前置き
さて、CQRSアーキテクチャでコマンドモデルとリードモデルが、同期通信の時には、コンテナ上は2つは別々のコンテナで運用するものの、インフラ上で蜜結合しているので、Podとしては1つでデプロイしてもいいのでしょうか?
アンチパターン
実はこの考えは、超アンチパターンです。
「同期通信なのでインフラで密結合しているから、デプロイ単位としては集約された状態なので、1つのPodなんじゃないの?」という風に考える方もいると思います。
しかしだからといって「1つのPodにまとめる」のは、さらに悪い問題を引き起こします。
Podは、「スケーリング」と「ライフサイクル」の最小単位だからです。
なぜ1つのPodにしてはいけないのか?
コマンドモデルとリードモデルは、
非機能要件(特にスケーリングとライフサイクル)が根本的に異なるため
「運命共同体」である単一のPodに同居させるべきではありません。
1. スケーリングのミスマッチ(これが最大の理由)
コマンドモデル(書き込み)
トラフィックは比較的少なく、安定しているかもしれません。(例:3個Podあれば十分。)
リードモデル(読み取り)
トラフィックが非常に多く、急増することもあります。(例:50 Podにスケールアウトさせたい。)
もしこれらを1つのPodに入れてしまうと、
リードモデルを50にスケールさせた結果、不要なコマンドモデルも50個作られてしまいます。
これはリソースの甚大な無駄遣いです。
2. ライフサイクルのミスマッチ
コマンドモデルの変更
ビジネスロジックの変更。
リードモデルの変更
画面表示用の新しいクエリ(ビュー)の追加。
もしこれらを1つのPodに入れてしまうと、「リードモデルに新しいクエリを1つ追加したい」というだけの変更のためにPodをローリングアップデートすると、その間コマンドモデル(書き込み処理)まで一緒に停止・再起動 してしまいます。
読み取り(Query)側の変更が、書き込み(Command)側の可用性を破壊してしまうのは、CQRSのメリットを完全に殺す、非常に悪い設計です。
密結合への正しい対処法
同期通信を選んだ時点で、アプリケーションアーキテクチャとして「密結合」 です。
コマンドモデルは、リードモデルが応答を返すまで待たされます。
リードモデルのDBが停止すれば、コマンドモデルの処理も失敗します。
この「密結合」は、2つを別々のPodにしてKubernetesのService経由(http://read-model-svc)で通信させても、同じPodにしてlocalhost経由で通信させても、どちらにせよ発生します。
1つのPodにまとめるという行為は、その密結合を解消するどころか、
「スケーリング」と「ライフサイクル」という別の結合を無理やり追加してしまう
という、わりと最悪の選択です。
Podの単位は必ず分ける
CQRSの同期モデルであっても、
・コマンドモデルは、command-deploymentとして(例: 3 Podsで)デプロイする。
・リードモデルは、read-deploymentとして(例: 50 Podsで)デプロイする。
というように、必ず別々のPod(Deployment)として運用 します。
これにより、
両者のスケーリングとライフサイクルを独立
させることができます。
ただし、パイプラインを別にしろという意味ではないです。
ここについては、後述で触れますので、是非下まで読んでください。
パイプラインアーキテクチャの構造
コマンドモデルとリードモデルを別々のPodとしてデプロイするのは、「スケーリング」と「ライフサイクル」(=OSのCPUアーキテクチャやランタイムの分離)という物理的な非機能要件が異なるからです。
しかし、CI/CDパイプラインは
「ビジネスロジックの一貫性」と「安全なデプロイ順序」
に責任を持ちます。
「同期通信」や「結果整合だがスキーマが密結合」の段階では、コマンドモデルとリードモデルは、論理的に「1つのデプロイ単位」 として扱わなければ危険です。
そのため、パイプラインのアーキテクチャは、以下のようなファンイン構造になります。
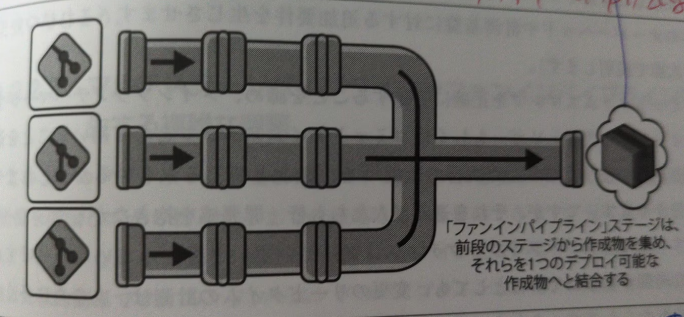
なぜファンインパイプラインになるのか?
