POLプロダクト Advent Calendar 2020 の11日目担当,プロダクト部でインターンをしている @kohei-shinden です.(社内ではモンティと呼ばれています.理由は Python 言語に由来します.)
10日目の @guevara-net さんの記事も是非ご一読ください!
今回は,インターン期間中に触れることの多かった Neo4j を使って自分にアニメをレコメンドしてみたいと思います.
0.環境について
今回の記事では,以下の環境下で実行をしました.環境の違いによる手順の違いなどは事前にご了承ください.
- MacOS Big Sur version 11.0.1
また,事前に Docker の環境構築をよろしくお願いします.
それでは,本題に入ります.
1.Neo4j とは
タイトルにもある「Neo4j」とはなんでしょうか?
Wikipedia には以下のような記載があります.
Neo4jはJavaで実装された、 オープンソースの最も人気のあるグラフデータベースである。
(出典:Neo4j - Wikipedi, https://ja.wikipedia.org/wiki/Neo4j )
Neo4j とは,グラフ構造モデルのデータベースです.
グラフとは,要素(頂点)間の関係を表す線からなる数学理論です.要素のことをノード,線のことをエッジと呼びます.
例えば,身近なものであれば家系図や路線図などがありますね.
以下の図は,Neo4j の公式ドキュメントに載っている画像です.
(出典:Neo4j Graph Platform – The Leader in Graph Databases, https://neo4j.com/ )

上記の図では,ノードによって「商品,カテゴリ,注文,供給者,顧客」が表現されています.また,それぞれのノード間の関係がエッジによって表現されています.
これらのデータは実際に Neo4j に格納されたデータを, Neo4j に備わっている UI で視覚化したものです.かなり直感的ですね.
このノードとエッジをうまく利用することで直感的にレコメンドシステムを構築できます.
2.データの用意
それでは,レコメンドする対象となるデータを用意しましょう.
今回は Kaggle 上で公開されている Anime Recommendations Database を利用します.
以下のリンクにアクセスしてデータをダウンロードしてください.
ダウンロードしたファイルを解凍すると,フォルダには anime.csv と rating.csv の2つのファイルがあります.それぞれ中身は以下のようになっています.
anime_id,name,genre,type,episodes,rating,members
32281,Kimi no Na wa.,"Drama, Romance, School, Supernatural",Movie,1,9.37,200630
5114,Fullmetal Alchemist: Brotherhood,"Action, Adventure, Drama, Fantasy, Magic, Military, Shounen",TV,64,9.26,793665
...
user_id,anime_id,rating
1,20,-1
1,24,-1
...
3.ノードとエッジを決める
アニメをおすすめするためのデータを得たところで,データを基にノードとエッジのラベルを決めましょう.
ノードの種類は次の通りです.
| ラベル | 説明 |
|---|---|
| Anime | アニメ作品 |
| User | ユーザ |
エッジの種類は次の通りです.
| ラベル | 向き | 説明 |
|---|---|---|
| RATING | Anime←User | アニメに対するユーザの評価 |
4.Neo4j の環境準備
それでは,Neo4j の環境構築を行います.
冒頭でもお伝えしましたが,MacOS 下で実行しています.
また,事前に Docker の環境構築もお願いします.
neo4j/docker-neo4j: Docker Images for the Neo4j Graph Database を参考にしながら進めます.
まず,ターミナルを立ち上げて以下を実行してください.
$ docker run --publish=7474:7474 \
--publish=7687:7687 \
--volume=$HOME/neo4j/data:/data \
--volume=$HOME/neo4j/logs:/logs \
--volume=$HOME/neo4j/import:/import \
neo4j:latest
この時,$HOME 下に neo4j ディレクトリが作成され,neo4j 下に data, logs, import が作成される.
この import ディレクトリ下に先ほど用意したデータを配置してください.import ディレクトリに Neo4j に読み込みたいデータを配置することで,クエリ言語を使用して読み込み可能になります.
配置後は以下のようになります.
$ pwd
/Users/$USER_NAME/neo4j
$ ls
data import logs
$ ls import
anime.csv rating.csv
以上で準備は整いました.
ブラウザから http://localhost:7474/ にアクセスしてみてください.
すると以下のような画面が表示されると思います.
デフォルトのユーザ名とパスワードはどちらも「neo4j」です.
入力して connect ボタンを押すと,新しいパスワード入力画面に移ります.
入力して Change password ボタンを押してください.
以下のページが表示されれば,正常にアクセスできています.
画面上部の入力欄にクエリを書き入力することで,Neo4jを操作できます.
