vmstat を可視化してみる (楽しさ:★☆☆)
あなたが vmstatグラフ化君 を使ってるなら飲み友達。
[root@SAKURA tmp]# vmstat -n 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
2 0 0 1681568 2236 246704 0 0 487 30 438 285 33 2 63 2 0
0 0 0 1681580 2236 246660 0 0 0 0 63 88 0 0 100 0 0
0 0 0 1681580 2236 246660 0 0 0 0 29 55 0 0 100 0 0
0 0 0 1681580 2236 246660 0 0 0 0 51 83 0 1 99 0 0
vmstatは1行1イベントとして扱えるし、各カラムが綺麗にスペースで区切られているので楽ですね。
ただしこのままでは _time 相当の情報がありません。
今回はawkコマンドでタイムスタンプを付与します。(-t付けろとか言わない)
[root@SAKURA tmp]# vmstat -n 1 | awk '{print strftime("date_str:%F %T"), $0}'
date_str:2019-12-01 23:09:06 procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
date_str:2019-12-01 23:09:06 r b swpd free buff cache si so bi bo in cs us sy id wa st
date_str:2019-12-01 23:09:06 2 0 0 1681288 2236 246832 0 0 133 9 145 123 9 1 90 1 0
date_str:2019-12-01 23:09:07 0 0 0 1681288 2236 246832 0 0 0 0 52 67 0 0 100 0 0
date_str:2019-12-01 23:09:08 0 0 0 1681288 2236 246832 0 0 0 0 47 73 0 0 100 0 0
date_str:2019-12-01 23:09:09 0 0 0 1681288 2236 246832 0 0 0 0 44 69 0 1 99 0 0
date_str:2019-12-01 23:09:10 0 0 0 1681288 2236 246832 0 0 0 0 30 59 0 0 100 0 0
date_str:2019-12-01 23:09:11 0 0 0 1681288 2236 246832 0 0 0 0 32 58 0 0 100 0 0
これを任意のファイルにリダイレクトで吐き出してSplunkへデータ追加します。
(今回は可視化させることだけが目的なので手動アップロードして確認します)
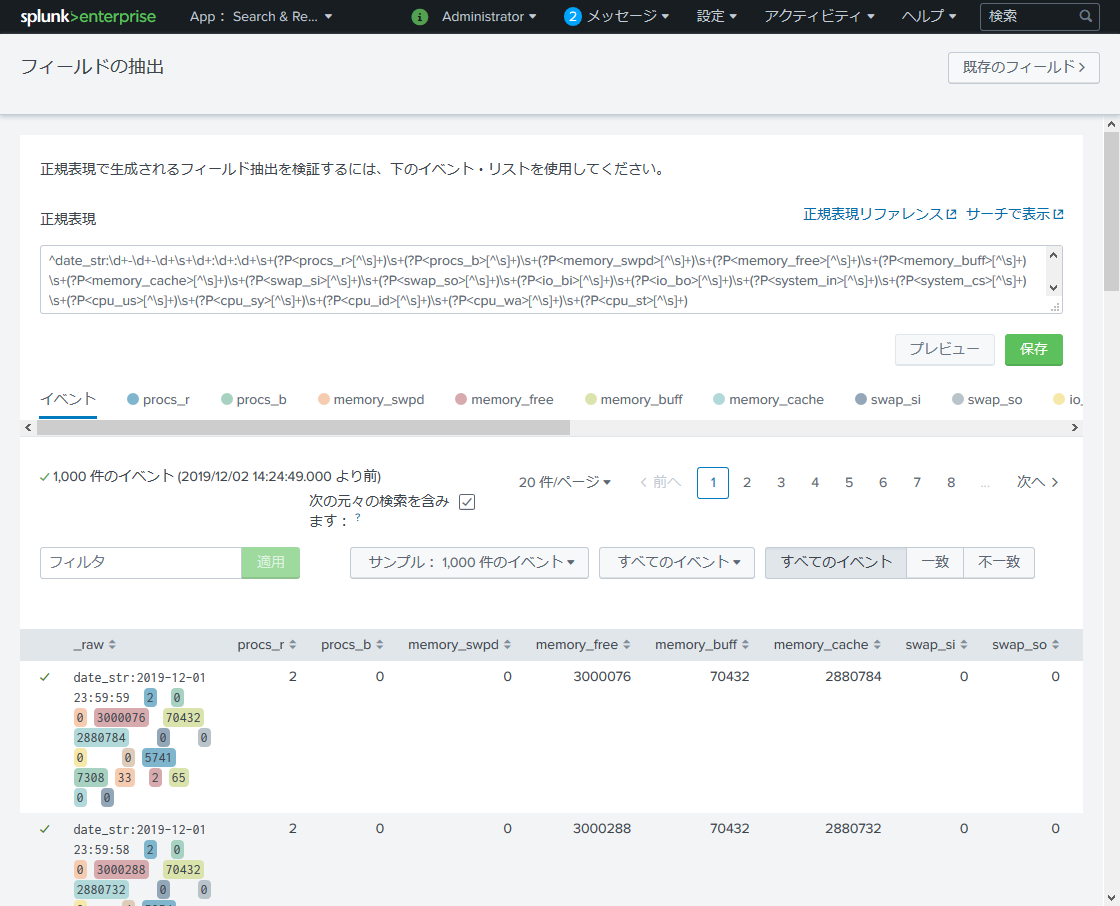
正規表現で各フィールドを vmstat のヘッダ行相当の文字列で抽出します。
使用した正規表現は以下。
^date_str:\d+-\d+-\d+\s+\d+:\d+:\d+\s+(?P<procs_r>[^\s]+)\s+(?P<procs_b>[^\s]+)\s+(?P<memory_swpd>[^\s]+)\s+(?P<memory_free>[^\s]+)\s+(?P<memory_buff>[^\s]+)\s+(?P<memory_cache>[^\s]+)\s+(?P<swap_si>[^\s]+)\s+(?P<swap_so>[^\s]+)\s+(?P<io_bi>[^\s]+)\s+(?P<io_bo>[^\s]+)\s+(?P<system_in>[^\s]+)\s+(?P<system_cs>[^\s]+)\s+(?P<cpu_us>[^\s]+)\s+(?P<cpu_sy>[^\s]+)\s+(?P<cpu_id>[^\s]+)\s+(?P<cpu_wa>[^\s]+)\s+(?P<cpu_st>[^\s]+)
