PostgreSQLを使用していたのが2015年前後で、いま(2023年)のPostgreSQLはなんかちょっと違うみたい?
-
recovery.confが無い?? - レプリケーションスロットってなんだ?
あと現場で使って体感で覚えていたところを基礎から学び直そうというお話。
目的
急遽業務で以下の構成を構築することに。
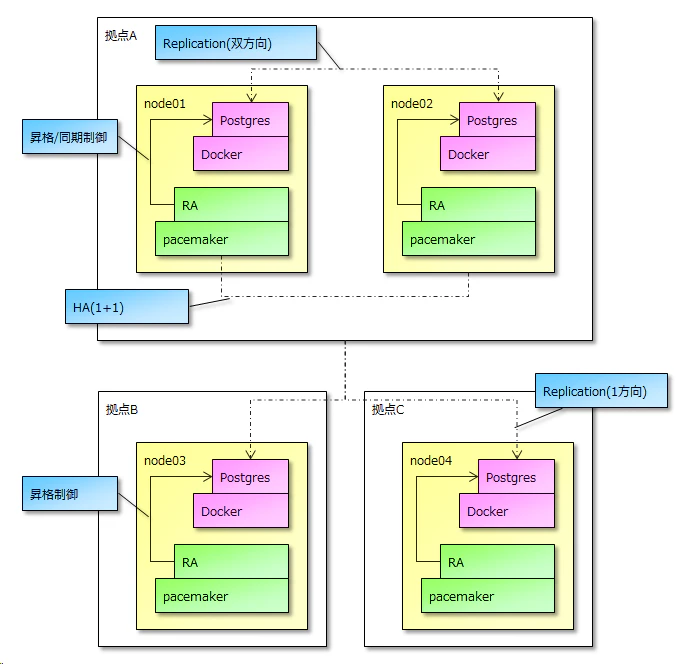
- 物理サーバは3台以上
- 2台は1+1のHA構成(Pacemaker)
- 3台目以降は1+1が故障した/定期メンテナンスした場合にのみ起動
- 3台目以降は1+1のプライマリ側からストリーミングされるのみ。3台目以降同士で同期はしない
- node01, node02が停止した場合はnode03, node04がそれぞれ独立して稼働し、DBのマスターは分散することになる
- 業務データにCreate, Update, Deleteを行うAppは拠点Aにしかいない
- 拠点B,CのAppは操作履歴のCreateのみ行う
- 拠点Aが復帰後はknode03,node04どちらかを
pg_basebackupし、追加で他方の操作履歴テーブルの差分のみINSERTして復元する
- スタンバイ系への負荷分散を目的としたAppからの参照は原則行われない
- Replicationは高可用性のみを目的とする
本記事で扱わない内容
- 実機検証
- 結論などのまとめ
- 目的以外に関わらない内容(以下参照)
以下を学ぶ必要がある
- いまどきのReplication設定方法
- 拠点B, 拠点Cは拠点Aのnode01, node02の参照をどうやって切り替えるのか
参考図書
- 動画から学ぶ
- PostgreSQLのレプリケーションを使ってみよう 2021-1-30 A-4
- オープンソースカンファレンス(OSC)2021 OnlineOsakaのセッション
- 日本PostgreSQLユーザ会 関西支部長 寺内さんのセッション
学んだこと覚書
レプリケーション方式(動画 3分29秒)
- ウォームスタンバイ
- スタンバイ系は遊んでいるReadアクセスも不可能
- ホットスタンバイ
- スタンバイ系はReadアクセス可能
| スタンバイ方式 | 方式 | 特徴 |
|---|---|---|
| ウォーム | 共有ディスク | NASとかデータ領域を物理的に共有する。マルチパスドライバとかでアクセス制御する |
| ウォーム | ファイルシステムレプリケーション | lsync/rsyncみたいにソフトレベルでファイル同期を実現 |
| ホット | ログシッピング | みんな大好きWAL(Write Ahead Logging) |
| ホット | トリガーベースレプリ | プライマリへの更新をトリガーでスタンバイに伝搬。こわっ |
| ホット | SQLベースレプリ | そもそも更新SQLをプライマリ/スタンバイに送ったろ。なるほどね |
トリガーベースを「こわっ」て言ってるのは、作り方次第とは思うけど、そのトリガーが成功しないと(スタンバイが生きていないと)プライマリの更新も失敗するんじゃないん?という感想。
レプリケーションのPostgreSQL標準方式(動画 6分20秒)
PostgreSQLの標準方式は「ログシッピング」。他は物理的、他のミドル、DDLでの対応のため。標準方式に2種類ある。
- ストリーミングレプリケーション
- WALをファイル単位ではなく変更内容単位で送る
- WAL = 16MB単位。ファイル単位だと16MBの更新ログが溜まらないと同期されない
-
 メリット
メリット
- プライマリとスタンバイは物理的に同じデータ
- プライマリでコミット済みデータをスタンバイで必ず「書き込み済み」にできる(む?)
