導入
要約
本記事では、DB設計においてる全体像をまとめました。
Webアプリケーションや業務システムにおけるデータベース(DB)の立ち位置や役割、DBを扱うためのDBMS、代表的なデータベースの種類について解説します。さらに、システム開発工程におけるDB設計の流れや、データ独立性を保つ 3層スキーマ(外部・概念・内部) の考え方に触れ、論理設計・物理設計の具体例とともに、実際のテーブル設計やER図、インデックス、ハードウェア構成までを体系的に紹介する。特に、正規化とパフォーマンスのトレードオフや、ストレージI/Oによる性能ボトルネックにも注意が必要です。
核心
-
システム開発は「データが中心」 (DOA: データ中心アプローチ)
- システムを作るときは、最初にどんなデータが必要か、どういう形でデータを保管するのが良いかを考えるのが基本です。
- 逆に、データの設計をせずにプログラムから始めると、めちゃくちゃ詰む(経験済み)
- データの設計は超大切で、データの設計がシステムの質に大きく悪い影響を与える
-
データの「キレイさ (整合性)」と「速さ (パフォーマンス)」は、ちょっとだけケンカする関係
- 正規化を行うと、データ間の矛盾や重複するデータの不整合のリスクを低減できる。
- ただし、正規化を進めると、データを複数のテーブルに分割するため、テーブルの数が増加する。
- テーブルの分割が行われると、テーブル間での結合処理が増えるのでパフォーマンスが落ちる可能性がある。
- とはいえ、多くのシステム開発では第3正規化まで行うことが一般的であり、通常、第3正規化の範囲内であれば、パフォーマンスへの影響はそれほど大きくありません。
-
データベースにおいての性能問題のほとんどはストレージI/Oが原因
- ディスクへのデータの読み書き速度(ストレージI/O)がボトルネックとなることが原因である。
- データベースは、データの永続化や検索、更新など、様々な処理でディスクへのアクセスを頻繁に行います。
- ディスクの読み書き速度が遅いと、これらの処理に時間がかかり、システム全体の応答遅延やスループットの低下を引き起こします。
-
ハードウェアを選定する場合は、ストレージ+パフォーマンス(CPU+メモリ)を考慮する
- システムで利用するデータ量
- サービス終了時のデータの増加率
- 応答時間
- スループット
本文
DBとは
現代のWebアプリケーションや業務システムは、ユーザーに見える「画面」の背後で、膨大なデータのやりとりを行っていますこの中核を担うのが データベース(Database) です
-
一言で言えば、データベースは「データを蓄積し、管理するための場所」です
-
実際には、蓄積されたデータはファイルに格納される
-
たとえば、以下のような動作があるとします。これらはすべて、裏側でデータベースに保存・取得されているデータによって成り立っている
- SNSで投稿した内容が保存される
- ECサイトで注文した履歴が確認できる
- 社内システムで社員データを検索できる
システムの中でのデータベースの役割
- システム全体の中での位置づけ
| レイヤー | 主な役割 |
|---|---|
| フロントエンド | ユーザーの画面(UI) |
| アプリケーション | 処理のロジック |
| データベース | データの保存・取得 |
-
データの取得
- ある画面にアクセスした場合、アプリケーションが呼ばれる
- アプリケーションがデータベースに対して、画面に表示するデータを取得・加工する
- 画面にデータを入れ、表示させる
-
大まかな流れ
- フロントエンドで入力されたデータをアプリケーションへ渡す
- アプリケーションでデータに対する、値のチェック(バリデーションチェック)・加工を行う
- アプリケーションがデータベースに対して、データを保存してくれと命令する
DBMS
DBMS(Database Management System) は、データベースを効率的かつ安全に管理・運用するためのソフトウェアです
-
DBMSは以下のような機能を提供します:
- データの保存、検索、更新、削除
- 同時アクセスの制御(トランザクション管理)
- ユーザーごとのアクセス制限(権限管理)