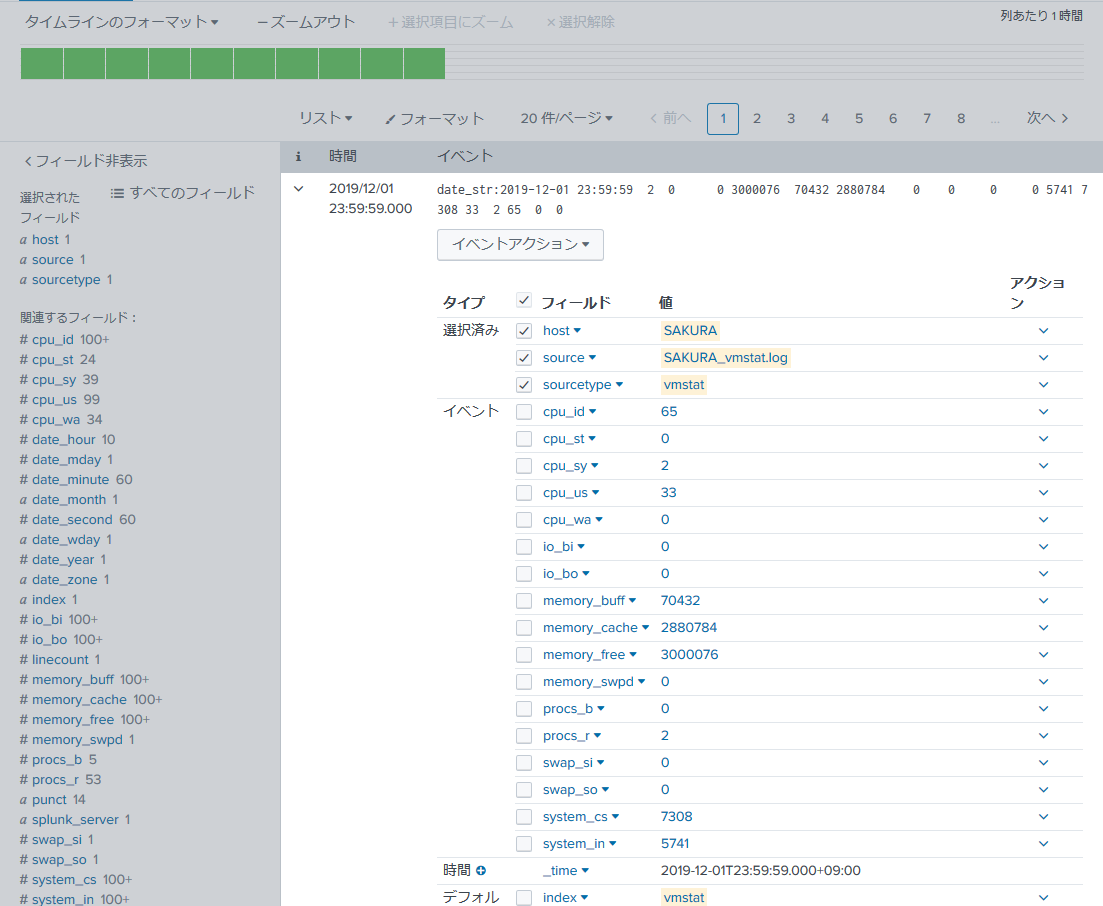
フィールド抽出した後はSearch画面で各フィールド値が抽出できていることを確認しましょう。
抽出時に「不一致」のイベントが無いことを確認するのもポイント。
vmstat の可視化で最も使うのは cpu 項ではないでしょうか。
まずは単純に cpu_id を timechart に入れてみます。
source="SAKURA_vmstat.log" host="SAKURA" index="vmstat" sourcetype="vmstat"
| timechart avg(cpu_id) span=5min
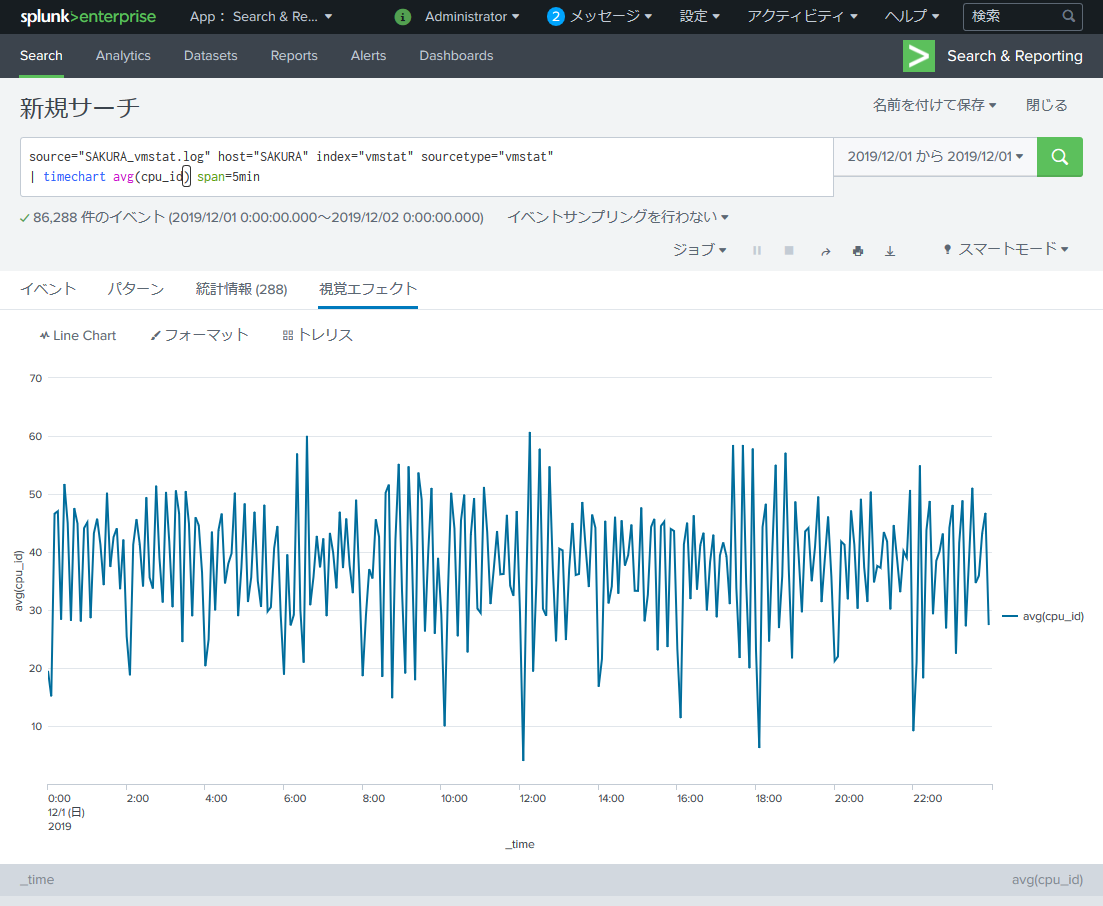
このグラフはCPUのidle状態、すなわち「CPU未使用率」なので eval を使用して「CPU使用率(cpu_use)」を作ります。
source="SAKURA_vmstat.log" host="SAKURA" index="vmstat" sourcetype="vmstat"
| eval cpu_use=100 - cpu_id
| timechart avg(cpu_use) span=5min
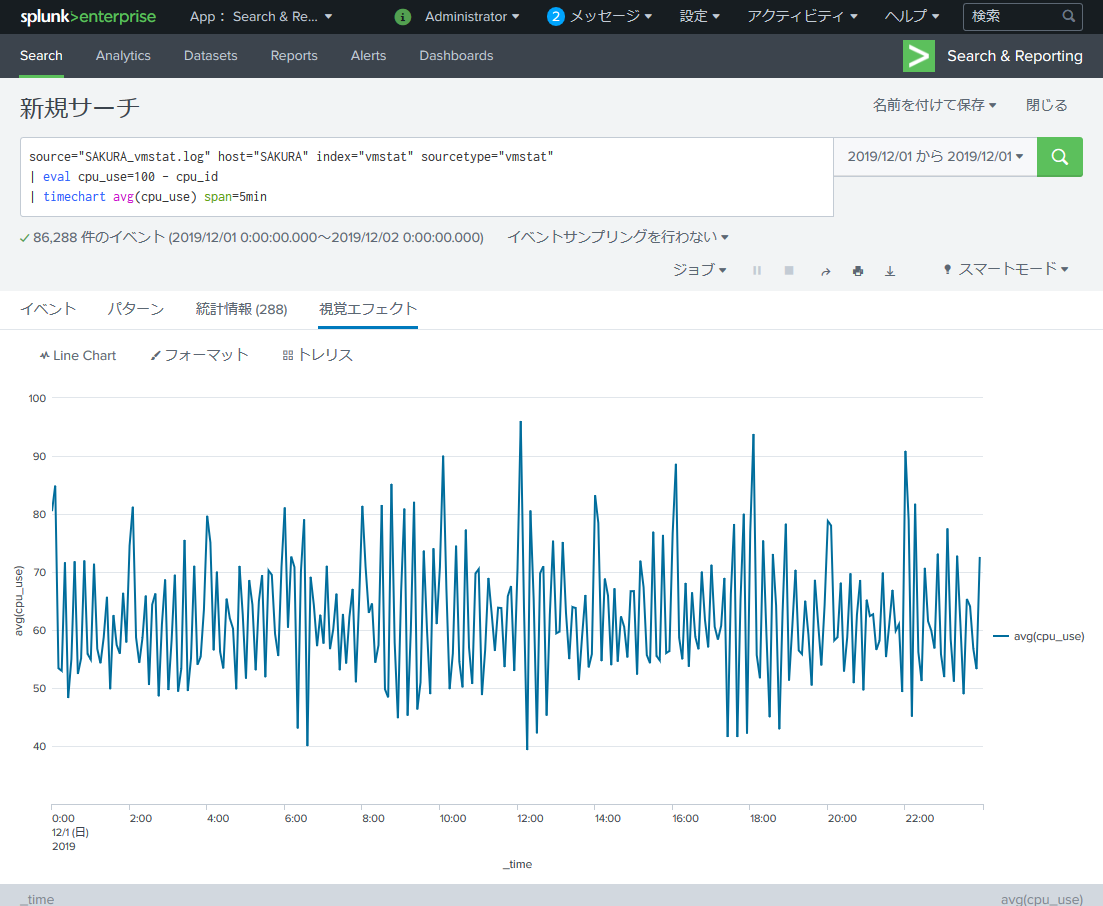
こちらが「CPU使用率」のグラフ。5分毎だと激しすぎてよくわからないので15分毎に変えます。
source="SAKURA_vmstat.log" host="SAKURA" index="vmstat" sourcetype="vmstat"
| eval cpu_use=100 - cpu_id
| timechart avg(cpu_use) span=15min
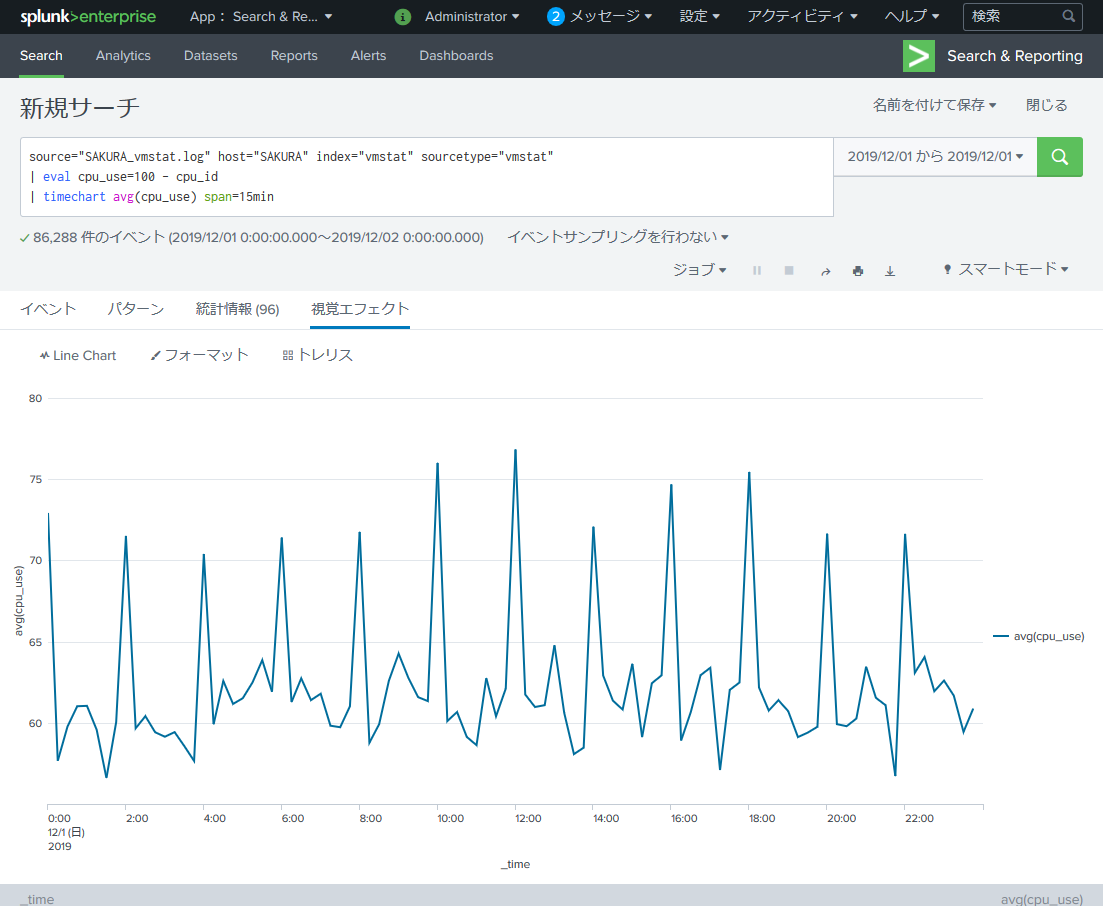
どうやらこのサーバは2時間毎にCPUを大きく消費する定期処理が動作しているようですね。
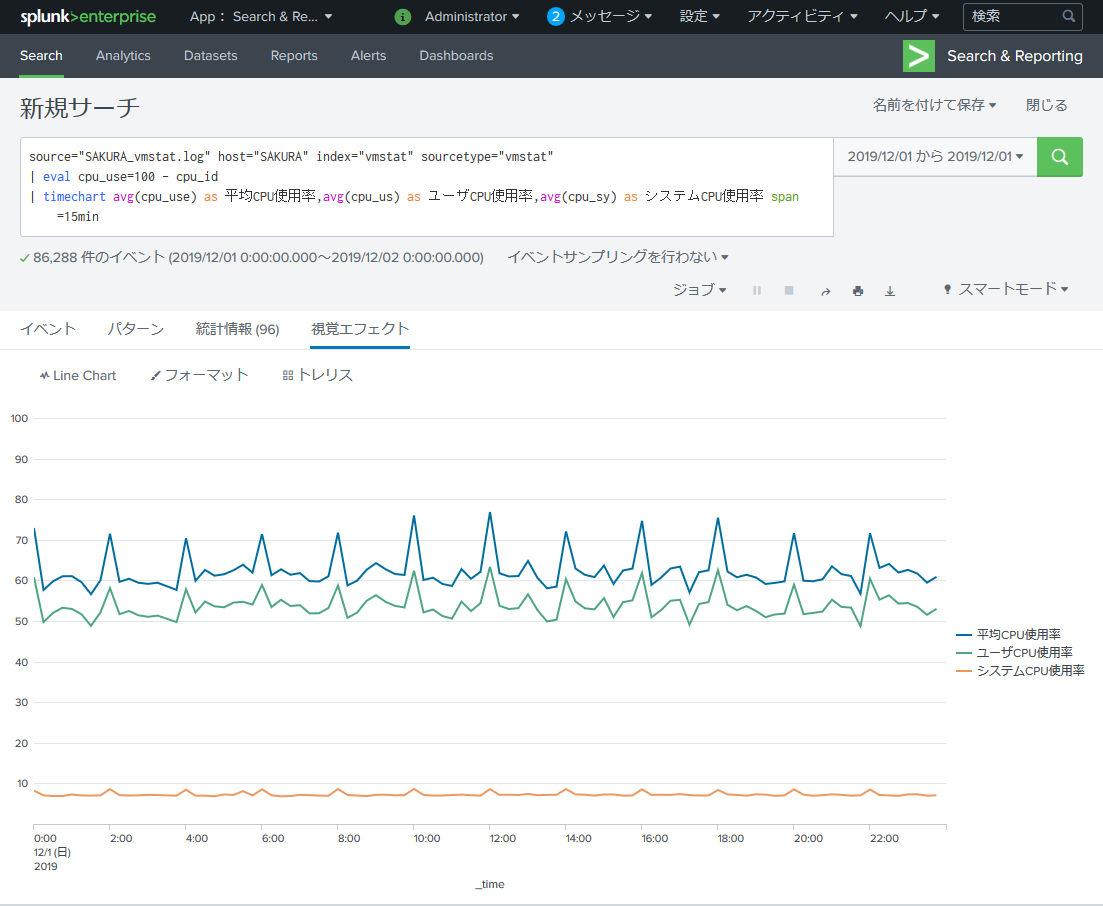
最終的に私が報告で見せる場合は以下のように「ユーザCPU使用率」「システムCPU使用率」も入れます。
同時にフォーマットでY軸を 最小:0 最大:100 間隔:10 にします。
source="SAKURA_vmstat.log" host="SAKURA" index="vmstat" sourcetype="vmstat"
| eval cpu_use=100 - cpu_id
| timechart avg(cpu_use) as 平均CPU使用率,avg(cpu_us) as ユーザCPU使用率,avg(cpu_sy) as システムCPU使用率 span=15min
もし複数のサーバを同時に見る場合は各サーバのログをアップロード後に by host を入れてあげればOKです。
source と host の編集をお忘れなく。
source="*_vmstat.log" index="vmstat" sourcetype="vmstat"
| eval cpu_use=100 - cpu_id
| timechart avg(cpu_use) as 平均CPU使用率,avg(cpu_us) as ユーザCPU使用率,avg(cpu_sy) as システムCPU使用率 by host span=15min
iostat を可視化してみる (楽しさ:★★☆)
iostat のコマンドは以下を使用します。
[root@SAKURA tmp]# /usr/bin/iostat -kdxt 10
Linux x.x.xx-xxx.x.x.elx.x86_64 (SAKURA) 2019年12月01日 _x86_64_ (x CPU)
2019年12月01日 00時00分00秒
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
vda 0.00 31.00 0.00 6.90 0.00 150.00 43.48 0.01 1.22 0.29 0.20