- 参照負荷分散が可能
-
 デメリット
デメリット
- 今回の目的的には特に困らない
- WALをファイル単位ではなく変更内容単位で送る
- ロジカル(論理)レプリケーション
- WALを外部のシステムが解釈できるデータにデコード
-
メリット
- 一部の表に対する更新だけスタンバイに送ることも可能
- 複数のプライマリの出力を1つのスタンバイで受け取れる

- メジャーバージョンの異なるPostgreSQL間で利用できる
- スタンバイのデータベースを更新できる
-
デメリット
- プライマリとスタンバイは物理的に異なるデータ
- 不整合に気をつける
え。![]() どうしよう。冒頭に書いた構成はこれじゃないと駄目…なんてないよね…
どうしよう。冒頭に書いた構成はこれじゃないと駄目…なんてないよね…
レプリ先を動的に変える方法があればいいんだよね…(あんのかなそんな方法)
ストリーミングレプリケーションの仕組み(動画 11分50秒)
- クライアントがプライマリに更新SQLを発行
- プライマリはDBに反映させつつWALに書込
- プライマリの
walsenderプロセスがスタンバイにWALを転送 - スタンバイの
walreceiverがWALをロード(DBに書込?)しつつWALに書込
![]() が記憶になかった。スタンバイのWALって転送されたものじゃなくて、転送されたものをDBに書き込んだ際の別のWALなのかな。
が記憶になかった。スタンバイのWALって転送されたものじゃなくて、転送されたものをDBに書き込んだ際の別のWALなのかな。
基本的な設定(動画 12分52秒)
必要なところだけ。
プライマリ側への初期データ投入時にレプリケーションの設定を行わないことで高速にデータ投入を行う方法があります
そうそう、最大データ試験(負荷試験)のときにレプリを切っておかないと大変なんだこれ。
- レプリ切る
- データ投入
- スタンバイで
pg_basebackup - レプリ再開
が必要
同期/非同期の違い(動画 18分17秒)
スタンバイ側でWALがどのような状態になったらプライマリ処理を完了(コミット完了を通知)させるかの違い。
- 同期
- スタンバイでWALが正常完了するまでプライマリは処理を止める
-
メリット
- プライマリとスタンバイでデータの完全一致が保証される
-
デメリット
- 2台構成の場合、スタンバイが停止しているとプライマリの処理が完了しない
- プライマリの処理がスタンバイの処理に左右される
- 非同期
- スタンバイのWAL処理を待たずにプライマリは処理を完了する。今回のハンズオンはこちら。
-
メリット
- 2台構成のレプリケーションが可能
- プライマリの処理が高速で完了する
-
デメリット
- 裏返し。NWなどでWALが正しく処理されないとデータがずれる
- 更新データが大量の場合は追従が遅れ、Readの結果が一時的に異なる可能性がある
-
- スタンバイのWAL処理を待たずにプライマリは処理を完了する。今回のハンズオンはこちら。
同期/非同期の設定は以下のパラメータ(たぶんpostgresql.conf)
synchronous_commit
トランザクションのコミットがクライアントに"完了"を報告する前にWALレコードがディスク上に書き込まれるまで待つかどうかの設定
| 設定値 | 同期/非同期 | プライマリ | スタンバイ |
|---|---|---|---|
| off | 非同期 | 待たない | 待たない |
| local | 非同期 | 待つ | 待たない |
| remote_write | 同期 | 待つ | メモリー書込みまで待つ |
| on | 同期 | 待つ | ディスク書込みまで待つ |
| remote_apply | 同期 | 待つ | WAL適応まで待つ |
remote_applyのみ完全同期。
デフォルトはonになっている。これだと2台構成時にスタンバイが停止するとプライマリの更新ができなくなる。
synchronous_standby_names
同期するスタンバイ名(アプリケーション名)をカンマ区切りで設定する。
-
'*'を指定するとすべてのスタンバイが対象となる -
'''を指定するとすべてのスタンバイが対象外となる。
