この記事では、サーバーレスアーキテクチャのメリットを紹介し、4つの代表的なユースケースを用いて、その実装と従来のソリューションを比較しています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
サーバーレスの進化
インターネット上では、サーバーレス・アーキテクチャの進化を説明するために、人類の進化との類似性を描くことがよくあります。人類の進化の各段階は、生産性の向上を伴っていました。同様に、ITコンピューティングの歴史もまた、次の図に示すように、生産性が徐々に向上してきたことを物語っています。
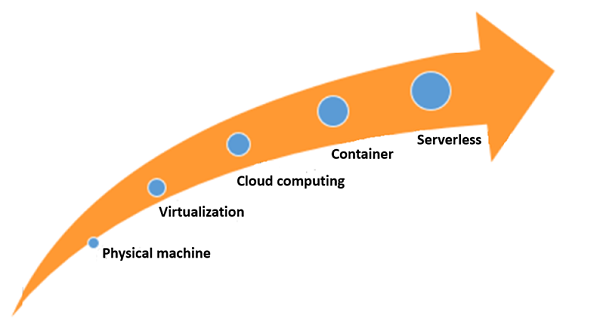
この開発プロセスには、いくつかのマイルストーンがあります。
- 仮想化技術は、大規模な物理サーバを個々のVMリソースに仮想化します。
- 仮想化クラスタをクラウドコンピューティングプラットフォームに移行し、簡単なO&Mを実現しています。
- 各VMは、動作スペースを最小限に抑えるという原則に基づいてDockerコンテナに細分化されています。
- Dockerコンテナ上に構築されたアプリケーションは、ランタイム環境の管理を一切必要とせず、コアコードのサーバーレスアーキテクチャのみで構成されています。
したがって、これもまた、一連の技術革命によって牽引されたITアーキテクチャの進化です。その過程で、リソースの細分化、運用効率の向上、ソフトウェアの保守の簡素化が進んできました。ITアーキテクチャの進化には、次のような特徴があります。
- ハードウェア資源の細分化が進む。
- リソースの利用率が上がる。
- O&M作業が徐々に削減される。
- 企業がコード層を重視するようになった。
サーバーレスアーキテクチャには以下のような特徴があります:
- 粒度の高いコンピューティングリソースが割り当てられる。
- リソースを事前に割り当てる必要がない。
- 本当の意味でのスケーラビリティと柔軟性が高いアーキテクチャになってきている。
- 利用者は必要なリソースのみを使用し、対価を支払う。
このようなサーバーレスアーキテクチャの一般的な特徴を踏まえて、参考になる代表的な事例をいくつか見てみましょう。
サーバーレスアーキテクチャの代表的な用途とは?
イベントリクエスト
-
カスタムイメージ
オンライン販売者が商品の画像を維持する場合、商品の表示位置に応じて画像を動的に異なるサイズに切り取るか、異なる画像の透かしを追加する必要があります。オンライン販売者が商品の画像を管理する際には、商品の表示位置に基づいて画像を動的に異なるサイズにカットするか、異なる画像の透かしを追加する必要があります。売り手が画像をOSSにアップロードする際には、Function Computeを使用してカスタムファンクションコンピューティングトリガーを作成することができます。コンピューティングルールに基づいて、売り手はオンラインでの商品表示のニーズに合わせて異なるサイズの画像を生成することができます。このプロセスでは、ウェブページの美観を確保するために、追加のサーバーを構築したり、手動で介入したりする必要はありません。 -
IoTアプリケーションにおける低周波要求
IoT業界では、IoTデバイスは少量のデータを、しばしば一定の間隔で送信します。そのため、低頻度の要求を伴うシナリオがあります。例えば、次のような場合です。IoTアプリケーションは、1分間に1回50ミリ秒しか動作しないことがあります。これは、CPU使用率が1時間あたり0.1%であることを意味します。言い換えれば、1,000個の同一のアプリケーションが同じコンピューティングリソースを共有することができます。さらに、サーバーレスアーキテクチャでは、コンピューティングのニーズを満たすために、1分間に100msのCPUリソースを購入することができます。これは効率性の問題を効果的に解決するだけでなく、使用コストの削減にもつながります。 -
カスタムイベント
