概要
まとめがあると振り返りやすいなぁと思ったので、機械学習のいろいろについてまとめていこうと思ったのですが、今回はテーブルデータの機械学習手法についてまとめます。
記事としてはまだ途中ですが、随時追加していきたいと思っているので、公開しています。
(公開することで、書かなければ……と自分を追い込んでいくスタイル)
掲載している内容についてですが、以下のようになっています。
- モデルまわりメイン(そのほかの部分や細かい部分は雑に作ってます)
- プログラムメイン(理論については参考URLをご参照ください)
- ここに載せているのは、簡単な結果やモデルまわりのコードだけ(全体はgithubにのせてます→github)
- ライブラリはふんだんに使っています
また使っているバージョン等は以下のような感じです。
python: 3.8
tensorflow: 2.3
線形回帰
線形回帰とは、ざっくりというと、以下のような関数で近似して値を予測する方法です。
f(x_{0}, x_{1}, \cdots, x_{n - 1}) = a_{0} x_{0} + a_{1} x_{1} + \cdots + a_{n - 1}x_{n - 1} + b
ここでは、入力の数はn個で、出力の数は1個になっています。
これをkerasというライブラリを使って実装する場合、以下のようになります。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
n = 2
model = Sequential()
model.add(Dense(1, input_dim=n))
model.compile(optimizer='rmsprop', loss='mse')
上のコードでは、インプットとして2個入ってくる想定です。
また、数式で書いた関数に対応する部分はmodel.add(Dense(1, input_dim=n))の部分になっています。
このモデルの特徴としては、線形に予測をすることしかできないところです。
例えば、$f(x_0, x_1) = -2.1 x_0 + 0.4 x_1 - 0.5$という関数にちょっとしたノイズをのせたデータを用意して学習させると、これはちゃんと予測することができます。
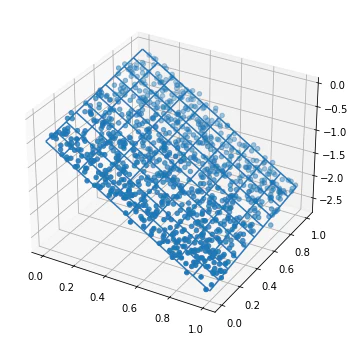
※点が実際のデータで、線が予測した値
また、以下のように重みの最終的な値を出力してみると
weights = model.get_weights()
print(weights)
# [array([[-2.104571 ],
# [ 0.4002266]], dtype=float32),
# array([-0.4965985], dtype=float32)]
となっていて、このモデルが最終的に$f(x_0, x_1) = -2.104571x_0 + 0.4002266x_1 -0.4965985$という関数として出力を出していることがわかります。
データを$f(x_0, x_1) = -2.1 x_0 + 0.4 x_1 - 0.5$をもとに作っているので、かなり近いところまで予測できています。
しかし、もしデータを例えば$f(x_0, x_1) = 10 x_0^2 + 10 x_1^2 - 0.5$のように線形でないものをもとに作成すると、このモデルでは以下のようにうまく予測することができません。
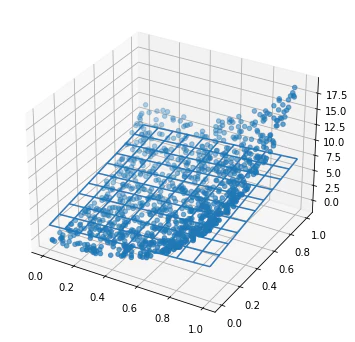
全体のコード
参考
http://kikei.github.io/ai/2017/07/28/keras3.html
ロジスティック回帰
こちらは回帰とついておきながら分類のモデルになります。
分類のモデルは、2クラス分類と多クラス分類で若干異なる部分があります。
2クラス分類では、1出力にして、例えばA or Bの分類だったら、Aである確率を出力するようにします。
確率を出力するので、値は0~1です。
また、多クラス分類は、例えばnクラスなら、それぞれのクラスである確率をもとめて、n個の要素の配列を出力としたりします。
[0.001, 0.98, \cdots, 0.012]
そのため、モデルの構成も、2クラスと多クラスでは若干異なります。
ですので、まずは2クラスの方からお話していきたいと思います。
2クラス分類
ロジスティック回帰は基本は線形回帰と同じなのですが、分類モデルなので、出力を0~1の確率にする部分が異なります。
そのため、2クラス分類の場合は、活性化関数としてシグモイド関数を通します。
f(x_{0}, x_{1}, \cdots, x_{n - 1}) = \phi(a_{0} x_{0} + a_{1} x_{1} + \cdots + a_{n - 1}x_{n - 1} + b)\\
\phi(z) = \frac{1}{1 + e^{-z}}
上の式の$\phi$がシグモイド関数で、グラフは以下のようになります。
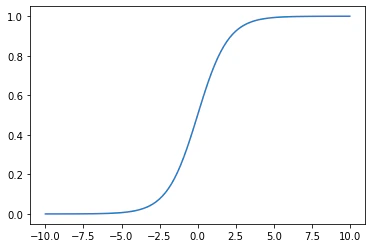
ちゃんと0~1に収まっていて、z=0のときに0.5になっていますね。
もちろん、0~1に収めたいこと以外にもこの関数にしている理由はあるのですが、そのあたりは割愛します。
今回の実装はkerasを使って以下のようにしました。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(1, input_dim=2, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
線形回帰との違いは、activationにsigmoidを入れているところです。
これで、線形回帰と同じ式である$a_{0} x_{0} + a_{1} x_{1} + \cdots + a_{n - 1}x_{n - 1} + b$のあとに、活性化関数としてシグモイド関数を通すことができます。
(ちなみにデフォルトはlinear(つまり何もしない)になっています)。
model.compileでは、線形回帰と比べると少し変わっていますが、今回はこちらの説明は割愛します。
このモデルも線形回帰と同様、線形にしか分離ができないところが特徴です。
例えば$f(x_0, x_1) = x_0 + x_1 (0 \leq x_0, x_1 \leq 1)$という関数に若干のノイズをのせて、1以上か1未満かで分類をさせたいとします。
その場合は、以下のようにうまく分類することができます。

