コンテナプラットフォームのシニアエキスパートであるZeng Fansong氏が、etcdの歴史、進化、正しい使い方を解説します。
Alibaba Cloudシニア・コンテナプラットフォームテクニカルエキスパート Zeng Fansong (Zhuling) 著
Etcdは、設定の共有やサービスの発見に使用される、分散型で一貫性のあるKey-Value Store(KVStore)です。この記事では、etcdの進化に注目し、その全体的なアーキテクチャと仕組みを紹介します。この記事が皆様のetcdに対する理解と使用の助けになれば幸いです。
1. etcdの開発経緯
Etcdは当初、CoreOS社によって、クラスタ管理システムにおけるOSアップグレードの分散同時制御や、設定ファイルの保存・配布を目的として開発されました。そのため、etcdは高可用性と高整合性のスモールKVStoreサービスを提供するために設計されています。
Etcdは現在、Cloud Native Computing Foundation(CNCF)に所属しており、Amazon Web Services(AWS)、Google、Microsoft、Alibabaなどの大手インターネット企業で広く利用されています。

CoreOSは、2013年6月に最初のバージョンの初期コードをGitHubに提出しました。
2014年6月には、Kubernetes V0.4がコミュニティに公開されました。Kubernetesは、Googleが開発し、コミュニティに貢献しているコンテナ管理プラットフォームです。Googleが長年培ってきたコンテナスケジューリングやクラスタ管理の経験を統合していることから、当初から大きな注目を集めていました。Kubernetes V0.4では、実験のコアとなるメタデータのストレージサービスとしてetcd V0.2が採用され、その後、etcdのコミュニティは急速に発展しました。
2015年2月、etcdは最初の公式安定版であるV2.0をリリースしました。V2.0では、etcdはRaftコンセンサスアルゴリズムを再設計し、シンプルなツリーデータビューを提供し、1秒間に1,000回以上の書き込みをサポートして、当時のほとんどのシナリオの要件を満たしました。etcd V2.0のリリース後、そのオリジナルのデータストレージソリューションは、継続的な反復と改善を経て、徐々にパフォーマンスのボトルネックとなっていきました。その後、etcdはV3.0のソリューション設計を開始しました。
