社内でKubernetesハンズオンをやってみたのでおすそ分け。
参加者6人からバンバン出てくる質問に答えながらやって、所要時間4時間ほどでした。
SpeakerDeckにも資料を上げています。
https://speakerdeck.com/ktam1219/yaruze-kuberneteshanzuon
(2019/07/11追記)
続編書きました! -> 今度はあんまりゴツくない!?「わりとゴツいKubernetesハンズオン」そのあとに
ハンズオンの目標
- Kubernetesとお友達になる
- イメージを掴む
- 触ってみる(ローカル・EKS・ちょっとGKE)
- 構築・運用ができるような気分になる
- 巷にあふれるKubernetesの記事・スライドが理解できるようになる
EKSがメインになっているのは、会社の業務でAWSを使うことが多いからです。
純粋にKubernetesを勉強したいだけならGKEのほうがオススメ。
とはいえ、大部分はKubernetesの一般的なお話なので、この記事を読む分にはどちらでもいいかと思います。
前提知識・準備
- Docker / Docker Composeは前提知識として扱います。
- 以下が用意されている前提で進めます
- Docker for Desktop
- kubectl
- AWS CLI(IAMユーザー作ってprofile設定済み)
- aws-iam-authenticator
- eksctl
$ docker -v
Docker version 18.09.2, build 6247962
$ kubectl version --short --client
Client Version: v1.13.4
$ aws --version
aws-cli/1.16.125 Python/2.7.14 Darwin/18.2.0 botocore/1.12.115
$ aws-iam-authenticator help
(省略)
$ eksctl version
[ℹ] version.Info{BuiltAt:"", GitCommit:"", GitTag:"0.1.31"}
Kubernetesとは
一言でいえば、
コンテナオーケストレーションシステム
- たくさんのサーバーに
- たくさんのコンテナを置いて
- 連携させるようなアプリケーションを
- デプロイ・管理・スケールとかさせるやーつ
の、デファクトスタンダード
2014年にGoogleがOSSとして公開しました。Googleの長きにわたるコンテナ運用の知見が詰まっているらしい。
現在はCNCF(Cloud Native Computing Foundation : クラウドネイティブなOSS技術の推進を行う団体)が管理。
Dockerも公式にサポート(Docker Swarmあるのに!😯)
CNCF、錚々たるメンバーが錚々たるOSSを管理しています。

動作環境としては、GCPだけでなくオンプレや他のクラウドでも動きます。
各種パブリッククラウドでは、自力で構築しなくてもマネージドサービスが出ています。
- GCP: GKE
- AWS: EKS (ECSあるのに!😯)
- Azure: AKS
- IBM Cloud(旧Bluemix): IKS
- Alibaba: Container Service for Kubernetes
今はまだ導入の知見がもてはやされるような段階ですが、
もうしばらくすると当たり前の技術になっているかもしれません。
Kubernetesって何がうれしいの?
Dockerって便利だよね
-> 本番環境で使いたいよね
-> でもDockerって基本的に1コンテナ1機能だよね
-> 複雑なアプリケーションを構築しようとすると複数種のコンテナが必要だよね
-> さて、どうやって構築しよう…?
ためしにDockerComposeでの構築を考えてみると…
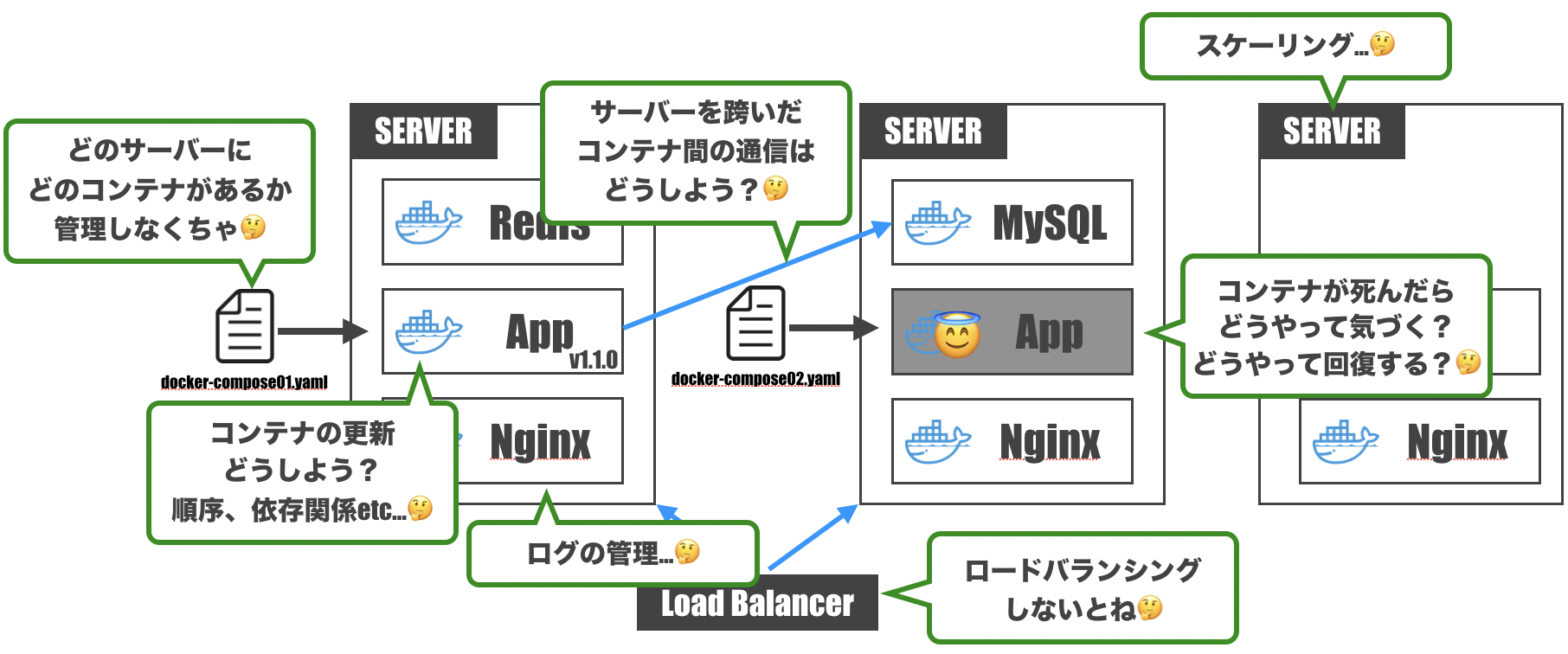
- コンテナが1台のサーバーに収まらないだろうから、どのコンテナがどのサーバーにあるか管理しなくちゃ
- コンテナが死んだときに気づけるようにしないと。回復方法も用意せねば
- サーバーを跨いだコンテナ間通信って結構めんどくさい
- コンテナを更新するとき、コンテナ間の依存関係とかデプロイ順序とか考えなくちゃ
- 複数サーバーにコンテナがあるんなら、ロードバランシングも考えなくちゃ
- サーバーのスケーリングをしないといけないこともあるよね…
- 各コンテナからログが出てくるけど、ちゃんと管理しておかないと運用辛いよね
- etc...
人類には高度すぎますね。。
でも、できるんです。
そう、Kubernetesならね。
Kubernetesのイメージを掴む
ベースとなるアイデア
コンテナの管理をいい感じにやってくれるシステムがあればいいじゃん。というのがベースとなる考え方です。
このいい感じのシステムに「こんな感じでシステムを運用して」と注文書を投げつけてよしなにやってくれると最高。
そしてそれをやってくれるのがKubernetesです。

