Apache Flink 1.9.0は、バッチジョブのバッチリカバリやBlinkベースのクエリエンジンなど、AlibabaのBlinkの多くの機能を統合した重要なアップデートです。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
2019年8月22日、Apache Flinkのバージョン1.9.0が正式に公開されました。この新バージョンは、アリババのBlinkの内部バージョンが統合され、Apacheの公式バージョンのFlinkに統合された後の最初のリリースです。
そのため、この全く新しいアップデートではいくつかの重要な変更点があります。この新しいリリースの注目すべき機能は、バッチジョブのためのバッチスタイルのリカバリと、テーブルAPIとSQLクエリのための新しいBlinkベースのクエリエンジンのプレビューです。同時に、このリリースでは、最も要望の多かった機能の1つであるステートプロセッサAPIも提供されており、Flink DataSetジョブでセーブポイントを柔軟に読み書きできるようになっています。このリリースには、再構築されたWebUIや、Flinkの新しいPython Table APIのプレビュー、Apache Hiveエコシステムとの統合も含まれています。
Apache Flink プロジェクトの目標は、当初から、さまざまなイベント駆動型アプリケーションに加えて、多くの形式のリアルタイムおよびオフラインのデータ処理アプリケーションを統合して動作させることができるストリーム処理システムを開発することでした。今回のリリースでは、Apache と Alibaba Cloud は、Blink のストリームとバッチ処理機能を統一されたランタイムの下で統合することで、最初の目標に向けて大きな一歩を踏み出しました。
この記事は、このアップデートに興味があり、何が期待されているのかを知りたいと思っている人の参考になればと思います。この記事では、この新しいアップデートでの Apache Flink の主要な新機能、改善点、重要な変更点を説明します。また、Apache の将来の開発計画についても見ていきます。
注: Flink 1.9 のバイナリ配布とソース・アーティファクトは、更新されたドキュメントとともに Flink プロジェクトのダウンロードページから利用可能になりました。Flink 1.9は、@PublicアノテーションでアノテーションされたAPIについては、以前の1.xリリースとAPI互換性があります。Flink メーリングリストやJIRA を通じてコミュニティとアイデアを共有することができます。
新機能と改善点
微細化バッチジョブ回収(FLIP-1)
この新しいリリースでは、データセット、テーブルAPI、SQLジョブのいずれであっても、タスク障害からバッチを復旧する時間が大幅に短縮されました。
Flink 1.9までは、バッチジョブのタスク障害は、すべてのタスクをキャンセルしてジョブ全体を再起動しなければならないという複雑なプロセスを経て回復していました。つまり、ジョブをゼロから開始しなければならず、すべての進捗が無効になっていました。
しかし、このバージョンのFlinkでは、ネットワークシャッフルのエッジに中間結果を保持し、障害の影響を受けたタスクのみを回復するためにこのデータを使用しています。このプロセスに関連して、パイプライン化されたデータ交換を介して接続されたタスクのセットであるフェイルオーバー領域を持つことができます。ジョブのバッチシャッフル接続は、そのフェイルオーバー領域の境界を定義します。このすべての詳細については、FLIP-1を参照してください。
