1. 何をするの?
自分のツイートを解析して、「疲れ指数」を計算するような簡単なプログラムを作りながら、TwitterAPIとMeCabをサクッと試してみましょう。
・TwitterAPIで自分のツイートを取得
・MeCabでツイートを分かち書き(形態素ごとにリスト化)
・「疲」「しんどい」「眠」といった文字列がどれくらいあるかを出力する(「疲れ指数」)
ちなみに、MeCabを使わずともTwitter APIだけで似たようなものは作れます。ではなぜMeCabを使うのかというと、例えば
「疲れた疲れた疲れた」
といったようなツイート(少し心配になりますね)を単にstrとして受け取って「疲」が含まれているかどうかを判断すると、値として1を返すのですが、MeCabを使うと
「疲れた」「疲れた」「疲れた」といった風に分かち書きしてくれるので、カウントが3になり、より正確な「疲れ指数」を計算できるようになるのです。
また、MeCabを使うと「自然言語処理」をやったというなんとなくかっこいい体験をした気になれておすすめです。
2. Twitter APIとMeCabの準備
まずはTwitter APIとMeCabを使えるようにしましょう。
・Twitter APIはこちら
https://qiita.com/bakira/items/00743d10ec42993f85eb
・MeCabはこちら
https://qiita.com/grachro/items/4fbc9bf8174c5abb7bdd
基本的にこちらの素晴らしい記事の通りに進めていただければ導入できると思います。私の環境は
MacOS High Sierra 10.13.5
Python 3.6.4
でした。
3. ソースコード
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import json, config #標準のjsonモジュールとconfig.pyの読み込み
from requests_oauthlib import OAuth1Session
import pandas as pd
import sys
import MeCab
# config.pyにAPIキーを書いておく。
CK = config.CONSUMER_KEY
CS = config.CONSUMER_SECRET
AT = config.ACCESS_TOKEN
ATS = config.ACCESS_TOKEN_SECRET
twitter = OAuth1Session(CK, CS, AT, ATS) #認証処理
url = "https://api.twitter.com/1.1/statuses/user_timeline.json"
# 調べる対象
keywords = ["疲", "しんどい", "眠"]
params = {}
# OAuth で GET
twitter = OAuth1Session(CK, CS, AT, ATS)
res = twitter.get(url, params = params)
text_list = []