- バックアップとリカバリ
- データの整合性確保(整合性制約)
-
データベースとDBMSの違い
| 用語 | 説明 |
|---|---|
| データベース | 実際にデータが保存されている場所そのもの(ファイルや記録の集まり) |
| DBMS | データベースを操作・管理するためのソフトウェア。保存・取得・更新・削除などを担う |
DBの種類
-
リレーショナルデータベース(RDB, Relatinal Database, 関係データベース)
- RDBは、2次元の表の形式で管理する
- 最も広く利用されているデータベースで、単に「データベース」言うとRDBのこと
-
オブジェクト指向データベース(OODB, Object Oriented Database)
- JavaやC++などオブジェクト指向言語では、「データ+操作」をまとめてオブジェクトという
- OODBは、このオブジェクトという単位でデータベースに保存するために作られた
-
XMLデータベース(XMLDB, XML Database)
- Web上でやり取りするデータの形式には、XMLというタグを使用して階層構造を表現するものがある
- XMLDBでは、XML形式のデータを扱えるように開発された
- RDBでは階層構造のデータの扱いを苦手としているが、XMLDBではそれを得意としている
-
キー・バリュー型ストア(KVS, Key-Value Store)
- KVSでは、データをKey(認識キー)とValue(値)の組み合わせだけの単純なデータ型で表現するデータベースのこと
-
ドキュメント型データベース
- JSON(JavaScript Object Notation)というJavaScriptのオブジェクトを定義するためのデータ構造で保存する
- JSONでは、データの階層や配列を定義できる
- 近年では、RDBにJSON型が標準化されることもある
- KVSやドキュメント型DB、グラフを扱うグラフデータベースをまとめてNoSQLという
- 階層型データベース(Hierarchical Database)とは、データを階層構造(木構造)で表現するデータベースのこと
- これはあまり使用されなくなった
システム開発の工程
-
要件定義
- システムが満たすべき要件(機能やサービスの水準など)を決める工程
-
設計
- 定義された要件を満たすために必要なシステムを作るための設計(デザイン)を行う工程
- プログラマが見る仕様書や設計書をここで作成する
- データベース設計が含まれる*
-
開発(実装)
- 仕様書や設計書に従ってシステムを実際に作る(実装する)工程
-
テスト
- 実装によって組みあがったシステムが、本当に実用にたえる品質なのかを試験(テスト)する工程
- 品質のテストと性能・信頼性のテストの2つがある
-
保守・運用
- 開発したものを運用する
この連載では、この設計についてメインに触れる。
システム開発のモデル
システム開発の進め方を開発モデルという。
- 開発モデルにはウォーターフォールモデルとアジャイルモデルに大別される。
-
ウォーターフォールモデル
- システム開発の工程順に、原則として前工程が完了しないと次工程に進まない開発モデルのこと。
- 大規模なプロジェクトにおいて、進捗を管理しやすいというメリットがある。
- 上流工程の誤りがあればあるほど、下流工程への影響が大きく修復コストが高くなる傾向がある。
-
アジャイルモデル
- 短時間にシステム開発の工程を繰り返す開発モデルのこと
- 一度にすべての機能を作るのではなく、小さな単位で実装と改善を繰り返すことで、柔軟に要求の変更に対応できる。
- 主に少人数のチームや、変化が多い・スピードが求められるプロジェクトに適している。
- 顧客との継続的なコミュニケーションを重視し、都度フィードバックを取り入れて開発を進める。
-
実際の採用状況(出典:2023年度ソフトウェア開発に関するアンケート調査)
回答者区分 ウォーターフォール アジャイル(ルールあり) アジャイル(ルールなし) その他(合計) ユーザー企業 (N=183) 71% 17% 48% 64% ベンダー企業 (N=199) 75% 27% 56% 72% 個人 (N=352) 74% 15% 45% 47% -