- いい感じに場所を判断してコンテナを配置
- コンテナが死んだら自動回復
- サーバー間ネットワークもいい感じに
- ローリングアップデート / Blue/Greenデプロイメントもお手の物
- ロードバランシングもやってくれる
- サーバーのオートスケーリングも(クラウドなら)設定可能
- ログ収集もカンタンに
Kubernetes用語に変換してみよう
先ほどの図の要素を一旦Kubernetes用語に変換しておきます。

- いい感じのシステム: Master(ControlPlaneとも)
- コンテナが配置されるサーバー: Node
- Nodeの集合: DataPlane
- MasterとDataPlaneを合わせて: Cluster
- Masterに投げる注文書: マニフェストファイル
- Masterに注文書を投げつけるやつ: kubectl
- CLIツール
- 注文書を投げつけるだけでなくいろんな操作ができる
となります。
マニフェストファイル
Kubernetesにおけるマニフェストファイルの考え方が特徴的なので取り上げておきます。
マニフェストファイルは、システムのあるべき姿を書いているファイルで、yaml(もしくはjson)で記述されます。
「宣言的設定」 ( <-> 「命令的設定」)が特徴です。
例えるなら、命令的設定は普通のそば屋さん。
ざるそば1つ注文してそばを受け取ったら、そば屋さんはその後のことには関与しません。
追加注文したいとなると、またお店の人を呼んで注文する必要があります。
Ansible、Terraform、CloudFormationといったものはコレですね。
宣言的設定はわんこそば。
わんこそばでは、お椀にそばがある状態があるべき姿で、そば屋さんはお椀を常に監視しています。
そして、そばを食べてお椀からそばがなくなると、自動で追加してくれます。
Kubernetesでは、コンテナの自動回復等、マニフェストファイルを適用したあともその内容を維持するよう動いてくれます。
つまりまとめると
- 宣言的に書いたマニフェストを
- kubectlを使ってmasterに渡すと
- 各nodeにコンテナをデプロイしたりしてくれて
- その後はいい感じに監視・維持をしてくれるやーつ
Kubernetesをローカルで試してみよう
さて、ここからハンズオンです。とりあえずやってみましょう。
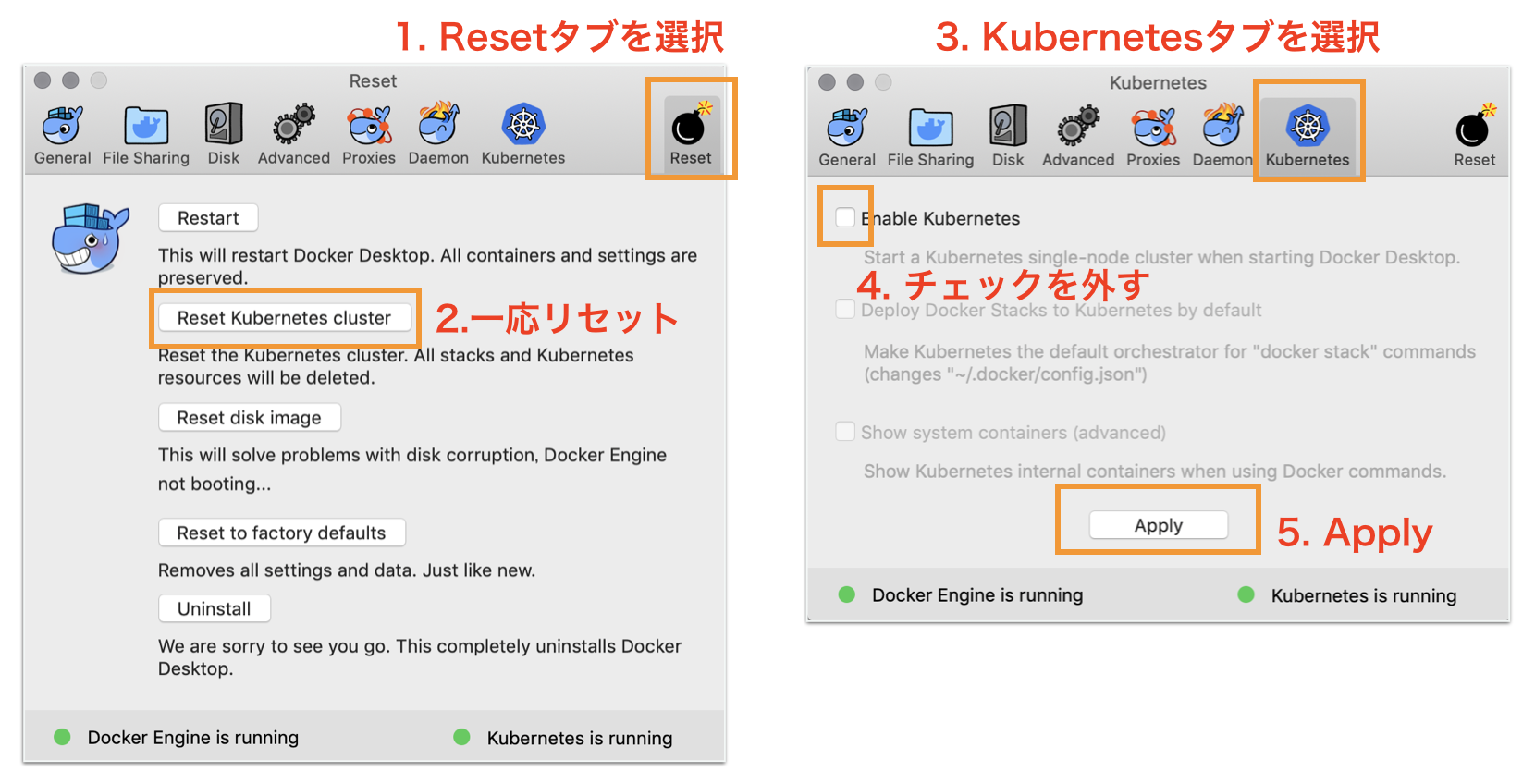
Docker for DesktopのKubernetesを有効化
Preference画面を開いて、以下のように設定しましょう。
初回は有効になるまで5分ほどかかります。

