概要
全国で開催されるレースの結果を予測するための人工知能モデルを作成しましたに失敗しました。
今回はある程度のデータが集まったので、その履歴を残します。
目的
- 今後の開発、研究のための資金調達
- 遊ぶ金欲しさに
生データ
- 直近1年分の全国で開催されたレースの前情報とその結果(約13000レース)
前処理
- 出走数を18に固定
- 前情報の項目数の最大値に合わせて次元を調整
- 全項目を文字列化 ⇒ 文字コード化
- 使用している文字の文字コードの最大値+αの値で正規化
各モデルのネットワークとその結果
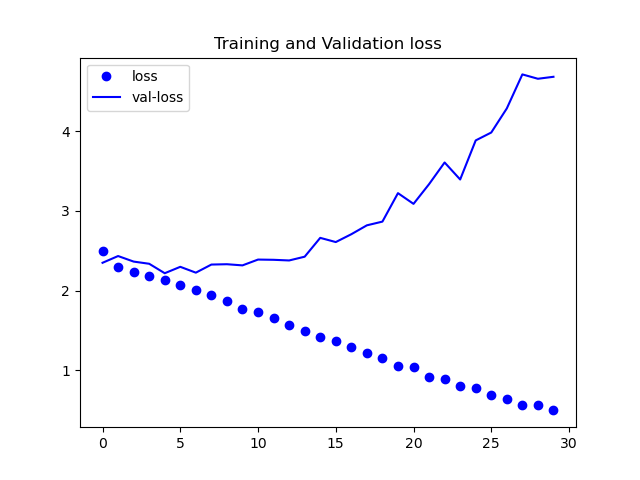
ケース①
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 86400) 0
dense (Dense) (None, 1000) 86401000
dense_1 (Dense) (None, 100) 100100
dense_2 (Dense) (None, 18) 1818
=================================================================
Total params: 86,502,918
Trainable params: 86,502,918
Non-trainable params: 0
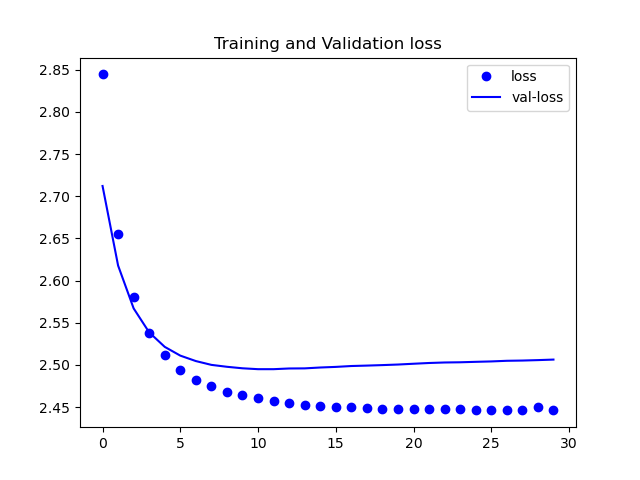
ケース②
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 86400) 0
dense (Dense) (None, 1000) 86401000
dropout (Dropout) (None, 1000) 0
dense_1 (Dense) (None, 100) 100100
dropout_1 (Dropout) (None, 100) 0
dense_2 (Dense) (None, 18) 1818
=================================================================
Total params: 86,502,918
Trainable params: 86,502,918
Non-trainable params: 0
_________________________________________________________________
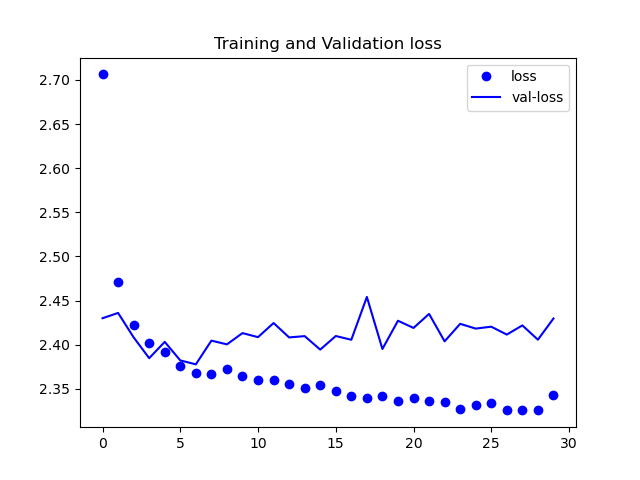
ケース③
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 86400) 0
dense (Dense) (None, 1000) 86401000
dropout (Dropout) (None, 1000) 0
dense_1 (Dense) (None, 1000) 1001000
dropout_1 (Dropout) (None, 1000) 0
dense_2 (Dense) (None, 100) 100100
dropout_2 (Dropout) (None, 100) 0
dense_3 (Dense) (None, 18) 1818
=================================================================
