Basic Technology Mid-EndsのエキスパートであるChen Xingyu氏が、etcdクライアントを使ってetcdサーバーのパフォーマンスを最適化し、最大限に活用するための最良の方法を紹介します。
著者:アリババクラウドのテクニカルエキスパートChen Xingyu (Yumu)氏
Etcdは、コンテナクラウドプラットフォーム上に重要なメタデータを保存します。Alibabaは3年前からetcdを使用しており、2019年のDouble 11 Global Shopping Festivalでは重要な役割を担いました。この記事では、etcdサーバーのパフォーマンスを最適化し、etcdクライアントを使用するためのベストプラクティスを紹介します。お客様が安定的かつ効率的にetdクラスターを運用するための一助となれば幸いです。
1. etcdの概要
EtcdはCoreOSがGolangを使って開発しました。分散型キーバリューストレージエンジンです。etcdは分散システムのメタデータを格納するデータベースとして使用できます。etcdは大手企業で広く使用されています。
次の図は、etcdの基本アーキテクチャを示しています。
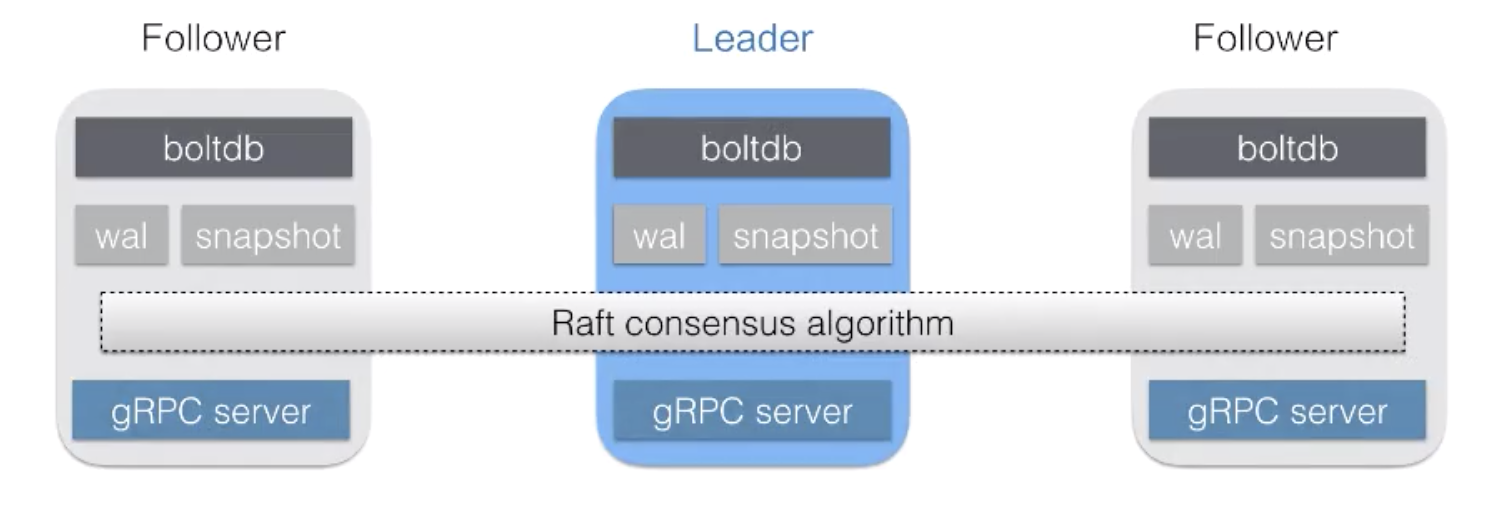
クラスタには、リーダー1台とフォロワー2台の計3台のノードがあります。各ノードは、Raftアルゴリズムを用いてデータを同期し、BoltDBにデータを保存します。1つのノードが故障すると、他のノードが自動的に新しいリーダーを選出し、クラスターの高可用性を維持します。etcdのクライアントは、どのノードに接続してもリクエストを完了することができます。
2.etcdの性能
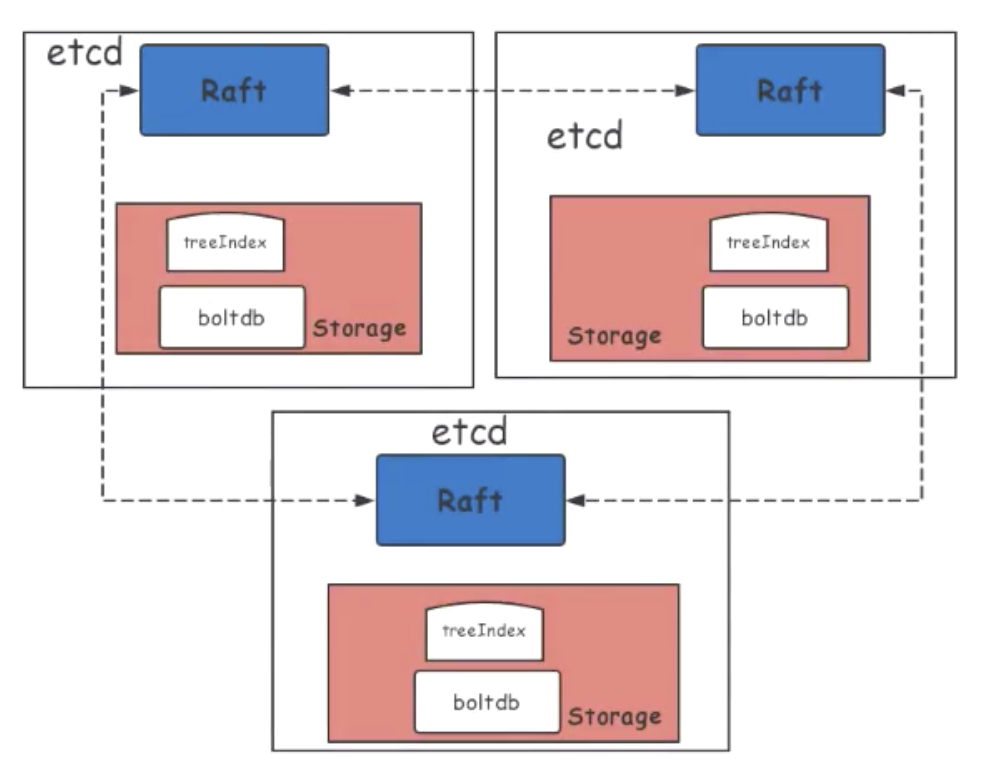
前述の図は、標準的な etcd クラスタのアーキテクチャを示しています。etcdクラスターは、Raft層(青)とストレージ層(赤)に分けられます。ストレージ層はさらに、treeIndex 層と、永続的なキーバリューストレージ用の BoltDB 層に分かれます。これらの各層は、etcd側のパフォーマンス低下を引き起こす可能性があります。
Raft 層は、ネットワークを通じてデータを同期させます。etcd のパフォーマンスは、ネットワーク内の I/O ノード間のラウンドトリップタイム(RTT)とバンド幅の影響を受ける可能性があります。WAL(Write-ahead logging)は、ディスクI/Oの書き込み速度に影響されることがあります。
ストレージ層では、ディスク I/O の fdatasync レイテンシーと treeIndex 層のロックブロックによって etcd のパフォーマンスが影響を受ける可能性があります。etcdのパフォーマンスは、BoltDBのTxロックとBoltDBのパフォーマンスに大きく影響される可能性があります。