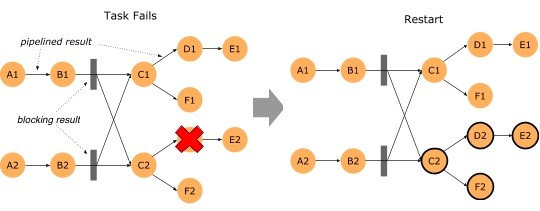
この新しいフェイルオーバー戦略を使用するには、flink-conf.yaml に jobmanager.execution.failover-strategy: region エントリがあることを確認してください。
注意: 1.9 ディストリビューションパッケージの設定にはデフォルトでこのエントリがありますが、以前の設定から設定ファイルを再利用する場合は、手動で追加する必要があります。
上で説明した "Region" フェイルオーバー戦略は、ストリーミングジョブ、つまり keyBy() や rebalance のようなシャッフルのないジョブのリカバリを高速化して改善します。このようなジョブがリカバリされると、影響を受けたパイプライン(フェイルオーバー領域)のタスクのみが再起動されます。その他のすべてのストリーミング・ジョブについては、リカバリ動作は以前の Flink のバージョンと同じです。
ステートプロセッサAPI(FLIP-43)
Flink 1.9までは、外部からジョブの状態にアクセスするには、(まだ実験的な)Queryable Stateに限定されていました。このリリースでは、DataSet APIを使用して状態のスナップショットを読み書きし、変更するための新しい強力なライブラリが導入されました。実際には、これは次のことを意味します。
-
外部システム、例えば外部データベースなどからデータを読み込み、それをセーブポイントに変換することで、リンクジョブの状態をブートストラップすることができます。
-
セーブポイント内の状態は、FlinkのバッチAPI(DataSet、Table、SQL)のいずれかを使用してクエリすることができます。例えば、関連するステートパターンを分析したり、監査やトラブルシューティングのためにステートの不一致をチェックしたりすることができます。
-
セーブポイント内の状態のスキーマは、スキーマアクセスでオンライン移行を必要とする従来のアプローチに比べ、オフラインで移行できます。
-
セーブポイント内の無効なデータを特定し、修正することができます。
新しいステート・プロセッサAPIは、スナップショットのすべてのバリエーション(セーブポイント、フルチェックポイント、インクリメンタル・チェックポイント)をカバーしています。詳細については、FLIP-43を参照してください。
Savepointで停止(FLIP-34)
"Cancel-with-savepoint “は、Flinkジョブの停止や再起動、フォークや更新のための一般的な操作です。しかし、これの既存の実装では、外部ストレージシステムに転送されたデータのデータ永続性を完全に保証できないという問題がありました。ジョブを停止する際のエンドツーエンドのセマンティクスを改善するために、Flink 1.9では、出力データの一貫性を確保しながら、セーブポイントでジョブを停止する新しいSUSPENDモードが導入されました。以下のようにFlink CLIクライアントでジョブをサスペンドすることができます。
bin/flink stop -p [:targetSavepointDirectory] :jobId