2017年1月、etcdは、etcd技術の成熟を示すV3.1をリリースしました。 etcd V3は、新しいAPIセットを提供し、より効率的な一貫性読み取りメソッドを可能にし、etcdの読み取りパフォーマンスを向上させるgRPCプロキシを提供しました。さらに、V3のソリューションには多くのGC最適化が含まれており、毎秒10,000回以上の書き込みをサポートしていました。
2018年には、30以上のCNCFプロジェクトが、コアデータストレージとしてetcdを使用しました。2018年11月、etcdはCNCFのインキュベーションプロジェクトとなりました。CNCFに参加した後、etcdには、AWS、Google、Alibabaなどの8社の9人のプロジェクトメンテナーを含む400を超える貢献グループがありました。
2019年には、etcd V3.4がGoogleとAlibabaによって共同で作成され、超大企業の厳しいシナリオに対応するために、etcdのパフォーマンスと安定性がさらに向上しました。
2. アーキテクチャと内部機構の分析
全体のアーキテクチャ
Etcdは、分散型システムで鍵データを保存するために使用される、分散型で信頼性の高いKVStoreシステムです。
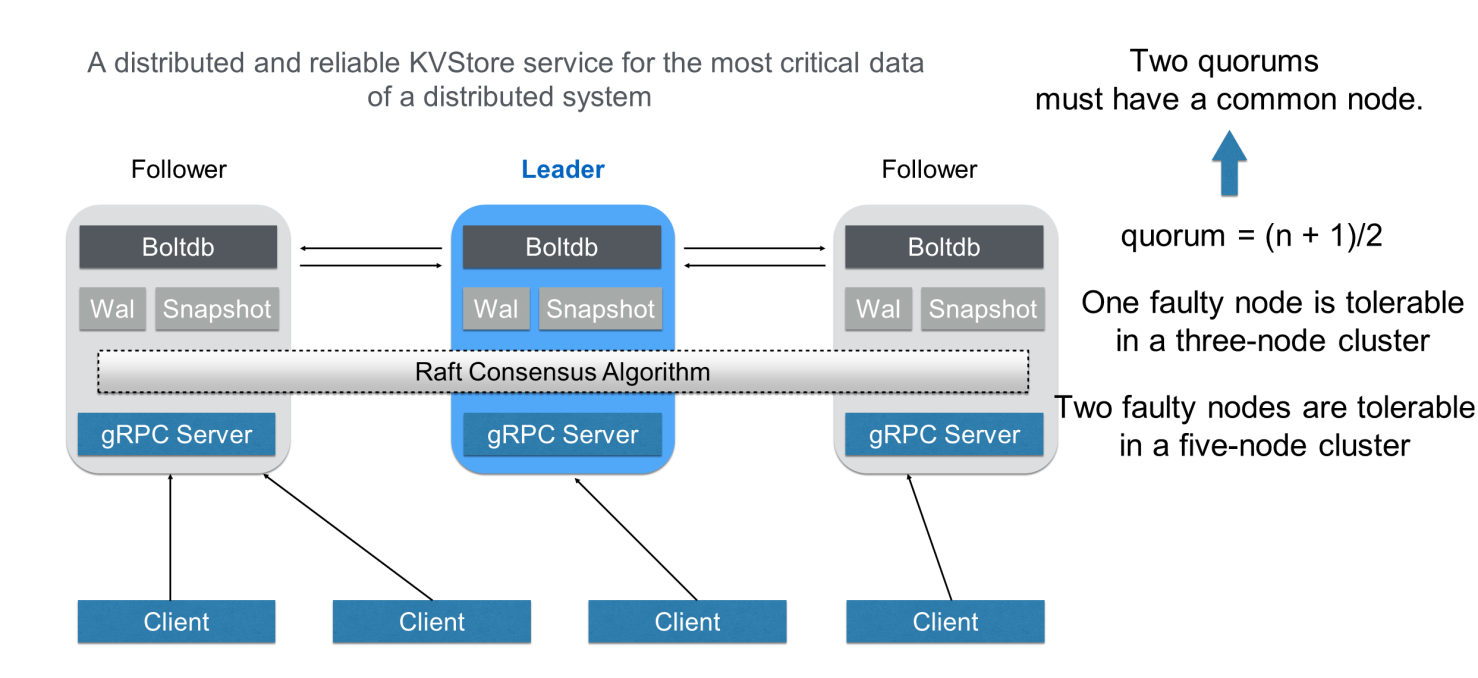
etcdクラスターは、3つまたは5つのノードで構成されています。複数のノードは、ラフトコンセンサスアルゴリズムによって相互に協力し合います。このアルゴリズムでは、データの同期と配布を担当するマスターノードをリーダーとして選出します。リーダーが故障した場合、システムは自動的に別のノードをリーダーとして選出し、再びデータの同期を完了させます。データの読み書きに必要なのはいずれか1つのノードだけで、内部の状態やデータの連携はetcdが完了します。
クォーラムは、etcdの重要なコンセプトです。これは(n+1)/2と定義され、クラスタ内のノードの半分以上がクォーラムを構成することを示します。3ノードのクラスターでは、2つのノードが利用可能である限り、etcdは動作します。同様に、5ノードのクラスターでは、3つのノードが利用可能である限り、etcdは実行されます。これが、etcd クラスタの高可用性の鍵です。