5.ノードを作る
次は,ノードの作成を行います.先ほど import ファイルに保存した2つの CSV ファイルを直接読み込み,ファイルに書かれたデータからノードを作成します.
CSV ファイルが読み込めることを確認します.ヘッダーありファイル anime.csv から5行分のデータを読み込んでみましょう.クエリは次の通りです.
LOAD CSV WITH HEADERS FROM 'file:///anime.csv' AS row
RETURN row LIMIT 5;
実行結果は以下の通りです.anime.csvを読み込めています.

読み込んだデータをもとにノードを作成しましょう.
まずは,Anime を作成します.
LOAD CSV WITH HEADERS FROM 'file:///anime.csv' AS row
CREATE (:Anime {
name: row.name,
anime_id: row.anime_id
});
ヘッダーありファイルの場合,1行目にある列名を指定することができます.
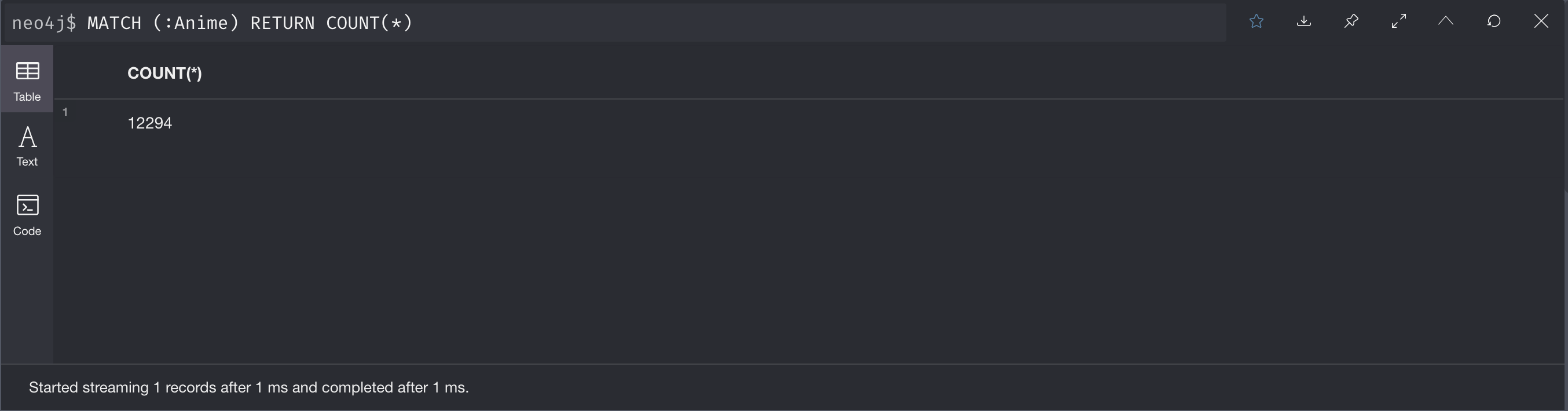
実際に正しくデータが作成されたことを確認するために,Animeノードの数をカウントしてみましょう.
MATCH (a:Anime)
RETURN COUNT(*);
実行結果は以下の通りです.anime.csvのヘッダーを除いたデータ行数と一致しています.
次は User を作成しましょう.User を作成する際は rating.csv を読み込みます.rating データはかなり多い(7,813,739 行)ので,user_id が 0 から 1000 までの 96,480 行のみを使用します.
LOAD CSV WITH HEADERS FROM 'file:///rating.csv' AS row
WITH DISTINCT row.user_id as user_id
WHERE toInteger(user_id) <= 1000
CREATE (:User {
user_id: user_id
});
6.インデックスの作成
エッジを作成する際,既存のノードからプロパティを検索してノード間をつなぐのですが,プロパティの検索速度を向上するために,インデックスを作成します.
CREATE INDEX index_anime_id FOR (n:Anime) ON (n.anime_id);
CREATE INDEX index_user_id FOR (n:User) ON (n.user_id);
7.エッジを作成する
次は,エッジの作成を行います.ノードの作成と同様に CSV ファイルを直接読み込みエッジを作成します.
// RATING Anime←User
LOAD CSV WITH HEADERS FROM 'file:///rating.csv' AS row
MATCH (u:User) WHERE u.user_id = row.user_id AND toInteger(row.user_id) <= 1000
MATCH (a:Anime) WHERE a.anime_id = row.anime_id
CREATE (u)-[:RATING{rating:toInteger(row.rating)}]->(a);
8.レコメンドする
ノードとエッジをうまく利用することで直感的にレコメンドシステムを構築できます.
次の手順でおすすめを作成します.
- 自分のノードを作る.