以前使ったことがある人は、Resetしておいたほうが躓かないかもしれません。

kubectlのconfig設定
kubectlで操作するKubernetesクラスターをdocker-for-desktopに
$ kubectl config use-context docker-for-desktop
ちゃんと設定されているか確認してみます。
$ kubectl config current-context
docker-for-desktop
動作確認
なんかいろいろ動いてる
$ kubectl get pods --namespace=kube-system
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system etcd-docker-for-desktop 1/1 Running 0 1m
kube-system kube-apiserver-docker-for-desktop 1/1 Running 0 1m
kube-system kube-controller-manager-docker-for-desktop 1/1 Running 0 1m
kube-system kube-dns-86f4d74b45-xb4qh 3/3 Running 0 2m
kube-system kube-proxy-8r45p 1/1 Running 0 2m
kube-system kube-scheduler-docker-for-desktop 1/1 Running 0 1m
下準備
docker-for-desktopでingress(後述)が使えるよう下準備。ローカルだけの操作なのであまり気にしなくてOK。
$ kubectl create namespace ingress-nginx
$ cat << EOF > kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
namespace: ingress-nginx
bases:
- github.com/kubernetes/ingress-nginx/deploy/cluster-wide
- github.com/kubernetes/ingress-nginx/deploy/cloud-generic
EOF
$ kubectl apply -k .
サンプルアプリをデプロイ
サンプルアプリケーションのマニフェストファイルを取ってきます。
$ git clone git@github.com:kubernetes/examples.git
Docker for DesktopのKubernetesはかなり負荷が大きいので、立てるコンテナの数を調整します。
$ vi examples/guestbook/frontend-deployment.yaml
10行目 replicas: 3 <- これを1に変更
$ vi examples/guestbook/redis-slave-deployment.yaml
11行目 replicas: 2 <- これを1に変更
デプロイ!examples/guestbook以下のマニフェストファイルをすべてデプロイします。
$ kubectl apply -f examples/guestbook/
これでサンプルアプリケーション自体は動き出しましたが、外部からアクセスするためにもうひと手間。
$ cat << 'EOT' >./guestbook-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: guestbook-ingress
spec:
rules:
- http:
paths:
- path: /
backend:
serviceName: frontend
servicePort: 80
EOT
これもデプロイします。
$ kubectl apply -f guestbook-ingress.yaml
ADDRESSがlocalhostになるまで待機します。
$ kubectl get ingress
NAME HOSTS ADDRESS PORTS AGE
guestbook-ingress * localhost 80 24m
http://localhostにアクセスするとサンプルアプリケーションの画面が出てきます。
ポートが80なんで、PCの状況によってはうまくアクセスできなかったりするかも。
http://127.0.0.1だとうまくいく場合もあるとか…。