ユーザー登録中に、ユーザーのメールアドレスを確認するための電子メールが送信されます。同様に、追加のアプリケーションを設定したり、後続のリクエストを処理するためにサーバーを使用したりすることなく、後続の登録プロセスをトリガーするカスタムイベントを作成することができます。 -
固定時間トリガー
イベントは、一定の時間帯にトリガーすることができます。例えば、夜間の繁忙期やサービスがアイドル状態の時に、サービスの処理トランザクションデータを提出させることができます。または、バッチデータを実行してデータレポートを生成することもできます。サーバーレス方式では、使用頻度の低い処理リソースを追加する必要がありません。
トラフィックスパイク
- 弾性的なスケーリングはトラフィックのバーストにも対応可能
モバイルインターネットアプリケーションは、しばしば突然のトラフィックの急増に対処しています。例えば、次のような場合です。モバイル・アプリケーションのトラフィック・レートは通常 20 QPS であるが、5 分ごとに 200 QPS(通常の 10 倍)に増加し、10 秒間持続します。従来のアーキテクチャでは、このようなビジネスのピークに対処するために、企業はハードウェアの機能を 200 QPS に拡張しなければなりません。
サーバーレスアーキテクチャでは、弾力性のあるスケーラビリティを活用して、現在の需要に合わせてコンピューティング能力を迅速に向上させることができます。そして、ビジネスのピーク時には自動的にリソースが解放され、コストを削減します。
- トランスコーディングとトラフィック容量のスケーリング
ライブ動画アクティビティでは、ライブストリームにアクセスする視聴者の数を予測できないため、Function メソッドを使用してトランスコーディングとトラフィック機能をスケーリングすることができます。これにより、同時実行やトラフィック容量のスケーリングの問題を考慮する必要がなくなります。
ビッグデータ処理
セキュリティ監査の問題から、過去1年間に蓄積されたOSSデータの中から特定のキーワードを持つアクセスログを複数の地域で検索し(1時間に1ファイル作成)、同時に集計処理(合計値を計算する)を行う必要がある場合があります。Alibaba Cloud Function Computeを利用すると、アクセスログに対して、ピーク時には2時間ごと、非ピーク時には4時間ごとにファンクションコンピューティングを実行し、処理結果をRDSに格納することができます。ある関数を使用して別の関数にデータをディスパッチすることで、何千もの同一のインスタンスを実行することができます。
このようにして、1000個近い計算関数(24×365÷10)を1分以内に実行することができます。ECS や計算スクリプトを用いて同じ計算を行う場合、これらのインスタンスのためだけにネットワークを構成するだけでも大変な作業となります(異なる地域ではイントラネット経由で OSS ファイルをダウンロードすることができない)。また、インスタンスはサブネット内の IP アドレスの数が多い場合があります(例えば、VPC が 24 ビットのサブネットマスクを使用している場合など)。
以下では、Alibaba CloudのFunction Compute製品を使用して、様々なユースケースにおけるアーキテクチャを説明し、そのケースに特有の困難をどのように解決できるかを説明します。Alibaba CloudのFunction Computeは、サーバーレスアーキテクチャに基づいた完全ホスト型の製品です。コアコードをFunction Computeにアップロードするだけで、イベントソースやSDKやAPIを使ってコードを実行することができます。Function Computeはランタイム環境を準備し、お客様のリクエストのピークに基づいて環境を動的にスケーリングします。あなたは、Function Computeを使用した時間に基づいて課金されます。リクエストが処理されると、課金は停止します。これにより、リクエスト量の変動が大きいアプリケーションのコストを削減することができます。