if res.status_code == 200: #正常通信出来た場合
timelines = json.loads(res.text) #レスポンスからタイムラインリストを取得
for line in timelines: #タイムラインリストをループ処理
text_list.append(line['text'])
else: #正常通信出来なかった場合
print("Failed: %d" % res.status_code)
print("最近のツイートを表示します。")
for text in text_list:
print(text)
m = MeCab.Tagger("-Owakati") #分かち書きします
keitaiso_list = []
for text in text_list:
keitaiso_list.extend(m.parse(text).split(" "))
number = 0
for keitaiso in keitaiso_list:
for key in keywords:
if key in keitaiso:
number += 1
print("あなたの疲れ指数は:")
tsukare = number / len(text_list)
print(tsukare)
・Twitter APIの部分はほぼコピペです()
・自分の直近のツイートを取得し、形態素で分かち書き
・「疲」「しんどい」「眠」というキーワードが総ツイート数に対しどれくらいあるかを計算します。
・つまり「疲れ指数」は1ツイートに平均どれくらい疲れてそうな言葉が入っているかを表します。1を超えたりするとやばそうです。
私の公開アカウント(@k_o2o_k)で何個かツイートして分析したところ、こうなりました。
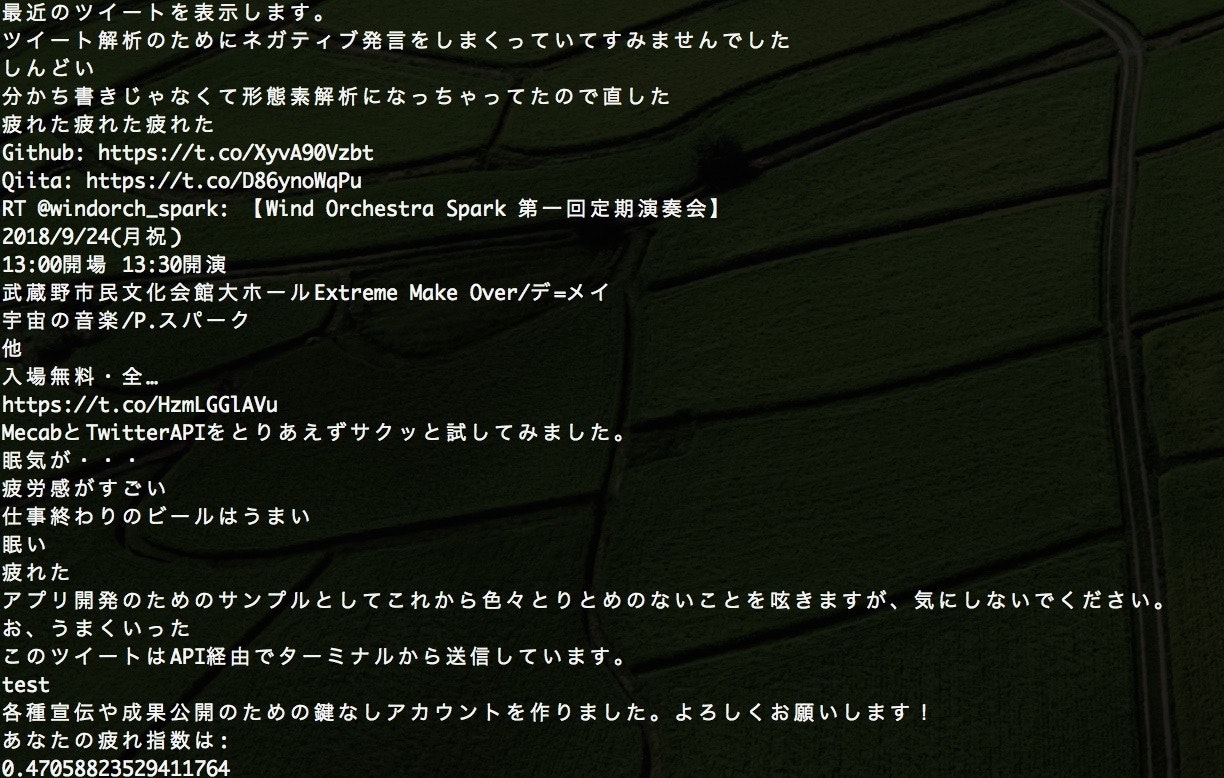
3. 発展・拡張
今回は「疲れ指数」を調べましたが、キーワードを「ビール」「焼酎」「飲み」「宴会」などとすれば、「飲み過ぎ指数」も計算できそうです。自分なりにカスタマイズしてみましょう。
keywords = ["ビール","焼酎","飲み","宴会","二日酔い"]
また、いくつかの指数を柔軟に調べられるようにプログラムを拡張することもできます。if構文を使ってkeywordsを変えられるようにしましょう。例えば冒頭にこういったコードを付け加えるといいと思います。
print("何について調べますか?→「疲れ」「飲み過ぎ」")
target = input(">>")
if target == "疲れ":
keywords= ["疲", "しんどい", "眠"]
elif target == "飲み過ぎ":
keywords = ["ビール","焼酎","飲み","宴会","二日酔い"]
else:
print("「疲れ」「飲み過ぎ」の中から選んでください")
この場合は、最後の「あなたの○○指数は」の部分も変更できるようにしておくことを忘れずに。
あとは、疲れ指数の値によって、異なるコメントを返すなど、色々拡張できそうです。
次はこれをウェブ上で使えるようにしてみたいと思います!