成功時の最終ジョブの状態がFINISHEDに設定されているので、操作が失敗したかどうかを簡単に確認することができます。詳しくはFLIP-34をご覧ください。
Flink WebUIのリファクタリング
FlinkのWebUIについての議論の後(ここにあるリンクを参照)、コミュニティはこのコンポーネントを最新の安定版であるAngular(たまたまAngular 7.0以降)を使ってリファクタリングすることを決定しました。この再設計されたアップデート版が1.9.0のデフォルトとなっています。しかし、Flink 1.9.0には古いWebUIに切り替えるためのリンクが含まれています。
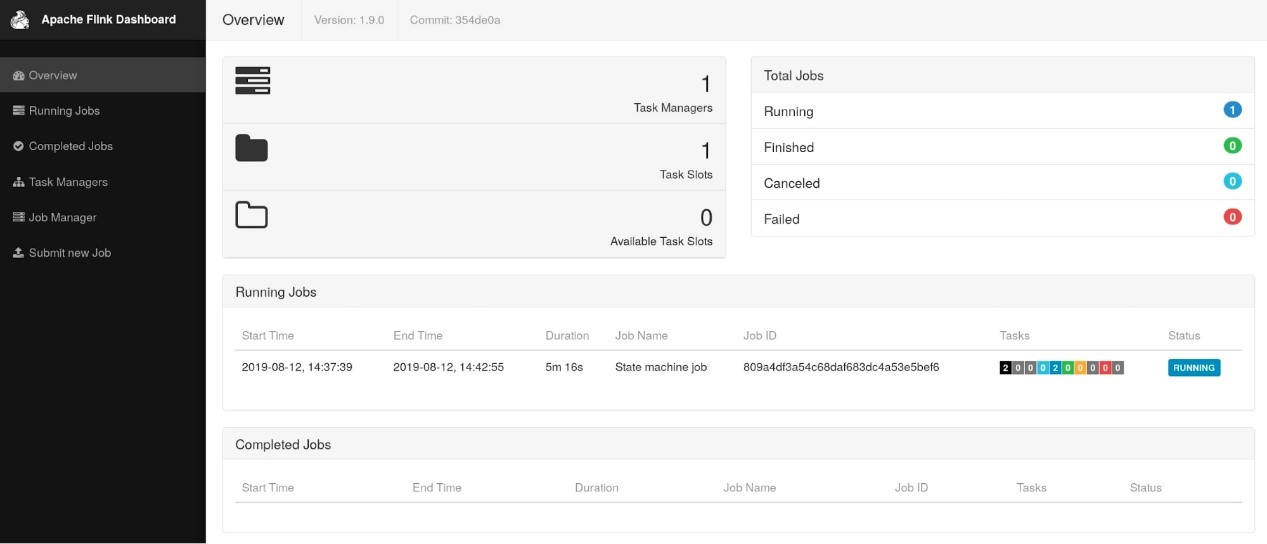
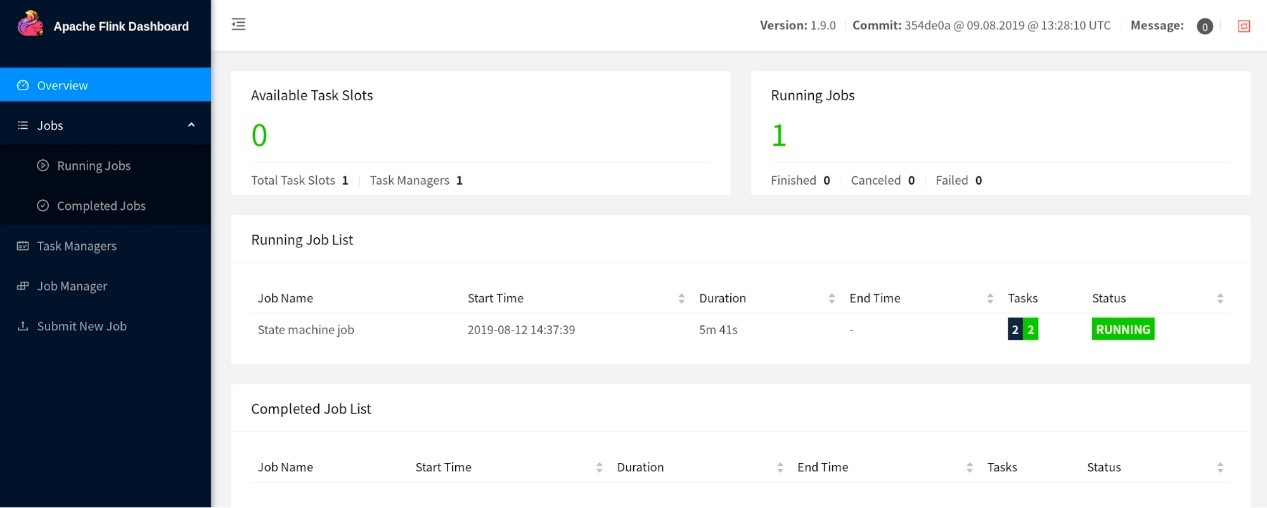
注意:注意すべき点としては、これらの大きな変更を考えると、将来的には旧バージョンの WebUI が新バージョンと同じ機能を持つことは保証されないということです。旧バージョンのWebUIは、新バージョンが安定した状態になった時点で非推奨となります。
新しいBlink SQLクエリプロセッサのプレビュー
AlibabaのBlinkがApache Flinkに統合されたことで、コミュニティはBlinkのクエリオプティマイザとテーブルAPIとSQLクエリ機能のランタイムをFlinkに統合する作業に取り組みました。この作業の最初のステップは、モノリシックなflink-tableモジュールをより小さなモジュールにリファクタリングすることでした(FLIP-32を参照)。JavaとScalaのAPIモジュール、オプティマイザ、ランタイムモジュールについては、これは明確なレイヤリングと明確に定義されたインターフェースを意味します。
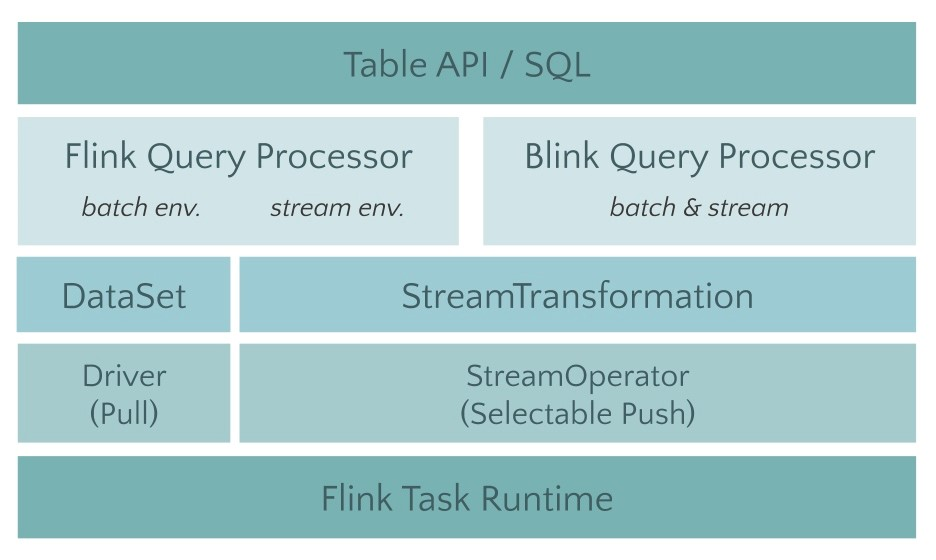
次のステップは、Blinkプランナーを拡張して新しいオプティマイザーインターフェイスを実装することでした。1.9より前のバージョンのFlinkプロセッサと新しいBlinkベースのクエリプロセッサです。Blinkベースのクエリプロセッサは、より優れたSQLカバレッジを提供し、1.9ではTPC-Hが完全にサポートされています。次のリリースでは、TPC-DSのサポートが予定されています。
また、コストベースのプラン選択とより多くの最適化ルールによるより広範なクエリ最適化に基づいて、バッチクエリのパフォーマンスが改善されています。最後に、コード生成と調整された演算子の実装も改善されています。Blinkベースのクエリ・プロセッサは、ディメンション・テーブル結合、TopN、重複排除、集約シナリオにおけるデータスキューの解決のための最適化、より便利な組み込み関数などの待望の新機能とともに、より強力なストリーミングも可能にしています。
注意: 2つのクエリプロセッサのセマンティクスとサポートされている操作のセットは、大部分が一致していますが、完全には一致していません。詳細については、リリースノートを参照してください。
しかし、Blinkのクエリプロセッサの統合は、まだすべてが完全に完了したわけではありません。Flink 1.9以前のバージョンのプロセッサは、Flink 1.9ではまだデフォルトのプロセッサであり、本番環境では推奨されています。