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.00 1.00 1.00 0.03
dm-2 0.00 0.00 0.00 5.10 0.00 20.40 8.00 0.02 3.76 0.14 0.07
dm-3 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.00 0.00 0.00 0.00
dm-4 0.00 0.00 0.00 31.70 0.00 126.80 8.00 0.04 1.36 0.03 0.10
2019年12月01日 00時00分10秒
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
vda 0.00 65.70 37.00 18.40 9981.20 336.00 372.46 3.59 63.32 14.41 79.84
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-1 0.00 0.00 0.70 0.80 8.40 3.20 15.47 0.07 46.87 19.20 2.88
dm-2 0.00 0.00 0.00 1.60 0.00 6.40 8.00 0.05 29.94 11.56 1.85
dm-3 0.00 0.00 0.00 3.30 0.00 13.20 8.00 0.04 11.91 7.09 2.34
dm-4 0.00 0.00 37.80 78.30 10069.60 313.20 178.86 6.29 53.44 6.84 79.44
取り込む前に perl スクリプトなどで日時フォーマットを変えてしまします。
date_str:2019-12-01 00:00:00
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
vda 0.00 31.00 0.00 6.90 0.00 150.00 43.48 0.01 1.22 0.29 0.20
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-1 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.00 1.00 1.00 0.03
dm-2 0.00 0.00 0.00 5.10 0.00 20.40 8.00 0.02 3.76 0.14 0.07
dm-3 0.00 0.00 0.00 0.30 0.00 1.20 8.00 0.00 0.00 0.00 0.00
dm-4 0.00 0.00 0.00 31.70 0.00 126.80 8.00 0.04 1.36 0.03 0.10
date_str:2019-12-01 00:00:10
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util
vda 0.00 65.70 37.00 18.40 9981.20 336.00 372.46 3.59 63.32 14.41 79.84
dm-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-1 0.00 0.00 0.70 0.80 8.40 3.20 15.47 0.07 46.87 19.20 2.88
dm-2 0.00 0.00 0.00 1.60 0.00 6.40 8.00 0.05 29.94 11.56 1.85
dm-3 0.00 0.00 0.00 3.30 0.00 13.20 8.00 0.04 11.91 7.09 2.34
dm-4 0.00 0.00 37.80 78.30 10069.60 313.20 178.86 6.29 53.44 6.84 79.44
今回は vmstat とは異なり、複数行で1イベントです。
取り込む時には各行がイベントと認識されるように指定します。
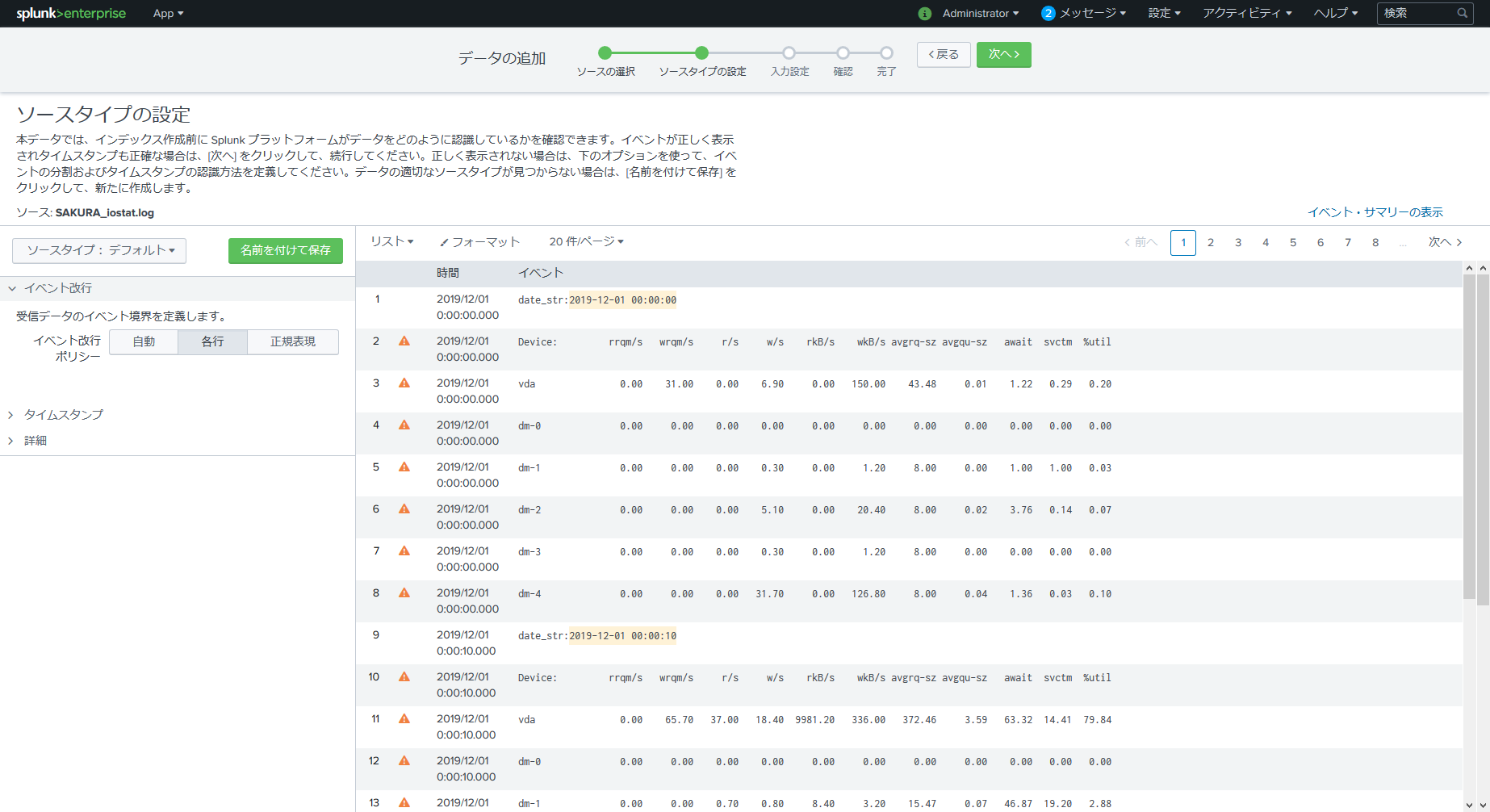