事前準備としてスタンバイ側のpostgresql.auto.confのprimaryconninfoにapplication_nameとしてアプリケーション名を付与する必要がある。
- カンマ区切りで指定
- 定義した全てのスタンバイを同期として扱う
- FIRST N
- 前からN台のスタンバイを同期として扱う
- ANY N
- いずれかN台のスタンバイを同期として扱う
デフォルトは '' = すべてのスタンバイが対象外
いくつかのノードだけ同期を完全にしたい場合はこのあたりを弄る。
ストリーミングレプリケーションの復旧(動画 34分02秒)
スタンバイの昇格
スタンバイを昇格させる前にprimary_conninfoのコメントアウトが必要。
上記警告が関係なければ以下の2種で可能。
(スタンバイにてコマンドで実施)
$ #PGDATAが環境変数設定されているものとする
$ pg_ctrl -D ${PGDATA} promote
(または、スタンバイにPSQLして以下を実施)
=# SELECT pg_promote();
後者知らんかった。へー。
旧プライマリの降格
# cd (postgresql.confと同じディレクトリ)
# touch standby.signal
# systemctl restart postgresql
standby.signalが無いとスタンバイとして起動しない。
実際の構築手順
レプリユーザの作成(動画 13分31秒)
プライマリ側のDBでREPLICATION権限を付与したユーザを作成。
postgresアカウントとか、適当な一般アカウントでやっちゃ駄目なんですね。
=# CREATE USER repl_user LOGIN REPLICATION PASSWORD 'xxx';
そんでプライマリ側のpg_hba.confに上記ユーザの接続許可を設定。
パスワードの認証方式はmd5以外でも大丈夫っぽい。
host replication repl_user <スタンバイ側IPアドレス>/<サブネットマスク> md5
プライマリpostgresql.confの編集(動画 15分15秒)
以下のパラメータ更新。
動画ではお試しとしてlisten_addressを'*'にしてたけど、流石にそれはお試し用だと思う。
listen_address = 'xxxx' # 接続可能なアドレス
max_wal_senders = 2 # スタンバイDBの台数 + 1
終わったらDBを再起動する。
スタンバイ側でデータ取込(動画 16分03秒)
ちょっと細かくセクション切りすぎてるかな。大丈夫かな。
以下をスタンバイ側で実施。
$ rm -rf ${PGDATA}
$ pgbasebackup -R -D ${PGDATA} -U repl_user -h <プライマリ側IPアドレス>
${PGDATA}は環境により異なるので注意。デフォルトだと/var/lib/pgsql/バージョン/data/だとは思うけど、postgresql.confを参照せよ。
というかそこら辺の管理権限ない人は勝手にこんなことやるなよ?
pg_basebackupじゃなくてpgbasebackupってコマンドだった。アンダーバーなかったっけ??
-Rオプションをつけないとスタンバイサーバとして設定されないので注意!
スタンバイpostgresql.confの編集(動画 16分50秒)
以下のパラメータ更新。
動画ではお試しとしてlisten_addressを'*'にしてたけど、流石にそれはお試し用だと思う。
listen_address = 'xxxx' # 接続可能なアドレス
#max_wal_senders = 2 # コメントアウトする
終わったらDBを再起動する。
積み残し
解決できなかった課題
- 1+1のどちらかからストリーミングを受ける拠点B,Cはどうすりゃいいのか
- プライマリが切り替わる度に
rm -rf + pgbaebackupは非現実的 - NW以上で両方アクセスできなくなるとデータが消えるだけになってしまうため
- 事前に疎通確認すりゃいいんだけど
- 質疑応答でチェーン構成のレプリの話があった。それで良さそうだな。
- A→B→C
- Aが落ちたときはそのまま
- Aが復旧したらB→A→Cに切り替える
- プライマリが切り替わる度に