はじめに
10月からの約2か月間、primeNumberさんにインターンとしてお世話になりました。期間中は、APIを叩いてデータを取得して、BigQueryに転送したり、データ結合したりと、troccoを使ってデータエンジニアリングはじめの一歩を経験させていただきました。
インターンの締めがアドカレのタイミングと被ったということで、集大成として、これまでにやったことを活かして自然言語処理やってみようと思います。
流れ
プログラミングETL(Python)で Cloud Natural Language API を呼び出します。
おおまかな流れは次の通りです。
- Twitter APIを使ってツイート取得
- プログラミングETLでAPIを呼び出す
- Looker Studioで可視化
1と2は同一のtrocco転送ジョブ(API=>BigQuery)で実施します。
3に関しては、BigQuery上のSQLで簡単な処理をしてからLooker Studioに紐づけます。
1. Twitter APIを使ってツイート取得
Twitterのデータを大量に取得する場合、一つ一つコピペで集めるのは現実的ではありません。
こういった場合、Twitter APIが便利です。
しかし、1度のAPIリクエストで取得できるツイートには制限があります。
- 期間
- リクエスト実行時から1週間前まで
- ツイート数
- 1回につき100ツイートまで
リクエストパラメータをその都度変更して実行していけば、このあたりの問題はクリアできます。が、いささか面倒です。それぐらいできる、と思っても、リクエストで返ってきたJSONデータを繋げる必要があるので、やっぱり面倒です。
そこで便利なのが、troccoの転送ジョブ(とワークフローのループ機能)です。
ちなみに、APIリクエストは ↓↓ のサイトで作ってくれます。
Twitter Developerのプロジェクトの画面でBearer Tokenを取得し、それを作成されたリクエストの$BEARER_TOKENのところに差し替えるだけです。
trocco転送ジョブの設定
Twitter DeveloperでAPIのtokenを発行、エンコードし、ヘッダーに詰め込むだけです。
trocco側に設定項目としてあるので、特に迷うことなくサクサクと設定できます。
また、Twitter APIによるツイート取得には、Twitterと同じようにキーワード検索をしてくれるパラメータが用意されています。
今回は、「#本田の解説」をパラメータに入れてツイートを取得します。