各行に時間が割り当てられていることを確認しましょう。
今回のフィールド抽出の正規表現は以下のとおりです。
^(?P<device>[^\s]+)\s+(?P<rrqm>[^\s]+)\s+(?P<wrqm>[^\s]+)\s+(?P<r>[^\s]+)\s+(?P<w>[^\s]+)\s+(?P<rkB>[^\s]+)\s+(?P<wkB>[^\s]+)\s+(?P<avgrq_sz>[^\s]+)\s+(?P<avgqu_sz>[^\s]+)\s+(?P<await>[^\s]+)\s+(?P<svctm>[^\s]+)\s+(?P<util>[^\s]+)
iostat はどのフィールドを見れば良いのか?は以下のスライドがわかりやすいです。
iostat await svctm の 見かた、考え方
from 歩 柴田, 日本オラクル - Consultant 様。
上記に従って await と svctm を見てみます。
index=iostat sourcetype=iostat host="SAKURA" source="SAKURA_iostat.log"
| timechart avg(await),avg(svctm) by device span=5min
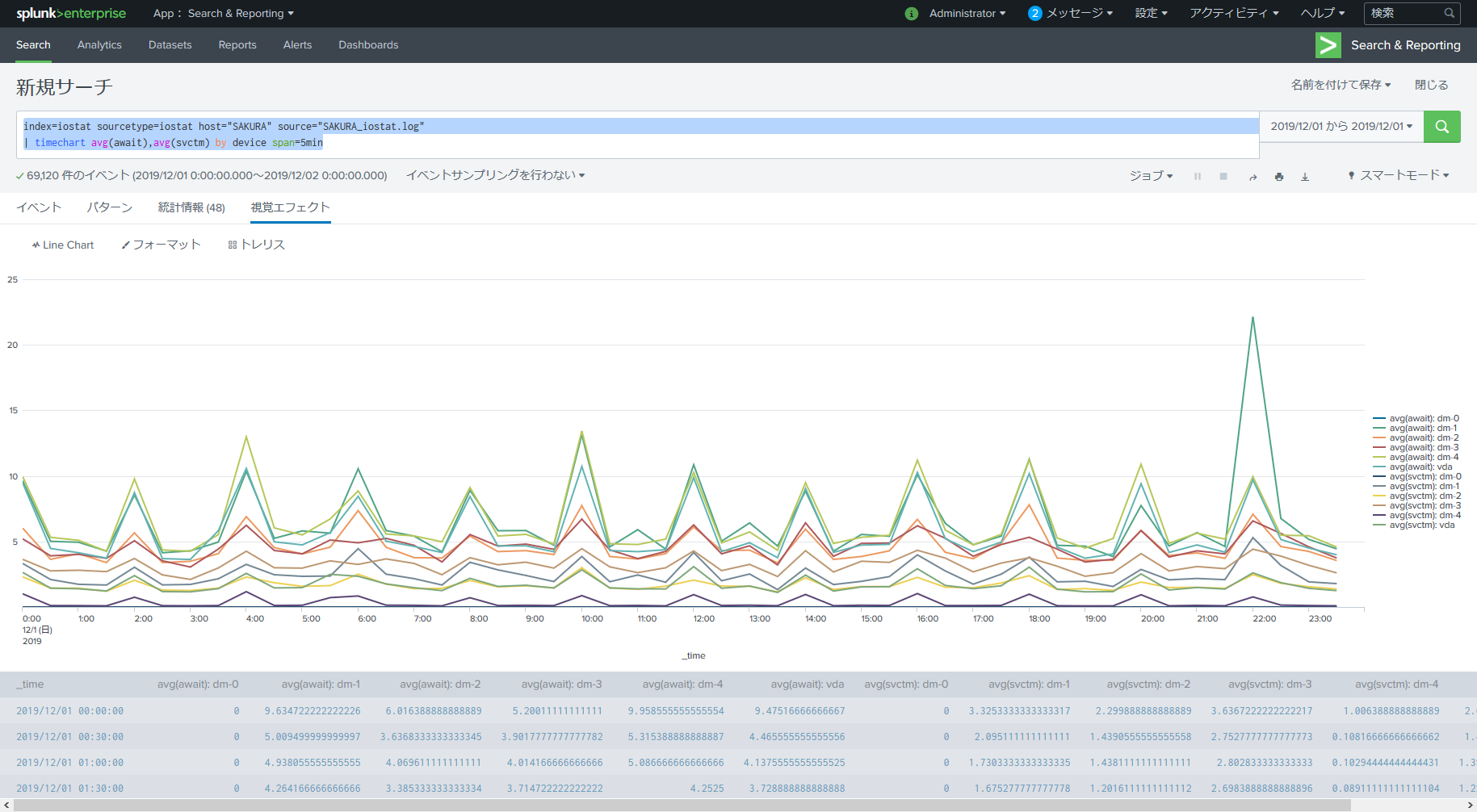
わーいカラフル~w
しかし「dm-x」だとイマイチなにかわからないので実際のパーティション情報と紐付けます。
[root@SAKURA ~]# df -hP
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup001-lv_root 69G 7.0G 59G 11% /
tmpfs 3.9G 57M 3.8G 2% /dev/shm
/dev/vda1 477M 28M 424M 7% /boot
/dev/mapper/VolGroup001-lv_home 20G 383M 19G 3% /home
/dev/mapper/VolGroup001-lv_apl 40G 25G 13G 67% /opt
/dev/mapper/VolGroup001-lv_log 30G 84M 28G 1% /var/log
[root@SAKURA ~]# ls -l /dev/mapper/
合計 0
lrwxrwxrwx 1 root root 7 11月 29 02:26 2019 VolGroup001-lv_apl -> ../dm-4
lrwxrwxrwx 1 root root 7 11月 29 02:26 2019 VolGroup001-lv_home -> ../dm-2
lrwxrwxrwx 1 root root 7 11月 29 02:26 2019 VolGroup001-lv_log -> ../dm-3
lrwxrwxrwx 1 root root 7 11月 29 02:26 2019 VolGroup001-lv_root -> ../dm-1
lrwxrwxrwx 1 root root 7 11月 29 02:26 2019 VolGroup001-lv_swap -> ../dm-0
crw-rw---- 1 root root 10, 58 11月 29 02:26 2019 control
今回のサーバは上記のとおりです。
ココで以下のCSVを作成します。
device,part_name
dm-0,swap
dm-1,root
dm-2,home
dm-3,log
dm-4,apl
上記を UTF-8 で device2part_name.csv という名前でPC上の任意の場所に保存します。
続いて Splunk の上部メニューより 設定 > ルックアップ を開きます。
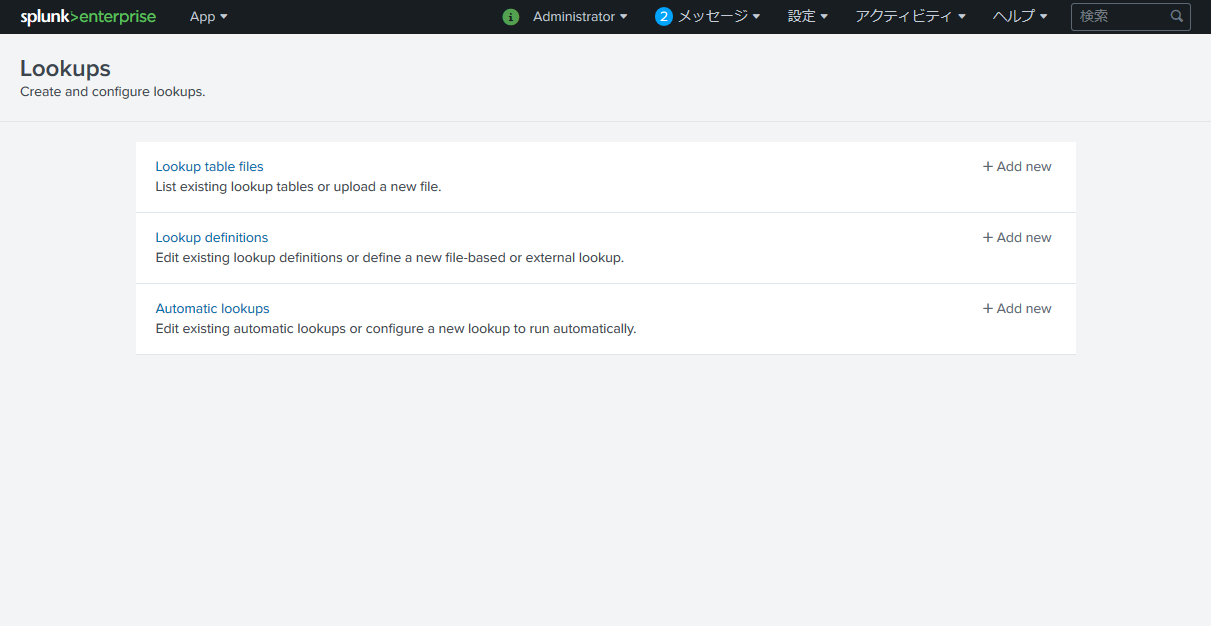
まずは Lookup table files の右端の + Add new を選択。
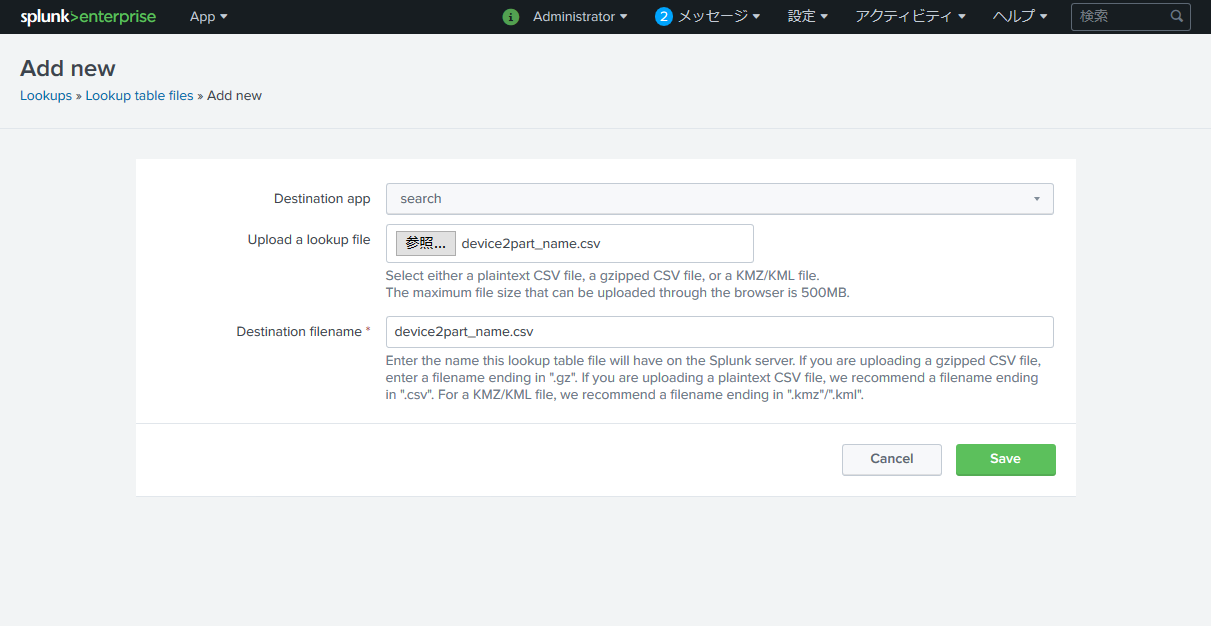