TableEnvironmentを作成する際にEnvironmentSettingsを設定することでBlinkプロセッサを有効にすることができます。選択したプロセッサは、実行中のJavaプロセスのクラスパスにある必要があります。クラスタ設定の場合、デフォルトでは、両方のクエリ プロセッサは自動的にクラスパスにロードされます。IDEからクエリを実行する場合は、明示的にプランナーの依存関係をプロジェクトに追加する必要があります。
テーブルAPIとSQLのその他の改善点
Blinkプランナーのエキサイティングな進展に加えて、コミュニティはこれらのインターフェイスの改善にも取り組んできました。
- ScalaフリーのテーブルAPIとJavaユーザーのためのSQL(FLIP-32を参照)。
flink-tableモジュールのリファクタリングと分割の一環として、JavaとScala用の2つの独立したAPIモジュールが作成されました。Javaを使用している人にとっては、これは大きな変更にはなりません。しかし、Javaユーザーは、Scalaの依存関係を使用せずにテーブルAPIとSQLを使用できるようになりました。
- テーブルAPIとSQL型システムのリファクタリング(FLIP-37参照)
コミュニティでは、FlinkのTypeInformationクラスからTable APIを切り離し、SQL標準への準拠性を向上させるための新しいデータ型システムを実装しました。この作業はまだ進行中で、次のリリースで完了する予定です。Flink 1.9では、UDFはまだ新しい型システムに移植されていません。
- テーブルAPIの多列・多行変換(FLIP-29参照)
Table APIの機能は、複数行および複数列の入力と出力をサポートする一連の変換によって拡張されました。これらの変換により、リレーショナル演算子を使用して実装するのが面倒な処理ロジックの実装が大幅に容易になりました。
- 新しい統一されたカタログAPI
コミュニティは、内部および外部のカタログを処理する統一された方法を提供するために、いくつかの既存のカタログAPIをリファクタリングして置き換えました。この作業は主にHiveとの統合に向けて開始されました。さらに、このリワークにより、Flinkでのカタログ・メタデータ管理の全体的な利便性が向上しました。
- SQL APIでのDDLサポート(FLINK-10232参照)
バージョン1.9以前のFlink SQLでは、SELECTやINSERTなどのDML文しかサポートしていませんでした。外部テーブル、特にテーブルのソースとシンクは、Java/Scalaコードまたは設定ファイルを使用して登録しなければなりませんでした。Flink 1.9では、コミュニティはテーブルを登録したり削除したりするためのSQL DDL文、特にCREATE TABLEとDROP TABLEコマンドのサポートを追加しました。しかし、コミュニティはタイムスタンプ抽出と透かし生成を定義するためのストリーム固有の構文拡張を追加しませんでした。ストリームシナリオの完全なサポートは次のリリースで予定されています。
Hive統合のプレビュー(FLINK-10556)
Apache Hive は、大量の構造化データを保存したり、クエリを実行したりするために、Hadoop エコシステムで広く使われています。クエリプロセッサであることに加えて、Hive は大規模なデータセットを管理・整理するための Metastore と呼ばれるカタログを特徴としています。クエリプロセッサの共通の統合ポイントは、Hive Metastoreと統合してHiveをデータ管理に利用できるようにすることです。
