このブログ記事では、Apache Flinkとそのエコシステムが、多くの課題を抱えながらも、機械学習の分野で何か素晴らしいことが起こるであろう、その可能性について論じています。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
執筆者 Jian Feng
Apache Flink のエコシステムについて議論する前に、まずエコシステムとは何かを見てみましょう。ITの世界では、エコシステムとは、共通のコアコンポーネントから派生したコンポーネントのコミュニティであり、このコアコンポーネントを直接または間接的に利用し、このコアコンポーネントと一緒に利用することで、より大きな、あるいはより特殊な種類のタスクを達成することができると理解することができます。続いて、Flinkのエコシステムとは、コアコンポーネントとしてのFlinkを取り巻くエコシステムのことを指します。
ビッグデータのエコシステムの中では、Flinkは計算側のみを扱う計算コンポーネントであり、独自のストレージシステムは一切関与しないということになります。しかし、多くの実用的なシナリオでは、Flinkだけでは要件を満たすことができないことに気づくかもしれません。例えば、データをどこから読み込むか、Flinkで処理されたデータをどこに保存するか、データをどのように消費するか、垂直的なビジネス分野で特殊なタスクを達成するためにFlinkをどのように使用するかなどを検討する必要があるかもしれません。下流と上流の両方の側面に加えて、より高い抽象度を伴うこれらのタスクを達成するためには、1つの強力なエコシステムが必要になります。
Flinkエコシステムの現状
エコシステムとは何かを理解したところで、Flinkエコシステムの現状について話してみましょう。全体的に見て、Flinkエコシステムはまだ黎明期にあります。現在、Flinkのエコシステムは主にアップストリームとダウンストリームの様々なコネクタと数種類のクラスタをサポートしています。
Flinkが現在サポートしているコネクタを一日中リストアップすることができます。しかし、いくつか挙げるとすれば、Kafka、Cassandra、Elasticsearch、Kinesis、RabbitMQ、JDBC、HDFSです。次に、Flinkはほぼすべての主要なデータソースをサポートしています。クラスタに関しては、現在FlinkはStandaloneとYARNをサポートしています。このエコシステムの現状を踏まえると、Flinkは主にストリームデータの計算に使われています。他のシナリオ(機械学習や対話型分析など)でFlinkを使用することは比較的複雑な作業になる可能性があり、これらのシナリオでのユーザーエクスペリエンスにはまだ多くの希望が残されています。しかし、このような課題の中にあっても、Flinkエコシステムには多くのチャンスがあることは間違いありません。
Flinkエコシステムの課題と機会
Flinkは主にバッチ処理やストリーム処理に使用されるビッグデータ・コンピューティング・プラットフォームとしての役割を果たしていますが、それ以外の用途にも大きな可能性を秘めています。私の考えでは、Flinkの可能性を最大限に引き出すためには、より強力で堅牢なエコシステムが必要だと考えています。Flinkをよりよく理解するために、2つの異なるスケーリング次元からエコシステムを評価することができます。
1、水平方向のスケーリング。水平方向のスケーリングという点では、エコシステムは、すでに持っているものに対して、より完全なエンドツーエンドのソリューションを構築する必要があります。例えば、このソリューションには、上流と下流の異なるデータソースを接続するさまざまなコネクタや、下流の機械学習フレームワークとの統合、さらには下流のBIツールとの統合、Flinkジョブの提出とメンテナンスを簡素化するツールや、よりインタラクティブな分析体験を提供するノートブックなどが含まれるかもしれません。
2、垂直的なスケーリング。他の分野へのスケールアウトという意味では、より抽象的なFlinkエコシステムは、当初意図した計算シナリオを超えた要件を満たす必要がありました。たとえば、垂直方向のエコシステムには、バッチおよびストリームコンピューティング、テーブルAPI(より高度な計算抽象化レイヤーを持つ)、CEP(複雑なイベント処理エンジン)、Flink ML(機械学習のためのより高度なコンピューティングフレームワークを持つ)、さまざまなクラスタフレームワークへの適応などがあります。