Upload a lookup file の 参照 を押して、先程作成したCSVを選択。
Destination filename にCSVファイル名と同じ文字列を指定して Save。
もう一度 設定 > ルックアップ を開きます。
今度は Lookup definitions の右端の + Add new を選択。
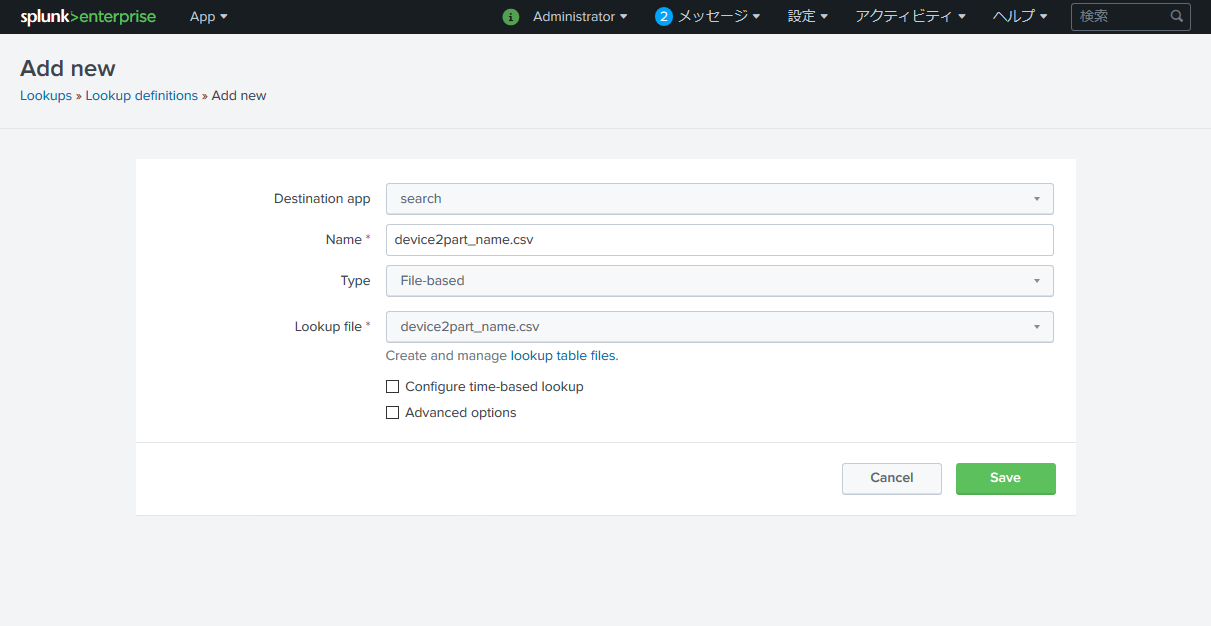
Name に再びCSV名を入れ、
Lookup file は Destination filename で指定した名前を選択して Save 。
これで準備ができたので Search に戻ります。
先程の Search文 に対して、device から part_name を引き込みます。
index=iostat sourcetype=iostat host="SAKURA" source="SAKURA_iostat.log"
| lookup device2part_name.csv device OUTPUT part_name
| timechart avg(await),avg(svctm) by part_name span=5min
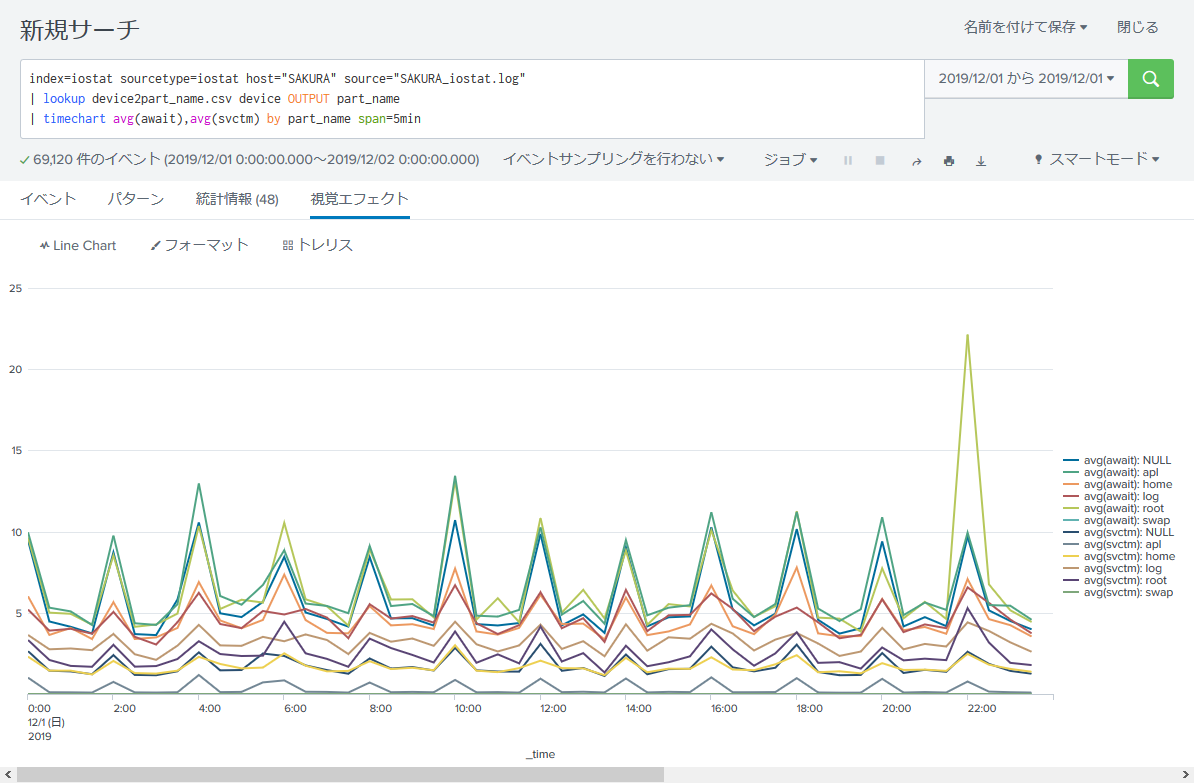
右端の凡例を見るとパーティション名が引き込まれていることが確認できます。
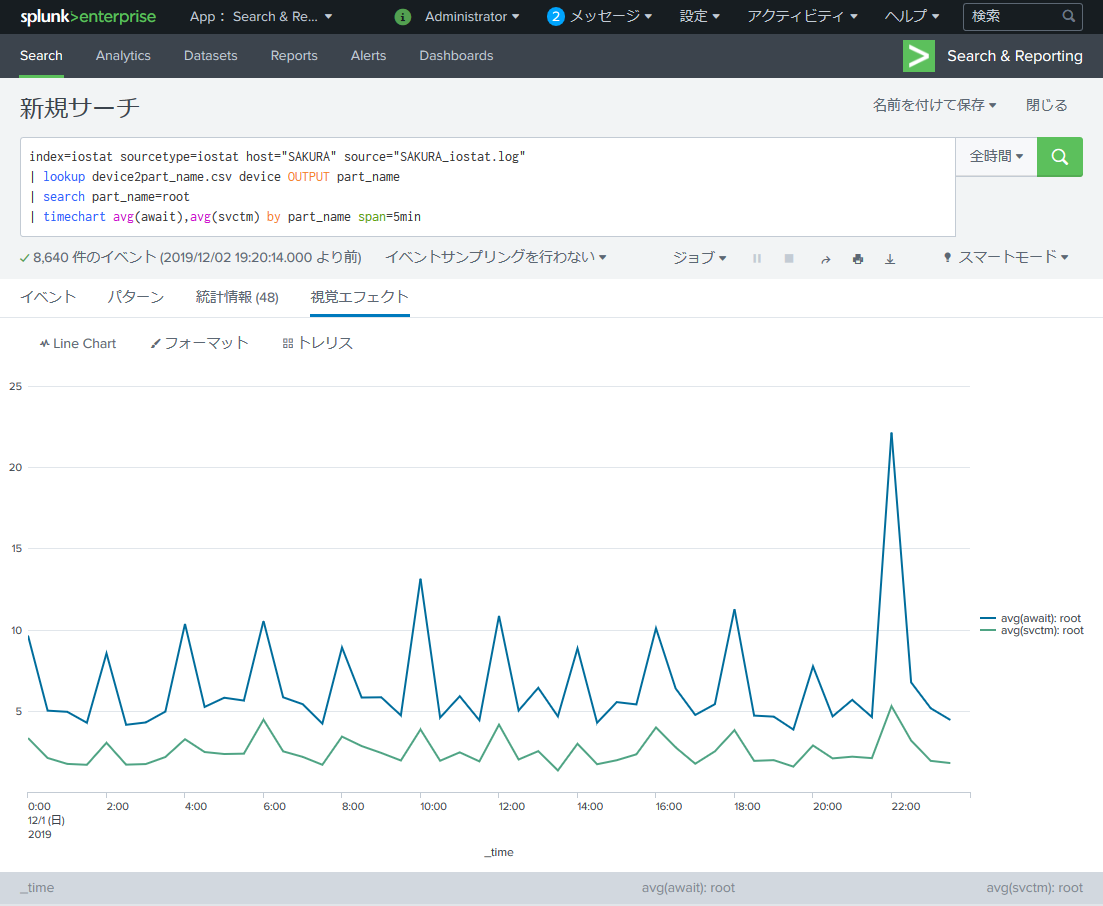
root パーティションで絞り込んでみます。
index=iostat sourcetype=iostat host="SAKURA" source="SAKURA_iostat.log"
| lookup device2part_name.csv device OUTPUT part_name
| search part_name=root
| timechart avg(await),avg(svctm) by part_name span=5min
ps を可視化してみる (楽しさ:★★★)
複数のアプリケーションを立ち上げているサーバで有用です。
常駐プロセスが大量に動作しているサーバで実行すると色んなものが見えてしまって楽しいです。
ps の情報収集は以下を使用します。
[root@SAKURA ~]# while :
> do
> date +'date_str:%F %T'
> /bin/ps -eww -o pid,stime,pcpu,pmem,vsz,size,rss,args
> sleep 300
> done
date_str:2019-12-01 00:04:22
PID STIME %CPU %MEM VSZ SZ RSS COMMAND
2 Nov29 0.0 0.0 0 0 0 [kthreadd]
3 Nov29 0.0 0.0 0 0 0 [migration/0]
:(省略)
27471 Nov29 0.0 0.1 287636 211492 15156 /usr/local/bin/DDCE -implid IDL:DST_EAST_5-interfaces:1.0 -id 210982774 ki2neudon
27302 Nov29 0.0 0.2 288656 212512 16164 /usr/local/bin/DDCE -implid IDL:DST_EAST_1-interfaces:1.0 -id 210982766 ki2neudon
5450 Nov29 0.0 0.2 119736 6616 19340 /usr/libexec/pacemaker/pengine
14498 Nov29 0.9 0.2 340432 265612 19828 /usr/local/bin/DDCA_mt -implid IDL:DST_WEST_1-interfaces:1.0 -id 100003098 ki2neudon
26674 Nov29 9.8 0.3 345860 269716 25696 /usr/local/bin/DDCE -implid IDL:DST_EAST_1-interfaces:1.0 -id 210982742 ki2neudon
