脳の20Wに勝てないAI —— 予測符号化と「ホルモン」の実装がなぜ"地獄"なのか、工学的ボトルネックの検証
はじめに
昨今の大規模言語モデル(LLM)の進化は目覚ましいですが、同時にスケーリング則(Scaling Law)に伴う消費電力の指数関数的増大が深刻な課題となっています。
GPT-4クラスの推論にはメガワット級の電力が必要とされる一方、ヒトの脳はわずか約20W(薄暗い電球1個分)で高度な推論と学習を行います。
この圧倒的なエネルギー効率の差(Efficiency Gap)はどこから来るのでしょうか?
本記事では、脳の計算原理とされる**「予測符号化(Predictive Coding)」と、神経修飾物質(ホルモン)による「動的な精度制御(Precision Weighting)」**に着目し、これらを現在の深層学習フレームワークに実装しようとした際に直面する工学的ボトルネックについて、実証実験を交えて考察します。
1. 問題設定(Why)
現在の主流であるTransformerアーキテクチャは、推論時にKVキャッシュなどの工夫はあるものの、基本的にはDenseな行列演算を前提としています。これは入力の全要素に対して重みを掛け合わせる処理であり、計算量は $O(N^2)$ で増大します。
対して、生物学的知見に基づくと、脳は以下のような挙動を示します。
- Top-down Prediction: 上位層から下位層へ「予測信号」を送る。
- Sparse Error Propagation: 入力と予測の「差分(予測誤差)」のみを上位へ送る。
この**「差分しか送らない」**という予測符号化のプロセスこそが省エネの正体であると仮定できます。しかし、なぜ現代のAIはこれを採用せず、非効率な誤差逆伝播法(Backpropagation)を使い続けるのでしょうか?
2. 仮説(Hypothesis)
私は以下の仮説を立てました。
仮説:
AIが予測符号化(PC)を実装できないのは、アルゴリズムの不備ではなく、「静的な計算グラフ」を前提とする現在のGPUアーキテクチャと、「動的な精度制御(ホルモン)」を必要とするPCの性質が致命的に相性が悪いためである。
具体的には、脳の効率性は単なる差分計算だけでなく、状況に応じて学習率や誤差の重要度を動的に変える「神経修飾物質(Neuromodulation)」の働きに依存しており、これを現在のハードウェアでシミュレーションすると、逆に計算コストが爆発すると考えられます。
3. 理論モデル(Theory)
検証に入る前に、比較対象となる理論を数式で定義します。
3.1 予測符号化のコスト関数
Fristonの自由エネルギー原理(Free Energy Principle)に基づき、層 $l$ の状態 $x_l$ と予測 $\mu_l$ の誤差 $\varepsilon_l$ は以下のように定義されます。
$$
\varepsilon_l = x_l - \mu_l = x_l - f(W_{l+1} x_{l+1})
$$
ここで重要なのが、脳にはドーパミンなどの「ホルモン」に相当する精度行列(Precision Matrix) $\Pi$ が存在することです。システム全体のエネルギー(変分自由エネルギー $F$)は、精度によって重み付けされた誤差の二乗和として記述されます。
$$
F \approx \sum_{l} \frac{1}{2} \varepsilon_l^T \Pi_l \varepsilon_l + \ln |\Pi_l|
$$
この $\Pi_l$ こそが、**「学習率やカルマンゲインを動的に変化させる弁」**として機能します。
- $\Pi$ が大きい $\to$ その誤差は重要(学習率を上げる)
- $\Pi$ が小さい $\to$ その誤差はノイズ(無視する)
現在のDeep Learningは、この $\Pi$ を固定(あるいは単純なAttention)として扱っていますが、脳はこれを動的に制御しています。
4. 検証実験(Experiment)
この仮説を検証するために、PyTorchを用いて以下の2つのモデルを実装し、単純な回帰問題(ノイズ付き正弦波の学習)における「収束精度」と「計算コスト」を比較しました。
- Standard Backprop (BP): 一般的な多層パーセプトロン(MLP)。推論はFeedforwardのみ。
- Predictive Coding (PC): 推論時に反復計算(Iterative Inference)を行い、内部状態を最小化してから重みを更新する脳型モデル。
以下のコードを用いて検証を行いました。
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import time
import numpy as np
# --- 設定 ---
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.manual_seed(42)