今回は取得期間を変更するので、ワークフローのループ機能を使うために該当箇所をカスタム変数で置き換えておきます。
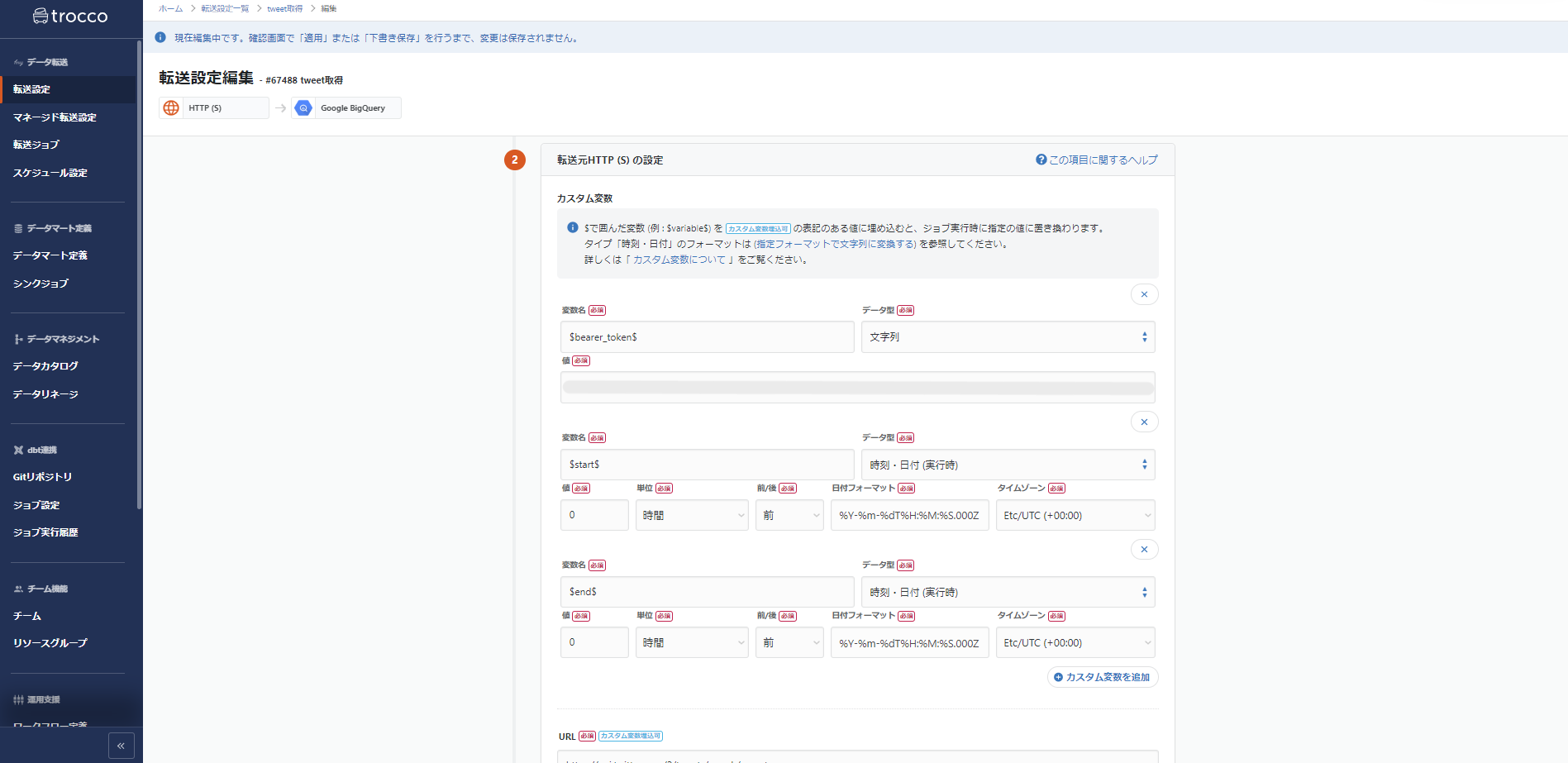
ツイート取得の転送ジョブです。
転送元:HTTP(S)
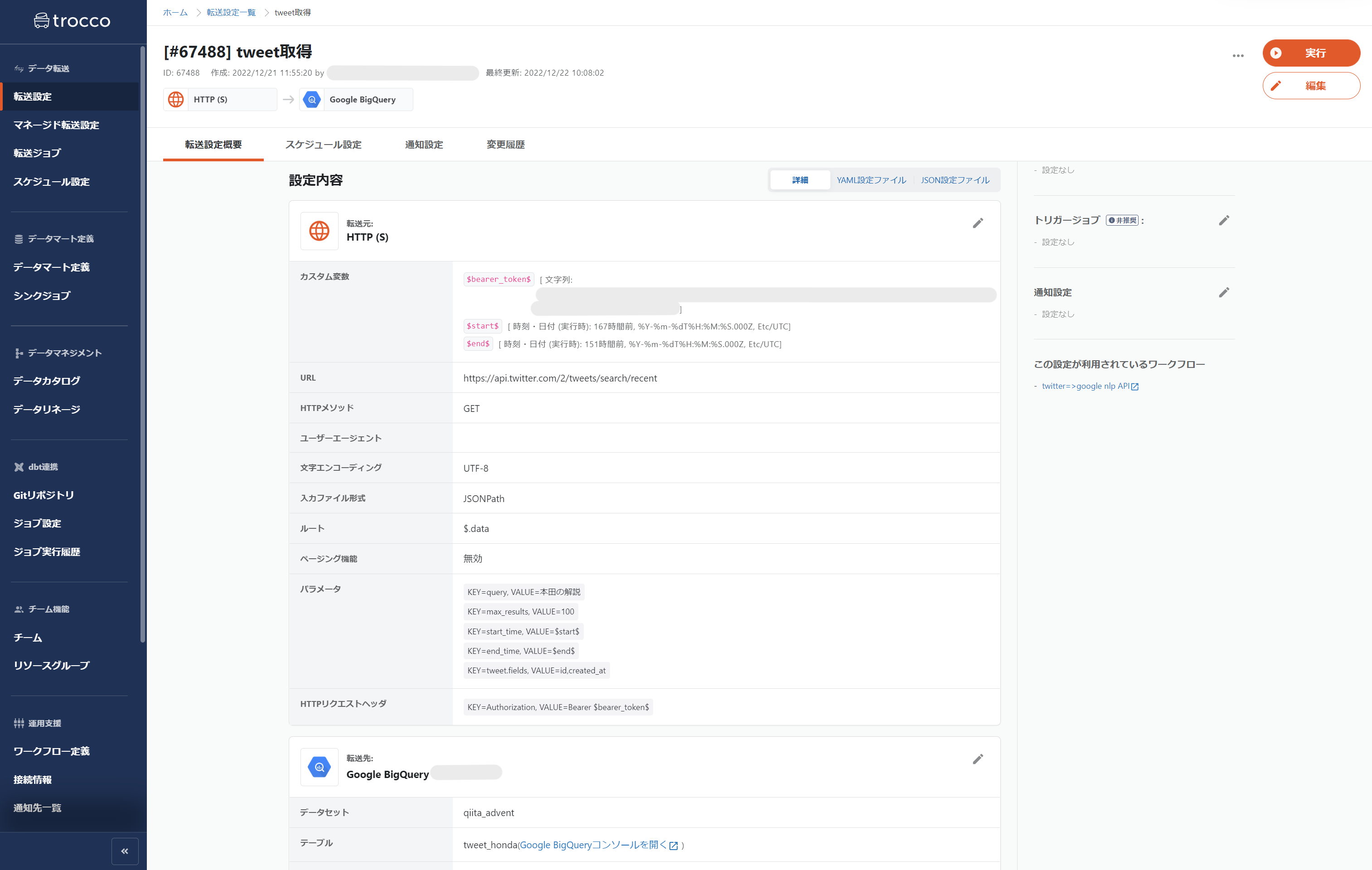
転送先:Google BigQuery
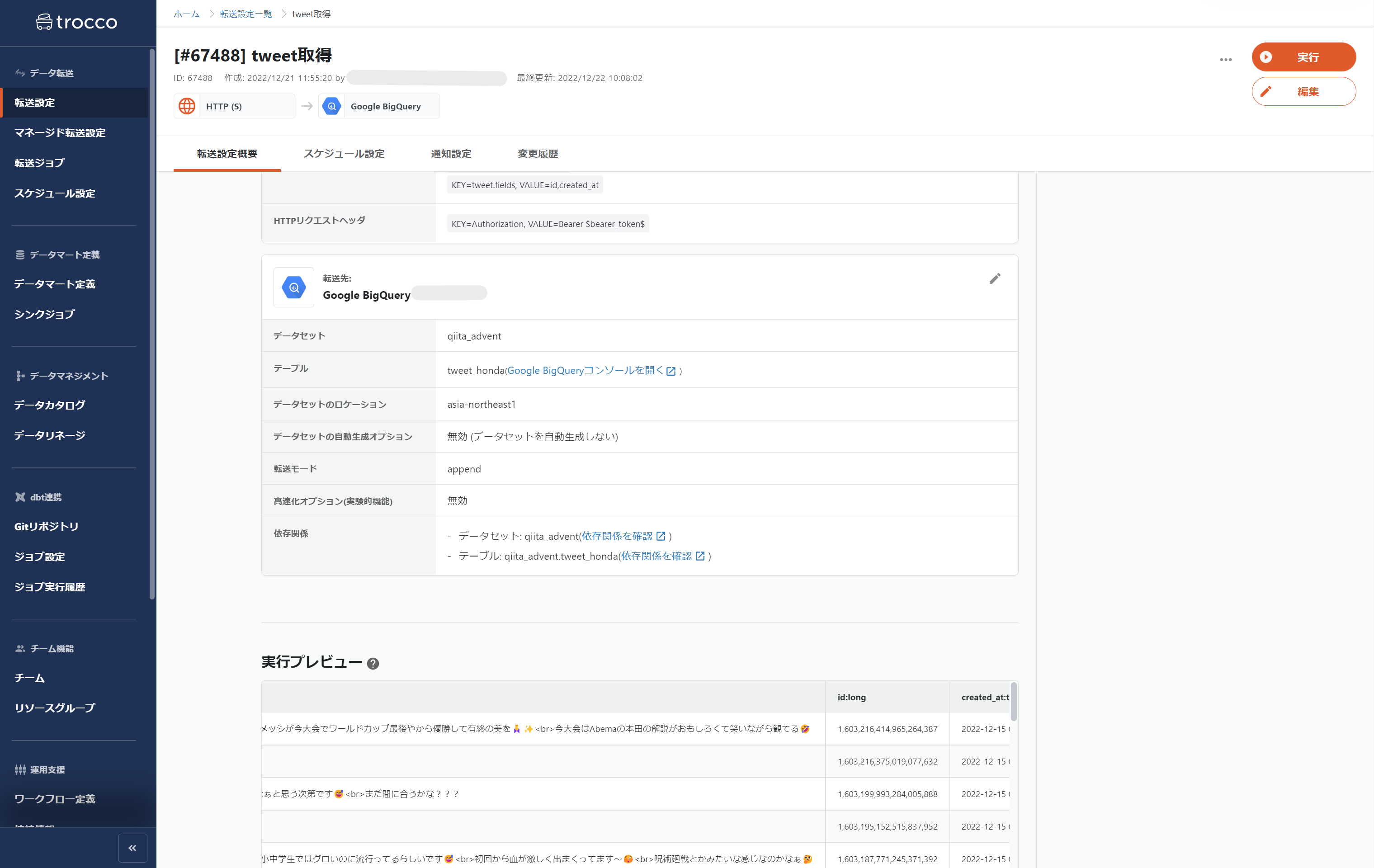
取得したデータを繋げるために転送モードは「append」にします。
ループ機能
詳しくは、↓↓を参照してください。
こちらの「日付範囲によるループ」に従って、ワークフローを設定します。
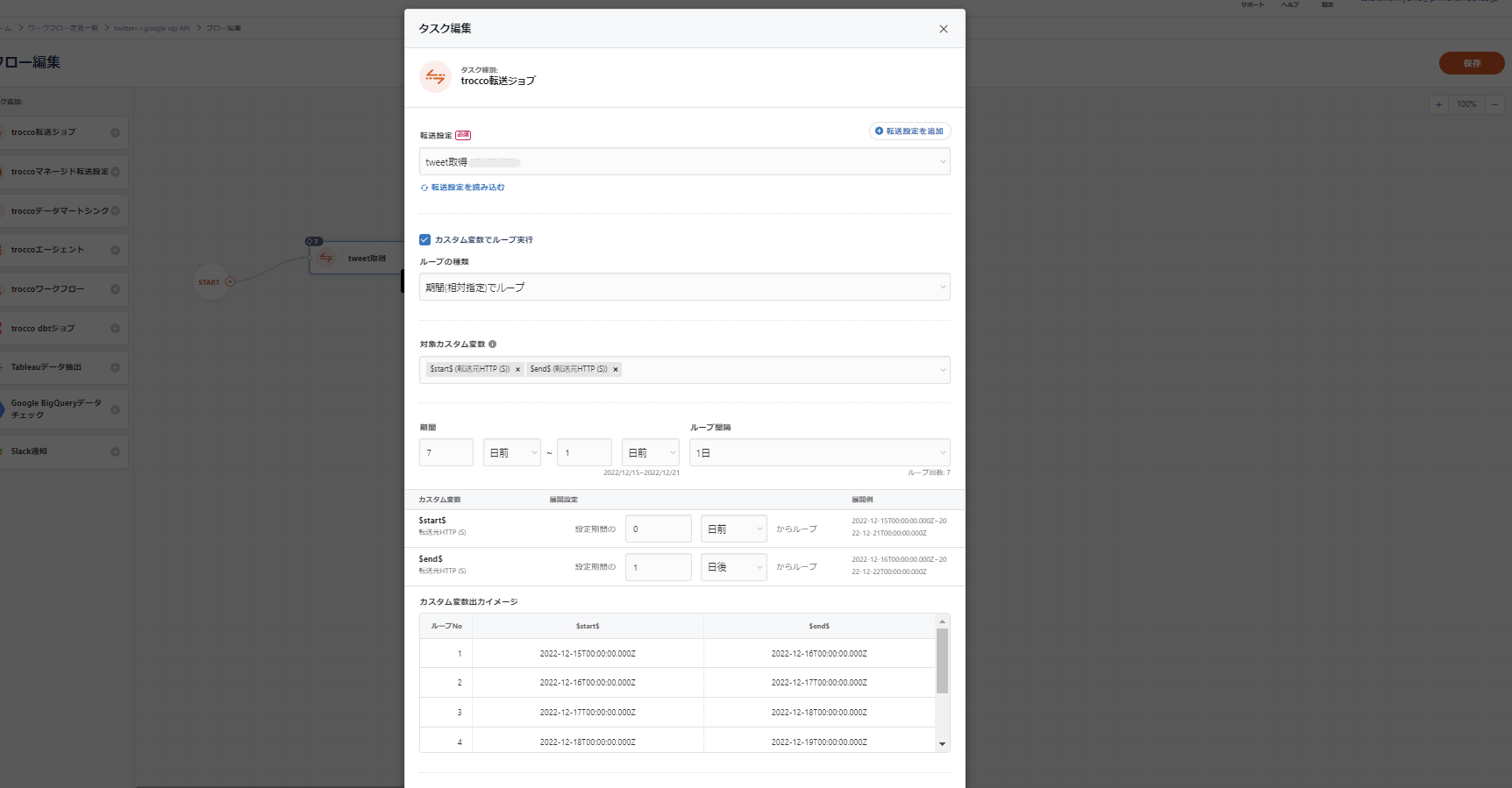
ワークフローの実行結果として、BigQueryを見てみます。
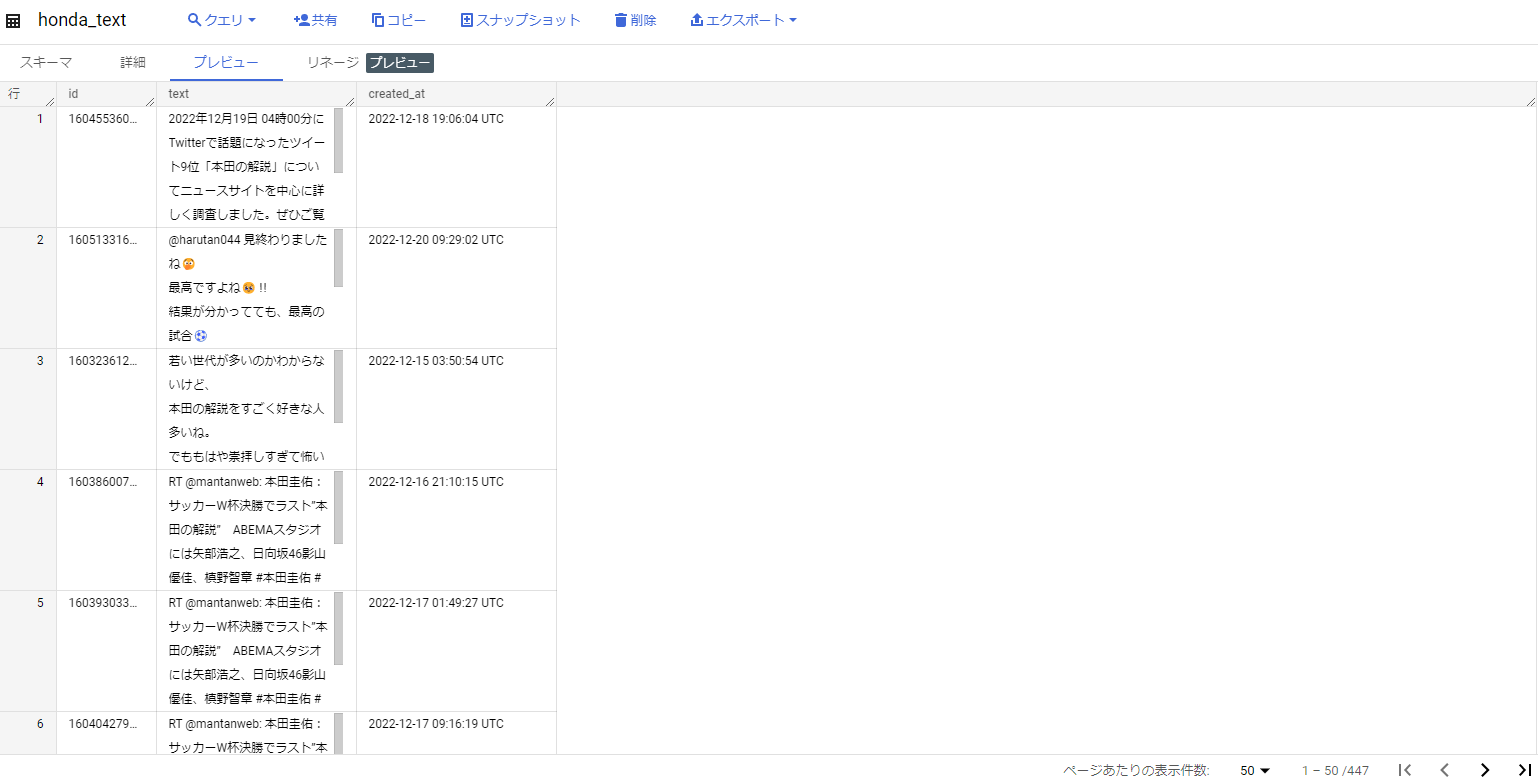
とりあえずある程度のツイートは取得出来たので、次に移ります。
2. プログラミングETLでAPIを呼び出し、感情分析(Google Cloud Natural Language API:analyzeSentiment)
流れは非常にシンプルです。
今回、初めてプログラミングETLの機能を使ってみましたが、
- Python
