいという願望が強い状況であるあるな現象ですね。
生産性は副産物
生産性とは=Developer Joyの副産物であり、
従業員にとってのプロジェクトを通した体験(ものがたり)の価値を高めた結果、
自ずと生産性は勝手に上がっている。
これは、近年よく耳にする【モノの品質からコトの品質へ】てものをまさに表現してますよね?
これを意識した継続的な従業員体験品質改善をしていないと、
チームの自律性の無さ
多すぎる別のチームとの摩擦
今既存で動いているコードを壊す恐れから手を入れない
といった、結果的にプロダクトの品質まで悪くなるようなことに繋がる。
これが生産性を低下させる要因でもある とのこと。(うんうんうん)
Developer Joy=DevEX + エンジニアリングカルチャー
エンジニアリングカルチャーとは、組織文化のこと。
DevEX(開発者体験)をここでは、DXと定義していました。(ほんとそれって思ってました)
ここからはちょっと自論を書きます。
ちなみにLeanとDevOpsの科学では、組織文化がもっともボトルネックになりやすくもあり、もっとも価値を高める要因であるとの趣旨が書かれていた。
これは制約理論にも通ずるものを感じていました。
ちなみにルール作り含めた、組織文化に関しての仕組みづくりは、往々にしておざなりにされがちです。
視えない概念を扱うからかゆえか、目に視える物としてのシステムにばかり
目がいくマネージャーの時代は終わりを告げていると個人的にも感じます。
てか、本当は文化という目に視えない概念でさえも、組織というシステムを構成する重要な要素なんだけどねって感じです。
組織文化においても設計思想を盛り込んだ組織は、少ないけれども存在はします。
代表的なのは、AWSのリーダー原則です。
SOLIDやコンポーネント原則をガチで学習されたことのある方なら、
ご覧いただければお分かりかと思いますが、この16つの原則、
すべてが関心ごとに分割されており、このポリシーにそった行動を実装としてアナタは体現されてますか?てことを面接では聞かれるそうです。
ちなみに私は、この組織文化にまで設計思想を取り入れようって試みに
自分が世界で唯一最初に気づいたと確信していたところ持ってきて、
この原則集を発見した際には「あ、私が最初じゃなかったΩ\ζ°)チーン」と一瞬なりましたが、同時に文化にまで設計思想をもってしてメスを入れているスタンスに芸術的感動を覚えました。
はい、長くなりましたが一旦ここで自論終わりです。
DXの定期的な1週おきのの現在地ヘルスチェックとして、
プラットフォームチームの設立(スクラム前提の少人数制)
を行ったそうです。
これはチームトポロジーにも記載がありましたが、
ストリームアイランドチームの担当スコープの拡大に伴う認知負荷を下げる手助けとして、