以下の図は、上記のようにFlinkのエコシステムが水平・垂直方向にスケールした場合を想定したものです。
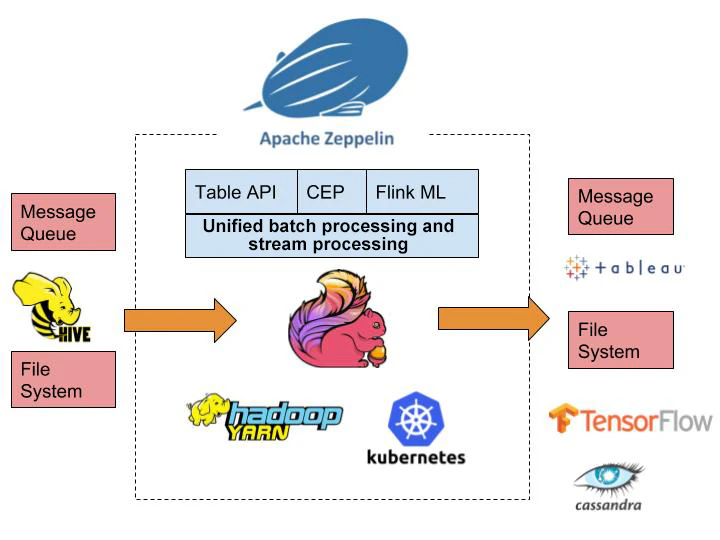
FlinkとHiveの統合
Apache Hiveは10年近く前に開発されたトップレベルのApacheプロジェクトです。このプロジェクトは当初、MapReduceの上にSQL文をカプセル化していました。ユーザーは、複雑なMapReduceジョブを書かなくても、使い慣れたシンプルなSQL文を書くだけで済むようになりました。ユーザーからのSQL文は、1つまたは複数のMapReduceジョブに変換されます。プロジェクトの継続的な進化の過程で、Hiveのコンピューティングエンジンはプラグイン可能になりました。現在、Hiveは3つのコンピューティングエンジンをサポートしています。MR、Tez、Sparkの3つのコンピューティングエンジンをサポートしています。Apache Hiveは、Hadoopエコシステムにおけるデータウェアハウスの業界標準となっています。多くの企業が何年も前からデータウェアハウスシステムをHive上で運用しています。
Flinkはバッチ処理とストリーム処理を統合したコンピューティングフレームワークなので、当然ながらHiveと統合する必要があります。例えば、Flinkを使ってETLを実行してリアルタイムデータウェアハウスを構築する場合、リアルタイムデータクエリにはHiveのSQLを使う必要があります。
Flinkコミュニティでは、Hiveとのより良い統合とサポートを可能にするために、FLINK-10556がすでに作成されています。その主な機能は以下の通りです。
- FlinkがHiveのメタデータにアクセスできるようにします。
- FlinkがHiveのテーブルデータにアクセスできるようにします。
- FlinkはHiveのデータ型と互換性があります。
- FlinkでHive UDFを使用できます。
- FlinkでHive SQLを使用できます(DMLやDDLを含む)。
Flinkコミュニティでは、上記のような機能を実装するための段階的なステップを踏んでいます。これらの機能を事前に試してみたいという方は、アリババクラウドが開発したオープンソースのBlinkプロジェクトを試してみると良いでしょう。オープンソースのBlinkプロジェクトでは、FlinkとHiveをメタデータ層とデータ層で接続しています。ユーザーはFlink SQLを直接使ってHive内のデータをクエリしたり、実際の意味でHiveとFlinkをシームレスに切り替えることができます。メタデータに接続するために、BlinkはFlinkカタログの実装を再構築し、メモリベースのFlinkInMemoryCatalogと、Hive MetaStoreに接続するHiveCatalogの2つのカタログを追加しました。このHiveCatalogを使用すると、FlinkのジョブはHiveからメタデータを読み取ることができます。データに接続するために、BlinkにはHiveTableSourceが実装されており、FlinkのジョブがHiveの通常のテーブルやパーティションテーブルから直接データを読み込めるようになっています。そのため、Blinkを利用することで、ユーザーはFlinkのSQLを利用して既存のHiveのメタデータやデータを読み込んでデータ処理を行うことができるようになります。アリババは今後、Hive固有のクエリ、データ型、Hive UDFのサポートなど、FlinkとHiveの互換性を向上させていく予定です。これらの改善は、徐々にFlinkコミュニティに貢献していく予定です。
Flinkでのインタラクティブな解析をサポート
バッチ処理もFlinkの一般的なアプリケーションシナリオです。インタラクティブな分析はバッチ処理の大部分を占めており、データアナリストやデータサイエンティストにとっては特に重要です。