- 関数定義、正規表現など
- API
- GET、POST
- JSON
の基本的なことさえおさえておけば、簡単に実装できます。
プログラミングETL(Python)
プログラミングETL設定画面
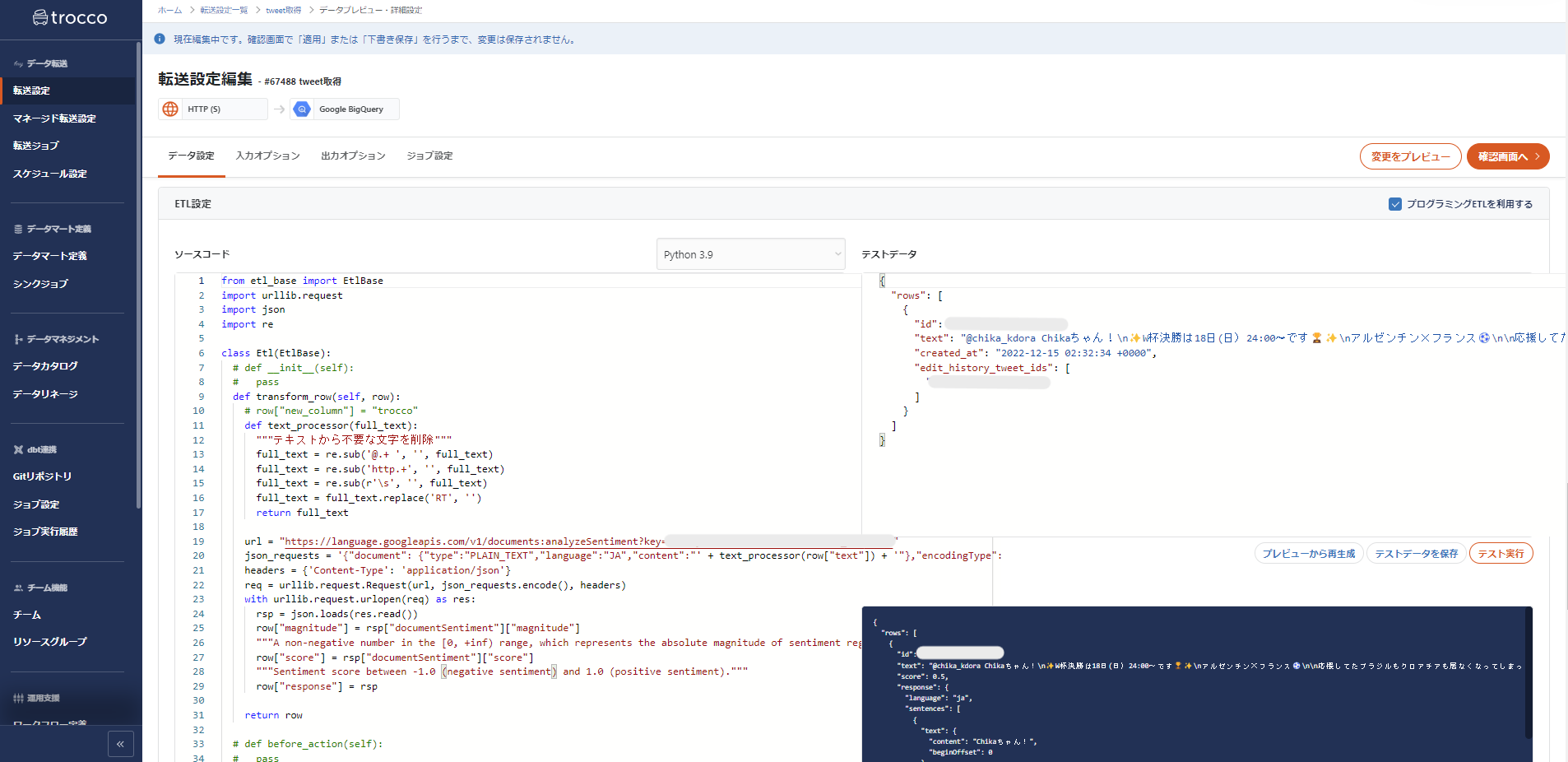
RubyとPythonのどちらか一方で処理できます。
今回は、Pythonで行います。
また、前処理としてテキストの整形を行います。
上記で取得した生データを見ると、@から始まるメンションやurl、RTなどといった、不要な文字列が含まれています。
これらは分析の対象外としたいので一応、削除します。
from etl_base import EtlBase
import urllib.request
import json
import re
class Etl(EtlBase):
def transform_row(self, row):
def text_processor(full_text):
"""テキストから不要な文字を削除"""
full_text = re.sub('@.+ ', '', full_text) #メンションの削除
full_text = re.sub('http.+', '', full_text) #URLの削除