date_str:2019-12-01 00:09:23
PID STIME %CPU %MEM VSZ SZ RSS COMMAND
2 Nov29 0.0 0.0 0 0 0 [kthreadd]
3 Nov29 0.0 0.0 0 0 0 [migration/0]
:(省略)
300秒毎に /bin/ps -eww -o pid,stime,pcpu,pmem,vsz,size,rss,args を実行したログ、ということです。
取り込む時は iostat と同様に1行1イベントとなるようにします。
フィールドの抽出は以下の正規表現で行いました。
^\s*(?P<pid>\d+)\s+(?P<stime>[^\s]+)\s+(?P<cpu>[^\s]+)\s+(?P<mem>[^\s]+)\s+(?P<vsz>[^\s]+)\s+(?P<sz>[^\s]+)\s+(?P<rss>[^\s]+)\s+(?P<command>.*)$
今回は ps コマンドログから各プロセスの実メモリ使用量(RSS)を可視化します。
何も考えずに RSS を timechart で確認してみます。
source="SAKURA_ps.log" host="SAKURA" index="ps" sourcetype="ps"
|timechart avg(rss) by command span=15min useother=false limit=1000
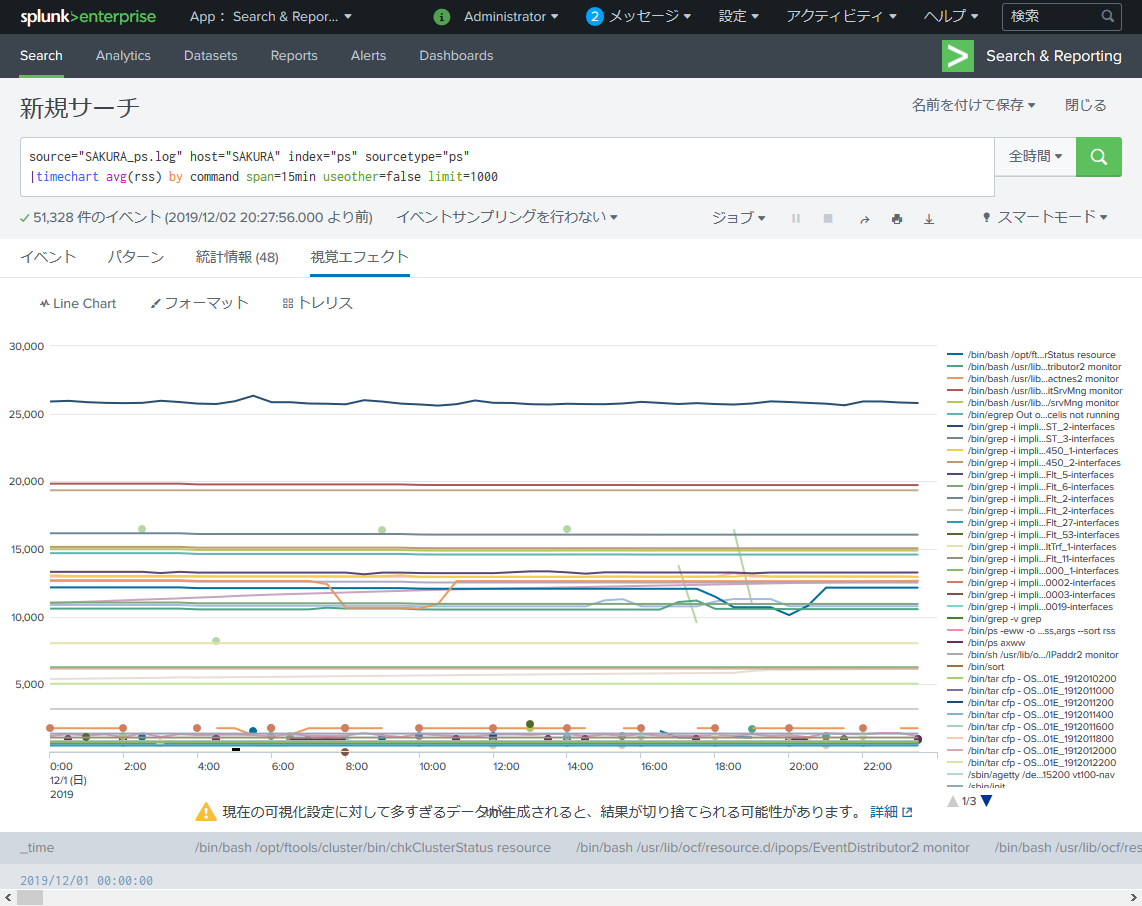
わ~いカラフル~w
ここで「確認したいプロセス」に絞り込みを行います。
PID STIME %CPU %MEM VSZ SZ RSS COMMAND
2 Nov29 0.0 0.0 0 0 0 [kthreadd]
3 Nov29 0.0 0.0 0 0 0 [migration/0]
:(省略)
27471 Nov29 0.0 0.1 287636 211492 15156 /usr/local/bin/DDCE -implid IDL:DST_EAST_5-interfaces:1.0 -id 210982774 ki2neudon
27302 Nov29 0.0 0.2 288656 212512 16164 /usr/local/bin/DDCE -implid IDL:DST_EAST_1-interfaces:1.0 -id 210982766 ki2neudon
5450 Nov29 0.0 0.2 119736 6616 19340 /usr/libexec/pacemaker/pengine
14498 Nov29 0.9 0.2 340432 265612 19828 /usr/local/bin/DDCA_mt -implid IDL:DST_WEST_1-interfaces:1.0 -id 100003098 ki2neudon
26674 Nov29 9.8 0.3 345860 269716 25696 /usr/local/bin/DDCE -implid IDL:DST_EAST_1-interfaces:1.0 -id 210982742 ki2neudon
今回は /usr/local/bin/{DDCE|DDCA_mt} というプロセスに絞って確認します。
※実在しない、この記事のために作成したアプリケーションです。
source="SAKURA_ps.log" host="SAKURA" index="ps" sourcetype="ps" command="*local/bin/DDCE*" OR command="*local/bin/DDCA*"
|timechart avg(rss) by command span=15min useother=false
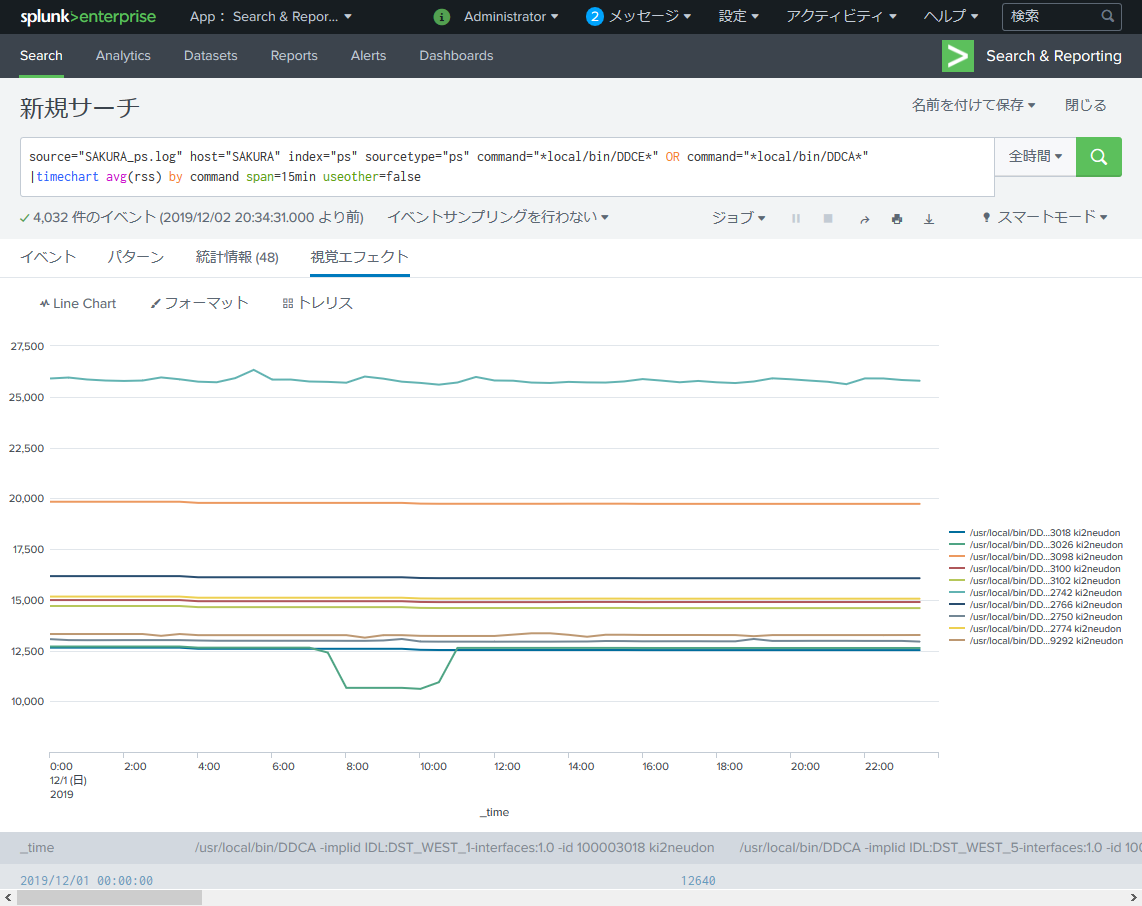
だいぶスッキリしました。
しかしこのままでは凡例部分が潰れてしまいよくわかりません。