何が起きたの?
図で表すとこんなのができています。

が、落ち着いてください。
要点を抜き出してみると、フロントエンドとRedisだけの単純なアプリです。

まずはこの図が理解できるようになりましょう。
Pod
- Kubernetesの最小デプロイ単位
- 1つ以上のコンテナとストレージボリュームの集まり
- 同一Pod内のコンテナは同一Nodeに配置される
- 「同一Nodeで動作する必要があるか?」がPod構成の一つの基準
- 1つのPod内のコンテナは同じIPアドレスとポートを使用する
- Pod内のコンテナ間の通信はプロセス間通信として行う
ReplicaSet
- 同じ仕様のPodが指定した数だけ存在するよう生成・管理する
- Podが死んだときも指定した数になるよう自動回復してくれる
- PodとReplicaSetは疎結合
- "Label"というメタデータを使って都度検索している
- 手動でPodのLabelを書き換えれば、 ReplicaSetから切り離してデバッグするといったことも可能
Deployment
- 新しいバージョンのリリースを管理するための仕組み
- ReplicaSetの変更を安全に反映させる / 世代管理する
- Podのスケール、コンテナの更新、ロールバックetc...
- 2つのDeployment戦略
- Recreate
- RollingUpdate
- ReplicaSetとDeploymentも疎結合
DeploymentのマニフェストファイルにReplicaSetとPodの情報も入れます。
(ReplicaSetやPod単体のマニフェストファイルも書けるけど、あまりやらない)
試しにサンプルアプリケーションのfrontend-deployment.yamlを見てみましょう。
redis-master-deployment.yaml, redis-slave-deployment.yamlもだいたい同じです。
apiVersion: apps/v1 # apply時に使用するAPIの種別。リソース(kind)によって決まる
kind: Deployment # Deploymentのマニフェスト
metadata:
name: frontend # Deploymentリソースの名前。「metadata.name + ランダム文字列」の名前でReplicaSetが生成される
spec:
selector:
matchLabels: # ReplicaSetがPodを検索するときのLabel
app: guestbook
tier: frontend
replicas: 1 # ReplicaSetが生成・管理するPodの数
template: # ---ここからPodの定義--------------------------------------------
metadata:
labels: # PodのLabel。ReplicaSetが管理下のPodを検索するときに使う
app: guestbook
tier: frontend
spec:
containers:
- name: php-redis # コンテナ名
image: gcr.io/google-samples/gb-frontend:v4 # コンテナイメージ
resources: # 使用するCPU, Memoryの指定
requests:
cpu: 100m
memory: 100Mi
env: # 環境変数
- name: GET_HOSTS_FROM
value: dns
ports: # EXPOSEするポートの指定
- containerPort: 80
Service
- Podの集合(主にReplicaSet)に対する経路やサービスディスカバリを提供
- クラスタ内DNSで、
<Service名>.<Namespace名>で名前解決可能に - 同じNamespace内なら
<Service名>だけでOK
- クラスタ内DNSで、
- ここでもLabelによって対象のPodが検索される
- 対象のPodが動的に入れ替わったりしても、Labelさえついていれば一貫した名前でアクセスできる
Serviceのマニフェストファイルはこんな感じです。
frontend-service.yamlはフロントエンド用、redis-*-service.yamlはバックエンド用なので、Serviceのtypeが違います。
apiVersion: v1
kind: Service # Serviceのマニフェスト
metadata:
name: frontend # Serviceリソースの名前
labels: # ServiceにつけるLabel
app: guestbook
tier: frontend
spec:
type: NodePort # Serviceの種別。NodePortはクラスタ外からアクセスできるやつ
ports:
- port: 80 # アクセスを受け付けるポート
selector: # 対象のPodを検索するときのLabel
app: guestbook
tier: frontend
apiVersion: v1
kind: Service
metadata:
name: redis-master
labels:
app: redis
role: master
tier: backend
spec:
# 省略されているけどtypeはデフォルトの"ClusterIP"。クラスタ上の内部IPアドレスにServiceを公開
ports:
- port: 6379
targetPort: 6379
selector:
app: redis
role: master
tier: backend
Ingress
- Serviceをクラスタ外に公開
- NodePortタイプのServiceと違い、パスベースで転送先のServiceを切り替えるといったことも可能
- Service(NodePort) : L4層レベルでの制御
- Ingress : L7層レベルでの制御
クラウド上でやる場合は、ServiceのtypeにLoadbalancerを指定して各クラウドのロードバランサーを使うので、
あんまり出番が無いかも。
とりあえず先ほど使ったguestbook-ingress.yamlはこんな感じです。
apiVersion: extensions/v1beta1
kind: Ingress # Ingressのマニフェスト
metadata:
name: guestbook-ingress # Ingressリソースの名前
spec:
rules: # ルーティングのルールの配列
- http:
paths:
- path: /
backend: # "frontend"Serviceの80番ポートにアクセス
serviceName: frontend
servicePort: 80
中を覗いてみよう
構成がわかったところで、次は中がどうなっているのか覗いてみましょう。
kubectl get [リソースタイプ]で一覧、kubectl describe [リソースタイプ] [リソース名]で詳細が確認できます。
Deployment
Deoloyment一覧 ("-o wide"は詳細を見るためのオプション)
$ kubectl get deploy -o wide
NAME (略) SELECTOR
frontend ... app=guestbook,tier=frontend
redis-master ... app=redis,role=master,tier=backend
redis-slave ... app=redis,role=slave,tier=backend
SELECTORの項目に出ているのは、ReplicaSetを検索するためのセレクタです。
DeploymentとReplicaSetは疎結合だと先ほど書きましたが、こういうことです。
手元で検索する場合は以下のようにします。
$ kubectl get rs -l app=guestbook,tier=frontend
Deployment詳細 (長いので手元で見て!)
$ kubectl describe deploy frontend
ReplicaSet
ReplicaSet一覧
$ kubectl get rs -o wide
NAME (略) SELECTOR
frontend-5c548f4769 ... app=guestbook,pod-template-hash=1710490325,tier=frontend
redis-master-55db5f7567 ... app=redis,pod-template-hash=1186193123,role=master,tier=backend
redis-slave-584c66c5b5 ... app=redis,pod-template-hash=1407227161,role=slave,tier=backend
名前がDeployment名 + ランダム文字列になっていますね。
また、SELECTORにpod-template-hashというものが入っています。RollingUpdateなどで同じtemplateのPodを管理するReplicaSetが複数混在しても大丈夫なように固有値のLabelをKubernetesが自動で入れています。
ReplicaSet詳細 (長いので手元で見て!)
$ kubectl describe rs frontend-5c548f4769
Pod
Pod一覧
$ kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
frontend-5c548f4769-xhpxz 1/1 Running 0 1d 10.1.1.65 docker-for-desktop
redis-master-55db5f7567-2n4qp 1/1 Running 0 1d 10.1.1.67 docker-for-desktop
redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1d 10.1.1.66 docker-for-desktop
今度は名前がReplicaSet名 + ランダム文字列になっていますね。
Pod詳細 (長いので手元で見て!)
設定や起動日時、状態、イベント等確認できます
$ kubectl describe pod frontend-5c548f4769-xhpxz
Podはログも見れます(長いので手元で見て!)
$ kubectl logs frontend-5c548f4769-xhpxz
Service
Service一覧
$ kubectl get svc -o wide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
frontend NodePort 10.102.204.76 <none> 80:30590/TCP 1d app=guestbook,tier=frontend
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 1d <none>
redis-master ClusterIP 10.98.133.213 <none> 6379/TCP 1d app=redis,role=master,tier=backend
redis-slave ClusterIP 10.107.141.173 <none> 6379/TCP 1d app=redis,role=slave,tier=backend
frontendだけtypeがNodePortなので、外部にポートが開かれています。
先ほどはIngressを立ててアクセスしましたが、実はlocalhost:30590(ポート番号は都度変わります)でもアクセスできます。
ただし、ServiceなのでL4制御です。
Service詳細 (長いので手元で見て!)
$ kubectl describe svc frontend
Ingress
Ingress一覧
$ kubectl get ing
NAME HOSTS ADDRESS PORTS AGE
guestbook-ingress * localhost 80 1d
Ingress詳細 (長いので手元で見て!)
$ kubectl describe ing guestbook-ingress
スケールさせてみよう
frontendのPodを2つに増やしてみます。
$ vi examples/guestbook/frontend-deployment.yaml
10行目 replicas: 1 <- これを2に変更
デプロイ
$ kubectl apply -f examples/guestbook/frontend-deployment.yaml
増えてる!
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
frontend-5c548f4769-vltkv 1/1 Running 0 15s
frontend-5c548f4769-xhpxz 1/1 Running 0 1d
redis-master-55db5f7567-2n4qp 1/1 Running 0 1d
redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1d
自動回復させてみよう
意図的にPodを削除してみます。
先ほど増えた2つめのPodを削除してみましょう。
$ kubectl delete pod frontend-5c548f4769-vltkv
しばらくすると新しいpodができています!
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
frontend-5c548f4769-ns5q2 1/1 Running 0 8s
frontend-5c548f4769-xhpxz 1/1 Running 0 1d
redis-master-55db5f7567-2n4qp 1/1 Running 0 1d
redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1d
Deploymentのデプロイ管理っぷりを見てみよう
Podの変更が起こらないと履歴が記録されない(スケールじゃダメ)ので、試しに使用メモリを変えてみます。
$ vi examples/guestbook/frontend-deployment.yaml
23行目 memory: 100Mi <- これを120Miに変更
デプロイ
$ kubectl apply -f examples/guestbook/frontend-deployment.yaml
徐々に切り替わっていきます。
# 徐々に切り替わっている!
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
frontend-5c548f4769-ns5q2 1/1 Running 0 11m
frontend-5c548f4769-xhpxz 1/1 Running 0 1d
frontend-68dd74b969-ztcdw 0/1 ContainerCreating 0 5s
redis-master-55db5f7567-2n4qp 1/1 Running 0 1d
redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1d
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
frontend-5c548f4769-xhpxz 1/1 Running 0 1d
frontend-68dd74b969-6shhj 0/1 ContainerCreating 0 6s
frontend-68dd74b969-ztcdw 1/1 Running 0 21s
redis-master-55db5f7567-2n4qp 1/1 Running 0 1d
redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1d
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
frontend-68dd74b969-6shhj 1/1 Running 0 26s
frontend-68dd74b969-ztcdw 1/1 Running 0 41s
redis-master-55db5f7567-2n4qp 1/1 Running 0 1d
redis-slave-584c66c5b5-z2fvj 1/1 Running 0 1d
Deploymentで管理している履歴を見てみましょう。
$ kubectl rollout history deployments frontend
deployment.extensions/frontend
REVISION CHANGE-CAUSE
1 <none>
2 <none>
REVISIONの数値が大きいほうが新しいものです。
CHANGE-CAUSEはマニフェストファイルに"Annotation"と呼ばれる情報を付け加えると出てきますが、今回は気にしないことにします。
REVISION=2の詳細を見てみます(長いので手元で見て!)
$ kubectl rollout history deployments frontend --revision=2
リビジョンを戻してみましょう。
今回リビジョンを指定していますが、1つ前に戻るときは"--to-revision"は省略できます。
$ kubectl rollout undo deployments frontend --to-revision=1
もう一度履歴を見ると、REVISION=1が消えています。
ロールバックでもリビジョンは積まれますが、同内容のリビジョンは履歴から消えます。
$ kubectl rollout history deployments frontend
deployment.extensions/frontend
REVISION CHANGE-CAUSE
2 <none>
3 <none>
ところでMasterって何やってるの?
Masterも結局Podの集まりです。
kube-systemのnamespaceの中にMasterに属するPodが。
$ kubectl get pods --namespace=kube-system
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system etcd-docker-for-desktop 1/1 Running 0 1m
kube-system kube-apiserver-docker-for-desktop 1/1 Running 0 1m
kube-system kube-controller-manager-docker-for-desktop 1/1 Running 0 1m
kube-system kube-dns-86f4d74b45-xb4qh 3/3 Running 0 2m
kube-system kube-proxy-8r45p 1/1 Running 0 2m
kube-system kube-scheduler-docker-for-desktop 1/1 Running 0 1m
etcd
- クラスタ内のさまざまなデータを保存している一貫性のある高可用性のKVS
kube-apiserver
- クラスタに対する全ての操作を司るAPIサーバー
- 認証や認可の処理なども行う
kube-scheduler
- PodのNodeへの割り当てを行うスケジューラー
- Podを配置するNodeの選択も行う
kube-controller-manager
- 各種Kubernetesオブジェクトのコントローラーを起動し管理するマネージャー
NodeにもMasterと連携するものが入っています。
kubelet
- Nodeのメイン処理であるPodの起動・管理を行うエージェント
kube-proxy
- Serviceが持つ仮想的なIPアドレス(ClusterIP)へのアクセスをルーティングする
図に表すとこんな感じになります。