次の図は、Function Computeの開発者試用運用手順を示しています。
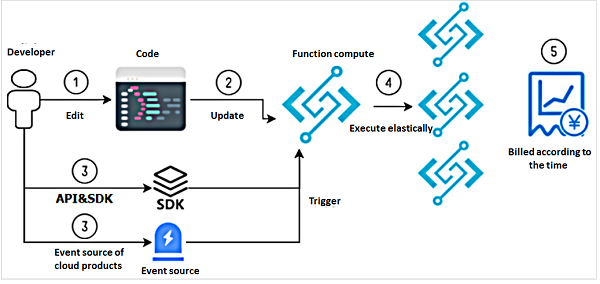
- 本製品は現在、Java、NodeJS、Pythonのプログラミング言語をサポートしています。
- APIやSDKを使用して、Function Computeにコードをアップロードすることができます。また、この操作をコンソール上で実行したり、Fcliコマンドラインツールを使用したりすることができます。
- APIやSDKを使用して、またはクラウドプロダクトのイベントソースを介して、Function Computeの実行をトリガーすることができます。
- 実行プロセスでは、Function Computeは、リクエストのピーク時に正常に実行されるように、ユーザーのリクエスト量に基づいて動的にサイズ変更されます。このプロセスは、ユーザーには透過的です。
- 関数の実行後、請求書に記録された料金を確認することができます。最低100ms単位で利用した時間に応じて課金されます。
以下では、サーバーレスアーキテクチャの理解を深めるために、いくつかのサーバーレスユースケースを詳しく説明します。
シナリオ1:イベントトリガーコンピューティング
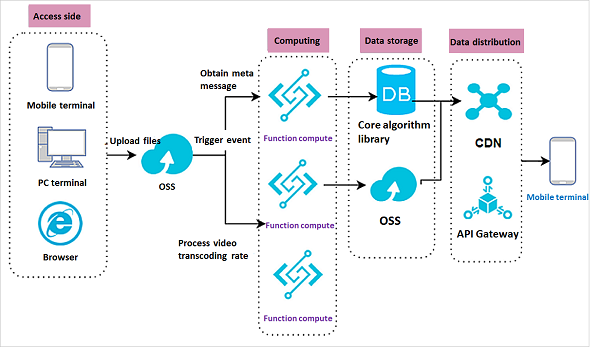
シナリオ
ユーザーは、携帯電話、Webアプリケーション、またはPCから様々なファイルタイプ(画像、動画、テキストファイルなど)をOSSにアップロードします。そして、OSSのPutObjectイベントは、アップロードされたファイルを処理するためにFunction Computeをトリガーします。
典型的なシナリオ
ユーザが動画ファイルをOSSにアップロードすると、Function Computeが起動し、オブジェクトのメタデータを取得してコアアルゴリズムライブラリに送信します。アルゴリズムに基づいて、コアアルゴリズムライブラリは、関連する動画ファイルをCDNオリジンサイトにプッシュし、指定された動画をホットロードします。別のシナリオでは、動画ファイルがOSSにアップロードされた後、Function Computeを起動して複数のトランスコーディングレートを同期させ、処理した動画ファイルをOSSに格納します。これにより、軽量なデータ処理ソリューションを提供します。
マルチメディア処理のシナリオでは、大量のファイルがOSSにアップロードされた後、処理(例えば、透かし、トランスコーディング、ファイル属性データのフェッチ)を行う必要があることがよくあります。このようなシナリオでは、以下の技術的な問題を解決する必要があります。
- ファイルがアップロードされた後にイベントをトリガーする方法 一般的には、OSSのイベント通知を受信するためのカスタムメッセージチャンネルを作成します。また、イベント通知を処理するためのランタイム環境を構築し、関連するコードを記述する必要があります。
- 大量にアップロードされたファイルを効率的に処理する方法。
- 複数のクラウド製品をシームレスに連携させる方法。
Function Computeは、これらの技術的な困難に簡単に対応できるソリューションを提供します。
- Function Computeは、イベント通知を受け取るためのOSSトリガーを設定することができます。Function Computeでは、ファイルを処理し、イントラネット経由でOSSにファイルを送信するためのビジネスコードを書くことができます。全体のプロセスはシンプルでスケーラブルです。
- コアコードをFunction Computeに構築し、そのコードを使用してイベント通知を同時に処理することができます。
- Function Computeは現在、他の製品との内部インタラクションをサポートしています。コンソール上で簡単な設定を行うことで、効率的に製品を接続することができます。