Total params: 87,503,918
Trainable params: 87,503,918
Non-trainable params: 0
_________________________________________________________________
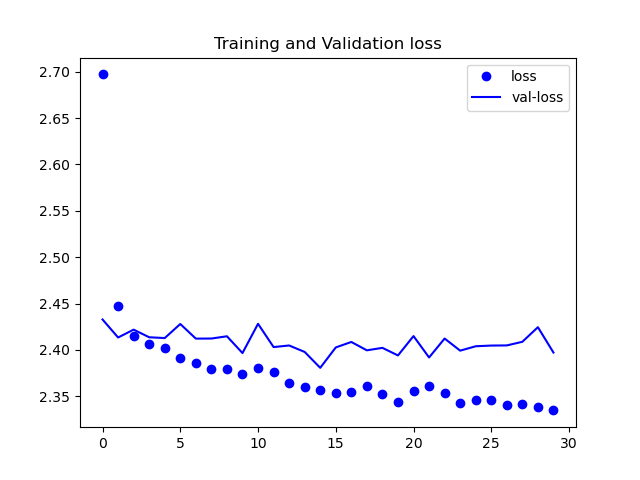
ケース④
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 86400) 0
dense (Dense) (None, 1000) 86401000
dropout (Dropout) (None, 1000) 0
dense_1 (Dense) (None, 1000) 1001000
dropout_1 (Dropout) (None, 1000) 0
dense_2 (Dense) (None, 1000) 1001000
dropout_2 (Dropout) (None, 1000) 0
dense_3 (Dense) (None, 100) 100100
dropout_3 (Dropout) (None, 100) 0
dense_4 (Dense) (None, 18) 1818
=================================================================
Total params: 88,504,918
Trainable params: 88,504,918
Non-trainable params: 0
_________________________________________________________________
ケース⑤
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 86400) 0
dense (Dense) (None, 2000) 172802000
dropout (Dropout) (None, 2000) 0
dense_1 (Dense) (None, 1000) 2001000
dropout_1 (Dropout) (None, 1000) 0
dense_2 (Dense) (None, 100) 100100
dropout_2 (Dropout) (None, 100) 0
dense_3 (Dense) (None, 18) 1818
=================================================================
Total params: 174,904,918
Trainable params: 174,904,918
Non-trainable params: 0
_________________________________________________________________
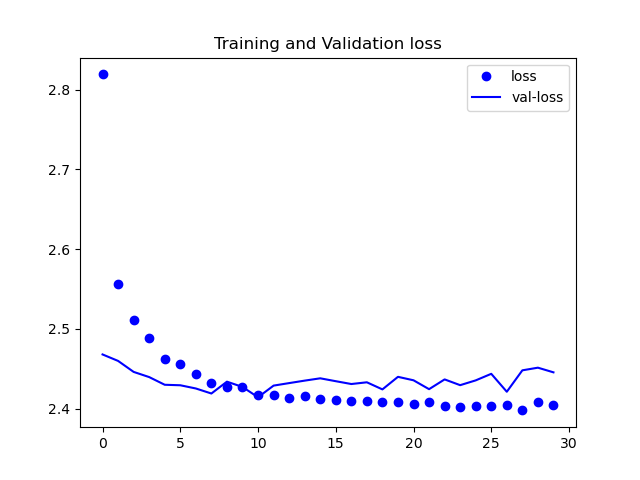
ケース⑥
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 86400) 0
dense (Dense) (None, 2000) 172802000
dropout (Dropout) (None, 2000) 0
dense_1 (Dense) (None, 1000) 2001000