いくつかのノードが故障した後でもetcdが継続して稼働できるようにするためには、分散一貫性という複雑な問題を解決しなければなりません。etcdでは、分散型コンセンサスアルゴリズムはRaftコンセンサスアルゴリズムによって実装されています。以下に、このアルゴリズムについて簡単に説明します。Raftコンセンサスアルゴリズムは、任意の2つのクォーラムに共有メンバーがいる場合にのみ動作します。つまり、生きているクォーラムには、クラスタ内のすべての確認済みおよび送信済みのデータを含む共有メンバーが含まれている必要があります。この原則に基づいて、Raftコンセンサスアルゴリズムでは、リーダーが変更された後に最後のクォーラムから提出されたすべてのデータを同期するデータ同期メカニズムが設計されています。これにより、クラスタの状態が変化しても、データの一貫性が保たれます。
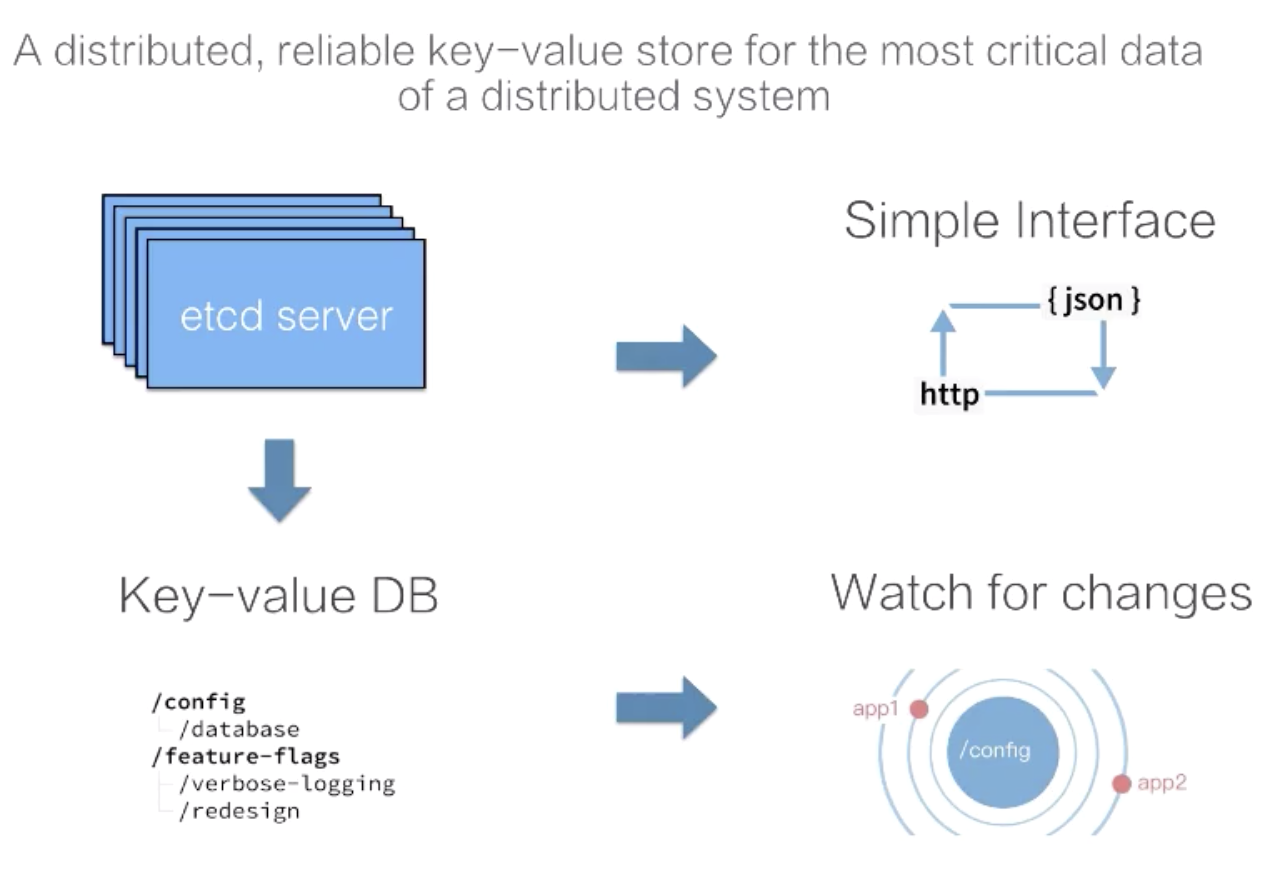
Etcdは複雑な内部機構を持っていますが、顧客のためにシンプルで直接的なAPIを提供しています。前述の図のように、クラスタのデータには、etcdクライアントを介してアクセスすることもできますし、HTTPで直接etcdにアクセスして、curlコマンドに似たようなことをすることもできます。etcdのデータ表現はシンプルです。etcdのデータストレージは、キーバリューデータを格納する順序付きマップと理解してよいでしょう。また、etcdは、クライアントのデータ変更を購読するウォッチメカニズムを提供します。ウォッチメカニズムは、データをetcdと同期させるために、etcdのインクリメンタルなデータ更新をリアルタイムで取得します。
APIの紹介
このセクションでは、etcdが提供する5つのAPI群について説明します。

- PutとDelete:前述の図に示すように、PutとDeleteの操作は簡単です。クラスタにデータを書き込むにはキーと値だけが必要で、データを削除するにはキーだけが必要です。
- Get: etcdは、指定されたキーによるクエリと、指定されたキーの範囲によるクエリをサポートしています。
- Watch: etcd は、リアルタイムで etcd のインクリメンタルなデータ更新を購読する Watch メカニズムを提供します。Watch では、キーまたはキーのプレフィックスを指定できます。一般的には、後者のオプションが使用されます。
- トランザクション: etcd は、ある一連の条件が満たされたときに特定の操作を実行したり、条件が満たされないときに他の操作を実行するためのシンプルなトランザクションメカニズムを提供します。これはコードで使用される if...else ステートメントに似ています。etcd はすべての操作のアトミック性を保証します。
- Leases: Leases APIは、分散システムにおいて一般的なデザインモードです。
データバージョンの仕組み