プラットフォームチームが存在します。
そして、DXとして
認知負荷を下げる
組織文化を継続的にメンテ
拡張性の高いプラットフォーム
の活動をしたことによって、Dev満足度は49%から70%にまで上昇したそうです。
そしてこの講演を聞いて、自分の中で今所属している価値駆動をポリシーに掲げた、
匠と、生産性を掛け合わせたアイデアがひらめいたので、どこかで発表したいと思います。
7年間1000件の障害事例からわかった、障害対応の改善ポイント~協同で変えるシステム障害対応とは?~
はい、今回デブサミに参加した主目的の野村さんによる障害対応講演です。
自分の中で、最近【境界付けられたコンテキスト】を考える際の、
重要な品質特性である、耐障害性観点の知見を得たいと強く思っていたので参加しました。
まず冒頭から衝撃的数字を突きつけられました。
障害によって発生する損失額は5兆円/年間で10年前から約7倍に膨れ上がっている。
何か障害が起きると、「とりあえず必要そうな情報集めろ」と言われ、
障害対応する人々は必死に情報を集めるけども、
集まった情報には、
・不要なものが大量に混ざっていたり
・必要な情報がすべてそろっていない
、、、という悲しい事態。
そこで以下の3つの方針によってこの課題に対処しようという試みがテーマです。
①システムの視座 → サービス全体視座へ
障害対応する人は、ついついシステム内部という詳細な視座で
「いまDBのこんなとこに問題が発生し~」みたいなことを言ってしまうけども、
そもそもエンドユーザーが本当に欲しい情報は、サービス全体を俯瞰した視座での情報。
どのくらいで復旧しそうなのか? 代替案は?など。
内部のトラブルの詳細情報には関心がないからである。
たしかにシステム内部という詳細な視座も必要だが、
それを外から眺めた1つ以上のシステム連携からなるサービス全体を俯瞰する視座との行き来が重要である。
②事象ではなく、アクション
起きているトラブルを追い続けている限り事態は何度も再発し、収束しなかったが、
その際のアクションを追うようにしたら収束へ向かったそう。
起きる障害としての事象は無限にあれども、アクション自体は収束傾向にあるからだ。

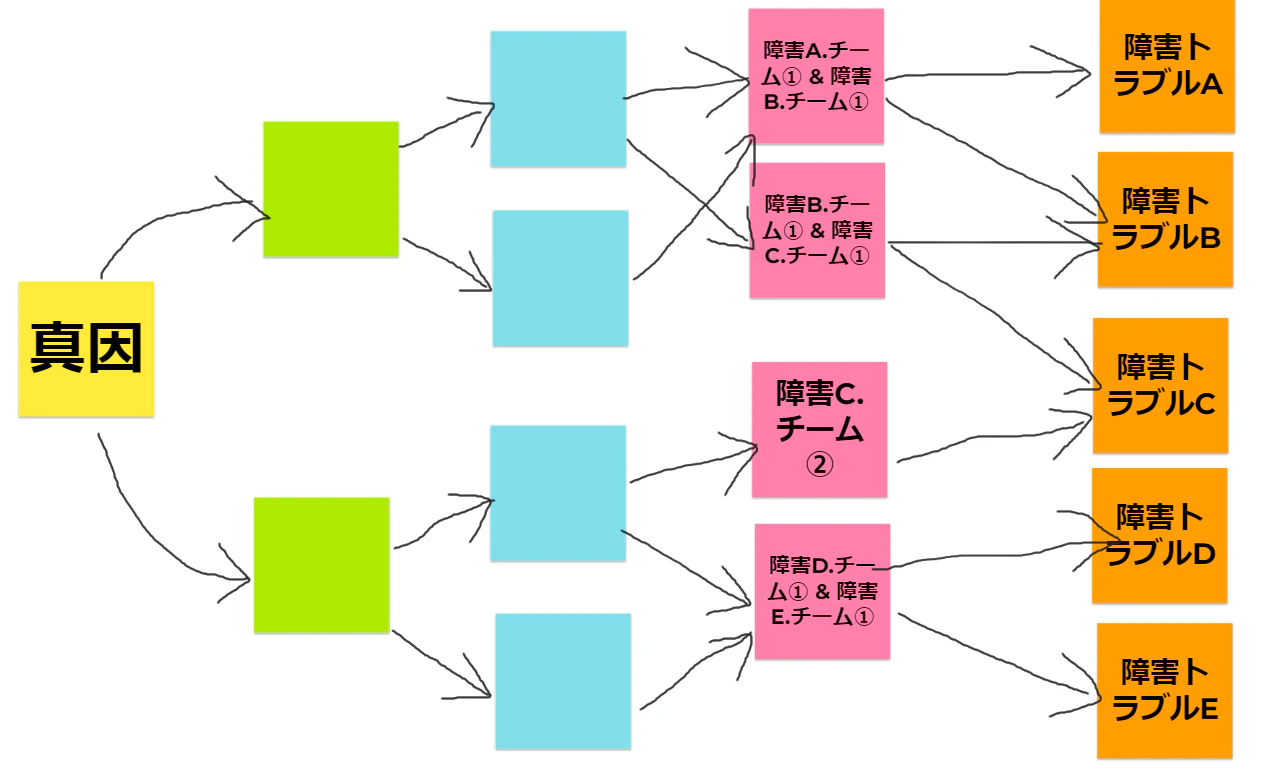
これはたとえば、上図のように粒度を揃えた障害の原因ツリーを作成してみればいいってこと。
オレンジの付箋がサービス全体として、利用者視点で起きている障害トラブルだとする。
その原因がピンク色付箋であり、その原因がブルーの内容であり、といった感じに原因分析すると、最終的に大体真因に収束する傾向にある。
アクションを追うというのは、いきなり真因にたどり着けずとも、
継続的な障害対応のナレッジ蓄積によって、
起きた障害に対してどんなアクションを取ったのか?