この表は複数回答形式のため、合計が100%を超える・または下回ることがあります。
-
「アジャイル(ルールあり)」:スクラムなどのフレームワークを厳格に適用する開発
-
「アジャイル(ルールなし)」:柔軟な手法でアジャイルの思想のみを適用
-
「その他」にはDevOps、DevSecOps、ノーコード/ローコード、モデルベース開発などを含む
3層スキーマ
- スキーマ は、データベースのデータ構造やフォーマットという意味。
-
外部スキーマ(外部モデル) =ビューの世界
- 画面やデータ=ユーザーから見たデータベース
-
概念スキーマ(論理データモデル) =テーブルの世界
- データの要素やデータ同士の関係=開発者から見たデータベース
- 概念スキーマを定義する設計を 論理設計
-
内部スキーマ(物理データモデル) =ファイルの世界
- テーブルやインデックスの物理的定義=DBMSから見たデータベース
- 内部スキーマを定義する設計を 物理設計
-
概念スキーマは、外部スキーマと内部スキーマの緩衝材である。
- 外部スキーマと内部スキーマの両者の変更が互いに影響しあわないようにする
- データ独立性を保証するためにある
-
論理設計を行ってから物理設計を行う
論理設計
- エンティティの抽出
- エンティティの定義
- 正規化
- ER図の作成
- 正規化とER図に関しては、追々、詳しく説明する
- 現実世界の対象物や概念のこと。
- 特に、システム上でデータとして取り扱うことができるように抽象的にモデル化されたもの。
- 1で、システム内で管理すべき実体(≒名詞)を洗い出します
- 2で、エンティティごとに 属性(名前、メールアドレスなど) と 主キー(ID) を定義し、他エンティティとの関係(リレーション)も整理し始めます
- 3で、データの不整合性を防ぐために、テーブル構造を整理します。
- データの正規化による整合性とパフォーマンスの間に強いトレードオフの関係が成り立つ
- 特に第4正規形・第5正規形に進むと、実装やパフォーマンスへの影響が大きいため、慎重に判断しなければならない
- 一般的には、第3正規形まで行えば、十分にデータの重複を排除し、整合性の高い設計が実現できるとされている
物理設計
- テーブル定義
- インデックス定義
- ハードウェアのサイジング
- ストレージの冗長構成決定
- ファイルの物理配置決定
-
ストレージの冗長構成決定に関しては、追々、詳しく説明する
-
性能問題のほとんどはストレージI/Oネックによって引き起こされる
- I/O性能とは、主にディスクやストレージとの読み書きの性能をこと
-
サイジングとは、ストレージ+パフォーマンス(CPU+メモリ)という意味
-
ハードウェアのサイジングには、大きく2つ考えるべき点がある
- キャパシティのサイジング:ストレージ
- パフォーマンスのサイジング:CPU+メモリ
-
キャパシティのサイジングをするにあたっては下の情報が必要
- システムで利用するデータ量
- サービス終了時のデータの増加率
-
パフォーマンスのサイジングをするにあたっては下の情報が必要
- 応答時間:どれだけ速く処理できるのか
- スループット:どれだけ沢山処理できるのか
-
冗長化とは、システムやデータの可用性(availability)や信頼性(reliability)を高めるために、同じ機能やデータを複数持たせておく仕組みのこと
- RAIDという冗長化技術を利用して、データを冗長化する。
-
データベースファイルの種類
- データファイル: ユーザーがデータベースに格納するデータを保持するファイル
- インデックスファイル: テーブルに作成されたインデックスが格納される
- システムファイル: DBMSの内部管理に使われるデータを管理する
- 一時ファイル: 一時的なデータの格納。GROUP BY等を利用した時のソートデータ
- ログファイル: テーブルに対するデータ変更の一時格納ファイル
- データベースファイルをどのディスクに配置するかを決定する
- このうち開発者はデータファイルとインデックスファイルを意識する必要がある
概念スキーマ(具体例)
テーマ:記事投稿サイト
-
エンティティの抽出