-
anime.csvから好きなアニメを探して,RATINGエッジを作る. - 好きなアニメを基におすすめする.
8.1.自分のノードを作る
既に登録されているユーザは, user_id が 1000 までのユーザなので user_id を 1001 にして自分のアカウントを作成しましょう.
CREATE (:User {
user_id: "1001"
});
8.2.好きなアニメを探してエッジを作る
私は週刊少年ジャンプで連載中の漫画ワンピースの大ファンです.具体的には,毎週週刊少年ジャンプを買い,アニメも毎週 TVer で欠かさず見て,ファンブックやグッズも集め考察も行い...という感じです.なので,「One Piece」を探してみましょう.
検索しやすくするために,フルテキストインデックス(Indexes for full-text search - Neo4j Cypher Manual)を作成しましょう.
CALL db.index.fulltext.createNodeIndex("AnimeSearch", ["Anime"], ["name"]);
作成したインデックスを使用して検索を行います.db.index.fulltext.queryNodes(${INDEX_NAME}, ${QUERY})という形式で実行します.Lucene query score の高い上位10件を使用してエッジを作成しましょう.(Lucene query score: Apache Lucene - Scoring)
まずは以下のクエリを実行して,検索結果を確認してみましょう.
CALL db.index.fulltext.queryNodes("AnimeSearch", "One Piece")
YIELD node, score
RETURN node.anime_id as id, node.name as name, score
ORDER BY score DESC
LIMIT 10;
実行結果は以下のようになります.結果を見た限り間違ったデータはなさそうですね.

それでは,上記で得た結果を使ってエッジを作成します.
UNWIND ["21", "8171", "16143", "16468", "16287", "12859", "459", "31490", "22661", "466"] AS anime_id
MATCH (a:Anime) WHERE a.anime_id = anime_id
MATCH (u:User) WHERE u.user_id = "1001"
CREATE (u)-[:RATING{rating:1}]->(a);
作成した結果を確認してみましょう.
MATCH (u:User{user_id:"1001"})-[r:RATING]-(a:Anime) RETURN u, r, a;
以下の図が確認クエリの実行結果です.エッジ作成の実行結果が正しく反映されていることがわかります.
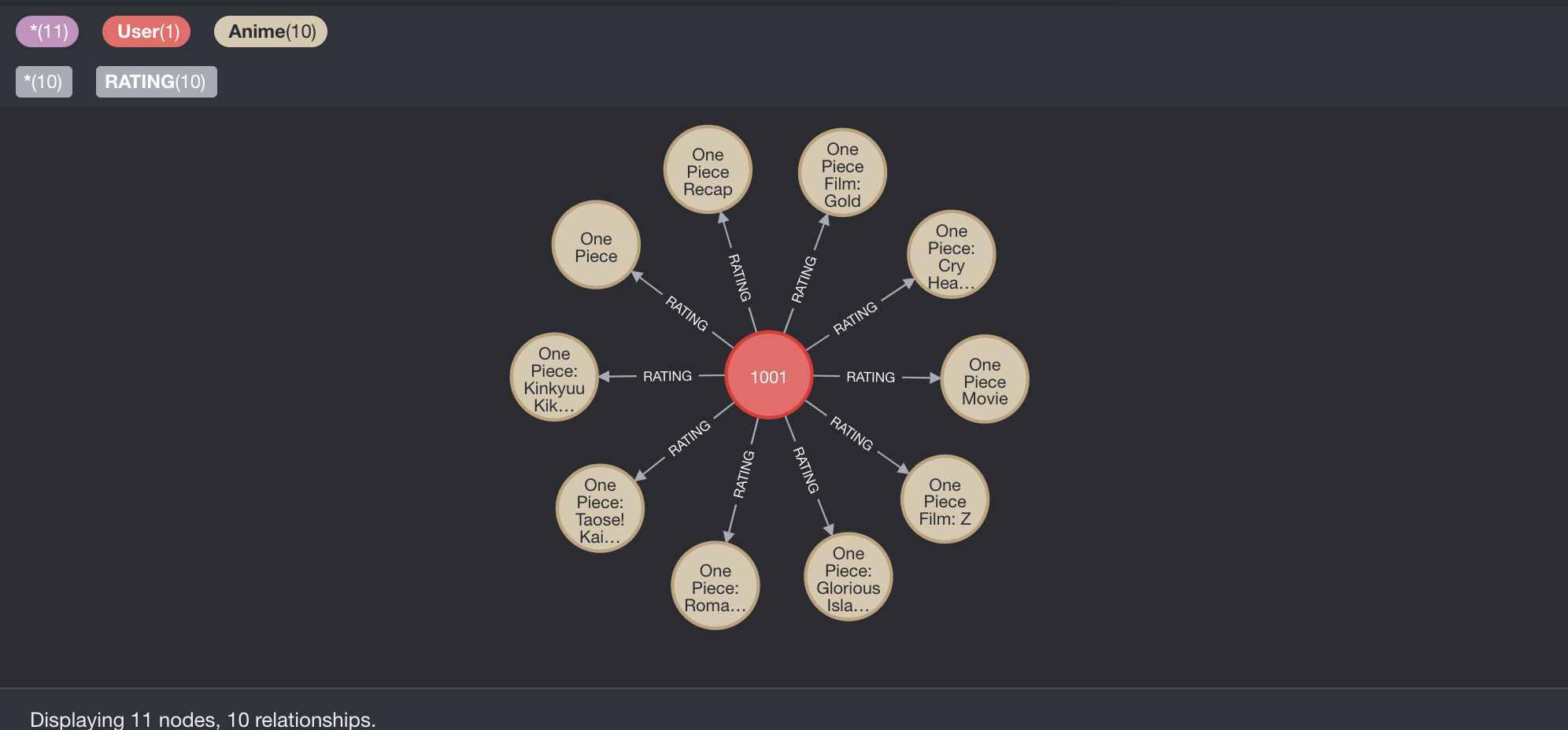
好きなアニメを探して登録する作業は以上です.