それはより深い原因として、どれが原因だと考えられたからなのか?と
図の階層構造を左に深めていくことで真因にたどり着けるからである。
黄色の真因への改善アクションさえ取れれば、図中のすべてのオレンジ付箋の障害は消える。
この真因を継続的に見つけやすくするために、表面的な起きてる事象よりも、
より原因に対してとったアクションを追うようにする。
この際に、障害対応している人たちは無意識のうちにアブダクションという原因→結果 の仮説メカニズムを体現していると感じている。
この仮説なしに場当たり的に障害対応していると、根本解決はできない。
③情報の量ではなく質
これは②の続きの内容であるが、情報量が多い状態では、適切な意思決定が困難になる。
特に分断されており、境界付けられたコンテキストが意識されていない組織構造の環境下においては、更にその難易度ははね上がる。
先程のこの図のように、階層構造化するなりして、
誰がどの障害対応をするのか?という背景を理解したうえで、その人にとって必要な情報のみを過不足なく伝えること。
最初からそれを実現することは難しくても、継続的な障害対応によって徐々に質を上げる活動が大事である。
その際にも意識したいのは、障害対応という観点でのチャネル設計などである。
これはチートポにも記載があることだが、
障害対応という観点でのコンテキスト境界が意識されたチームの境界、
チャネル設計などによるコンテキストごとの情報の過不足ない伝達の仕組みづくりが重要である。
チャネル設計の際にも、名前を意図のわかる名称にした方が良く、
この際にパッケージの名前空間の名称付の考え方をパクった名前設計で行うといいと感じる。
大分名前は適当だが、以下のような感じ。
事例紹介
3つの方針以外に具体的な事例が3つ紹介されたので記載する。
組織体制の変更
ベテランへの属人化を無くすために、障害対応するのを若手へ体制変更した事例である。
まず大規模障害といっても色々あるので、その定義を最初の時点で明確化にしたそう。
その中で不確実性が高いなど、リスクポイントの特に高い代表的なものをチョイスし、
それぞれのパターンで関連組織を形成する。
これはサービス障害が起きたというリスクベースアプローチである。
ようはサービス視座で視た際の代表的な障害とその背景を定義し、
その障害が起きているという仮定の中で、どのような組織構造を形成すべきか?
障害復旧という軸の観点でコンテキスト境界を考えるということ。
例として、Webアクセスが10秒以内に10000件以上来ているから不正アクセスの可能性。
→ セキュリティ担当者へ連絡しよう。みたいな
これもチートポのような思想をうまく取り入れた事例に感じた。
改善のための工夫
一度割り当てられた責務を思考停止して行うのではなく、
障害対応時の責務の割当を適切に変えたことによって、自分たちがもっと楽になるような改善のサイクルが回りだした事例。
これによって、最初運用と保守の間にあった対立構造が解消され、
1か月に鳴り響いていたアラート数が、なんと9割も減ったそう。
提示されたグラフを直に見させてもらったが、減衰曲線の減衰度合いがすさまじかった。
ここでもチートポの思想のように、
もしも自分たちのパフォーマンスが悪いなと感じるなら、
一度定義された責務の配置を疑い、責任の割当を再検討してみる。
その結果、別チームとは、いい意味でも疎結合になれるし、情報の分断も抑制できる。
まさにカプセル化の発想そのものである。
協同で変える
エンドユーザーへの悪影響を最小化するため、部門の壁とかを超えよってこと。
状況によって視座や視点を迅速に変え続ける訓練が必要。
それによって、先程の情報の質もより向上していくからである。
さらには、それが生産性向上にも繋がっていくと思われるし、
継続的な障害対応を通した改善活動によって、アーキテクチャも進化していく。
という、障害対応という活動を通して組織自体のアーキテクチャもより良くなっていくので、開発者体験の質も向上し、生産性が副次的にアップするという好循環をもたらす。
まとめ
今回のテーマは、最終的に生産性というテーマに集約されているなと感じた。
初日しか参加ができなかったが、様々な観点でどのようにコンテキストを切り分けることによって、より生産性の上がる仕組みが実現できるのか?を考えさせられる素晴らしいイベントでありました。