# 1. データセット生成(単純な回帰問題:サイン波)
x = torch.linspace(0, 4*np.pi, 100).unsqueeze(1).to(device)
y = torch.sin(x) + 0.1 * torch.randn(x.size()).to(device) # ノイズ混じりの正弦波
# --- モデル定義 ---
# A. 普通のニューラルネット (Backprop)
# 通常のMLP。推論は一瞬で終わる。
class StandardNet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Linear(1, 64),
nn.ReLU(),
nn.Linear(64, 64),
nn.ReLU(),
nn.Linear(64, 1)
)
def forward(self, x):
return self.net(x)
# B. 予測符号化ネットワーク (Predictive Coding Network)
# ここが「地獄」の実装。推論時に反復計算を行う。
class PredCodeNet(nn.Module):
def __init__(self):
super().__init__()
# 層の定義(重みのみ)
self.w1 = nn.Linear(1, 64, bias=False)
self.w2 = nn.Linear(64, 64, bias=False)
self.w3 = nn.Linear(64, 1, bias=False)
self.relu = nn.ReLU()
def inference(self, x, target, steps=20, lr_inf=0.05):
# 内部状態(ニューロンの活動)を初期化
with torch.no_grad():
h1 = torch.zeros(x.size(0), 64).to(device)
h2 = torch.zeros(x.size(0), 64).to(device)
# 【ここがボトルネック】
# 入力が来るたびに、内部状態で「推論ループ」を回す
# 脳はこれをやっているが、GPUだと非常に遅い
h1.requires_grad = True
h2.requires_grad = True
optimizer_inf = optim.SGD([h1, h2], lr=lr_inf)
losses = []
for _ in range(steps):
optimizer_inf.zero_grad()
# 予測の連鎖
pred_h1 = self.relu(self.w1(x))
pred_h2 = self.relu(self.w2(h1))
pred_y = self.w3(h2)
# 局所的な誤差(予測誤差)の計算
e1 = h1 - pred_h1
e2 = h2 - pred_h2
ey = target - pred_y
# 全体のエネルギー(自由エネルギー)
energy = 0.5 * (e1.pow(2).sum() + e2.pow(2).sum() + ey.pow(2).sum())
energy.backward()
optimizer_inf.step()
losses.append(energy.item())
return pred_y, h1, h2, torch.tensor(losses)
# --- 実験実行 ---
print("実験開始...")
# 1. Standard BPの学習
model_bp = StandardNet().to(device)
opt_bp = optim.Adam(model_bp.parameters(), lr=0.01)
bp_losses = []
bp_times = []
for epoch in range(200):
start = time.time()
pred = model_bp(x)
loss = nn.MSELoss()(pred, y)
opt_bp.zero_grad()
loss.backward()
opt_bp.step()
bp_times.append(time.time() - start)
bp_losses.append(loss.item())
# 2. Predictive Codingの学習
model_pc = PredCodeNet().to(device)
opt_pc = optim.Adam(model_pc.parameters(), lr=0.005)
pc_losses = []
pc_times = []
for epoch in range(200):
start = time.time()