- ユーザー
- 記事
-
エンティティの定義
例:ユーザー
| 属性名 | 型 | 説明 |
|---|---|---|
| id | 整数 | ユーザーID(主キー) |
| name | 文字列 | 名前 |
| 文字列 | メールアドレス |
例:投稿
| 属性名 | 型 | 説明 |
|---|---|---|
| id | 整数 | 投稿ID(主キー) |
| user_id | 整数 | 投稿者のユーザーID(外部キー) |
| title | 文字列 | 記事のタイトル |
| body | 文字列 | 記事の本文 |
-
正規化
- 上の例では、たまたま正規化された状態となっている
-
ER図の作成
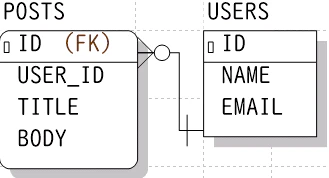
- ER図はエンティティ同士の関係(リレーション)を可視化するものです。
- 投稿(posts)とユーザー(users)は 1対多(1:N) の関係。
- 1人のユーザー は、複数の投稿を持つことができる。
- 1つの投稿 は、必ず1人のユーザーにしか属しません。
論理設計(具体例)
-
テーブル定義
- users
カラム名 データ型 制約 説明 id INTEGER PRIMARY KEY ユーザーID(主キー) name VARCHAR(100) NOT NULL ユーザー名 email VARCHAR(255) UNIQUE NOT NULL メールアドレス - posts
カラム名 データ型 制約 説明 id INTEGER PRIMARY KEY 投稿ID(主キー) user_id INTEGER FOREIGN KEY → users(id) 投稿者のユーザーID(外部キー) title VARCHAR(200) NOT NULL 記事のタイトル body TEXT 記事の本文 - このフェーズで作成されるモデルを 物理モデル という
-
インデックス定義
- posts.user_id にインデックスを設定すると、ユーザー別の投稿検索が高速化されます。
- users.email は UNIQUE 制約とともにインデックスが必要(ログイン時などの照合に使われる)。
-
ハードウェアのサイジング
- キャパシティのサイジングとパフォーマンスのサイジングについて、それぞれの入力情報を調べて適切なハードウェアを決める
- このとき、なるべくスケーラビリティー(拡張性)が高い構成にする
-
ストレージの冗長構成決定
-
ファイルの物理配置決定
- RAIDが決まれば、どのディスクにどのファイルを配置するのかが決まるため、割愛する
出典
-
IBM「3層アーキテクチャとは」
- https://www.ibm.com/jp-ja/topics/three-tier-architecture (アクセス日:2025年5月16日)
-
Innovative「データベースの種類とその選び方のポイント」
-
IPA 2011/07/22 財団法人計算科学振興財団ソフトウェア・エンジニアリングセミナー「ソフトウェア開発の標準プロセス ソフトウェア開発の標準」
- https://www.ipa.go.jp/archive/files/000004771.pdf (アクセス日:2025年5月16日)
-
応用情報技術者試験ドットコム 応用情報技術者試験令和4年春期午前問27
- https://www.ap-siken.com/kakomon/04_haru/q27.html (アクセス日:2025年5月16日)
-
基本情報技術者試験ドットコム 基本情報技術者試験平成23年午前問53
- https://www.fe-siken.com/kakomon/23_toku/q53.html (アクセス日:2025年5月16日)
-
内閣官房情報通信技術(IT)総合戦略室 2021 年(令和3年)3 月 30 日「アジャイル開発実践ガイドブック」
-
IPA「2023年度ソフトウェア開発に関するアンケート調査」 調査結果データの公開と分析レポートの募集
-
ORACLE Oracle Drirect Seminar「いまさら聞けない!?Oracle Database設計」
-
IT用語辞典 エンティティ