この状態は、まさに 「分散モノリス」 です。
アプリケーションは(Podとして)分散していますが、ロジックやコントラクト(契約)が密結合しています。
この密結合なアーキテクチャを安全にデプロイするためには、CI/CDパイプラインが 「集約(ファンイン)」 にならざるを得ません。
結果整合 && 同期通信の場合(おとぎ話サーガ型)の事例
インフラで密結合
コマンドPod v1.1は、リードPod v1.1のAPIを同期呼び出しします。
リスク
コマンド v1.1だけをデプロイし、リード v1.0が古いままだと、コマンド v1.1はAPI呼び出しに失敗し、システム全体が即座に停止します。
パイプラインの解決策(ファンイン)
CI/CDパイプラインは、
「コマンド v1.1とリード v1.1の両方のビルドとテストが成功した場合にのみ、両方を同時に(あるいは決められた順序で)デプロイする」 という、ファンイン・ゲートを設ける必要があります。
ここのまとめ
「別々のPod(物理的分離)」と「ファンインパイプライン(論理的集約)」は、全く矛盾しません。
「物理的には分離しつつ(スケーリングのため)、論理的には密結合している(一貫性のため)」という分散モノリスの特性を、CI/CDパイプラインが正確に反映した結果が「ファンインパイプライン」です。
逆コンウェイ戦略に伴うコミュニケーション設計
さて、ここでチームトポロジー的な話もしておきましょう。
1つ前のトピックで触れた、インフラ部分で集約されているパイプラインと相似形になるように、このアーキテクチャの構造は、組織のコミュニケーションパスと相似形になっている必要があります。
アプリケーション層ではコマンドモデルサービスの担当チームと、リードモデルサービスの担当チームはコミュニケーションは疎である。
だけども、インフラチームである、SREエンジニアやプラットフォームエンジニアたちのコミュニケーションは密になります。

1. アプリケーション層(疎なコミュニケーション)
アーキテクチャ
コマンドモデルとリードモデルは、論理的に異なる関心事(書き込み vs 読み取り)を扱っており、別々のPod(チーム) で開発・運用されています。
コンウェイの法則
これにより、コマンドチームとリードチームは、「自分たちのドメインロジック」に集中できます。
彼らの間のコミュニケーションは、APIの 「コントラクト(契約)」 の議論だけに限定されるため、コミュニケーションは疎(コミュニケーションコストがかからない) になります。
コントラクトに反するようなケースの場合には、コミュニケーションが発生します。
2. インフラ層(密なコミュニケーション)
アーキテクチャ
コマンドPodとリードPodは、「ファンインパイプライン」という集約されたインフラによってデプロイされます。
また、同期通信によってインフラレベルで密結合しています(片方の障害がもう片方に伝搬する)。
コンウェイの法則
この 「密結合なインフラ」を運用するSRE / プラットフォームエンジニアチーム は、その結合性を管理するために、どうしても密なコミュニケーションを取らざるを得ません。
・「リード側のデプロイが失敗したから、コマンド側のデプロイもロールバックするぞ!」
・「コマンド側がリード側を同期呼び出ししすぎて、リード側のネットワーク帯域が逼迫している!」
・「両方のPodを同時に安全にデプロイするために、ファンインパイプラインの順序を調整しよう」
こんな感じで、このコミュニケーション調整コストも見積もりに含んだ状態で、予算管理しないといけません。
ここのまとめ
アーキテクチャの密結合(技術的負債)が、インフラチームのコミュニケーションコスト(人的負債)にそのまま転嫁されている状態を示しています。
このコストは、必ず認知した状態でなくてはなりません。
同期通信の場合のトレードオフ
コマンドとリードモデル間に同期通信を選択した場合、
パフォーマンス(低レイテンシー)がセキュリティ(厳密な分離)よりも優先
されることが多いため、あえて同じネットワークセグメント(あるいは同じアベイラビリティゾーンなど、ネットワーク的に極めて近い場所)に配置するという設計判断をされます。
しかし、それによりセキュリティリスクといった別の問題も起きてきます。
なぜ同期通信だと、そのリスクを許容するのか? について、以下の3つに分けて書いていきます。
1. 同期通信の「ペイン(苦痛)」 ⏳