さらに、etcd のパフォーマンスは、etcd ホストのカーネルパラメータと gRPC API レイヤーのレイテンシーの影響を受けます。
3. etcd サーバーのパフォーマンスの最適化
etcdサーバーのパフォーマンスを最適化する方法を紹介します。
ハードウェアの導入
etcdはディスクI/Oに依存したデータベースプログラムであり、I/Oレイテンシーが低く、スループットの高いソリッドステートディスク(SSD)が必要です。また、etcdは分散型のキーバリューストレージシステムであり、正常に動作するためには良好なネットワーク環境が必要です。そのため、ホスト上で実行されている他のプログラムから独立してetcdを配置し、etcdのパフォーマンスに影響を与えないようにしてください。
etcdの公式設定については、こちらをご覧ください。
ソフトウェア
etcdのソフトウェアはいくつかのレイヤーに分かれています。以下では、これらのレイヤーでのetcdのパフォーマンスを最適化する方法を示します。関連コードを入手するには、GitHub PRをご覧ください。
- etcd のメモリインデックス層を最適化します。具体的には、内部ロックの使用を最適化して、待ち時間を短縮します。オリジナルの実装では、内部ロックをトラバースします。B-Tree は粒度の粗い内部ロックを使用しており、これが etcd のパフォーマンスに大きく影響します。最適化されたロックは、パフォーマンスへの影響と待ち時間を減らします。
詳細については、以下のリンクを参照してください。
- リーススコープを最適化します。具体的には、リースの取り消しルーチンと期限切れチェックアルゴリズムを最適化し、期限切れリストのトラバーサルの時間的複雑さをO(n)からO(logn)に減らします。これにより、広範なリース使用の問題が解決されます。
詳細については、以下のリンクをご覧ください。
-
バックエンドのBoltDBを最適化します。具体的には、バックエンドのバッチサイズの上限と間隔を調整して、異なるハードウェアやワークロードに基づく動的な構成にします。これらのパラメーターは以前は固定の保守的な値に設定されていました。
-
完全同時読み取りを最適化しました。具体的には、読み取りのパフォーマンスを向上させるために、BoltDB Txの読み取りロックと書き込みロックの呼び出しを最適化します。この最適化はGoogleのエンジニアによって行われました。
分離されたハッシュマップに基づくフリーリストでのetd内部ストレージの割り当てと再利用の新しいアルゴリズム