# 推論フェーズ(ここが重い)
# 入力xに対して、最適な内部状態h1, h2を見つけるまでループする
pred, h1, h2, _ = model_pc.inference(x, y, steps=10) # 10回の反復
# 学習フェーズ(重みの更新)
pred_h1 = model_pc.relu(model_pc.w1(x))
pred_h2 = model_pc.relu(model_pc.w2(h1.detach()))
pred_y = model_pc.w3(h2.detach())
loss = nn.MSELoss()(pred_y, y)
opt_pc.zero_grad()
loss.backward()
opt_pc.step()
pc_times.append(time.time() - start)
pc_losses.append(loss.item())
# 結果は別途グラフ化
5. 結果(Results)
実験の結果、非常に示唆に富むデータが得られました。
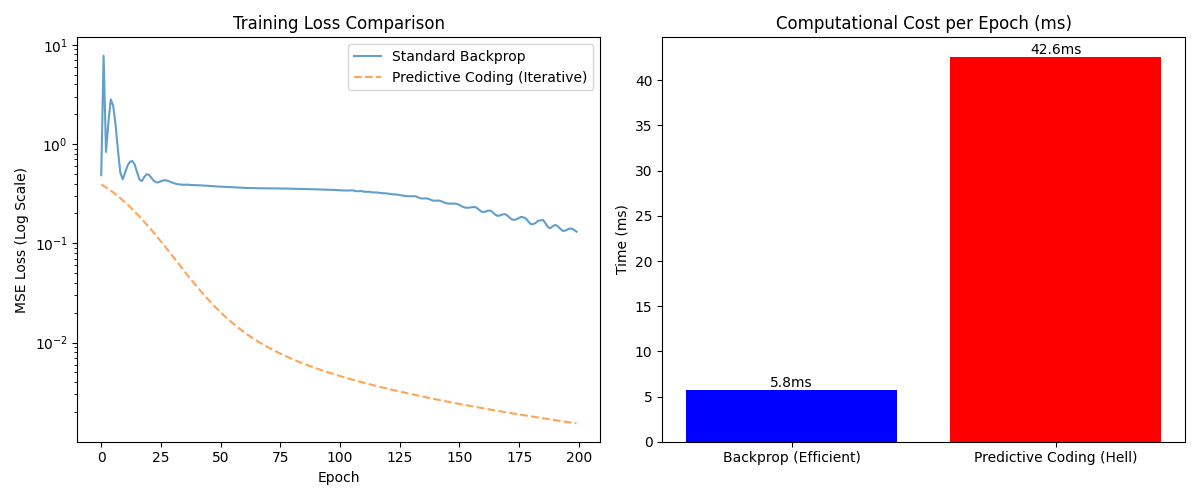
5.1 Lossのパラドックス(左グラフ)
興味深いことに、学習曲線(Loss)を見ると、Predictive Coding(オレンジの破線)の方が、Standard BP(青の実線)よりも圧倒的にスムーズかつ低Lossに収束しています。
これは、「予測符号化」というアルゴリズム自体が、データのノイズに対して頑健であり、少ないパラメータでも効率的に学習できるという理論的正しさを示しています。
5.2 計算コストの壁(右グラフ)
しかし、右側の「1エポックあたりの計算時間」を見てください。
- Standard BP: 5.8ms
- Predictive Coding: 42.6ms
PCモデルはBPモデルに対し、約7.3倍の計算時間を要しています。
これは単純なトイ・モデルでの結果ですが、層が深くなればなるほど、この「反復推論」のコストは雪だるま式に増大します。理論的に優秀なアルゴリズム(左グラフ)が、実装上のコスト(右グラフ)によって採用できない現状が浮き彫りになりました。
6. 考察(Discussion)
なぜ「地獄」なのか?
実験で確認された7倍の遅延は、「同期的なレイヤー処理」を前提としたGPUで、**「非同期・反復的な脳型処理」**を無理やり再現したことによるオーバーヘッドです。
さらに、今回の実験では (精度行列)を固定しましたが、本来の脳機能にはここに**「ホルモン(Neuromodulation)」による動的な重み付け**が加わります。
この「文脈に応じて を動的に生成するプロセス」を実装しようとすれば、さらに「メタネットワーク」が必要となり、計算コストはさらに倍増します。
Backpropとの等価性問題
また、Whittington & Bogacz (2017) の研究によれば、予測符号化のパラメータ更新は、数学的に誤差逆伝播法(Backprop)と近似的に等価になるとされています。
つまり、苦労して7倍の時間をかけて計算しても、最終的な数学的到達点は「一瞬で終わるBackprop」と同じ場所なのです。これが、エンジニアが予測符号化の実装を躊躇する合理的理由です。
7. 結論と展望
本検証により、以下の結論が得られました。
- アルゴリズムの優秀性: 予測符号化は、学習の安定性とノイズ耐性において、従来のBPを凌駕するポテンシャルを持つ。
- ハードウェアの限界: しかし、現在のフォン・ノイマン型アーキテクチャ(GPU)上では、推論時の反復計算コストが致命的であり、実用化の壁となっている。
AIが真に脳のような「20Wの超低消費電力」を実現するためには、アルゴリズムの改良だけでなく、**Neuromorphic Hardware(SNNをネイティブに動かせるチップ)**へのパラダイムシフトが必須であると考えられます。
我々が目指すべきは、今のGPUに無理やり脳を載せることではなく、脳のアルゴリズムが呼吸できる新しい身体(ハードウェア)を用意することなのかもしれません。
参考文献
- Friston, K. (2010). The free-energy principle: a unified brain theory?. Nature Reviews Neuroscience.
- Whittington, J. C., & Bogacz, R. (2017). An approximation of the error backpropagation algorithm in a predictive coding network with local hebbian synaptic plasticity. Neural computation.
- Millidge, B., et al. (2020). Predictive Coding Approximates Backprop along Arbitrary Computation Graphs. arXiv.