サーバレスアーキテクチャの遍歴
サーバレス界隈のre:invent 2024の一番大きなアップデートはAmazon Aurora DSQL(この先はDSQLで省略します。)ではないでしょうか?
データベースを中心に過去のアーキテクチャから振り返り、DSQLでどうゆうことが便利になるかを振り返りたいと思います。
第1期
サーバレスの当初はAmazon DynamoDBまたはAWS S3の選択肢ありませんでした。リレーショナルなデータを保持したい場合はアプリケーション側で工夫が必要でした。

第2期
Amazon Elasticsearch Service(Amazon OpenSearch Service)が選択肢に増えて検索の柔軟性が向上しました。ただ選択肢としては以前NoSQLベースのデータベースしかない状況です。

第3期
Amazon Aurora Serverlessがリリースされて、データベースとしての制約は撤廃されたと思いますが、Amazon Aurora ServerlessはVPCが必要となり第2期までのように、ネットワークを意識しない構成にするのは困難でした。

第4期
DSQLを活用することでネットワークを意識しない構成で作成することが可能になります。
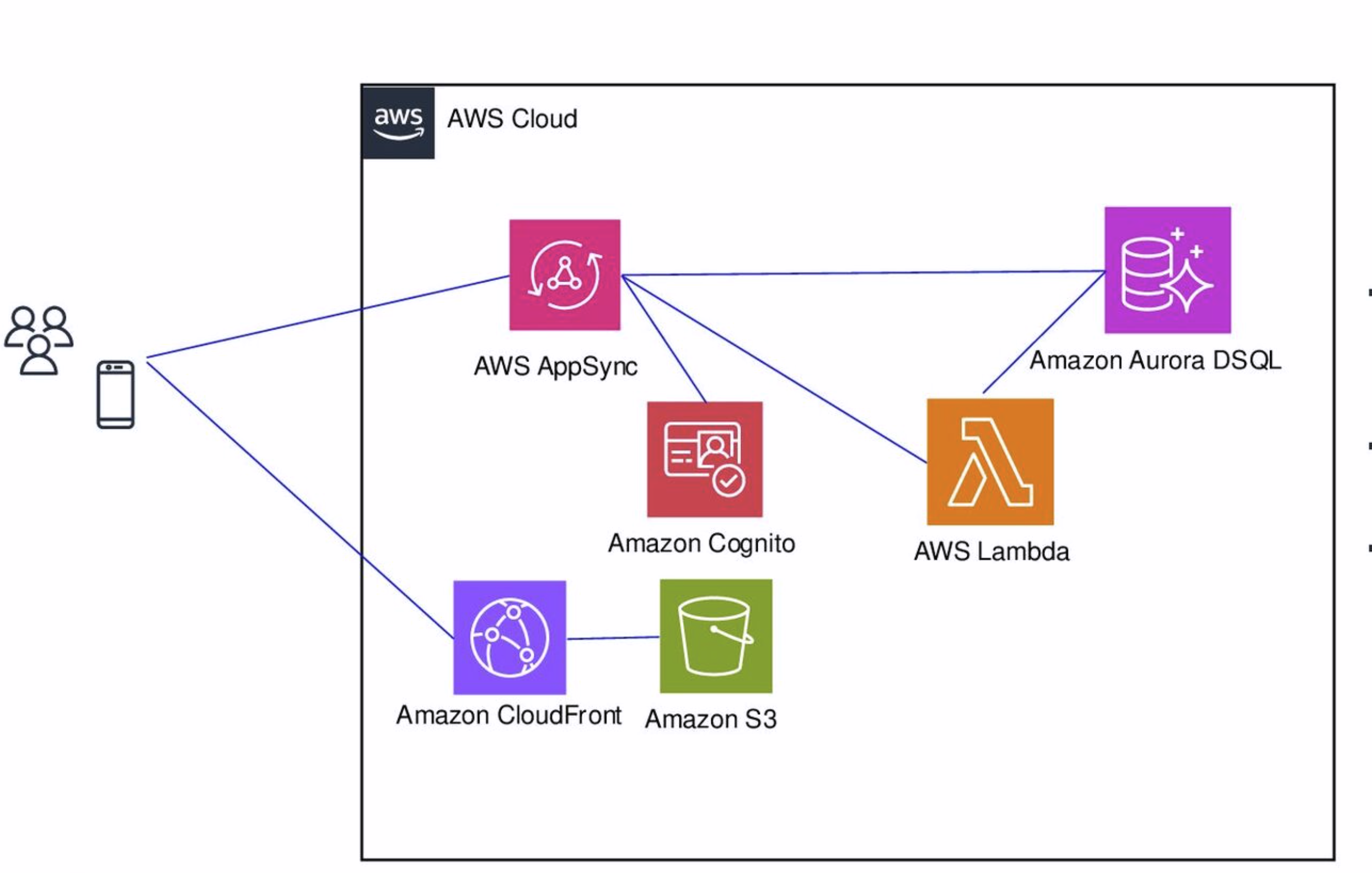