dropout_1 (Dropout) (None, 1000) 0
dense_2 (Dense) (None, 100) 100100
dropout_2 (Dropout) (None, 100) 0
dense_3 (Dense) (None, 18) 1818
=================================================================
Total params: 174,904,918
Trainable params: 174,904,918
Non-trainable params: 0
_________________________________________________________________
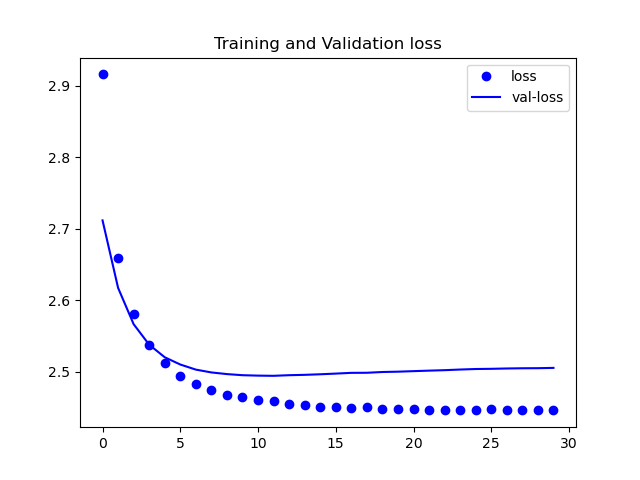
ケース⑦
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 86400) 0
dense (Dense) (None, 3000) 259203000
dropout (Dropout) (None, 3000) 0
dense_1 (Dense) (None, 1000) 3001000
dropout_1 (Dropout) (None, 1000) 0
dense_2 (Dense) (None, 100) 100100
dropout_2 (Dropout) (None, 100) 0
dense_3 (Dense) (None, 18) 1818
=================================================================
Total params: 262,305,918
Trainable params: 262,305,918
Non-trainable params: 0
_________________________________________________________________
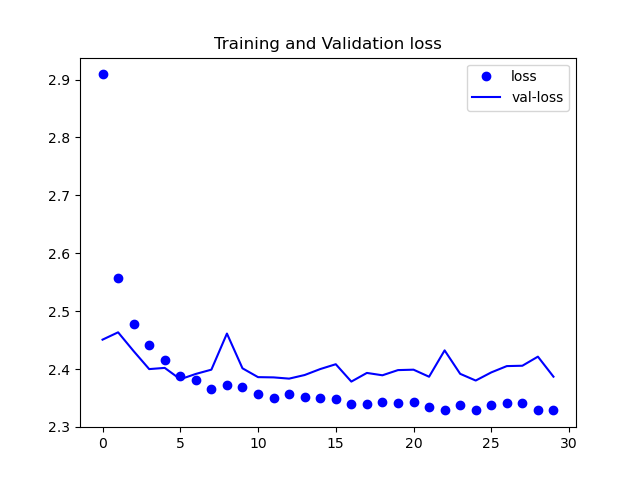
まとめ
見ての通り誤差が下がってはいますが、理想的な数値にまでは至っていません。
また、今回は載せていませんが、精度の方も収束しなかったです。
今回得られたことは以下の通り。
- メモリが足りない
16GBの自作機ですが、今回は画像認識ではないため畳み込みができず、
すべて全結合で行っているため、ユニットの数が足りませんでした。 - ラベリングが必要
データセットの値をラベル化せず、すべて1文字ずつ文字コード化してラベリングをサボったのも、入力変数の増大につながりました。
結果的に、入力変数の数は約86,000近くになりました。 - ネットワークの貧弱さ
上記、入力変数の多さから、メモリ不足のために最初の全結合層のユニット数を3000以上にできませんでした。
理想としては10,000は欲しいところです。 - ネットワークについて
ある程度は予想通りでした。
Dropoutレイヤーをある程度追加すると過学習が発生しないため、エポック数を増やせる。
全結合層のみによる深層学習では、3層以上の多層化ではあまり結果に影響しない。
最初の層でどれだけユニットを設定できるかが肝心。
ラベリングをモデル内で担保するにはユニット数が圧倒的に足りない。
ラベリングしたうえで、入力変数を減らす必要がある。