お片付け
guestbookアプリケーションを削除
$ kubectl delete -f examples/guestbook/
しばらくすると削除される
$ kubectl get pod
No resources found.
Docker for DesktopのKubernetesを無効化
EKSでクラスタを作ってみよう
EKSとは
- 複数AZでmasterを冗長構成して実行
- masterの監視・自動回復
- 自動アップグレード・パッチ適用
- 他のAWSサービスとの統合
- DataPlane(EC2)は自前で用意する必要がある
- ざっくり費用感 : $144/月 (2019/04現在・東京リージョン : EC2費用は別途)

クラスタを作ってみよう!
…とは言いつつ今回は手順を確認するだけでよいかと思います。
本来どんな手順が必要なのかは知っておくといいけど、もっといいやり方があるので実際にやるのは時間がもったいないので。
スライドには手順も書いているので、やってみたい方はそちらを参照。
もっといいやり方
eksctl
- 非公式・デファクトスタンダード
- https://eksctl.io/
- コマンド一つでクラスタ構築
クイックスタート
- 公式・最近出た
- https://aws.amazon.com/jp/quickstart/architecture/amazon-eks/
- https://dev.classmethod.jp/cloud/aws/eks-quickstart/
- Cfnを使ってクラスタ構築
- ベストプラクティスに従っているので結構豪華な構成
eksctlを使ってみよう
eksctlとは
- コマンド一つでEKSのClusterができちゃうツール
- CloudFormationのテンプレートを自動生成して構築してる
- nodeのオートスケーリングなど、便利な機能も
- とはいえまだ発展途上
- ロゴを見てみると分かると思いますが、goでできています

やってみよう!
コマンド1つでクラスタができます!
$ eksctl create cluster \
--name eksctl-handson \
--region ap-northeast-1 \
--nodes 3 \
--nodes-min 3 \
--nodes-max 3 \
--node-type t2.medium \
--ssh-public-key <キーペア名>
ただし構築完了まで15分ぐらいかかります…
ap-northeast-1bが選択できる古いAWSアカウントはAZ指定も必要です。
その他のオプションはヘルプを参照してください。
$ eksctl create cluster -h
構築が完了すると、以下のような感じになります。

とりあえずデプロイしよう
git cloneしてきた内容をもとに戻します。
$ cd examples
$ git reset --hard
$ cd ../
frontend-serviceのタイプをLoadBalancerに変更します。
クラウドのロードバランサー(ここではELB)と連携するタイプです。
$ vi examples/guestbook/frontend-service.yaml
9-13行目
# comment or delete the following line if you want to use a LoadBalancer
type: NodePort <- ここをコメントアウト
# if your cluster supports it, uncomment the following to automatically create
# an external load-balanced IP for the frontend service.
# type: LoadBalancer <- ここをアンコメント
apply!
$ kubectl apply -f examples/guestbook/
しばらくすると構築が完了します。
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/frontend-56f7975f44-2vtbr 1/1 Running 0 8s
pod/frontend-56f7975f44-j25zn 1/1 Running 0 8s
pod/frontend-56f7975f44-mss7q 1/1 Running 0 8s
pod/redis-master-6b464554c8-wrjrp 1/1 Running 0 8s
pod/redis-slave-b58dc4644-ft2fd 1/1 Running 0 7s
pod/redis-slave-b58dc4644-p59fk 1/1 Running 0 7s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/frontend LoadBalancer 10.100.61.11 xxxxxx.ap-northeast-1.elb.amazonaws.com 80:31673/TCP 8s
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 23m
service/redis-master ClusterIP 10.100.137.217 <none> 6379/TCP 7s
service/redis-slave ClusterIP 10.100.217.57 <none> 6379/TCP 7s
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/frontend 3 3 3 3 8s
deployment.apps/redis-master 1 1 1 1 8s
deployment.apps/redis-slave 2 2 2 2 7s
NAME DESIRED CURRENT READY AGE
replicaset.apps/frontend-56f7975f44 3 3 3 8s
replicaset.apps/redis-master-6b464554c8 1 1 1 8s
replicaset.apps/redis-slave-b58dc4644 2 2 2 7s
service/frontendのEXTERNAL-IPにELBのドメインがついているので、そこにアクセスしてみましょう。
ダッシュボードを入れてみよう
ダッシュボード用のPodをapply
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
ダッシュボードにログインするためのトークンを取得
$ aws-iam-authenticator token -i eksctl-handson | jq -r '.status.token'
プロキシ経由でダッシュボードにアクセス
$ kubectl proxy --port=8000 --address='0.0.0.0' --disable-filter=true
http://localhost:8000/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy/にアクセスすると、ダッシュボードのログイン画面になります。トークンを入力してログインしましょう。