ついに東京リージョンにきましたのでAppSyncと繋げて第4期のアーキテクチャを実現させてみたいと思います。(2025年6月4日時点ではシングルリージョンでしか使えないので注意してください)
DSQLとAppSyncを繋げてみる
Amazon API GatewayとAWS Lambdaの組み合わせでも、構築は可能ですが、あえてAppSyncと組みあせたいと思います。
本来AWS AppSyncはRDSと接続が可能です。その辺は去年記載していますので確認を、現状はその機能が使えないので、Lambda経由で繋げて、登録検索を行ってみたいと思います。
DSQLを作成する
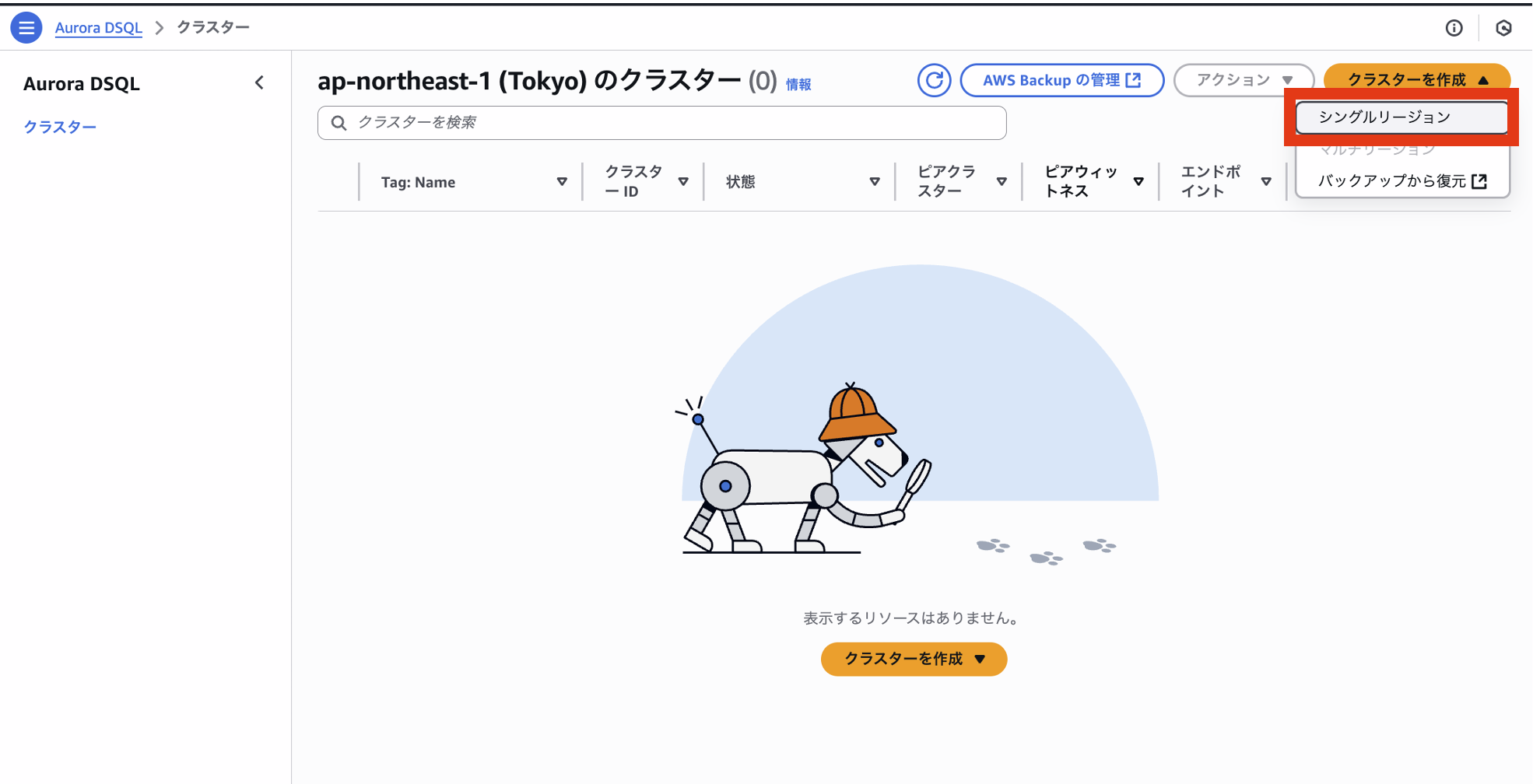
マネージメントコンソールからDSQLを選択します。

クラスタの作成から、シングルリージョンを選択します。
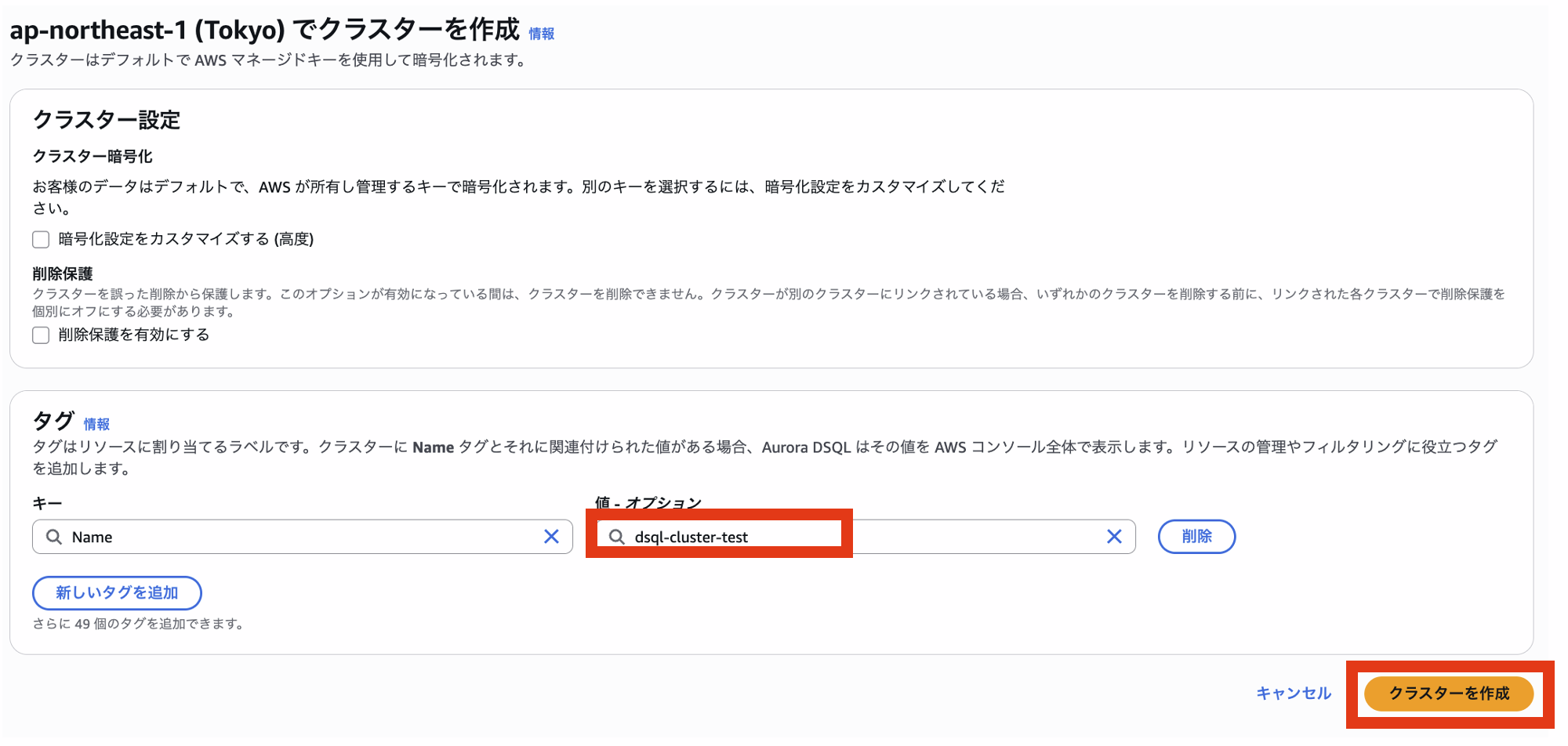
あとはNameを任意の値に変更していただいてクラスターの作成ボタンを押下するだけでAuroraが起動します。RDSの作成に比べてネットワークや、オプションなども考慮不要で作成できるのは大きなポイントかと思います。
テーブル定義は今回は下記とします。
※DSQLではSERIALが使えないので注意してください。
また考え方としては、主キーは分散することが大事になりますので、設計するときは注意してください。
-- DSQLでのテーブル作成SQL
CREATE TABLE items (