Alibaba社が行ったパフォーマンス最適化を紹介します。このパフォーマンス最適化は、分離されたハッシュマップに基づいてフリーリスト内のetcd内部ストレージを割り当てて再利用するための新しいアルゴリズムによって、etcdの内部ストレージのパフォーマンスを大幅に改善します。
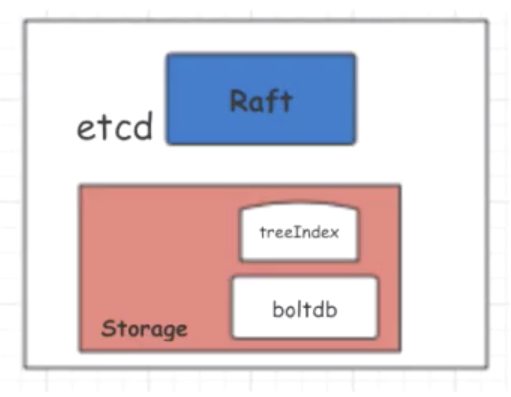
前述の図は、シングルノードのetcdアーキテクチャを示しており、そこではBoltDBがすべてのキーバリューデータを永続的に保存しています。BoltDBのパフォーマンスは、etcdの全体的なパフォーマンスに不可欠です。大量のAlibabaメタデータがetcdに格納されています。これにより、etcdのパフォーマンス問題の一部が露呈します。
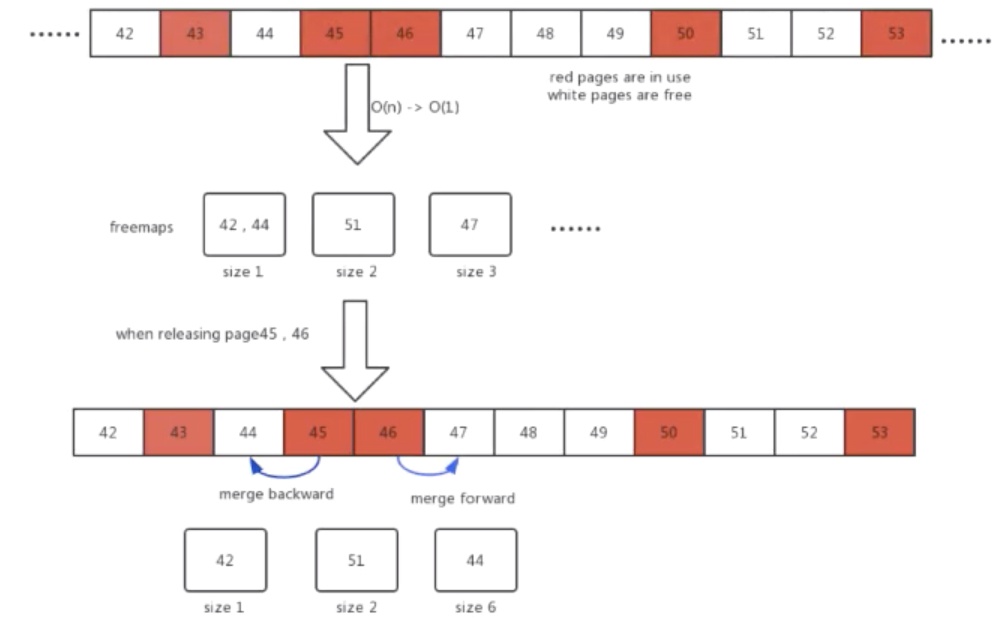
前述の図は、etcdの内部ストレージを割り当て、再利用するためのコアアルゴリズムを示しています。デフォルトでは、etcd はデータの保存に 4 KB のページを使用します。図に示すように、数字はページIDを示しています。赤色のページは使用されており、白色のページは使用されていません。
データが削除されても、etcdはすぐにはストレージスペースをシステムに戻さず、ページプールに保持します。これにより、ストレージスペースの再利用がより効率的になります。このページプールを「フリーリスト」と呼びます。図のように、フリーリストは43、45、46、50、53のページを使用中にして、さらに42、44、47、48、49、51、52の未使用のページも保持しています。
新しいデータをサイズ3の連続したページに保存する必要がある場合、古いアルゴリズムはフリーリストのヘッダーからスキャンし、開始ページID47を返します。線形フリーリスト・スキャン・アルゴリズムは、フリーリスト内に大量のデータや多くの内部フラグメントがある場合には性能が低くなります。
この問題を解決するために、分離型ハッシュマップに基づいた新しいフリーリストの割り当てと再生のアルゴリズムを設計し、実装しました。このアルゴリズムでは、連続するページサイズをハッシュマップキーとして使用し、その値は開始ページIDの構成セットとなります。新しいページにデータを格納する必要があるときは、時間計算量O(1)でハッシュマップの値を照会するだけで、開始ページIDを素早く取得することができます。
また、サイズが3の連続したページにデータを格納する必要がある場合は、ハッシュマップを照会して開始ページID 47を素早く取得することができます。
また、ハッシュマップを利用することで、ページ解放のプロセスを最適化しました。例えば、45ページと46ページがリリースされると、関連するページは前のページと次のページにマージされ、44ページから始まるサイズ6の大きな連続したページになります。
