インラインコード
はじめに
システム企画では、往々にして
「この部分の業務を自動化することによって、このくらいの作業工数が浮いてコストがこれだけ削減できます」
というメリット部分だけが語られ、システム導入によるネガティブブランチとして、
新たにシステム化によって発生する運用業務がこれだけ発生することが見込まれる
というデメリット部分の議論なく、システム導入自体が目的となってしまっていることが多々あります。
DX系の案件とかは、まさにこれに該当することが多いのではないでしょうか?
そこで今回は、システム要件定義の際にマストで行うべき、運用要件について触れていきます。
システム要件定義における「運用要件」の設計指針
初期リリース(Day1)に向けたシステム要件定義では、運用業務のすべてをシステム化・自動化しようとするアプローチは絶対に避けるべきです。
不確実性の高い例外対応を初期にすべて予測することは不可能だからです。
1. どこまで定義すべきか?(境界線の設定)
初期の運用要件定義においてスコープに含めるべき「Do」と、含めるべきではない「Don't」は以下の通りです。
含めるべきこと(Do)
・アトミックな運用ユースケースAPIの提供
状態を強制変更するなど、単一の振る舞いをする「安全な部品」の設計。
・運用の可観測性(Observability)の確保
運用APIが実行された際のメタデータやメトリクスを記録する仕組み。
・自動化への移行判定ルール(閾値)の合意
「月に〇時間以上の運用コストが発生したら自動化バックログに積む」といったROIの基準。
含めるべきではないこと(Don't)
・複雑な条件分岐を伴う運用ロジックのシステム化
「AエラーならAPI-1、BエラーならAPI-2」といった複雑なオーケストレーション。
これは初期段階では人間の手順書(Runbook/SOP)に委ねます。
なぜこの境界線にするのか?(理由)
予測不可能なエラーに対する複雑なリカバリロジックを初期に設計しようとすると、要件定義が泥沼化(Big Design Up Front)し、リリースが遅延します。
判断と複雑なフローは人間に任せ、システム側は「安全に介入できる手段」と「判断材料となるデータの蓄積」に徹する
ことで、運用を通じて得られた実績データ(勝ちパターン)をもとに、後から確実なROIをもって自動化していく「アンチフラジャイルな成長ループ」を描けるからです。
2. なぜ「運用ユースケースAPI」が必要なのか?
運用担当者が介在して業務データをリカバリ・補正する場合、DBへの直接アクセス(直接のSQL実行など)を絶対に許容してはいけません。
理由
データの「所有権(ドメインチーム)」と「実行権限(運用担当者)」を明確に分離するためです。
これをやってしまうと、ビジネスルールをバイパスすることになり、
データの不整合や「誰が・なぜ変えたか分からないデータ」
が生み出されてしまいます。
目的
運用担当者に直接データを触らせると、システムが持つビジネスルールをバイパスしてしまい、データの不整合やガバナンスの崩壊を招きます。
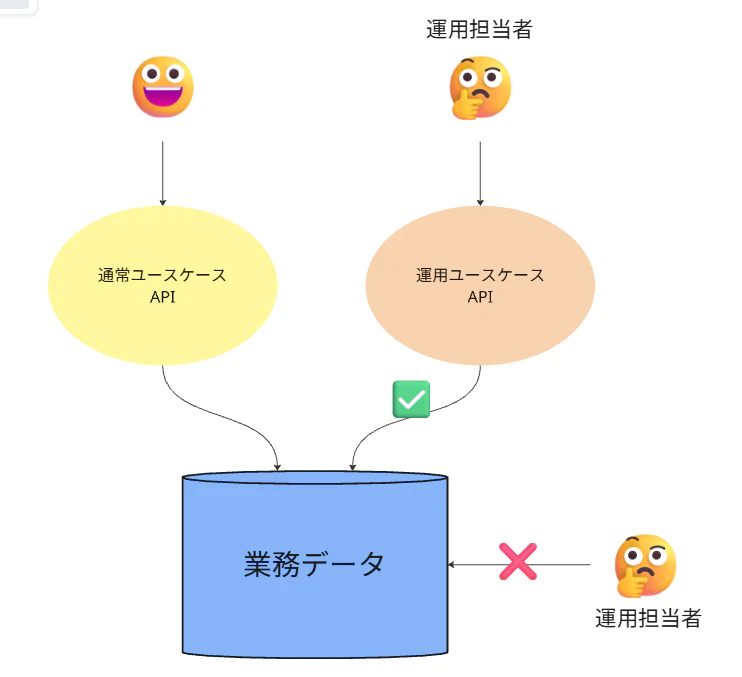
システム側に特例用の「正規ルート(運用ユースケースAPI)」を用意し、そこを経由させることで、ビジネスルールの制約下で安全に状態を変更させると同時に、後述する「運用メタデータ」と「業務トランザクション」をシステム的に確実に紐づけて記録することが可能になります。
取得すべき運用メトリクスとメタデータ(Informationビュー)
運用の実行ログを「システムを改善するためのドメインイベント」として捉え、以下のデータをシステム要件として取得・蓄積します。
① パフォーマンスと制約を測るデータ(時間と量)
運用タスクがビジネス全体の「制約(ボトルネック)」になっていないか、自動化によってどれだけのコストを削減できるか(ROI)? を定量化します。
所要時間(Cycle Time / Duration)
作業の開始から完了までの実時間。
待ち時間(Wait Time)
タスク発生から着手までのリードタイム。
処理件数(Batch Size)
対象となったレコードやファイル数。
② トレーサビリティと監査を担保するデータ(文脈と権限)
誰が、どんな権限で、何を引き金にしてシステムの業務トランザクション(状態)を変更したのか?
を追跡可能にします。
実行者ID(Personnel ID)
操作を行った運用担当者の物理ロールID。
論理ロールID(Performer ID)
どの論理的なロールでの権限(例:SRE、一次保守)で行使されたか。
起因チケットID / トリガーイベント
なぜその運用が発生したかの起点(監視アラートIDやCSチケット番号)。
対象リソースID
変更対象となった具体的なデータID(ユーザーIDや注文ID)。
利用目的(理由コード)
例外処理を実施したビジネス上の理由。
③ プロセス品質とフィードバックを測るデータ(結果)
その運用手順自体に問題がないか、システム側の根本改修が必要かを判断します。
実行結果ステータス(Result Status)
成功、失敗、部分成功など。手戻り率の計測。
エラー分類(Error Category)
何が原因でリカバリが必要だったか。
システムバグ(排除対象)か、仕様の隙間(自動化対象)かの切り分け。
複雑度フラグ(Complexity Indicator)
ランブックマニュアル通りに完了したか、高度な属人的判断を要したか。
まとめ
初期の運用要件定義では、「運用手順の完全なマニュアル化」までは不要ですが、上記で触れたように、
「運用の可観測性(Observability)の確保」と「自動化への移行判定ルールの定義」
までは行うべきです。
作ってから考えるのでは、あまりにも遅すぎます。