id UUID PRIMARY KEY DEFAULT gen_random_uuid(),
name VARCHAR(100) NOT NULL,
updated_at TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP
);
-- サンプルデータ挿入
INSERT INTO items (name) VALUES
('りんご'),
('バナナ'),
('メロン');
下記手順でテーブルの作成と初期データを設定します。
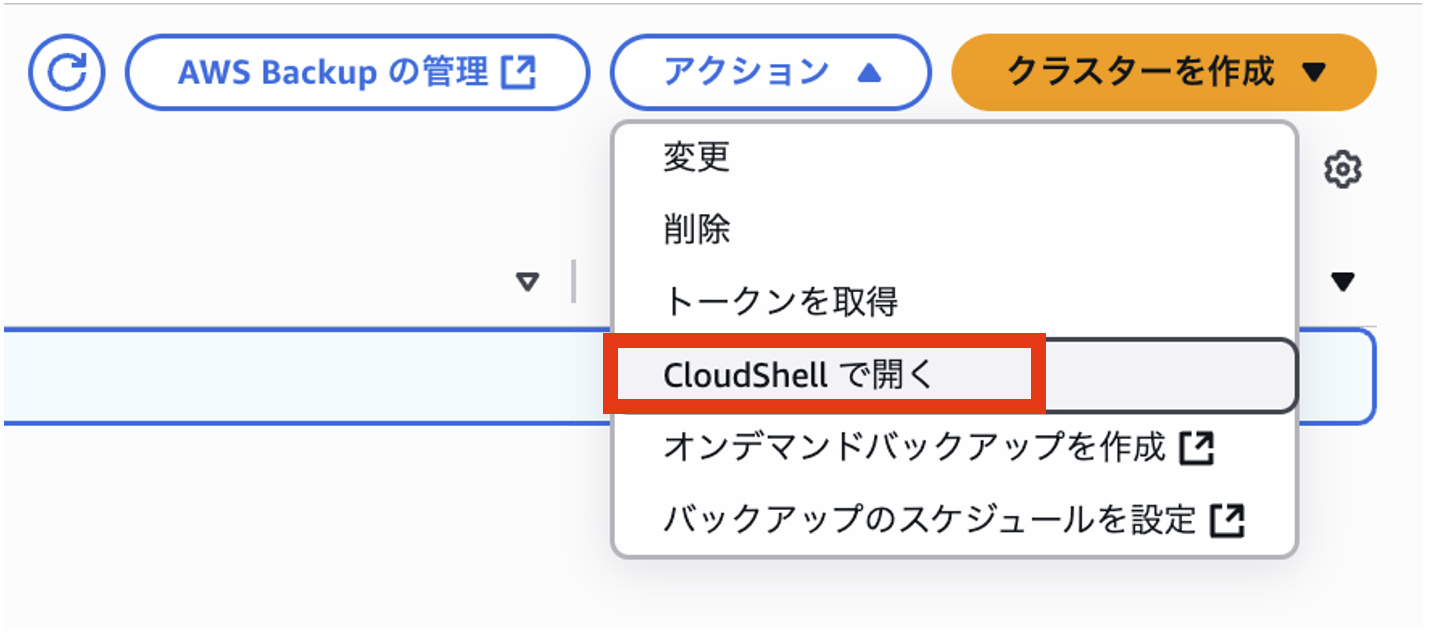
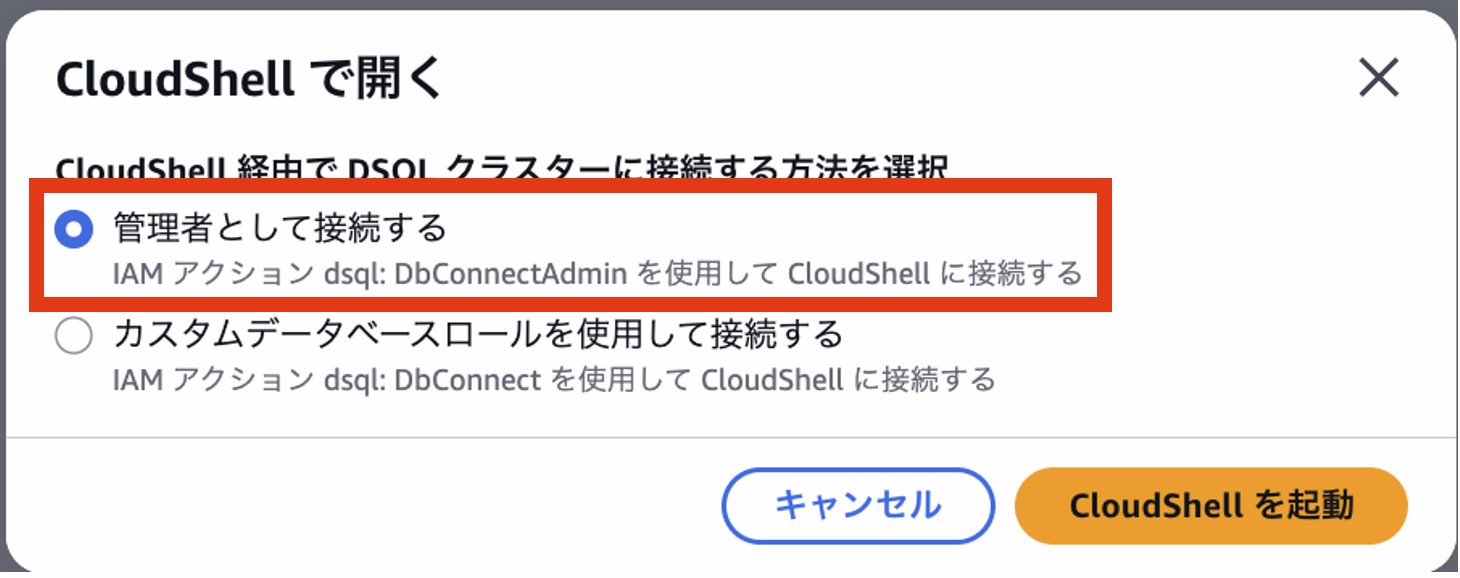
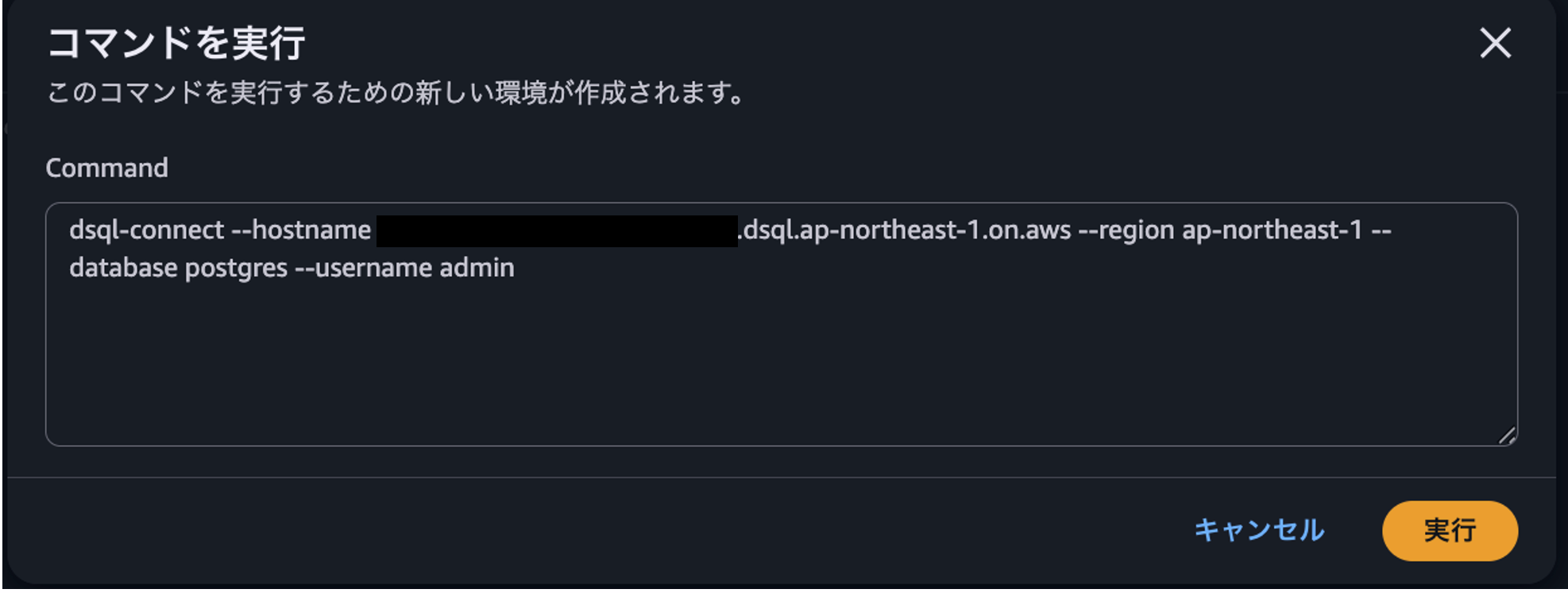
先ほどのテーブル定義を流し込みデータが格納されたことを確認します。
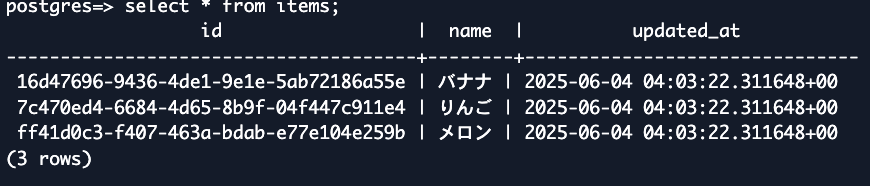
select * from items;
Lambdaを作成する
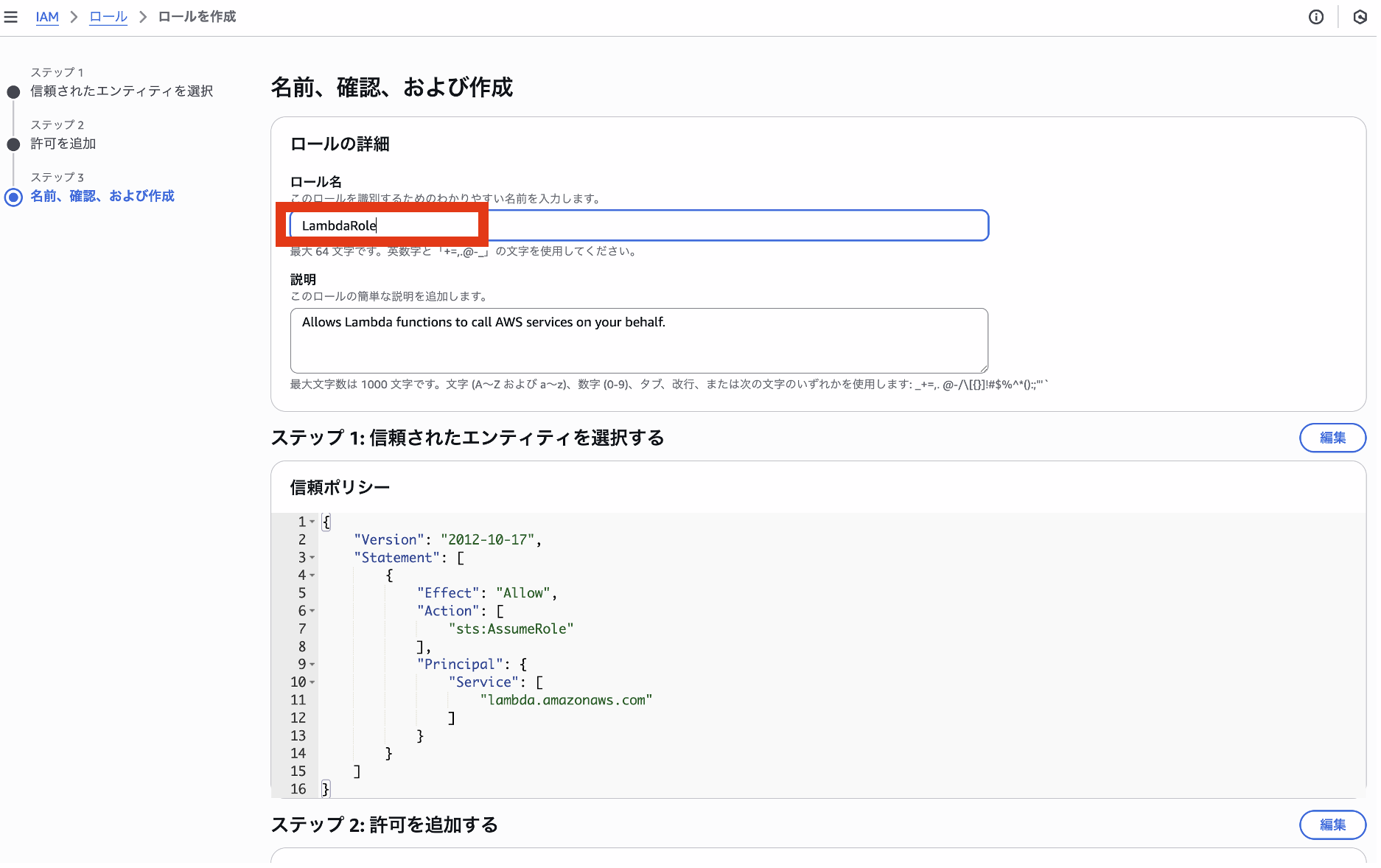
まずは必要なロールを作成します。


作成したロールにDSQLのアクセス権限を追加で付与します。
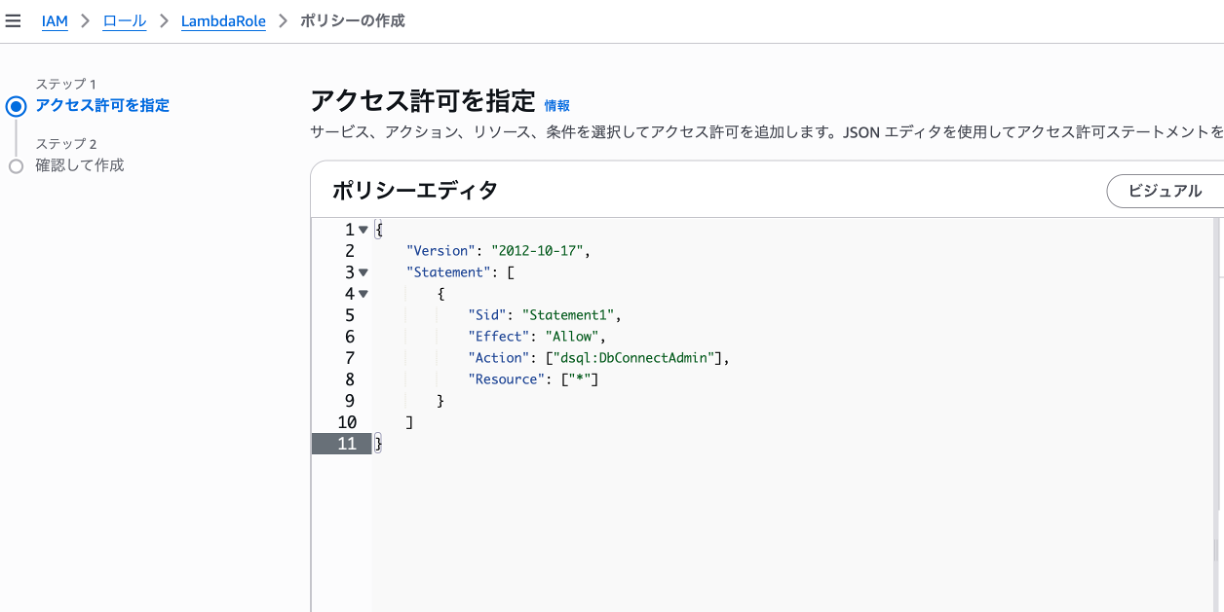