新しいアルゴリズムは、割り当ての時間的複雑さをO(n)からO(1)に、再生の時間的複雑さをO(nlogn)からO(1)に削減しました。etcdは、もはや内部ストレージの読み書き性能に制限をかけることはなく、etcdの性能は数十倍向上しています。1つのクラスターで推奨されるストレージは、2GBから100GBにスケールアップされています。この最適化は現在Alibaba社内で使用されており、オープンソースコミュニティでも利用可能です。
これらのソフトウェアの最適化は、すべて新しいetcdのバージョンで利用可能です。
4. etcdクライアントパフォーマンスの最適化
以下では、最適なetcdクライアントパフォーマンスを確保するためのベストプラクティスを紹介します。
etcd サーバーは、次の API を etcd クライアントに提供します。Put、Get、Watch、Transactions、およびLeasesです。

etcdクライアントでこれらのAPIを呼び出す際には、次のようなベストプラクティスを採用しています。
1、Put APIを呼び出す際には大きな値の使用を避け、呼び出し処理を簡素化します。例えば、KubernetesのCustomResourceDefinition(CRD)でPut APIを使用します。
2、etcdは、頻繁に変更されないkey-valueメタデータの保存に適用されます。頻繁に変更されるkey-valueデータをetcdクライアント上に作成することは避けてください。このプラクティスは、Kubernetes環境の新しいノードがハートビートデータをアップロードする際に観察されます。
3、多くのリースを作成しないようにし、可能な限りリースを再利用します。このプラクティスは、Kubernetesのイベントデータ管理で観察されます。同じTTL(time to live)を持つイベントは、リースを作成するのではなく、既存のリースで管理されます。
etcdクライアントを使用する際には、上記のベストプラクティスを守り、etcdクラスタが安定的かつ効率的に動作するようにしてください。
まとめ
今回の記事で学んだことをまとめてみましょう。
- etcdに影響を与える潜在的なパフォーマンスのボトルネック
- ハードウェア、デプロイメント、内部のコアソフトウェアアルゴリズムの観点から、etcdサーバーのパフォーマンスを最適化する方法
- etcdクライアントを使用する際のベスト・プラクティス
この記事が、皆様のetcdクラスタを安定的かつ効率的に運用するための一助となれば幸いです。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