etcdのAPIを正しく使用するには、対応する内部データのバージョンを知っておく必要があります。
etcdでは、クラスタリーダーの任期を表すためにtermを使用します。リーダーが変更されると、termの値が1増加します。リーダーが変更されるのは、リーダーが故障したとき、リーダーのネットワーク接続が異常になったとき、またはクラスターが停止して再起動したときです。
リビジョンとは、グローバルデータのバージョンのことです。データが作成、変更、削除されると、リビジョンの値は1ずつ増加します。具体的には、リビジョンは、クラスタ内のリーダーターム全体で常にグローバルに増加します。この機能により、クラスタ内のどのような変更に対しても、一意のリビジョンが利用できるようになります。そのため、MVCC(Multi-Version Concurrency Control)やリビジョンに基づくデータウォッチをサポートすることができます。
etcdは、各key-valueデータノードの3つのバージョンを記録します。
- create_revision は、キーバリュー データの作成時のリビジョンです。
- mod_revision は、データ操作時のリビジョンです。
- counterは、キーバリューデータが何回修正されたかを示します。
次の図は、用語とリビジョンの変更を示しています。
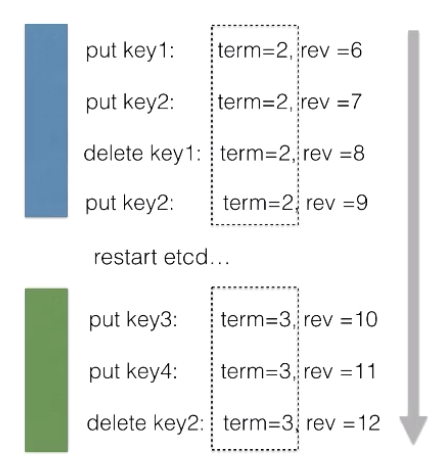
リーダーの任期中、すべての変更操作の項の値は2で、revの値は毎回1ずつ着実に増加していきます。クラスタの再起動後、すべての変更操作の項の値は3に変更されます。新しいリーダーの任期中、すべての項の値は3で変更されませんが、revの値は毎回1ずつ増加し続けています。2人のリーダーの任期中、REV値は着実に増加していきます。
MVCCとストリーミング視聴
ここでは、複数のバージョンのetcdを使用して、同時制御とデータ購読(Watch)を実装する方法について説明します。
etcdでは、同一キーに対して複数回のデータ変更が可能であり、各データ変更にはバージョン番号が対応しています。etcdは各変更のデータを記録しているため、1つのキーには複数の履歴バージョンが存在することになります。データを照会する際にバージョンを指定しない場合、etcdはキーの最新バージョンを返します。etcdはバージョンによる履歴データの照会もサポートしています。