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "Statement1",
"Effect": "Allow",
"Action": ["dsql:DbConnectAdmin"],
"Resource": ["*"]
}
]
}
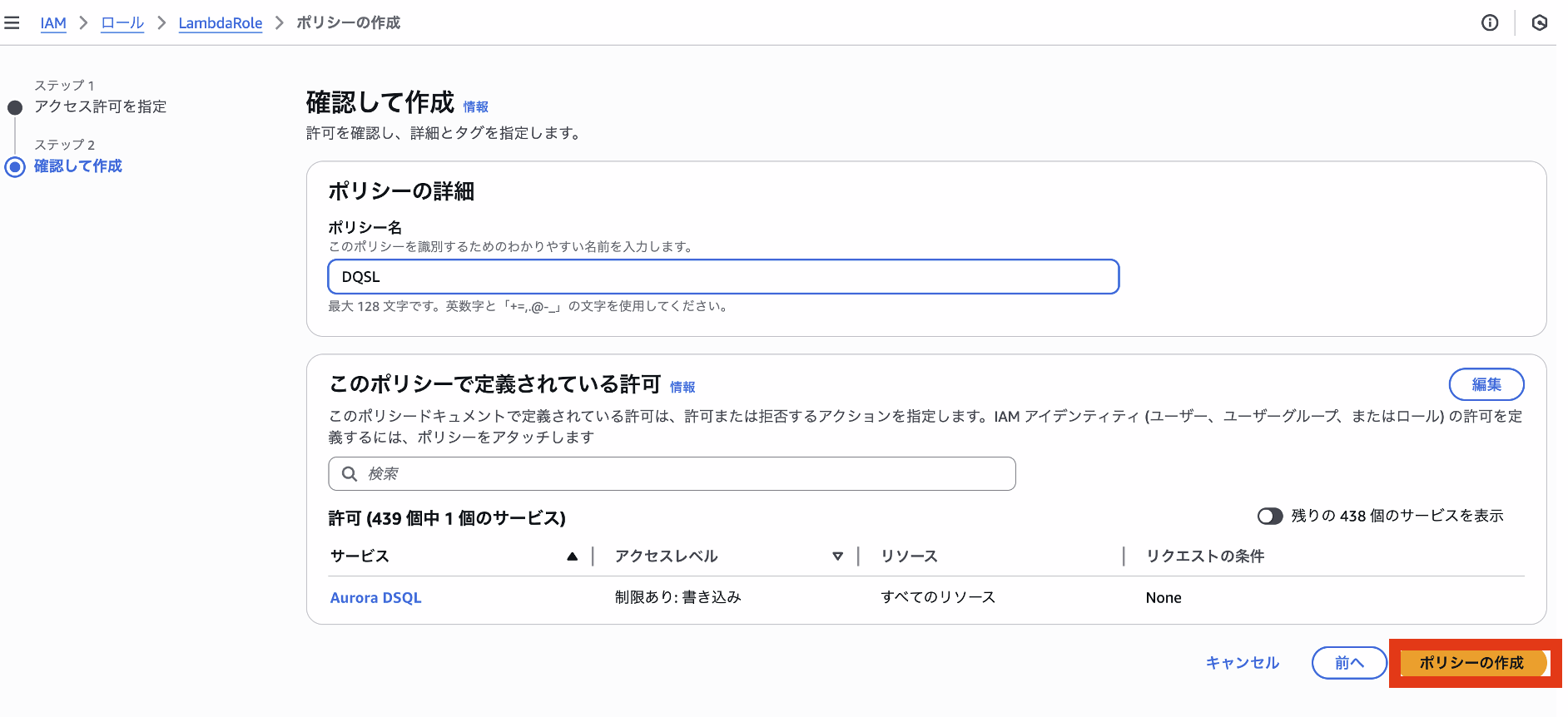
ポリシーエディターに直接上記のポリシーを付与します。
Lambdaを作成します。
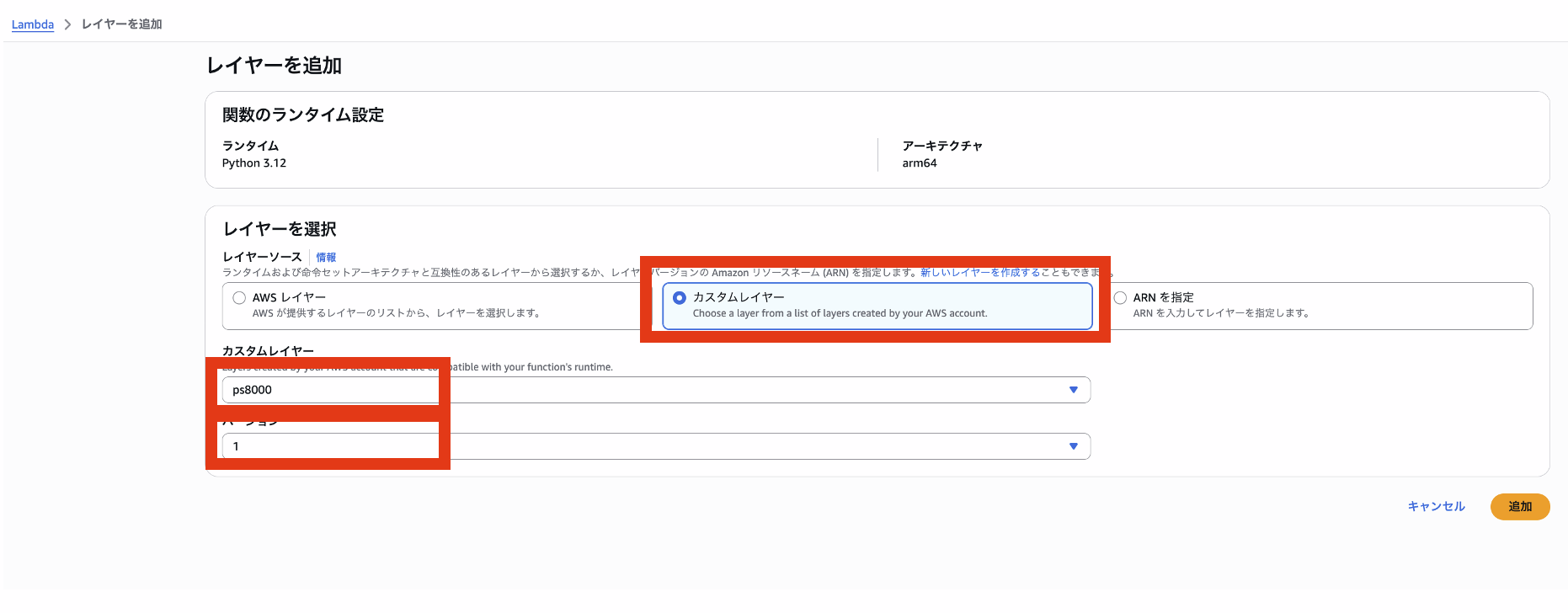
最初にLambdaLayerを作成します。CloudShellを起動して下記を入力してください。
pip3.9 install pg8000 -t ./python
zip -q -r ./layer.zip ./python
aws lambda publish-layer-version \
--layer-name ps8000 \
--zip-file fileb://layer.zip \
--compatible-runtimes python3.12

作成したLambdaに書きソースを貼り付けます。
import os
import boto3
import json
import logging
from datetime import datetime
import pg8000
logger = logging.getLogger()