イベントトリガーへの従来のアプローチ:
- イベント通知を受信するためのメッセージチャネルを設定し、関連するビジネスコードを記述します。
- バックエンドのデータ処理のためのサーバーリソースを購入します。
- ビジネスのピーク時にアップロードされたファイルを処理するためのマルチコンカレントフレームワークを設計します。
- 複数の製品を有効化し、ビジネスの相互作用のためにSDKコードを呼び出します。
関数計算アプローチ:
- コンソール上でイベントソースの通知を設定し、関連する業務コードを記述します。
- Function Computeにコードを記述します。ソフトウェアやハードウェア環境を管理する必要はありません。
- Function Computeは、ビジネスのピークに対処するために動的にスケーリングします。管理は必要ありません。
- Function Computeには他の多くの製品との接続性が組み込まれているため、簡単な構成でシームレスに製品を接続することができます。
シナリオ2:弾性的なリサイズ(複数の接続されたマイクを使用したライブビデオのシナリオ
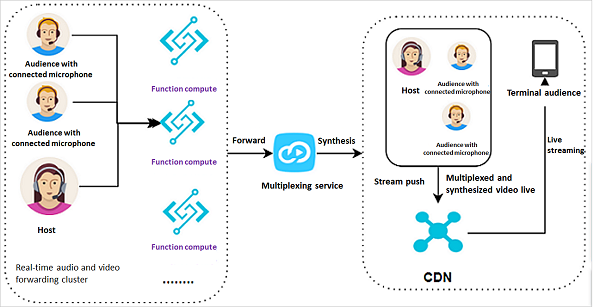
シナリオ
クライアントは、接続されたマイクを持つホストと視聴者からオーディオとビデオのストリームを収集し、多重化のためにFunction Computeに送信します。Function Computeは収集したデータを合成のために多重化サービスに送り、合成されたビデオストリームをCDNにプッシュします。視聴者は、リアルタイムでライブストリームを引っ張ってきて、多重化され合成されたビデオをライブで見ることができます。
いくつかのライブビデオシナリオでは、接続されたマイクを使用して複数の視聴者メンバーが相互作用するため、ホストは同時に複数のマイクに接続されています。ホストは、複数の視聴者メンバーや友人を画面に接続し、映像を合成して一つのシナリオにして、ライブストリームの視聴者に提供することができます。このシナリオでは、以下のような技術的な問題があることを認識しておく必要があります。
- 接続されるマイクの数は固定ではないので、同時性や弾力性を考慮する必要があります。
- ライブストリームは24時間稼働しているわけではなく、ビジネスのアクセス量に大きな変動があります。
- ライブ放送は、視聴者の急激な変動を伴うイベント駆動型のシナリオです。高速なアップデートとバージョンの反復が必要であり、最新のテクノロジーを迅速に組み込む必要があります。
サーバーレスアーキテクチャは、これらの問題を解決するための完璧なソリューションを提供します。
ホストと接続されたマイクのためのリアルタイムオーディオおよびビデオ転送クラスタとして、Function Computeは、リアルタイムデータストリームを処理するために使用される複数の実行環境のサイズを、同時に発生するボリュームに基づいて自動的に変更します。ビジネスピーク後には、ファンクションは適切にリソース量を削減します。コード管理機能はクラウド上に展開され、いつでもコードの反復を修正して維持することができます。複数のソフトウェア実行環境を管理する必要がなくなります。
ライブビデオストリーミングへの従来のアプローチ:
- 同時並行トラフィックを処理するためのロードバランサーを購入。
- データを処理するためのコンピューティング リソースを購入。
- コスト削減のために、ピーク時以外の期間にハードウェアリソースを解放する方法を見つける。
- 複数のバージョンで複数のランタイム環境を維持する。
関数計算アプローチ:
- 関数内に負荷分散プログラムを書きます。
- バージョンの反復のために実行環境を変更するのではなく、コードのバージョンを入れ替えるだけで済みます。
- 実際の業務トラフィックに応じて課金され、ピーク時以外は低額または無課金となります。
シナリオ3:IoTデータ処理
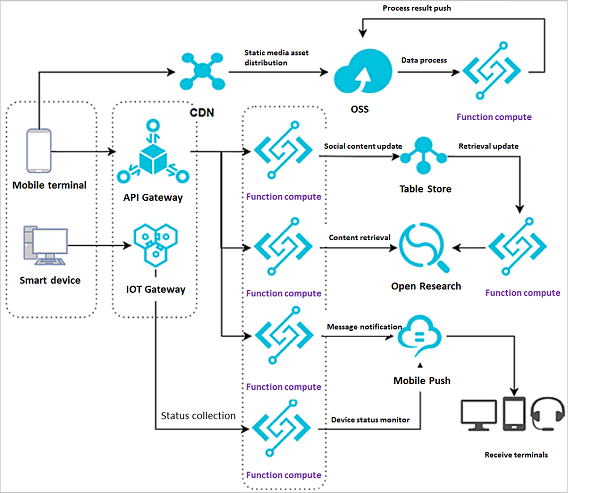