ログを収集してみよう
KubernetesのログをCloudWatchLogsに入れてみます。
CloudWatch Container Insights
が、ハンズオン実施後に「CloudWatch Container Insights」が発表されました。
ログやメトリクスを取得してくれるマネージドサービスです。
まだパブリックプレビューですが、AWSを使う場合はコレがスタンダードになると思われます。
https://dev.classmethod.jp/cloud/aws/cloudwatch-container-insights/
とりあえずここではDaemonSetの概念が出てくるので従来の手順を書いておきます。
Dockerコンテナのログ
Dockerコンテナでは、標準出力がログとして扱われます。ログはデフォルトでjson型式のファイルになります。
今回は各NodeにfluentdのPodを置き、Node内のPodが出力したログファイルを収集してCloudWatchに送ります。

DaemonSet
さて、ReplicaSetでPodを配置するときは、Nodeの選択はできませんでした。Kubernetesがよしなにやってくれます。
今回のように各Nodeに1つずつPodを起きたいときは、DaemonSetを使います。

ということでやってみましょう。
デプロイ
NodeのEC2に紐付いているIAM Roleの名前を取得
$ INSTANCE_PROFILE_NAME=$(aws iam list-instance-profiles | jq -r '.InstanceProfiles[].InstanceProfileName' | grep nodegroup)
$ ROLE_NAME=$(aws iam get-instance-profile --instance-profile-name $INSTANCE_PROFILE_NAME | jq -r '.InstanceProfile.Roles[] | .RoleName')
IAM Roleにログ収集用のインラインポリシーを追加
$ cat << "EoF" > ./k8s-logs-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Action": [
"logs:DescribeLogGroups",
"logs:DescribeLogStreams",
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "*",
"Effect": "Allow"
}
]
}
EoF
$ aws iam put-role-policy --role-name $ROLE_NAME --policy-name Logs-Policy-For-Worker --policy-document file://k8s-logs-policy.json
fluentdのマニフェストファイルを取得
$ wget https://eksworkshop.com/intermediate/230_logging/deploy.files/fluentd.yml
クラスタ名を変更
$ vi fluentd.yml
197行目
value: us-east-1 <- ap-northeast-1 に変更
199行目
value: eksworkshop-eksctl <- eksctl-handson に変更
fluentdをデプロイ
$ kubectl apply -f fluentd.yml
しばらくするとCloudWatchにログが上がってきます。

マニフェストファイルを見てみる
fluentd.yamlを見てみると、DaemonSetが設定されているのが分かりますね。
(略)
---
apiVersion: extensions/v1beta1
kind: DaemonSet # DaemonSetのマニフェスト
metadata:
name: fluentd-cloudwatch
namespace: kube-system
labels:
k8s-app: fluentd-cloudwatch
spec:
template: # ---ここからPodの定義--------------------------------------------
metadata:
labels:
k8s-app: fluentd-cloudwatch
spec:
serviceAccountName: fluentd
terminationGracePeriodSeconds: 30
# Because the image's entrypoint requires to write on /fluentd/etc but we mount configmap there which is read-only,
# this initContainers workaround or other is needed.
# See https://github.com/fluent/fluentd-kubernetes-daemonset/issues/90
initContainers:
- name: copy-fluentd-config
image: busybox
command: ['sh', '-c', 'cp /config-volume/..data/* /fluentd/etc']
volumeMounts:
- name: config-volume
mountPath: /config-volume
- name: fluentdconf
mountPath: /fluentd/etc
(略)
Helmを使ってみよう
Helmとは
- Kubernetes用のパッケージ管理ツール
- パッケージは"Chart"と呼ばれ、マニフェストファイルのテンプレートが含まれる
- "Tiller"と呼ばれるサーバーアプリケーション(これもPod)を介してクラスタ内にパッケージをインストール
- ちなみに"helm"は兜ではなく船の舵、"chart"は海図、"tiller"は舵柄の意味

Role-Based Access Control (RBAC)
- Kubernetesの権限制御の仕組み
- Kubernetesのリソースへのアクセスをロールによって制御
- ユーザーとロールをBindingによって紐付けることによって機能する
- ユーザー種別
- 認証ユーザー・グループ : クラスタ外からKubernetes APIを操作するためのユーザー
- ServiceAccount : PodがKubernetes APIを操作するためのユーザー
- ロール種別
- Role : 指定のnamespace内でのみ有効
- ClusterRole : クラスタ全体で有効
- HelmにもRBACを有効にできるChartが多く管理されている

Helmのインストール
- https://helm.sh/docs/using_helm/#installing-helm
- Macの場合
brew install kubernetes-helm
Tiller用のサービスアカウントのマニフェストファイルを作成
"cluster-admin"はデフォルトで存在するClusterRole
$ cat <<EoF > tiller_rbac.yaml
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: tiller
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: tiller
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: tiller
namespace: kube-system
EoF
Tiller用のサービスアカウントを作成
$ kubectl apply -f tiller_rbac.yaml
Tillerのサービスアカウントを指定してクラスタにHelmを導入
これでTillerのPodがkube-systemネームスペースにデプロイされる
$ helm init --service-account tiller
Jenkinsをインストール
CustomValueファイルを作成
パラメーター詳細は "helm inspect values stable/jenkins" で確認
$ cat <<EoF > jenkins.yaml
rbac:
create: true
master:
service_port: 8080
persistence:
size: 1Gi
EoF
Jenkinsをインストール
$ helm install -f jenkins.yaml --name jenkins stable/jenkins
しばらくするとデプロイ完了(2-3分ぐらい)
$ kubectl get all
NAME READY STATUS RESTARTS AGE
pod/jenkins-f65b9477-89s69 1/1 Running 0 33m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/jenkins LoadBalancer 10.100.22.208 xxxxxx.ap-northeast-1.elb.amazonaws.com 8081:30196/TCP 33m
service/jenkins-agent ClusterIP 10.100.58.26 <none> 50000/TCP 33m
service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 2h
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
deployment.apps/jenkins 1 1 1 1 33m
NAME DESIRED CURRENT READY AGE
replicaset.apps/jenkins-f65b9477 1 1 1 33m
パスワード取得(インストール時のログに取得方法が書いているやつ)
$ printf $(kubectl get secret --namespace default jenkins -o jsonpath="{.data.jenkins-admin-password}" | base64 --decode);echo
XXXXXXXX
ログインURL取得(インストール時のログに取得方法が書いているやつ)
$ export SERVICE_IP=$(kubectl get svc --namespace default jenkins --template "{{ range (index .status.loadBalancer.ingress 0) }}{{ . }}{{ end }}")
$ echo http://$SERVICE_IP:8080/login
http://xxxxxx.ap-northeast-1.elb.amazonaws.com:8080/login
アクセスしてログインすると以下のような画面になります。
username : admin
password : コマンドで取得したやつ