8.3.好きなアニメを基にレコメンドする
さて,それでは,最後に好きなアニメをもとにおすすめなアニメを表示しましょう.ここでは,
「自分が好きなアニメを高評価している他のユーザが,高評価している他のアニメは自分に適合する可能性が高い」と仮定します.
// 自分が高評価しているアニメ
MATCH (:User{user_id:"1001"})-[:RATING]-(a0:Anime)
WITH collect(a0.anime_id) AS a0_ids
// 自分が高評価しているアニメを高評価している他のユーザが高評価している他のアニメ
MATCH (:User{user_id:"1001"})-[:RATING]-(:Anime)-[r0:RATING]-(:User)-[r1:RATING]-(a1:Anime)
// 自分が高評価しているアニメを除外するかつ r0 と r1 の rating が 1 より大きい
WHERE NOT a1.anime_id IN a0_ids AND r0.rating > 1 AND r1.rating > 1
WITH a1, count(a1) as cnt_a1
RETURN a1, cnt_a1
// 重複数の降順でソート
ORDER BY cnt_a1 DESC
LIMIT 10;
実行結果は以下の通りです.

上から順に,進撃の巨人,ワンピース(Film: Strong World),デスノート,ソードアートオンライン,鋼の錬金術師となっています.
自分がアニメ視聴アプリに登録していてこのおすすめが送られてきたら,なかなか良い線だなと思いますね.進撃の巨人はワンピースと同じようなアクション漫画のアニメであり,デスノートは週刊少年ジャンプで連載されていた漫画のアニメなので,妥当だと感じられます.また,ワンピース(Film: Strong World)は今回の設定上では,まだ評価していないことになっているので,おすすめされて見ていないなら見るし,見ているなら評価するというように何らかのアクションは起こすでしょう.
9.さいごに
今回は Neo4j と Anime Recommendations Database を使って自分にアニメをおすすめしてみました.割と妥当な結果が出て良かったです.一方で,今回利用したデータは十分な量があったため妥当な結果が出ましたが,データが少ないようなシステムに今回のような方法を適用しても,あまり使えるものではない可能性が高いです.
今回は使いませんでしたが, Anime Recommendations Database には他にもレコメンドに役立つ要素となるデータが含まれています.例えば,アニメのタイプ(映画,テレビなど)やアニメのジャンル(アクション,コメディなど)です.これらを使うことでさらに精度良くすることが可能だと考えられます.
ところで,社内のあだ名の由来は Python と言っておきながら,全く触れませんでしたね.
次回 12 日目は,ナッツさん(@sho-kanamaru)です!お楽しみに!
おまけ
Neo4j にアクセスできない
認証のエラーが発生している場合には, $HOME 下に作成される neo4j ディレクトリを削除して,Docker run を再実行してみてください.エラーが解消される場合があります.
ノードとエッジを全部削除したい
注意して以下を実行してください.全てのノードとエッジが削除されます.
MATCH (n) OPTIONAL MATCH (n)-[r]-() DELETE n,r;
インデックスを確認したい
CALL db.indexes();
インデックスを削除したい
DROP INDEX ${INDEX_NAME};
各言語の Driver
- Using Neo4j from Go - Developer Guides
- Using Neo4j from Java - Developer Guides
- Using Neo4j from Python - Developer Guides