Alibaba CloudがGrafana Dashboardを使用してCOVID-19のアウトブレイクに関する情報を動的に表示した方法をご紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
プロジェクトの準備
目的を明確にするために、流行状況を表示するダッシュボードをカスタマイズしたい。現在上海にいるので、全国の確定症例数、疑われる症例数、回復者数、死亡者数を表示したいと同時に、症例曲線を表示して流行の発展傾向を観察し、上海の各省、各地区の状況を表示したい。
Grafanaは単にデータを表示するためのツールなので、まずはデータソースを入手する必要があります。現在のところ、利用可能な疫病データソースはGrafanaに直接統合することはできません。そのため、以下のことを行う必要があります。
-
ラップトップまたはKubernetesクラスタ上にGrafanaプログラムを準備します。Grafanaを実行するには、Dockerコンテナを使用することをお勧めします。
-
Grafana用にJSON形式のデータをデータソースに変換できるSimpleJsonプラグインをインストールします。
データソースの開発
ここではPython Bottleを使ってデータソースを開発しています。また、同等の機能を持つFlaskという選択肢もあります。Bottleを使うことにした理由は、以前のGrafanaのデータソースの開発に使っていたからです。デバッグ設定はもちろん、Dockerイメージを構築するためのDockerfileやKubernetesをデプロイするためのdeploy.yamlファイルまで用意されており、すぐに使えるようになっています。Pythonを使ってGrafanaのデータソースを開発するのは非常に簡単です。データがSimpleJsonのフォーマット要件を満たしていることを確認するだけです。Grafana用のデータソースを開発するためにPythonを使用する方法については、Oz Nahum Tiram氏のブログ記事「Visualize Almost Anything with Grafana and Python」を読んでください。
データソースのカスタマイズでは、以下の2種類のデータを使用することができます。
時系列型データ
中国、特に上海の流行傾向をリアルタイムで表示するために、確定症例数、疑われる症例数、回収数、死亡数、および以前のデータと比較したデータの変化を表示することができます。また、確定症例と疑い症例、回収数と死亡数を比較するための曲線を描くことができます。
確定症例については、全国の確定症例数 gntotal と現在のタイムスタンプを組み合わせてデータを返すだけです。他のメトリクスも同じように処理できます。
@app.post('/query')
def query():
print(request.json)
body = []
all_data = getDataSync()
time_stamp = int(round(time.time() * 1000))
for target in request.json['targets']:
name = target['target']
if name == 'gntotal':
body.append({'target': 'gntotal', 'datapoints': [[all_data['gntotal'], time_stamp]]})
body = dumps(body)