full_text = re.sub(r'\s', '', full_text) #スペースや改行の削除
full_text = full_text.replace('RT', '') #RTを削除
return full_text
row["processed_text"] = text_processor(row["text"])
url = "https://language.googleapis.com/v1/documents:analyzeSentiment?key=$API_KEY"
json_requests = '{"document": {"type":"PLAIN_TEXT","language":"JA","content":"' + row["processed_text"] + '"},"encodingType": "UTF8"}'
headers = {'Content-Type': 'application/json'}
req = urllib.request.Request(url, json_requests.encode(), headers)
with urllib.request.urlopen(req) as res:
rsp = json.loads(res.read())
row["response"] = rsp
return row
Google Cloud Natural Language API
また、今回はGoogle Cloud Natural Language APIを使って感情分析を実施します。
Natural Language APIを使うために、Google Cloud Platform のアカウントがあり、課金が有効化されている(無料期間あります)必要があります。
アカウントを作り、課金を有効化したら、
- GCPのWEBコンソールから「APIとサービス>ライブラリ」を選択する
- 「Cloud Natural Language API」を検索する
- 「有効にする」をクリックする
- 「APIとサービス>認証情報」を選択する
- 「認証情報を作成」する
- 表示されているAPI Keyを
key=API_KEYパラメータと一緒に渡す
の流れでPOSTメソッドで呼び出せます。
プログラミングETLの設定が完了したので、再度転送します。
先ほどのTwitter APIからそのまま取得したデータの下に append するとスキーマ不一致のためエラーが発生します。
一応、先ほどとは別のテーブルを作成します。
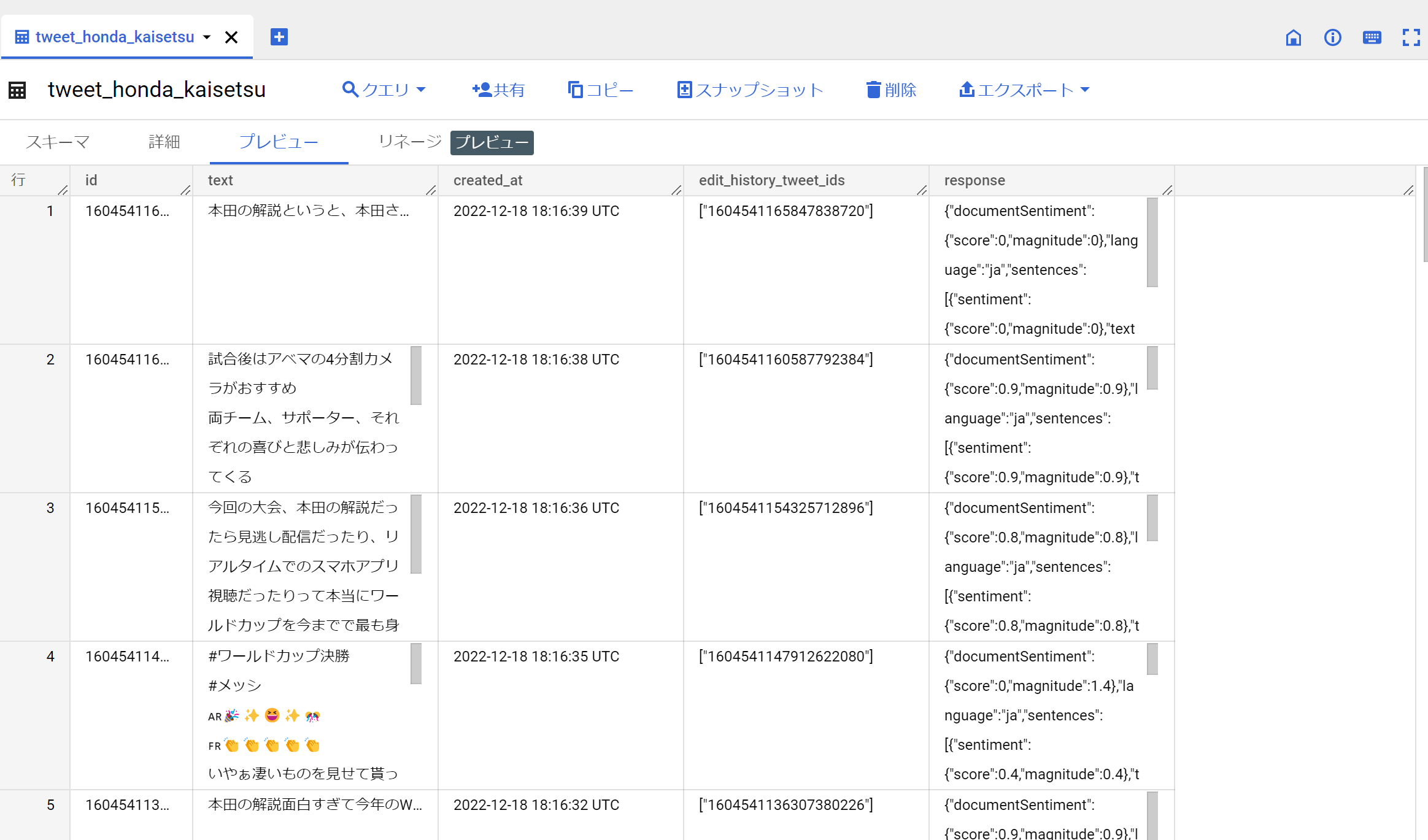