CQRSを同期で連携するということは、ユーザー(クライアント)のリクエスト処理が、
2つの異なるデータベース書き込みが完了するまで待たされる(ブロックされる)
ことを意味します。
①. コマンドサービスが「コマンドDB」に書き込む。
②. コマンドサービスが (同期で)「リードモデルDB」に書き込む。
③. 両方が成功して初めて、ユーザーに応答を返す。
2. ネットワークセグメントが「レイテンシーのボトルネック」になる
もし、この2つのDBを以下のように、異なるネットワークセグメントに配置すると、ステップ②の通信は必ずネットワークホップとファイアウォール(セキュリティグループ/NACL)の通過を伴います。
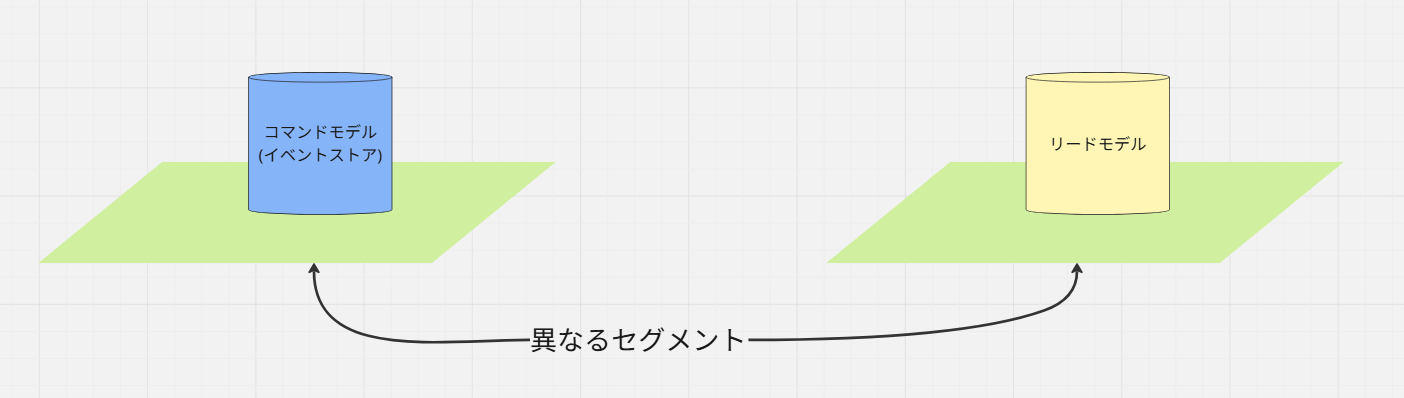
この時のファイアウォール通過が数ミリ秒のレイテンシーを追加するだけで、ユーザー体感速度は著しく悪化します。
また、トランザクションを長時間保持することは、DBのロック競合を引き起こし、システム全体のパフォーマンスを低下させます。
3. トレードオフの「意思決定」
したがって、アーキテクトは以下の意識的な選択を迫られます。
選択A:同期通信のパフォーマンスを最優先する
そのために2つのDBを同じセグメントに配置し、ネットワークレイテンシーを最小化する。
※許容するリスク
セキュリティレベルが低い方(リードモデル側)に、高い方(コマンドモデル側)が引きずられるリスクを許容する。
選択B:セキュリティ分離を最優先する
そのために2つのDBを別のセグメントに配置する。
※許容するリスク
同期通信のままではレイテンシーが悪化しすぎるため、アーキテクチャを非同期(イベント駆動)に変更し、結果整合性(リードモデルの更新が少し遅れる)を許容する。
ここのまとめ
「同期通信」を選択するということは、
「レイテンシー」に対して非常に厳しい要件を持つ
ということです。
そのため、「セキュリティリスクを許容してでも、同じセグメントに配置する」という判断は、その前提(同期通信)の上では、最も合理的な設計判断と言えます。
多くのアーキテクトがこの「セキュリティ vs パフォーマンス」のトレードオフを嫌い、最初から「非同期(イベント駆動)」を選択する理由も、ここにあるのではないでしょうか?
他のPodへの爆発半径の拡大
マイクロサービスアーキテクチャでは、障害の影響範囲に関して、
「Pod内で起きた障害は別のPodには影響が伝搬しない」(爆発半径の最小化)
という、重要な原則があります。
同期通信を選択するということは、まさにこの原則を、意図的に犠牲にするという設計上の決断です。
なぜ原則に反する設計になるのか
これを
・非同期通信で、爆発半径が閉じている場合
・同期通信であり、爆発半径が局所的でなく開いてしまっている場合
とに分けて考察してみましょう。
理想 (非同期)
Service Aはイベントを発行して即座に完了します。
Service Bが後でそのイベント処理に失敗しても、Service Aには何の影響もありません。
爆発半径はService Bに閉じ込められます。
現実 (同期通信)
①. Service A(コマンドモデルPod)が、Service B(リードモデルPod)を同期呼び出しします。
②. Service Aは、Service Bからの応答を待ちます (ブロックされます)。
ここで、もしService Bがバグや高負荷で障害を起こし、応答を返せない場合...
③. Service Aもタイムアウトするか、リソース(スレッドプールなど)を使い果たして道連れとなって障害を起こします。
Service Bという 「別のPodで起きた障害」が、ネットワーク(同期呼び出し)を通じて「Service AのPodに伝搬」 してしまっています。
ここのまとめ:「トレードオフ」の受け入れ
「同期通信のCQRS」を選択することは、以下のようなメリデメを伴います。
得るもの
強い整合性(Strong Consistency)、シンプルなアーキテクチャ(ブローカー不要)。
失うもの(許容するリスク)
爆発半径の最小化、システムの疎結合性、完全なスケーラビリティ。
この設計は「爆発半径最小化の原則に反さざるを得ない」のです。
このリスクを軽減するために、サーキットブレーカーや厳格なタイムアウトといった「防衛策」が必要になってきます。
サーキットブレーカーについては、以下の方の記事がわかり良かったで、引用します。