logger.setLevel(logging.INFO)
REGION = os.environ['REGION']
DSQL_ENDPOINT = os.environ['DSQL_ENDPOINT']
DSQL_USER = os.environ['DSQL_USER']
DSQL_DATABASE = os.environ['DSQL_DATABASE']
DSQL_PORT = os.environ['DSQL_PORT']
def lambda_handler(event, context):
logger.info(f"Event: {json.dumps(event)}")
# データベース接続設定
connection = None
cursor = None
try:
# Generate a password token
client = boto3.client("dsql", region_name=REGION)
password_token = client.generate_db_connect_admin_auth_token(DSQL_ENDPOINT, REGION)
connection = pg8000.connect(
host=f'{DSQL_ENDPOINT}',
port=5432,
database=f'{DSQL_DATABASE}',
user=f'{DSQL_USER}',
password=f'{password_token}'
)
connection.autocommit = True
cursor = connection.cursor()
# AppSyncイベントからフィールド名と引数を取得
field_name = event["info"]["fieldName"]
arguments = event["arguments"]
logger.info(f"field_name: {field_name}")
logger.info(f"arguments: {arguments}")
# 操作に応じて処理を分岐
if field_name == 'getItem':
result = get_item(cursor, arguments)
elif field_name == 'listItems':
result = list_items(cursor, arguments)
else:
raise ValueError(f"Unknown field: {field_name}")
print(result)
return result
except Exception as ex:
logger.error(f"エラー:{ex}")
finally:
# 接続のを閉じる
if cursor:
cursor.close()
if connection:
connection.close()
def get_item(cursor, arguments):
item_name = arguments.get('name')
cursor.execute('SELECT * from items where name = %s', (item_name,))
result = cursor.fetchone()
print(result)
return {
"id": str(result[0]),
"name": result[1],
"updated_at": result[2].isoformat()
}
def list_items(cursor, arguments):
limit = arguments.get('limit', 10)
offset = arguments.get('offset', 0)
query = """
SELECT * FROM items
ORDER BY updated_at DESC
LIMIT %s OFFSET %s
"""
cursor.execute(query, (limit, offset))
results = cursor.fetchall()
result = []
for item in results:
result.append({
"id": str(item[0]),
"name": item[1],
"updated_at": item[2].isoformat()
})
return result
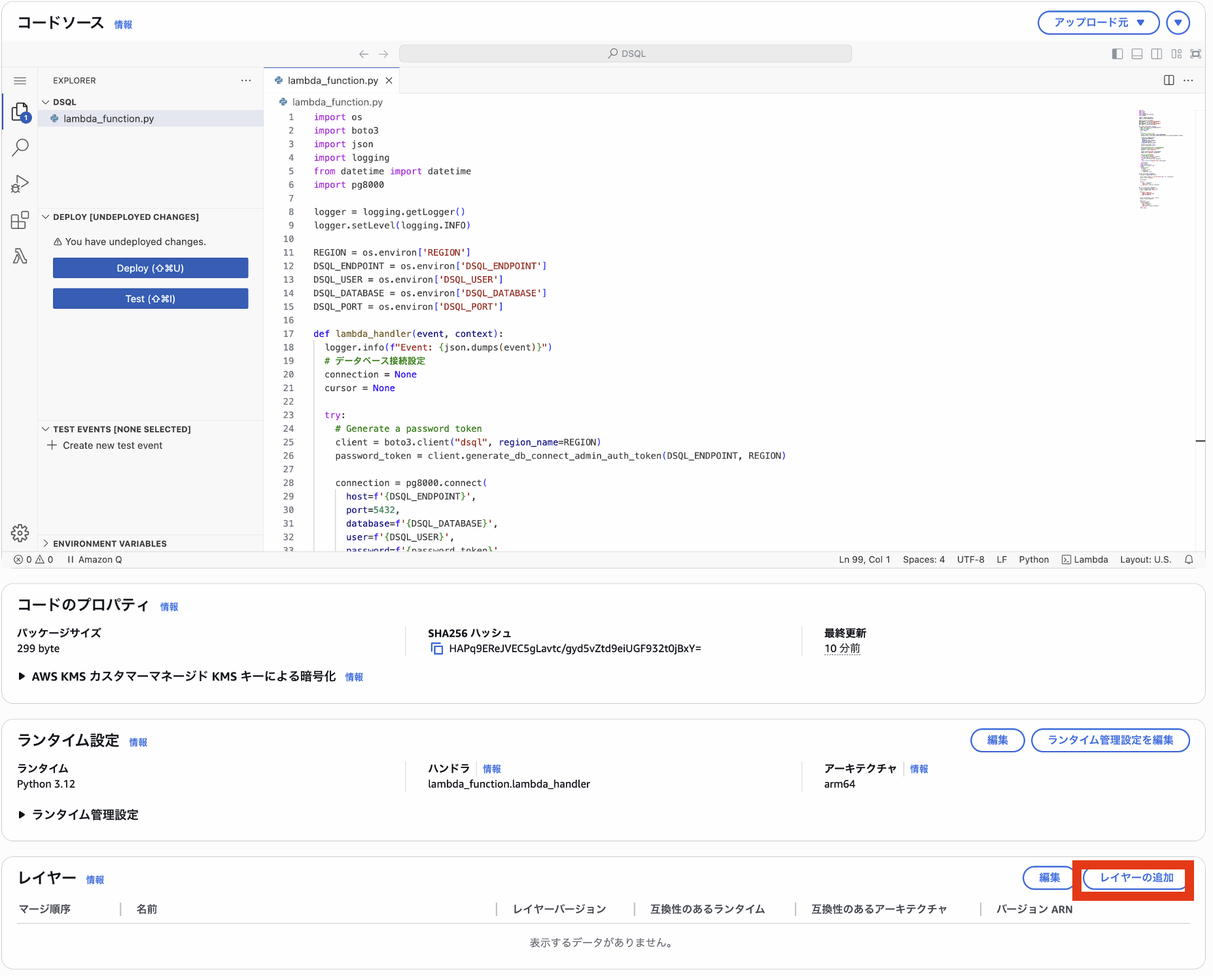
作成したLambdaにLayerと環境変数を設定します。


AppSyncを作成する
最後にAppSyncを作成します。



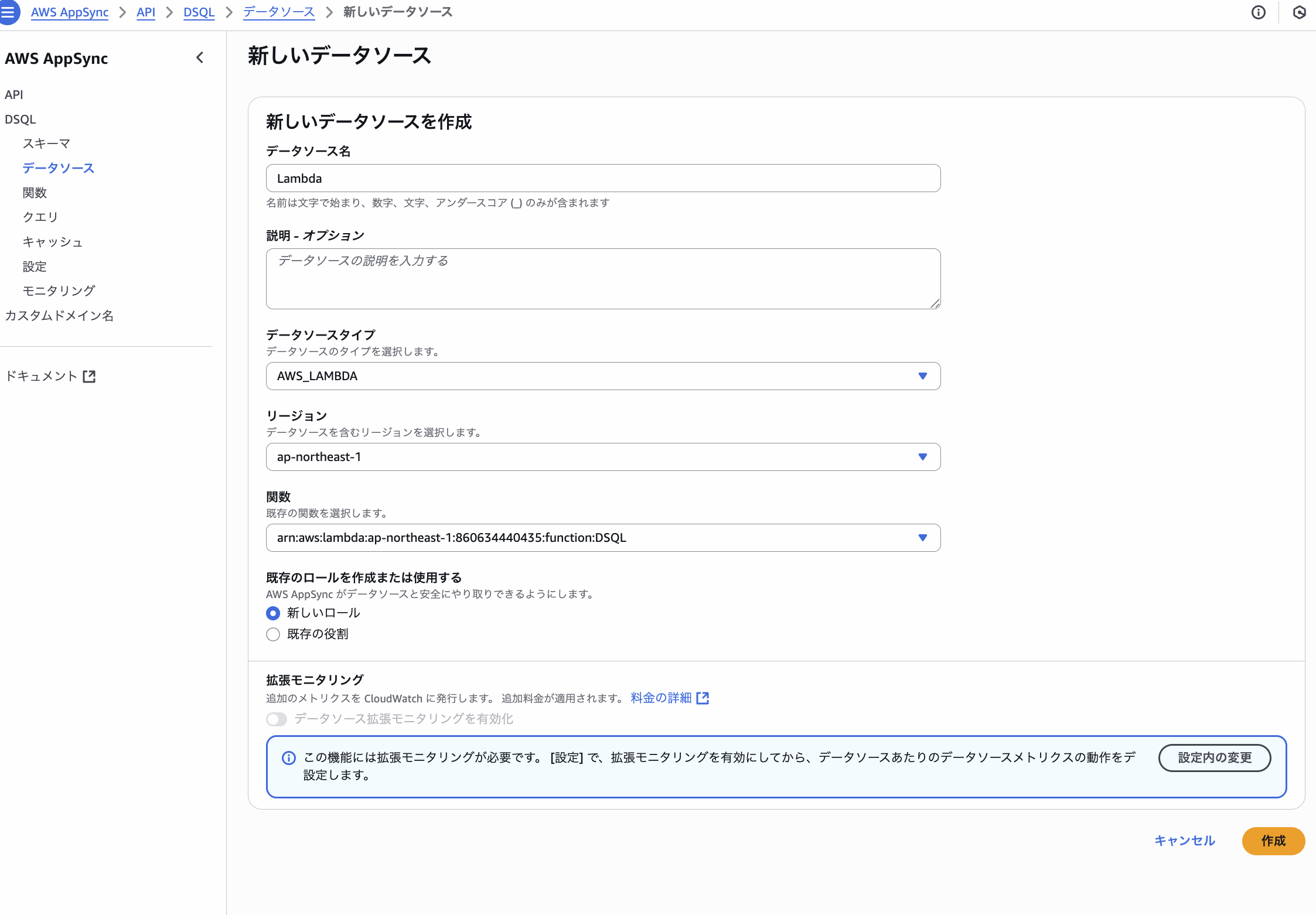
次にデータソース作成します。
最後にスキーマーを作成します。下記をコピーして貼り付けてください。
type Item {
id: ID!
name: String!
updated_at: AWSDateTime
}
type Query {
getItem(name: String!): Item
listItems(limit: Int, offset: Int): [Item!]!
}
Queryに先ほど作成したデータソースをアタッチします。
※作成ボタンを押したらエラーになる場合がありますが10秒ほど待ってから作成ボタンを押すと成功します。

動作確認
最初に作成したバナナの情報が取得できたことを確認できたと思います。

まとめ
今回はAppSyncがDSQLのデータソースに対応していなかったためLambdaから取得してみました。
このやり方は、AppSyncが対応していないものと連携する場合は応用が聞くと思いますので、
様々なものと接続してみてください