responseカラムがAPIの結果となります。
うまくいったようなので、次に移ります。
3. Looker Studioで可視化
文章の感情を表す数値であるscore と magnitudeがJSONの中に入っており、可視化できないのでBigQuery上で簡単に処理します。
SELECT
text,
created_at,
CAST(JSON_EXTRACT(response,"$.documentSentiment.score") AS FLOAT64) AS score,
CAST(JSON_EXTRACT(response,"$.documentSentiment.magnitude") AS FLOAT64) AS magnitude
FROM
`テーブルID`
;
これをビュー保存して、Looker Studioで可視化する。
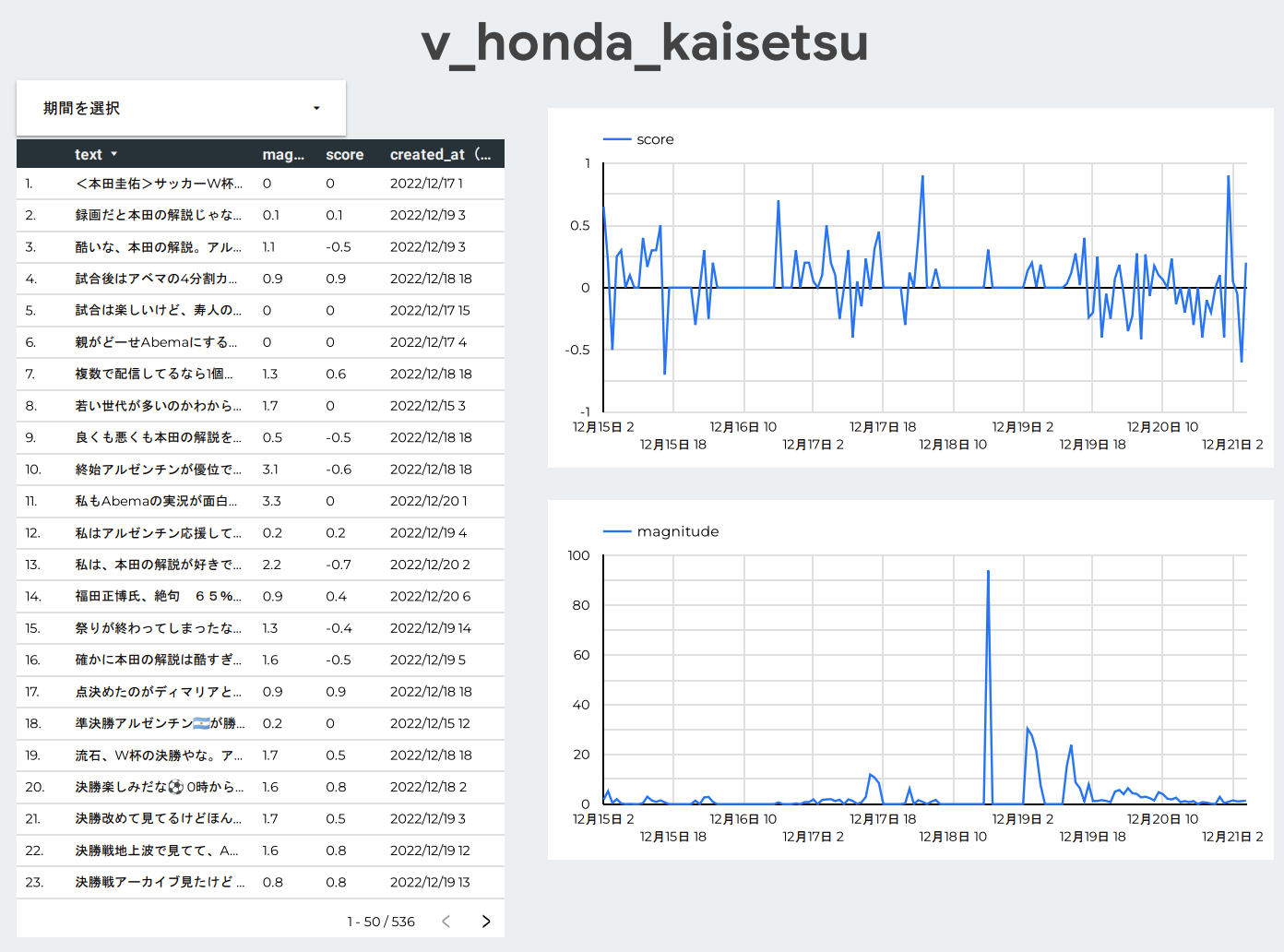
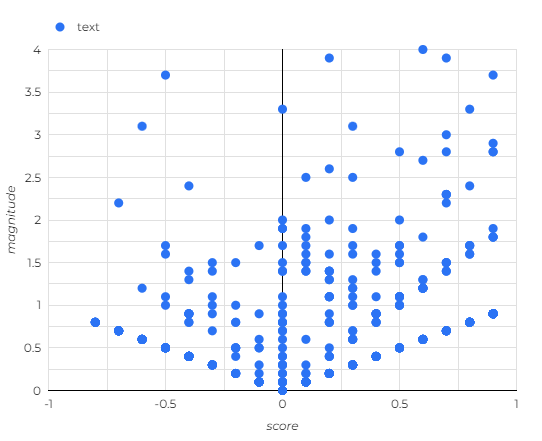
ケイスケ・ホンダが解説をした日のmagnitudeの合計が大きくなっていることから、影響の大きさが分かります。
scoreがマイナスに振れてネガティブツイートと判定されているものが目立ちます。
内訳をみると決勝戦のアルゼンチン(メッシ)贔屓の解説に反応したものが多いです。
これまでの解説者にはいない、等身大の発言で注目を集めた「本田の解説」が、これらのツイートを呼んだというのは興味深いです。
ちなみに、score と magnitudeについては↓↓の通りです。
-
score- -1.0(ネガティブ)~1.0(ポジティブ)のスコアで感情が表される
- テキストの全体的な感情の傾向に相当
-
magnitude- 指定したテキストの全体的な感情の強度(ポジティブとネガティブの両方)が 0.0~ の値で示される
-
scoreと違ってmagnitudeは正規化されていないため、テキスト内で感情(ポジティブとネガティブの両方)が表現されるたびにテキストのmagnitudeの値が増加する- そのため、長いテキストブロックで値が高くなる傾向がある(下図)
- 直線状に点がプロットされるのが目立つ
- そのため、長いテキストブロックで値が高くなる傾向がある(下図)
まとめ
Twitter APIからツイートを取得して、Cloud Natural Language APIで感情分析を行いました。
Twitter APIの制限をtroccoのループ機能ですり抜けたのは、グッドジョブポイントではないでしょうか。