※点が実際のデータで、青い部分と赤い部分で分類している
しかし、例えば$f(x_0, x_1) = x_0^2 + x_1^2 (-1 \leq x_0, x_1 \leq 1)$という関数に若干のノイズをのせて、1以上か1未満かで分類をすると、1本の直線ではとても分類することができないので、以下のようにだいぶ的外れな分類になってしまいます。

多クラス分類
続いて、多クラス分類の例として、3クラス分類を行います。
3クラス分類は、分類タスクの入門として有名なアヤメの品種データ(Iris plants dataset)を用いて行いたいと思います。
このデータセットについては詳しくはこちらの記事がとてもわかりやすかったです。
多クラス分類では最初に述べたように確率の配列を出力する必要があるため、シグモイド関数の代わりにソフトマックス関数を使います。
実装は以下のようにしました。
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential()
model.add(Dense(3, input_dim=2, activation='softmax'))
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
2クラス分類のときとの変更点は、activationをsoftmaxにしたことと、出力を3にしたこと、そしてlossをcategorical_crossentropyにしたことです。
アヤメのデータセットは3クラスに分かれているため出力は3になっています。
また、アヤメのデータセットは4つの特徴量を持っていますが、今回は2つだけ使用しました。
lossには損失関数を設定するのですが、今回は損失関数については説明を省きます。
(基本的に2クラス分類にはbinary_crossentropyを、多クラス分類にはcategorical_crossentropyを設定します)
そしてソフトマックス関数についてですが、ソフトマックス関数は以下のような関数です。(以下の式は i 番目のクラスの予測値)
f_i(x_{0}, x_{1}, \cdots, x_{n - 1}) = \frac{e^{x_i}}{\sum_{k=0}^n e^{x_k}}
ソフトマックス関数は、各クラスに対する予測値を足し上げるとちゃんと1になり、出力結果をそれぞれのクラスである確率として解釈することができます。
また、今回の例でいうと出力が3つのため、それぞれの出力用に3つの多項式があり、それぞれがソフトマックス関数を通ることになります。
g_i(x_{0}, x_{1}, \cdots, x_{n - 1}) = a_{0} x_{0} + a_{1} x_{1} + \cdots + a_{n - 1}x_{n - 1} + b\\
f_i(g_{0}, g_{1}, \cdots, g_{n - 1}) = \frac{e^{g_i}}{\sum_{k=0}^n e^{g_k}}
最後に分類結果をのせます。
おおよそ分類できていますが、特徴量を2つに絞っているのもあって直線では分類しきれない部分がありますね。

全体のコード
参考
https://aidiary.hatenablog.com/entry/20161030/1477830597
https://www.yakupro.info/entry/ml-multi-logisticregression
Python機械学習プログラミング
終わりに
ということで、まだ2つだけですが、随時追加していく予定です。