データをサブスクライブするためにWatchを使用する場合、任意の履歴時間または指定されたリビジョンからウォッチャーを作成し、クライアントとetcdの間にデータパイプラインを作成することができます。etcdは指定されたリビジョン以降に発生したすべてのデータ変更をプッシュします。etcdが提供するWatchメカニズムは、キーの変更されたデータを、データパイプラインを通じて直ちにクライアントにプッシュします。
次の図に示すように、etcdのすべてのデータはB+ツリー(グレーで表示)に格納されており、B+ツリーはディスクに格納され、クイックアクセスのためにmmapモードでメモリにマッピングされています。灰色の B+ ツリーは、リビジョンと値のマッピングを維持し、リビジョンによるデータ検索をサポートします。したがって、Watch を使用して指定したリビジョン以降のデータをサブスクライブする場合、B+ ツリーのデータ変更をサブスクライブするだけで済むことになります。
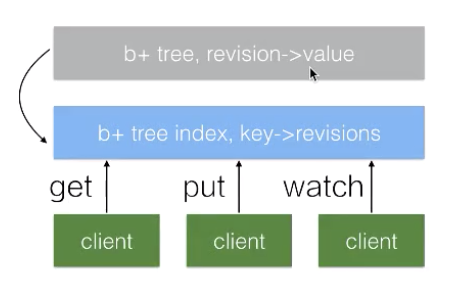
もうひとつのB+ツリー(青)は、キーとリビジョンのマッピングを管理するetcdで管理されています。鍵を使ってデータを照会する場合、クライアントは青のB+ツリーで鍵をリビジョンに変換し、グレーのB+ツリーでデータを照会します。
Etcdは各修正を記録するが、これはデータの継続的な増加を招き、メモリとディスクスペースを占有し、B+ツリーのクエリ効率に影響を与えます。 etcdは定期的なコンパクションメカニズムを使用して、ある時間以前に作成された同じキーの複数の履歴バージョンのデータをクリーンアップします。その結果、グレーのB+ツリーは、多少のギャップはあるものの、着実に増え続けています。
ミニ・トランザクション
このセクションでは、etcdのミニ・トランザクション・メカニズムについて説明します。etcdのトランザクションメカニズムはシンプルです。それはif-elseプログラムと考えることができ、次の図のようにif文の中で複数の操作を提供することができます。

Ifステートメントには2つの条件が含まれています。Value(key1)の値がbarの値より大きく、Version(key1)の値が2であれば、Thenステートメントを実行してkey2のデータをvalueXに変更し、key3のデータを削除します。いずれの条件も満たさない場合は、key2のデータをvalueYに変更します。
Etcdは、トランザクション操作全体のアトミック性を確保します。つまり、If文の中のすべての比較条件のビューが一貫していることです。また、Then文のすべての操作が実行されるという、複数の操作のアトミック性も確保されています。