Jenkinsをアンインストール
--purgeはオプション。付けない場合、リビジョンの記録が残り、ロールバックができる
$ helm delete --purge jenkins
監視できるようにしてみよう
これも「CloudWatch Container Insights」に置き換わるのではないかと思いますが、一応書いておきます。
今回はPrometheus/Grafanaを利用します。
- Prometheus
- OSSのリソース監視ツール
- 導入がカンタン、いい感じに通知くれる、高性能などで人気が高い
- ただ、データの可視化が本業ではないので力不足
- Grafana
- OSSのログ・データ可視化ツール
- Prometheusが収集したデータをかっこよく表示できる
Prometheusをインストール
CustomValueファイルを作成
パラメーター詳細は "helm inspect values stable/prometheus" で確認
$ cat <<EoF > prometheus.yaml
alertmanager:
persistentVolume:
size: 1Gi
storageClass: "gp2"
server:
persistentVolume:
size: 1Gi
storageClass: "gp2"
retention: "12h"
pushgateway:
enabled: false
EoF
Prometheusをインストール
$ kubectl create namespace prometheus
$ helm install -f prometheus.yaml --name prometheus --namespace prometheus stable/prometheus
デプロイが完了したらアクセスしてみる(立ち上がるまで数分かかる)
以下はインストール時のログに出てくるやつ
$ export POD_NAME=$(kubectl get pods --namespace prometheus -l "app=prometheus,component=server" -o jsonpath="{.items[0].metadata.name}")
$ kubectl --namespace prometheus port-forward $POD_NAME 9090
http://localhost:9090/targetsにアクセスすると、Prometheusの画面が確認できます。

Grafanaをインストール
CustomValueファイルを作成
パラメーター詳細は "helm inspect values stable/grafana" で確認
$ cat <<EoF > grafana.yaml
persistence:
storageClassName: gp2
adminPassword: password
datasources:
datasources.yaml:
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
url: "http://prometheus-server.prometheus.svc.cluster.local"
access: proxy
isDefault: true
service:
type: LoadBalancer
EoF
Grafanaをインストール
$ kubectl create namespace grafana
$ helm install -f grafana.yaml --name grafana --namespace grafana stable/grafana
デプロイが完了したらアクセスしてみる(立ち上がるまで数分かかる)
以下はインストール時のログに出てくるやつ
$ export ELB=$(kubectl get svc -n grafana grafana -o jsonpath='{.status.loadBalancer.ingress[0].hostname}')
$ echo "http://$ELB"
http://xxxxxx.ap-northeast-1.elb.amazonaws.com
アクセスしてログインすると以下の画面になります。
- username : admin
- password : password (grafana.yamlに書いた)

ダッシュボードを作る
今回はImport画面から、公開されているテンプレートを導入してみましょう。
テンプレート番号は3131です。


なんだかそれっぽいのが出ました。

3146ならこんな感じになります。

お片付け
クラスタ内をお片付けしないと、eksctlでクラスタを削除するときにCloudFormationで怒られてしまうのでご注意。
PrometheusとGrafanaを削除
$ helm delete --purge prometheus
$ helm delete --purge grafana
fluentdを削除
$ kubectl delete -f fluentd.yml
ダッシュボードを削除
$ kubectl delete -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml
guestbookアプリを削除
$ kubectl delete -f examples/guestbook/
ログ収集用にIAM RoleにくっつけたPolicyを外す
$ INSTANCE_PROFILE_NAME=$(aws iam list-instance-profiles | jq -r '.InstanceProfiles[].InstanceProfileName' | grep nodegroup)
$ ROLE_NAME=$(aws iam get-instance-profile --instance-profile-name $INSTANCE_PROFILE_NAME | jq -r '.InstanceProfile.Roles[] | .RoleName')
$ aws iam delete-role-policy --role-name $ROLE_NAME --policy-name Logs-Policy-For-Worker
eksctlでクラスタを削除
途中までしか見てくれないので、AWSコンソールで本当に削除されたか確認したほうがいいです。
$ eksctl delete cluster --name eksctl-handson
(おまけ)GKEでクラスタを作ってみよう
やっぱり本家も見ておかないと、ということでちょっとだけ。
CLIやGCPプロジェクトの設定は終わっている前提です。
やってみよう
コマンド1つでNodeも含めてクラスタを作ってくれます。
なんと3分半ぐらいでできる!!
$ gcloud container clusters create gke-handson --cluster-version=1.12.7-gke.10 --machine-type=n1-standard-1 --num-nodes=3