27471 Nov29 0.0 0.1 287636 211492 15156 /usr/local/bin/DDCE -implid IDL:DST_EAST_5-interfaces:1.0 -id 210982774 ki2neudon
27302 Nov29 0.0 0.2 288656 212512 16164 /usr/local/bin/DDCE -implid IDL:DST_EAST_1-interfaces:1.0 -id 210982766 ki2neudon
14498 Nov29 0.9 0.2 340432 265612 19828 /usr/local/bin/DDCA_mt -implid IDL:DST_WEST_1-interfaces:1.0 -id 100003098 ki2neudon
26674 Nov29 9.8 0.3 345860 269716 25696 /usr/local/bin/DDCE -implid IDL:DST_EAST_1-interfaces:1.0 -id 210982742 ki2neudon
なので、引数の -id の後に続く文字列を新たに ID フィールドとして抽出します。
正規表現でフィールドを抽出するには rex を使います。
source="SAKURA_ps.log" host="SAKURA" index="ps" sourcetype="ps" command="*local/bin/DDCE*" OR command="*local/bin/DDCA*"
|rex field=command "-id\s(?P<id>[^\s]+)\s"
|timechart avg(rss) by id span=5min useother=false limit=20
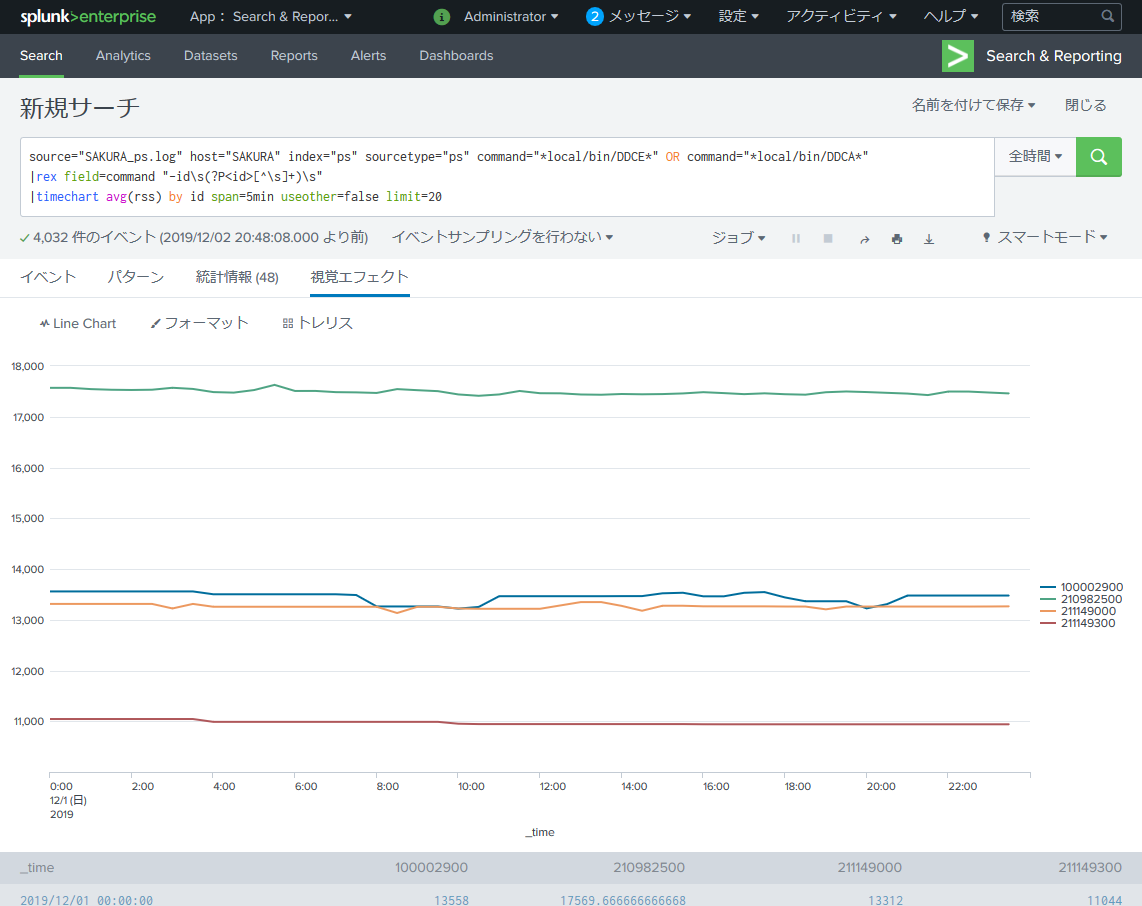
…なにかおかしい。
プロセスが4つしか存在しません。
実際は以下のプロセスが存在します。
/usr/local/bin/DDCA -implid IDL:DST_WEST_4-interfaces:1.0 -id 100003024 ki2neudon
/usr/local/bin/DDCA -implid IDL:DST_WEST_2-interfaces:1.0 -id 100003020 ki2neudon
/usr/local/bin/DDCE -implid IDL:DST_EAST_9-interfaces:1.0 -id 211149306 ki2neudon
/usr/local/bin/DDCA -implid IDL:DST_WEST_3-interfaces:1.0 -id 100003022 ki2neudon
/usr/local/bin/DDCA -implid IDL:DST_WEST_1-interfaces:1.0 -id 100003018 ki2neudon
/usr/local/bin/DDCA -implid IDL:DST_WEST_5-interfaces:1.0 -id 100003026 ki2neudon
/usr/local/bin/DDCE -implid IDL:DST_EAST_5-interfaces:1.0 -id 210982750 ki2neudon
/usr/local/bin/DDCE -implid IDL:DST_EAST_9-interfaces:1.0 -id 211149292 ki2neudon
/usr/local/bin/DDCA_mt -implid IDL:DST_WEST_3-interfaces:1.0 -id 100003102 ki2neudon
/usr/local/bin/DDCA_mt -implid IDL:DST_WEST_2-interfaces:1.0 -id 100003100 ki2neudon
/usr/local/bin/DDCE -implid IDL:DST_EAST_5-interfaces:1.0 -id 210982774 ki2neudon