etcdのトランザクション機構を使えば、複数の競技でデータの読み書きの一貫性を確保することができます。例えば、前述のKubernetesプロジェクトでは、複数のKubernetes APIサーバーで同じデータが一貫して変更されることを保証するために、etcdのトランザクションメカニズムを使用しています。
Lease
Leaseは、一般的に分散システムにおける分散リースを表すために使用されます。典型的には、分散システムにおいてノードが生きているかどうかを検出するために、リース機構が必要となる。
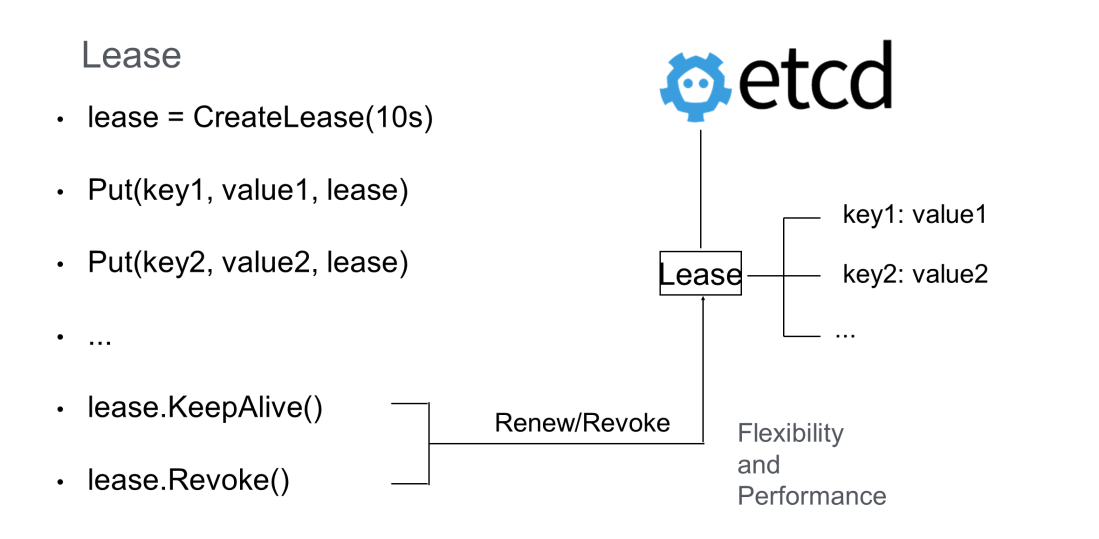
上図のように、10秒間のリースが作成されます。リース作成後に何も操作しなければ、10秒後に自動的にリースが終了します。リースにkey1とkey2をバインドして、リースが切れるとetcdが自動的にkey1とkey2をクリアするようにします。
リースを維持したい場合は、定期的に KeeyAlive メソッドを呼び出してリースを更新する必要があります。例えば、分散システムのプロセスが生きているかどうかを確認するには、そのプロセスにリースを作成し、定期的にプロセスのKeepAliveメソッドを呼び出します。プロセスが正常であれば、このノードのリースは維持されます。プロセスがクラッシュした場合は、リースは自動的に失効します。
しかし、多数のキーが同様のリースメカニズムをサポートする必要があり、キーごとに独立してリースを更新しなければならない場合、これはetcdに大きな負担をかけることになります。そこで、etcd では、複数の鍵(例えば、有効期限が似ている鍵)を同じリースにバインドすることができ、これにより、リースリフレッシュのオーバーヘッドを大幅に削減し、etcd のパフォーマンスを向上させることができます。
3. 典型的なシナリオ
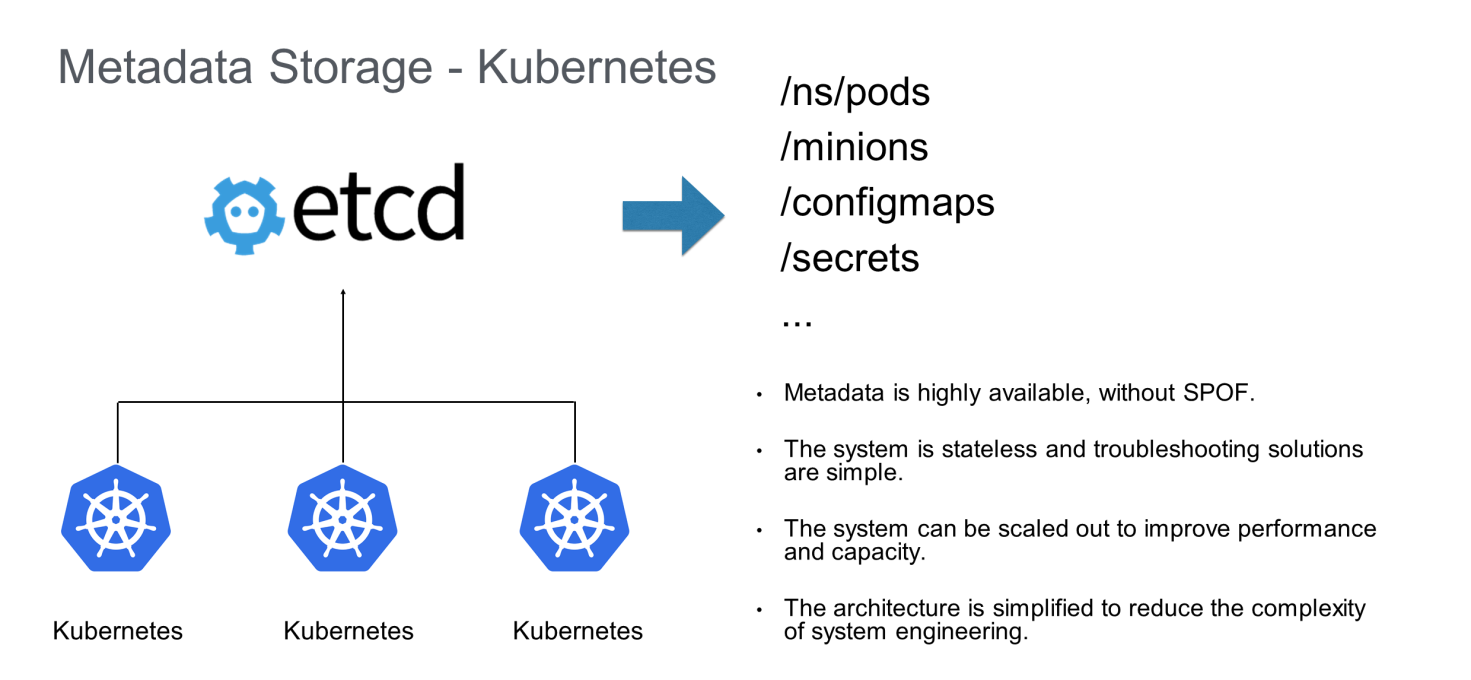
メタデータの保存
Kubernetesは、高可用性のためにステータスデータをetcdに格納しています。これにより、Kubernetesは分散システムの複雑なステータス処理を行う必要がなくなり、システムアーキテクチャを大幅に簡素化することができます。
サービスディスカバリー(ネーミングサービス)
分散システムでは、検索サービスやレコメンデーションサービスなどのピアサービスを提供するために、複数のバックエンド(場合によっては数百のプロセス)が必要になります。
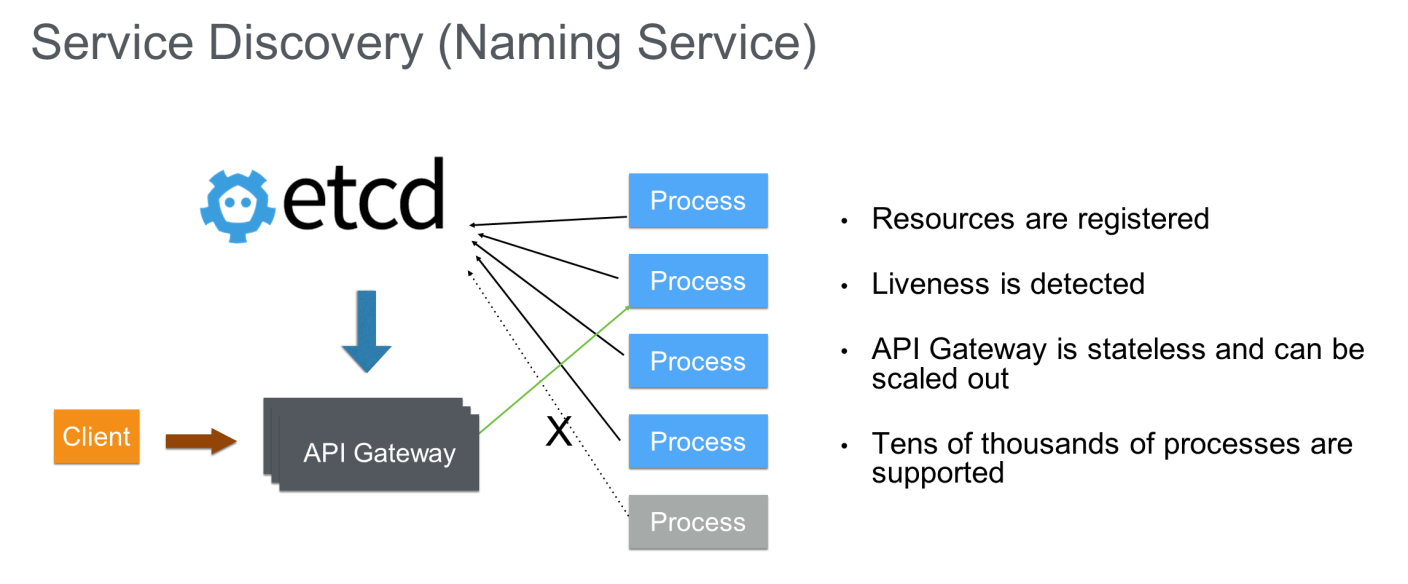