アーキテクチャは2つの部分に分かれています。
- ウェブアプリケーション:ソーシャルメディアのコンテンツ更新とデータ処理の流れをシミュレートします。ウェブユーザからのリクエストは、処理のためにAPI GatewayからFunction Computeに転送されます。その後、Function Computeはデータベース内の処理されたコンテンツを更新し、インデックスを更新します。別のFunction Computeインスタンスは、インデックスの更新を検索エンジンにプッシュし、新しいコンテンツは外部の顧客によって検索されます。これは、クローズドループのデータプロセスです。
- スマートデバイス:IoTゲートウェイは、処理のためにスマートデバイスのステータスをFunction Computeにプッシュします。Function ComputeはAPIを使用してMobile Pushにメッセージを送信し、ステータス確認と管理のためにモバイル端末にメッセージをプッシュします。
スマートデバイスのステータス処理には、いくつかの重要な技術的な困難も発生します。多数のデバイスからIoTプラットフォームへのステータスデータを処理するために、効率的な非ポーリング技術フレームワークを設計する必要があります。次に、データベースへの書き込みやモバイル端末へのデータのプッシュなど、処理されたデータを効率的かつ透過的に他の製品に送信する方法が必要です。
IoTデバイスの状態を知るための従来のアプローチ
- イベント通知を受け取るためのメッセージチャネルを設定し、関連するビジネスコードを記述する。
- バックエンドのデータ処理のためのサーバーリソースを購入する。
- 複数の製品をアクティベートし、ビジネスインタラクションのためのSDKコードを呼び出す。
- 関連するハードウェアとソフトウェアの環境を維持する。
Function Computeのアプローチ:
- IoTプラットフォームのイベント通知をカスタマイズし、関連するビジネスコードを直接Function Computeに記述する。
- 使ったらすぐに実行環境を解放することができる。
- コンソールコンフィグレーションを利用して、関連する製品に透過的に情報を伝達する。
これら2つの方法を比較すると、Function Computeソリューションの方がより汎用性が高く、保守作業の負荷を大幅に軽減できることがわかります。
シナリオ4:共有派遣システムの詳細
顧客は派遣プラットフォームを利用して、食品の注文や商品の購入など、様々な販売者が提供するサービスの中から選択することができます。そして、派遣プラットフォームは、最寄りの配送員に通知して、最寄りの販売者から該当する商品を受け取り、顧客に商品を届けます。簡単なプロセスは下図のようになります。
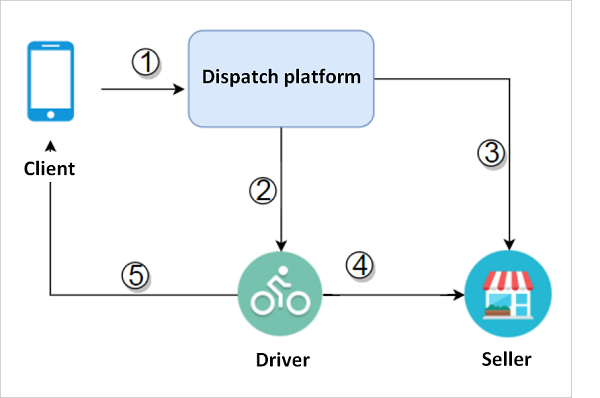
プロセスの詳細:
1、顧客は派遣プラットフォームに商品を注文するように通知します。
2、派遣プラットフォームは、最寄りの配送スタッフに通知します。
3、派遣プラットフォームは、同時に売り手に製品を販売することを通知します。
4、配達スタッフは、製品をピックアップするために指定された販売者に行きます。
5、配送スタッフは、顧客の場所に商品を配送します。
この派遣シナリオでは、いくつかの技術的な困難を解決しなければなりません。
1、様々なリソースを統合する必要があります。コンピューティングリソースには、配送スタッフの位置情報、最適なルート、車両条件、スケジューリングシステムが含まれます。
2、低レイテンシ:派遣システムでは、迅速な注文対応が求められます。売り手が注文を受けてから、注文が顧客に届くまでの全てのプロセスを一定期間内に完了させる必要があります。
- 膨大なデータ量:顧客データ、販売者データ、位置情報や商品情報などのプラットフォーム配送担当者データの3種類のデータがあります。