/usr/local/bin/DDCE -implid IDL:DST_EAST_1-interfaces:1.0 -id 210982766 ki2neudon
/usr/local/bin/DDCA_mt -implid IDL:DST_WEST_1-interfaces:1.0 -id 100003098 ki2neudon
/usr/local/bin/DDCE -implid IDL:DST_EAST_1-interfaces:1.0 -id 210982742 ki2neudon
これは切り出した-idパラメータが四捨五入されて丸め込められてしまっています。
rex の sed を利用して「ID_」という文字列を付与することで対処します。
source="SAKURA_ps.log" host="SAKURA" index="ps" sourcetype="ps" command="*local/bin/DDCE*" OR command="*local/bin/DDCA*"
|rex mode=sed "s/^\/usr\/local\/bin\/DD.*\-id\s+/ID_/g" field=command
|rex mode=sed "s/\s+ki2neudon.*$//g" field=command
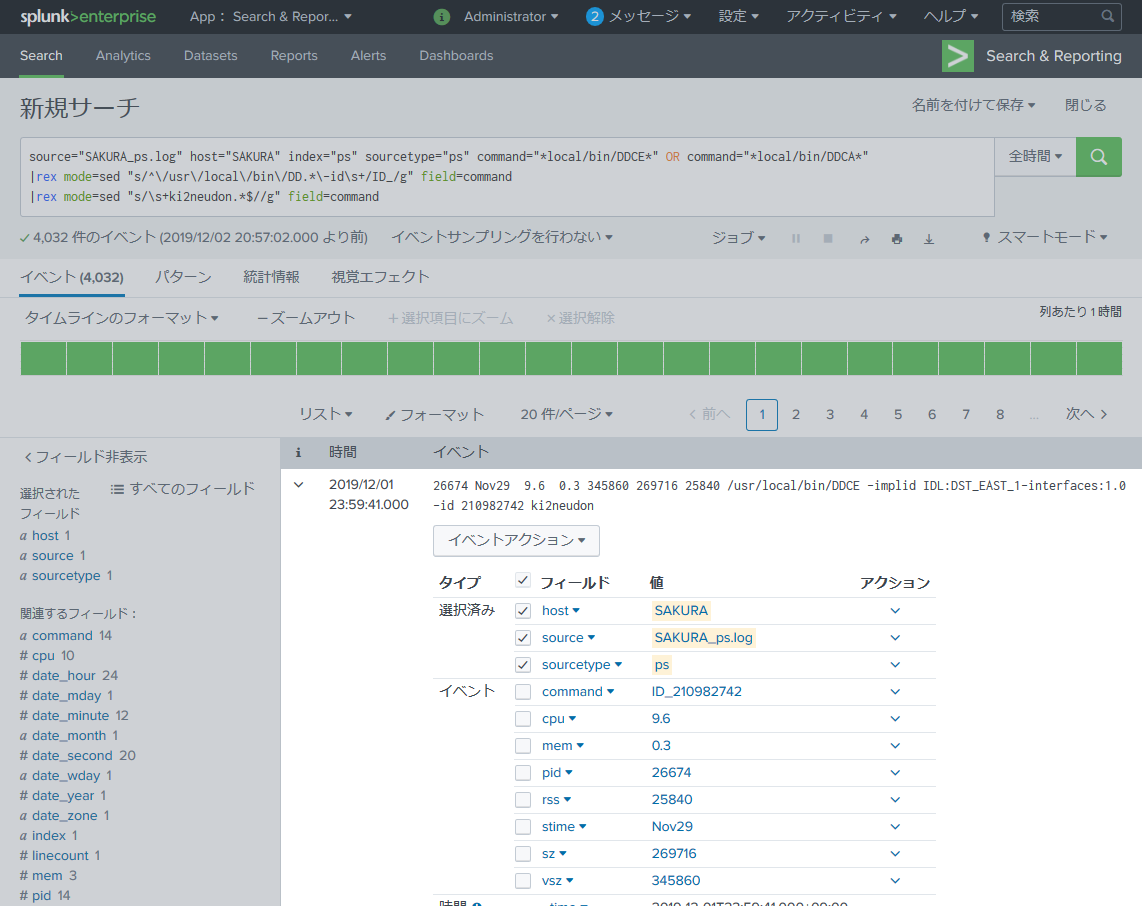
command フィールドが 「ID_xxxxx」 になりました。これで丸め込まれることはありません。
source="SAKURA_ps.log" host="SAKURA" index="ps" sourcetype="ps" command="*local/bin/DDCE*" OR command="*local/bin/DDCA*"
|rex mode=sed "s/^\/usr\/local\/bin\/DD.*\-id\s+/ID_/g" field=command
|rex mode=sed "s/\s+ki2neudon.*$//g" field=command
|timechart avg(rss) by command span=5min useother=false limit=20
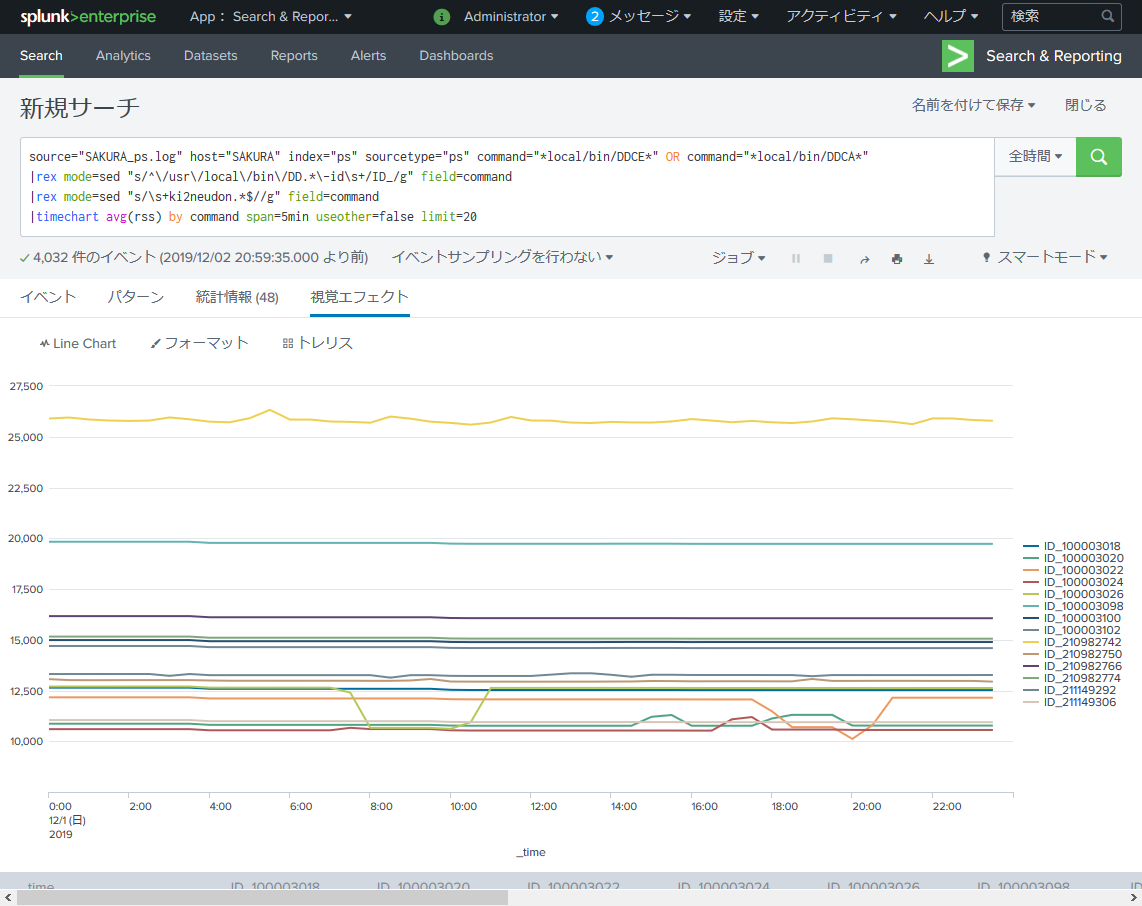
ここで右肩上がりのプロセスが居ると「メモリリークだ!」とか疑えて面白んですけどね。
Splunk を使う利点
手軽に可視化できることがもちろんのこと、「アップロードしたデータが結果だけでなく、ログごと残ること」が一番嬉しいです。
ここで紹介した内容はExcelでも可能ですが、その場合は「結果」のみ残してログは捨ててしまいがちです。
Splunk にアップロードすることで、例えば数年後に「あの時の ps コマンドの vsz はどうだった??」と後からデータを見直すことができます。
またSQLライクに「あれはどうだ?」「これはどうだ?」を試せるので、Excelの長い計算時間に思い悩むこともありません。
データの可視化に時間を掛けてしまっている…と思う人は是非試してみてください!
補足
今回はアナログにLinuxコマンド結果を利用してリソースを可視化しましたが
Splunk にはリソース監視に特化した Splunk Insights for Infrastructure も存在します。
興味のある方はぜひ。
そして使い勝手を私に教えて下さい…!!
おわりに
-
Splunkってスゲェな!俺もSplunkに興味湧いてきたぜ! - 私も
Splunk大好き!一緒に盛り上げよう!!
という方は「イイネ」を!
- フィールド抽出の正規表現、こうしたらスマートだぜ!
-
rexで切り出した数値が丸め込まれないようにするのはこうするんだぜ! - こういうサーバリソースはどうやって可視化できる?
- ちょっとここの操作、もうちょっとkwsk!
という方は是非、コメントを!
そして Go Japan Splunk User Group への参加登録をよろしくお願いします!
「Go Japan Splunk User Group って何?」という方はGOJASの歴史とこれからの活動 もご確認ください!