このようなバックエンドサービスのO&Mコスト(故障したノードはすぐに交換される)を削減するために、バックエンドプロセスはKubernetesのようなクラスタ管理システムによってスケジューリングされます。このようにして、ユーザーや上流のサービスがこのプロセスを呼び出す際には、サービスをルーティングするためのサービス・ディスカバリー・メカニズムが必要になります。このサービスディスカバリーは、etcdを使うことで効率的に実装できます。
- プロセスを起動した後、プロセスのアドレスをetcdに登録することができます。
- API Gatewayは、etcdを使用してバックエンドプロセスのアドレスを迅速に検出することができます。フェイルオーバーが発生した場合、新しいプロセスのアドレスを etcd に登録することで、API Gateway は新しいアドレスを速やかに検出することができます。
- サービングプロセスがクラッシュした場合、API Gateway は etcd のリースメカニズムを利用してそのトラフィックを削除し、コールタイムアウトを防ぐことができます。
このアーキテクチャでは、サービスステータスデータはetcdに引き継がれ、API Gatewayはステートレスなので、より多くの顧客にサービスを提供するためにスケールアウトすることができる。etcdの優れたパフォーマンスにより、数万のバックエンドプロセスがサポートされているため、このアーキテクチャは大企業にも対応できる。
分散型コーディネーション:リーダーの選出
分散システムでは、マスター+ワーカーという設計モデルが一般的に採用されています。一般的に、ワーカーノードはCPU、メモリー、ディスク、ネットワークなどのさまざまなリソースを提供し、マスターノードはこれらのノードを調整して、分散ストレージや分散コンピューティングなどの外部サービスを提供します。代表的なHadoop分散ファイルシステム(HDFS)も、Hadoop分散コンピューティングサービスも、同様の設計モデルを採用しています。このようなデザインモデルには、マスターノードの可用性という共通の問題があります。マスターノードに障害が発生すると、クラスター内のすべてのサービスが停止し、ユーザーにサービスを提供できなくなります。
一般的な解決策は、複数のマスターノードを起動することです。マスターノードには制御ロジックが含まれており、複数のノード間でのステータスの同期は複雑です。最も典型的な方法は、サービスを提供するリーダーとしてマスターノードを選択し、他のマスターノードは待機状態にすることです。