- 依頼量の変動が大きい:派遣システムが必要とするリソースは、特定のピーク時間帯(食材宅配サービスの場合はランチやディナーなど)とそうでない時間帯があり、一日を通して変動します。
Alibaba Cloud製品ソリューションを選択した後、Function Computeは他の製品と連携してこれらの問題を効果的に解決します。ソリューションのアーキテクチャを次の図に示します。
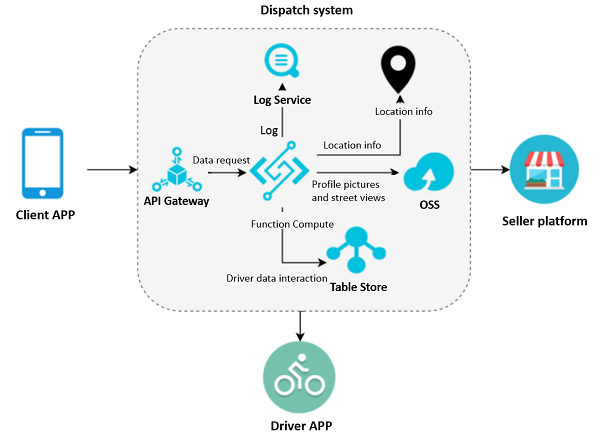
プロセスの詳細:
1、顧客アプリは、API Gatewayを介して透過的に注文リクエストをFunction Computeに送信します。
2、Function Computeは、処理されたデータをTable Storeに送信します。
3、テーブルストアには、ルートデータ、販売者情報、位置情報が格納されます。
注意事項
ここでは、ルートログはログサービスに格納され、その後の報告や分析を容易にします。配送プロセスでは、配送スタッフのプロフィール写真やストリートビューがOSSに格納されます。Function Computeは、AutoNavi Mapsなどのサードパーティの地図情報から配送スタッフの場所を引き出すために使用することができます。
このソリューションでは、Function Computeはダイナミックなリサイズ機能を提供することができ、API Gatewayは認証を行い、安全なアクセスを保証します。Function Computeは、他のリソースやコンテンツをシームレスに利用するために、複数の製品と通信することができます。処理されたデータはすべてTable Storeデータベースに保存され、すべてのログは、その後のデータレポートのために直接Log Serviceにロードされます。
共有ディスパッチシステムの従来のアプローチ:
- ピーク時のトラフィックをサポートするために複数のサーバーを購入 低トラフィック期間のためのリリース原則を独立して構成する。
- 複数の製品間の相互作用を可能にするコードを記述する。
- ロードバランシングをサポートするために関連製品を購入する。
- 関連するハードウェアとソフトウェアの環境を維持する。
Function Computeのアプローチ:
- IoTプラットフォームのイベント通知をカスタマイズし、関連するビジネスコードを直接Function Computeに記述する。
- 使ったらすぐに実行環境を解放することができる。
- コンソール構成を使用して、関連する製品に情報を透過的に伝達する。
- どちらのソリューションも有効ですが、リソース利用率やメンテナンスの面ではサーバーレスアーキテクチャの方が優れている。
概要
前述のシナリオを通して、次のような結論に達することができます。イベントトリガーシナリオ、ビジネストラフィックの変動を伴うシナリオ、および複数の他の製品への迅速な接続を必要とする反復的なシナリオにおいて、Function Computeは、コスト、効率性、および接続性に関する考慮事項に対処するための最適なソリューションを提供します。
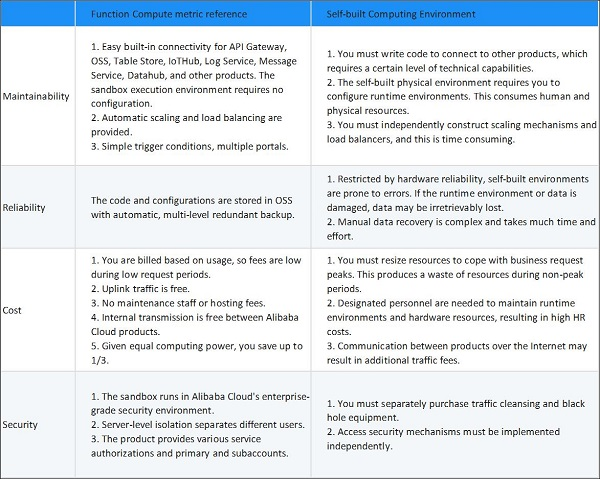
Function Computeは多くのシナリオに適用されますが、それはワンサイズのソリューションではありません。例えば、あなたのビジネスが日中に大きなリクエスト変動を経験しない場合、Function Computingはあまり節約にはなりません。
新興技術として、サーバーレスフレームワークは、一般版がまだパイプラインの中にあり、より多くの開発ツールをサポートするには至っていません。さらに、Function Computeの実行環境は状態を記録しないので、サーバーレスフレームワークは緊密に結合されたアプリケーションにはあまり適していません。割り当て可能なリソースが限られているため、特定の大規模アプリケーションを分割して起動することは容易ではありません。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