インタラクティブな分析プロジェクトやツールに関しては、Fink 自体もパフォーマンス要件を改善するための更なる強化が必要です。FLINK-11199を例に考えてみましょう。現在、複数のジョブにまたがる同じFlinkアプリ内のデータを共有することはできません。各ジョブのDAGは分離されたままです。FLINK-11199はこの問題を解決するために設計されており、インタラクティブな分析をよりフレンドリーにサポートします。
さらに、データアナリストやデータサイエンティストがFlinkをより効率的に利用できるようにするためには、インタラクティブな分析プラットフォームが必要です。Apache Zeppelinはこの点で多くのことを行ってきました。Apache Zeppelinは、対話型の開発環境を提供し、Scala、Python、SQLなどの複数のプログラミング言語をサポートするApacheの最上位プロジェクトでもあります。また、Zeppelinは高度なスケーラビリティをサポートしており、Spark、Hive、Pigなど多くのビッグデータエンジンをサポートしています。Alibabaは、ZeppelinでFlinkのより良いサポートを実装するために多大な努力をしてきました。ユーザーは、Zeppelinで直接Flinkコード(Scala言語またはSQL言語)を書くことができます。また、ローカルでパッケージングしてからbin/flinkスクリプトを実行して手動でジョブを投入するのではなく、ユーザーはZeppelinで直接ジョブを投入してジョブ結果を見ることができます。ジョブ結果は、テキストで表示することも、可視化することもできます。SQL結果の場合は、特に可視化が重要です。Zeppelinでは、主に以下のようなFlinkのサポートを提供しています。
- 3つのrunモード ローカル、リモート、ヤーン
- Scala、バッチSQL、ストリームSQL
- 静的・動的テーブルの可視化
- ジョブURLとの自動関連付け
- ジョブキャンセル
- フリンクのSavepointの求人情報
- コントロールの作成など、ZeppelinContextの高度な機能
- 3つのチュートリアルノート ストリーミングETL、Flinkバッチチュートリアル、Flinkストリームチュートリアル
これらの変更のいくつかは Flink に実装されており、いくつかは Zeppelin に実装されています。これらの変更がすべて Flink コミュニティと Zeppelin コミュニティに貢献される前に、この Zeppelin Docker イメージを使用して、これらの機能をテストして使用することができます。Zeppelin Docker イメージのダウンロードとインストールの詳細については、Blink ドキュメントに記載されている例を参照してください。ユーザーがこれらの機能をより簡単に試すことができるように、このバージョンのZeppelinでは3つの組み込みFlinkチュートリアルを追加しました。1つはStreaming ETLの例を示し、他の2つはFlink BatchとFlink Streamの例を示しています。
#Flinkでの機械学習のサポート
ビッグデータのエコロジーにおいて最も重要なコンピューティングエンジンのコンポーネントとして、Flinkは現在、主にデータコンピューティングと処理の伝統的なセグメント、つまり従来のビジネスインテリジェンス(またはBI)(例えば、リアルタイムのデータウェアハウスやリアルタイムの統計レポート)に使用されています。しかし、21世紀は人工知能(AI)の時代です。いくつかの異なる業界の企業が、ビジネスのやり方を根本的に変えるためにAI技術を選択するケースが増えてきています。このようなビジネス界全体の変化の波に、ビッグデータコンピューティングエンジンFlinkは欠かせない存在であると言えるのではないでしょうか。Flinkが機械学習専用に開発されているわけではないにしても、Flinkのエコシステムの中で機械学習がかけがえのない役割を果たしていることに変わりはありません。そして今後、Flinkが機械学習をサポートするための3つの大きな機能を提供していくことが期待されています。
- 機械学習のためのパイプラインの構築
- 従来の機械学習アルゴリズムをサポート
- 他のディープラーニングフレームワークとの統合を可能にする