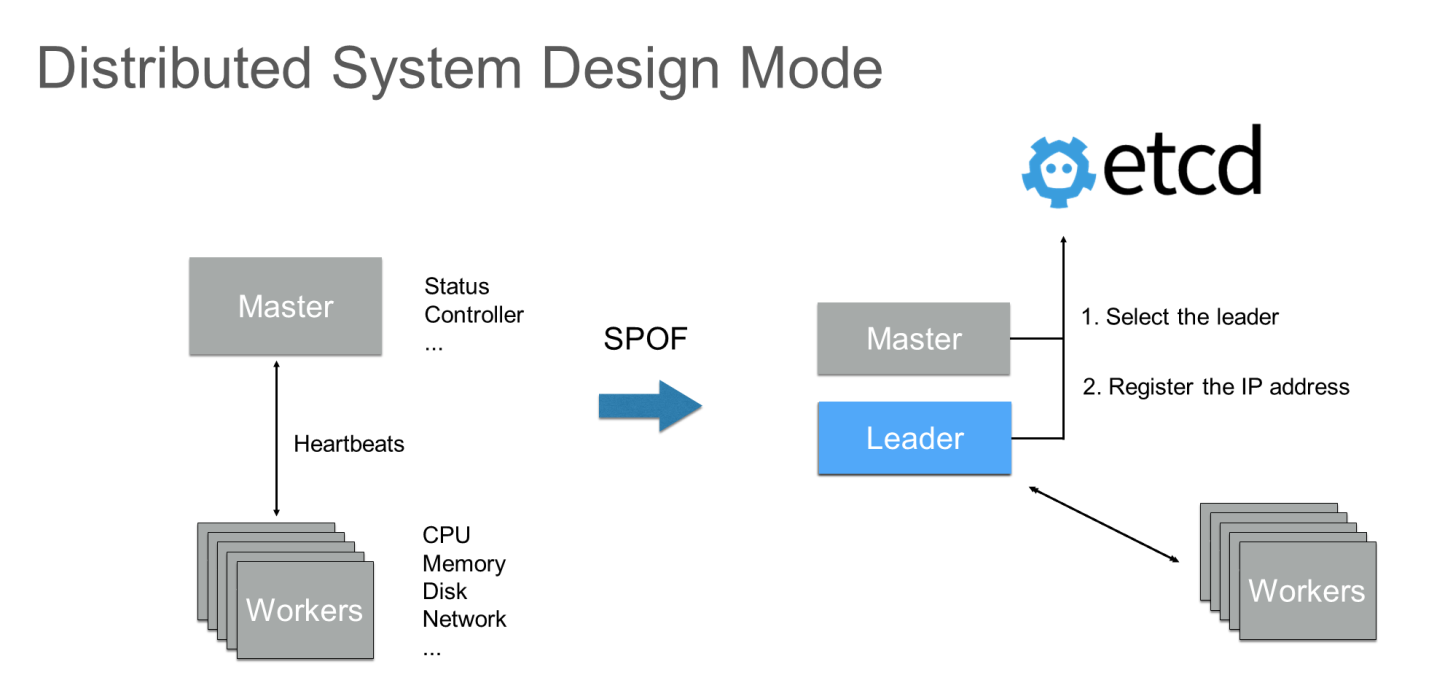
etcdが提供するメカニズムは、分散プロセスのリーダー選出機能を容易に実装することができます。例えば、リーダー選出ロジックは、同一キーに対するトランザクションの書き込みによって実装することができます。一般的に、選出されたリーダーはそのIPアドレスをetcdに登録し、ワーカーノードが現在のリーダーのIPアドレスを速やかに取得できるようにし、システムは1つのマスターノードのみで動作し続けることができます。リーダーに例外が発生した場合は、etcdを通じて新しいノードをリーダーとして選択することができます。新しいIPアドレスが登録された後、ワーカーノードは新しいリーダーのIPアドレスを引き出してサービスを再開することができます。
分散コーディネーション。分散システムのコンカレンシー制御
分散システムでは、オペレーティングシステムのアップグレード、オペレーティングシステム上のソフトウェアのアップグレード、コンピューティングタスクの実行など、いくつかのタスクを実行する際には、バックエンドサービスのボトルネックを防ぎ、ビジネスの安定性を確保するために、タスクの同時実行性を制御する必要があります。タスクの調整を実施するマスターノードがない場合は、etcdを使用して調整することができます。
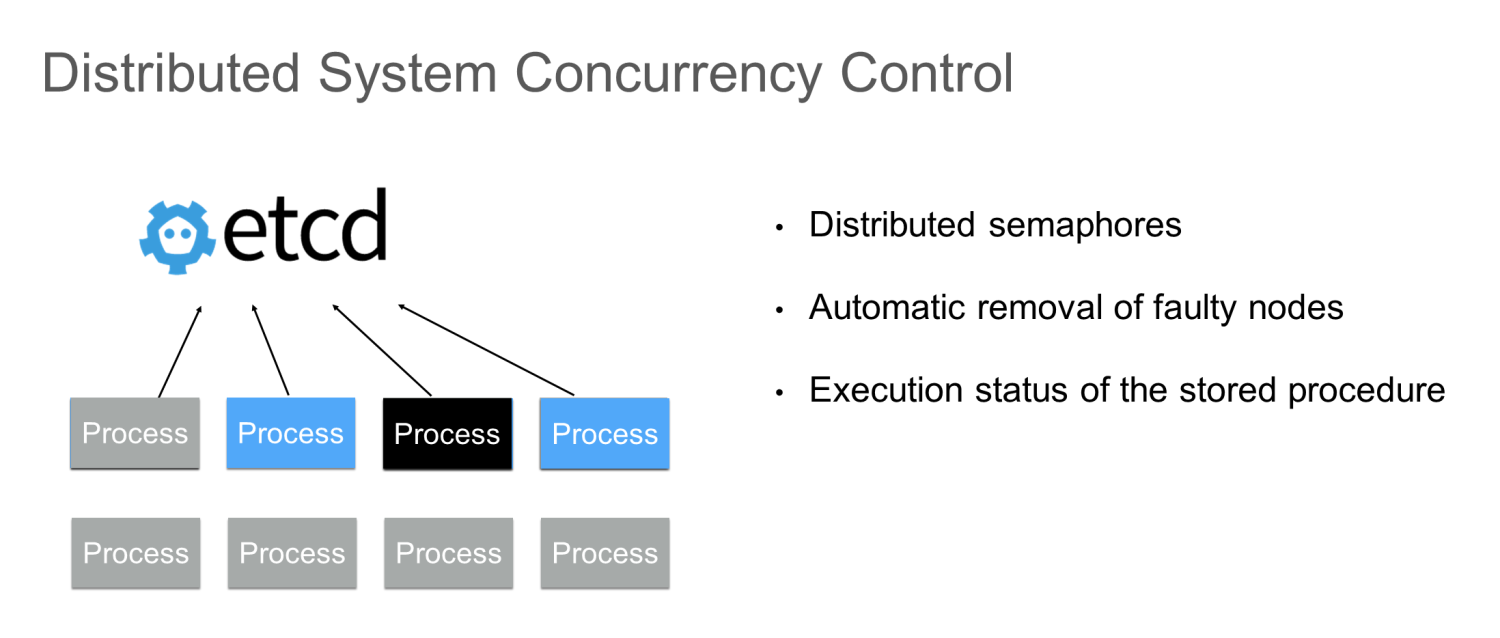
このモードでは、etcdを使って分散型セマフォを実装し、etcdのリースメカニズムを使って故障したノードを自動的に削除することができます。プロセスの実行サイクルが長い場合、いくつかの生成されたステータスデータを etcd に保存することができます。このようにして、プロセスが失敗した場合、コンピューティングロジック全体を再度完成させるのではなく、いくつかの実行ステータスをetcdから復元することができます。これにより、タスク全体の効率が向上します。
まとめ
今回の記事で学んだことをまとめてみましょう。
- 第1部では、etcdの登場と、その進化の過程におけるいくつかの重要な瞬間について説明しました。
- 第2部では、etcdのアーキテクチャと基本的なAPIを紹介し、etcdの基本的なデータ操作とetcdがどのように動作するかを説明しました。
- 第3部では、3つの典型的なetcdのシナリオと、これらのシナリオにおける分散システムの設計思想について説明しました。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