kubectlのconfigもちゃんと変わってる!
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
docker-for-desktop docker-for-desktop-cluster docker-for-desktop
* xxxxxx_asia-northeast1-a_gke-handson xxxxxx_asia-northeast1-a_gke-handson xxxxxx_asia-northeast1-a_gke-handson
デフォルトでfluentdやprometheusが入ってる!
$ kubectl get pods --namespace=kube-system
NAME READY STATUS RESTARTS AGE
event-exporter-v0.2.3-f9c896d75-52nkr 2/2 Running 0 2m5s
fluentd-gcp-scaler-69d79984cb-zm56b 1/1 Running 0 113s
fluentd-gcp-v3.2.0-5mncb 2/2 Running 0 63s
fluentd-gcp-v3.2.0-9sdg7 2/2 Running 0 74s
fluentd-gcp-v3.2.0-t59sr 2/2 Running 0 54s
heapster-v1.6.0-beta.1-6fc8df6cb8-54qrk 3/3 Running 0 85s
kube-dns-autoscaler-76fcd5f658-22l8j 1/1 Running 0 104s
kube-dns-b46cc9485-5kspm 4/4 Running 0 92s
kube-dns-b46cc9485-j8fmn 4/4 Running 0 2m5s
kube-proxy-gke-gke-handson-default-pool-d757b1ec-9ld7 1/1 Running 0 108s
kube-proxy-gke-gke-handson-default-pool-d757b1ec-lcl8 1/1 Running 0 110s
kube-proxy-gke-gke-handson-default-pool-d757b1ec-z2m6 1/1 Running 0 110s
l7-default-backend-6f8697844f-s8lgv 1/1 Running 0 2m6s
metrics-server-v0.3.1-5b4d6d8d98-tn8cw 2/2 Running 0 87s
prometheus-to-sd-4v26j 1/1 Running 0 111s
prometheus-to-sd-k4jj7 1/1 Running 0 110s
prometheus-to-sd-mhs8h 1/1 Running 0 110s
これで3Nodeのクラスタができました。
もちろん今まで使ってきたマニフェストファイルが使えるのでデプロイしてみましょう。
$ kubectl apply -f examples/guestbook/
お片付け
削除も3分半ぐらいで終わります!!
$ gcloud container clusters delete gke-handson
kubectlのconfigもちゃんと消えています。
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
docker-for-desktop docker-for-desktop-cluster docker-for-desktop
念のため残っているリソースが無いかコンソールで確認しておくと吉。
EKSとGKE
- 柔軟性
- EKSはユーザーによるカスタマイズの幅が大きい
- でもやっぱり面倒なのでeksctlとかが誕生していたりする…
- GKEはいい感じにしてくれる
- EKSはユーザーによるカスタマイズの幅が大きい
- 立ち上がりの速さ
- EKSは(eksctl利用で)15分ぐらい
- GKEは3分半ぐらい
- 費用
- EKSはmasterに費用がかかる(東京リージョンで$144/月ぐらい)
- GKEはmasterに費用がかからない!
- どっちを選ぼう?
- 純粋にKubernetesを使いたいだけなら圧倒的にGKE
- AWSのもろもろのサービスと合わせて使いたいならEKS
その他もろもろ
紹介しなかったリソースたち
ハンズオン中に出てこなかった主要なリソースを紹介します。
Job
- 単発の処理を管理
- 指定した数だけPodを作成して処理を実行
apiVersion: batch/v1
kind: Job # Jobのマニフェスト
metadata:
name: example_job
labels:
app: example
spec:
parallelism: 3 # 同時に実行するPodの数
template: # ---ここからPodの定義--------------------------------------------
metadata:
labels:
app: example
spec:
(略)
CronJob
- 定期実行する処理を管理
- スケジュールに沿ってPodを作成して処理を実行
- コンテナ内でCronを設定しなくてよくなるので便利!
apiVersion: batch/v1beta1
kind: CronJob # CronJobのマニフェスト
metadata:
name: example_job
labels:
app: example
spec:
schedule: "*/1 * * * *" # 起動スケジュールをcronと同じ型式で定義
jobTemplate:
spec:
template: # ---ここからPodの定義--------------------------------------------
metadata:
labels:
app: example
spec:
(略)
ConfigMap
- アプリケーションの設定情報を定義してPodに提供
- 環境変数として提供
- Volumeとして提供
apiVersion: v1
kind: ConfigMap
metadata:
name: cm-example
data: # key-value型式で設定情報を書いていく
EXAMPLE: this_is_example
example.txt: |
this
is
example
# Podの定義中
(略)
env: # 環境変数として提供
- name: EXAMPLE
valueFrom:
configMapKeyRef:
name: cm-example
key: EXAMPLE
(略)
containers: # Volumeとして提供。これで /config/example.txt が扱えるようになる
- image: alpine
(略)
volumeMounts: ## コンテナ内でのVolumeのマウント設定
- name: cm-volume
mountPath: /config
volumes: ## Volumeの定義
- name: cm-volume
configMap:
name: cm-example
(略)
Secret
- アプリケーションの機密情報を定義してPodに提供
- 環境変数として提供
- Volumeとして提供
- ConfigMapとの違い
- 文字列をBase64エンコードした状態で扱う(バイナリデータを扱えるように)
- もちろん暗号化目的じゃないので、そのままGithubに上げたりしたらダメ
- (設定によって)etcd上に暗号化した状態で保存される
- NodeではPodのtmpfs(要するにメモリ)上に保存される
- Nodeは割り当てられたPodが参照するSecret以外はアクセスできない
- いくつかTypeがある
- Opaque: ConfigMapと同じ構造化されてないKey/Value形式
- kubernetes.io/tls: TLSの秘密鍵と公開鍵を格納
- kubernetes.io/service-account-token: Kubernetesのサービスアカウントのクレデンシャル
- 文字列をBase64エンコードした状態で扱う(バイナリデータを扱えるように)
apiVersion: v1
kind: Secret
metadata:
name: secret-example
stringData:
password: xxxxxxxxxxxx # Base64エンコードされた文字列
credential.txt: |
xxxxxxxxxxxxx
xxxxxxxxxxxxx
xxxxxxxxxxxxx
# Podの定義中
(略)
env: # 環境変数として提供
- name: PASSWORD
valueFrom:
secretKeyRef:
name: secret-example
key: password
(略)
containers: # Volumeとして提供。これで /secrets/credential.txt が扱えるようになる
- image: alpine
(略)
volumeMounts: ## コンテナ内でのVolumeのマウント設定
- name: secret-volume
mountPath: /secrets
volumes: ## Volumeの定義
- name: secret-volume
secret:
secretName: secret-data
(略)
ストレージ関連もろもろ
- PersistentVolume
- ストレージの実体
- AWSならNodeのEC2が持つEBS
- PersistentVolumeClaim
- ストレージを論理的に抽象化したリソース
- PersistentVolumeに対して必要な容量を動的に確保
- StorageClass
- PersistentVolumeが確保するストレージの種類を定義
- AWSなら io1/ gp2/sc1/st1
- StatefulSet
- 継続的にデータを永続化するステートフルなアプリケーションの管理に向いたリソース
- 管理下のPodには連番の識別子が付与され、再作成されても同じ識別子であれば同じストレージを参照する
クラウドでKubernetesを使うなら基本的にマネージドのDBサービス等を使うので、自分から使う機会はあまりないかも。
外部から持ってきたマニフェストファイルに書かれていたりするので、存在は知っておいてもらいたい、というぐらいです。
マニフェストファイルのフォーマットを調べる
Kubernetesの情報を本なりWebなりで見ていると、マニフェストファイルの例はたくさん出てきます。
でもパラメーターが多すぎて全部説明してくれるのはマニュアルぐらいなのでその調べ方をば。
https://qiita.com/Kta-M/items/039cee72e82590a0c4f4
運用時の基本構成イメージ
と言いつつ運用はしたことないんですが、こんな感じの構成になるはず。

まとめ
ハンズオンの目標(再掲)
- Kubernetesとお友達になる
- イメージを掴む
- 触ってみる(ローカル・EKS・ちょっとGKE)
- 構築・運用ができるような気分になる
- 巷にあふれるKubernetesの記事・スライドが理解できるようになる
とはいえ…
Kubernetesは大規模で複雑なシステムで真価を発揮するものです。
単純なものならFargateとかECSとかのほうが良かったりもします。。
場合によってはEC2を使ったレガシーな構成でも事足りるはず。
でも、数年後には
当たり前の技術になっている可能性が高いのではないかと思います。
そしてもっとカンタンに使えるようになっている可能性も十分にある!
たとえばEKSのFargate対応もあるとかないとか…。
いずれにせよ、現時点でも自分の選択肢が増えるのはいいことだよね!
というわけで
とりあえず目標が達成できていたなら幸いです😊
が、Kubernetes沼の入り口に立ったばかり。今回紹介しきれなかった用語、エコシステムなどまだ膨大に…。
俺たちの戦いはこれからだ!