機械学習のパイプラインを見ていると、機械学習は単純にトレーニングと予測の2つの主要なフェーズに煮詰めることができると簡単に思い込むことができます。しかし、トレーニングと予測は機械学習のごく一部に過ぎません。トレーニングの前に、機械学習モデルのためにデータを準備するプロセスでは、データのクリーニング、データの変換、正規化などの作業が不可欠です。そして、訓練後には、モデルの評価も重要なステップです。予測段階でも同じことが言えます。複雑な機械学習システムでは、個々のステップを適切に組み合わせることが、ロバストでスケーラブルな機械学習モデルを生成するための鍵となります。多くの点で、FLINK-11095はこの目標を実現するためにコミュニティが現在取り組んでいるものであり、Flinkはこれらのすべてのステップを通して機械学習モデルを構築する上で重要な役割を果たしています。
現在、Flinkのflink-mlモジュールは、いくつかの伝統的な機械学習アルゴリズムを実装していますが、さらなる改善が必要です。
Flinkコミュニティでは、ディープラーニングのサポートが積極的に行われています。AlibabaはTensorFlow on Flinkプロジェクトを提供しており、ユーザーはFlinkのジョブでTensorFlowを実行し、Flinkをデータ処理に使用し、処理されたデータをTensorFlowのPythonプロセスに送って深層学習のトレーニングを行うことができます。プログラミング言語については、FlinkコミュニティがPythonのサポートに取り組んでいます。現在、FlinkはJavaとScalaのAPIのみをサポートしています。どちらの言語もJVMベースです。そのため、現在のところFlinkはシステムのビッグデータ処理には適していますが、データ分析や機械学習にはあまり適していません。一般的にデータ分析や機械学習の分野の人たちは、PythonやRなどのより高度な言語を使うことを好みますが、Flinkのコミュニティでも近い将来、これらの言語のサポートを計画しています。FlinkがまずPythonをサポートするのは、Pythonは近年、AIやディープラーニングの発展に伴い、急速な発展を遂げているからです。現在、TensorFlow、Pytorch、Kerasなど、人気のあるディープラーニングライブラリはすべてPythonのAPIを提供しています。FlinkでPythonがサポートされるようになれば、ユーザーは機械学習のためのすべてのパイプラインをたった1つの言語で接続できるようになり、開発が飛躍的に向上するはずです。
Flinkジョブの送信とメンテナンス
開発環境では、Flink のジョブは一般的にシェルコマンド bin/flink run で投入されます。しかし、本番環境で使用する場合、このジョブ投入方法は実際には多くの問題を引き起こす可能性があります。例えば、ジョブのステータスの追跡と管理、失敗したジョブの再試行、複数のFlinkジョブの開始、ジョブパラメータの変更と送信などが困難な場合があります。これらの問題は、もちろん手動での介入で解決することは可能ですが、手動での介入は、時間がかかることは言うまでもなく、生産現場では非常に危険なことです。理想的には、自動化できるすべての操作を自動化する必要があります。残念ながら、現在のところFlinkのエコシステムには適切なツールは見当たりません。アリババはすでに社内向けに適切なツールを開発しており、長い間本番で稼働しており、Flinkジョブの提出と維持のための安定した信頼性の高いツールであることが証明されています。現在、アリババは、アリババが内部的に依存しているいくつかのコンポーネントを削除し、このプロジェクトのソースコードを公開する予定です。このプロジェクトは2019年前半にオープンソース化される予定です。
要約すると、現在の Flink のエコシステムには多くの問題がありますが、同時に多くの開発の余地があります。Apache Flink のコミュニティは人間的なもので、Flink の可能性を最大限に引き出すために、より強力な Flink のエコシステムを構築するために、常に大きな努力をしています。
アイデアをお持ちですか?インスピレーションを感じていますか?コミュニティに参加して、より良いFlinkエコシステムを一緒に構築しましょう。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。