最近、コミュニティはFlink Table APIとHive Metastoreに接続するSQLクエリの外部カタログの実装を開始しました。Flink 1.9では、Hiveに格納されているさまざまなデータ形式のクエリや処理が可能になりました。さらに、Hive との統合により、Flink Table API や SQL クエリで Hive UDF を使用することができるようになりました。詳細については、FLINK-10556を参照してください。
以前は、テーブルAPIとSQLで定義されたテーブルは常に一時的なものでした。新しいカタログコネクタでは、SQLのDDL文で作成したテーブルをMetastoreに永続化することもできるようになりました。つまり、Metastoreに接続してテーブル、例えばKafkaトピックに似たテーブルを登録することができます。今後は、カタログがMetastoreに接続されるたびに、そのテーブルをクエリすることができるようになります。
注: Flink 1.9でのHiveサポートは実験的なものであることに注意が必要です。コミュニティは次のリリースでこれらの機能を安定化させることを計画しており、皆様からのフィードバックをお待ちしています。
新しいPythonテーブルAPIのプレビュー(FLIP-38)
このリリースでは、Python Table API の最初のバージョンが導入されています(FLIP-38 を参照してください)。これは、本格的な Python サポートを Flink に導入するというコミュニティの目標に向けてのスタートとなります。この機能はTable APIのスリムなPython APIラッパーとして設計されており、基本的にはPython Table APIのメソッド呼び出しをJava Table APIの呼び出しに変換します。Flink 1.9では、Python Table APIは現在UDFをサポートしておらず、標準的なリレーショナル操作のみを有効にしています。PythonでのUDFのサポートは今後のリリースのロードマップにあります。
新しいPython APIを試したい場合は、PyFlinkを手動でインストールする必要があります。ドキュメント内のウォークスルーを見て、自分で探り始めることができます。コミュニティでは現在、pipを通してインストールできるpyflinkのPythonパッケージを用意しています。
重要な変更点
-
テーブルAPIとSQLは、Flinkディストリビューションのデフォルト設定の一部になりました。以前は、テーブルAPIとSQLは、対応するJARファイルを
./optから./libに移動して有効にする必要がありました。 -
機械学習ライブラリ(
flink-ml)はFLIP-39に備えて削除されました。 -
古いDataSetとDataStreamのPython APIを削除し、FLIP-38で導入された新しいPython APIの利用を推奨します。
-
FlinkはJava 9でコンパイルして実行することができますが、コネクタ、ファイルシステム、レポーターなどの外部システムと相互作用する一部のコンポーネントは、対応するプロジェクトがJava 9のサポートをスキップしている可能性があるため、動作しない場合があります。
リリースノート
Flink の既存バージョンからのアップグレードを計画している場合、変更点や新機能の詳細な概要については、リリースノートを参照してください。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