return HTTPResponse(body=body, headers={'Content-Type': 'application/json'})
テーブルタイプデータ
中国の各省の確定症例数、疑われる症例数、回収数、死亡数をマップした表と、上海の各地区の同じデータを示す別の表を使用することができます。
データから名前、確定症例、疑い症例、回収者、死亡者を抽出し、行rowsに追加appendすることができます。
@app.post('/query')
def query():
print(request.json)
body = []
all_data = getDataSync()
sh_data = getShDataSync()
if request.json['targets'][0]['type'] == 'table':
rows = []
for data in all_data['list']:
row = [data['name'], data['value'], data['susNum'], data['cureNum'], data['deathNum']]
rows.append(row)
sh_rows = []
for data in sh_data['city']:
row = [data['name'], data['conNum'], data['susNum'], data['cureNum'], data['deathNum']]
sh_rows.append(row)
bodies = {'all': [{
"columns": [
{"text": "省份", "type": "name"},
{"text": "确诊", " type": "conNum"},
{"text": "疑似", " type": "susNum"},
{"text": "治愈", "type": "cureNum"},
{"text": "死亡", "type": "deathNum"}
],
"rows": rows,
"type": "table"
}],
'sh': [{
"columns": [
{"text": "省份", "type": "name"},
{"text": "确诊", " type": "value"},
{"text": "疑似", " type": "susNum"},
{"text": "治愈", "type": "cureNum"},
{"text": "死亡", "type": "deathNum"}
],
"rows": sh_rows,
"type": "table"
}]}
series = request.json['targets'][0]['target']
body = dumps(bodies[series])
return HTTPResponse(body=body, headers={'Content-Type': 'application/json'})
パネルタイプの選択
データ表示には、一般的に4つのパネルを使用しています。
-
シングルスタットは症例番号の表示に使用されます。
-
グラフは比較曲線を表示します。
-
Table は表の表示に使用します。
-
テキストは、テキストのタイトルに使用されます。
データソースの設定
それでは、データソースの設定をしていきましょう。
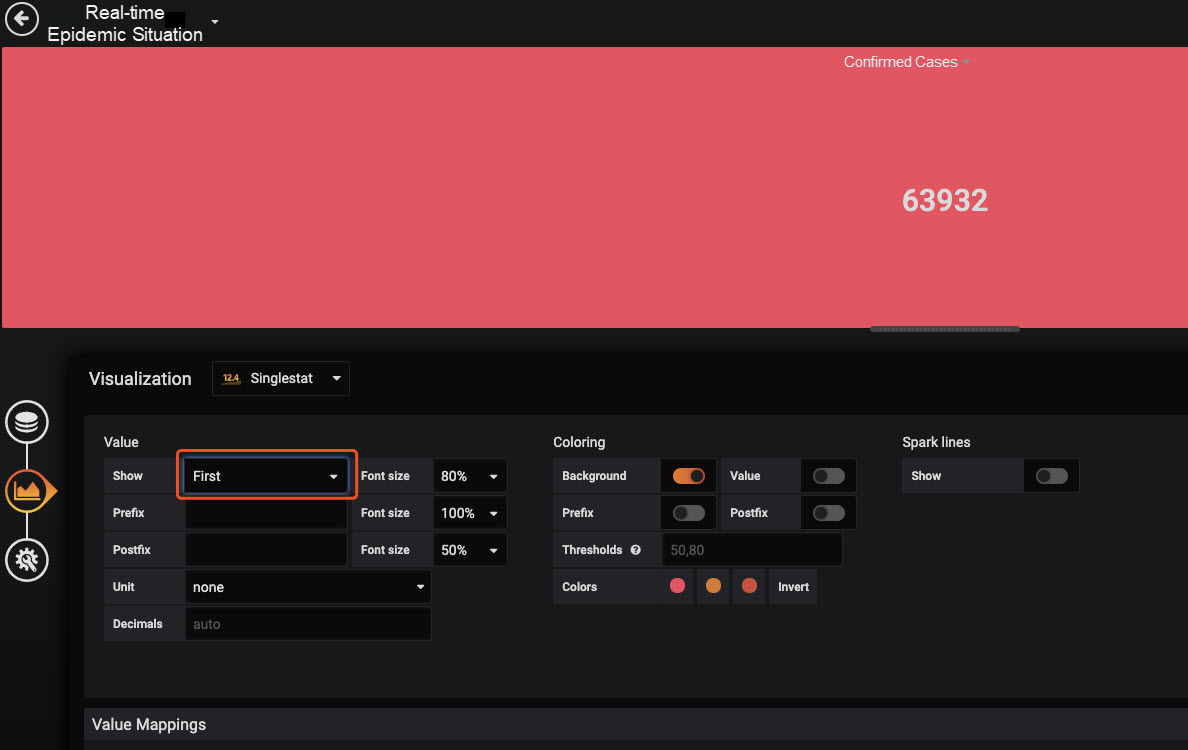
ケース番号パネル
ここでは値は1つしかないので、ファーストを選択します。
ケース数グラフ
これらのグラフは、確定症例数と疑われる症例数、回収数と死亡数を比較したものです。

データテーブル
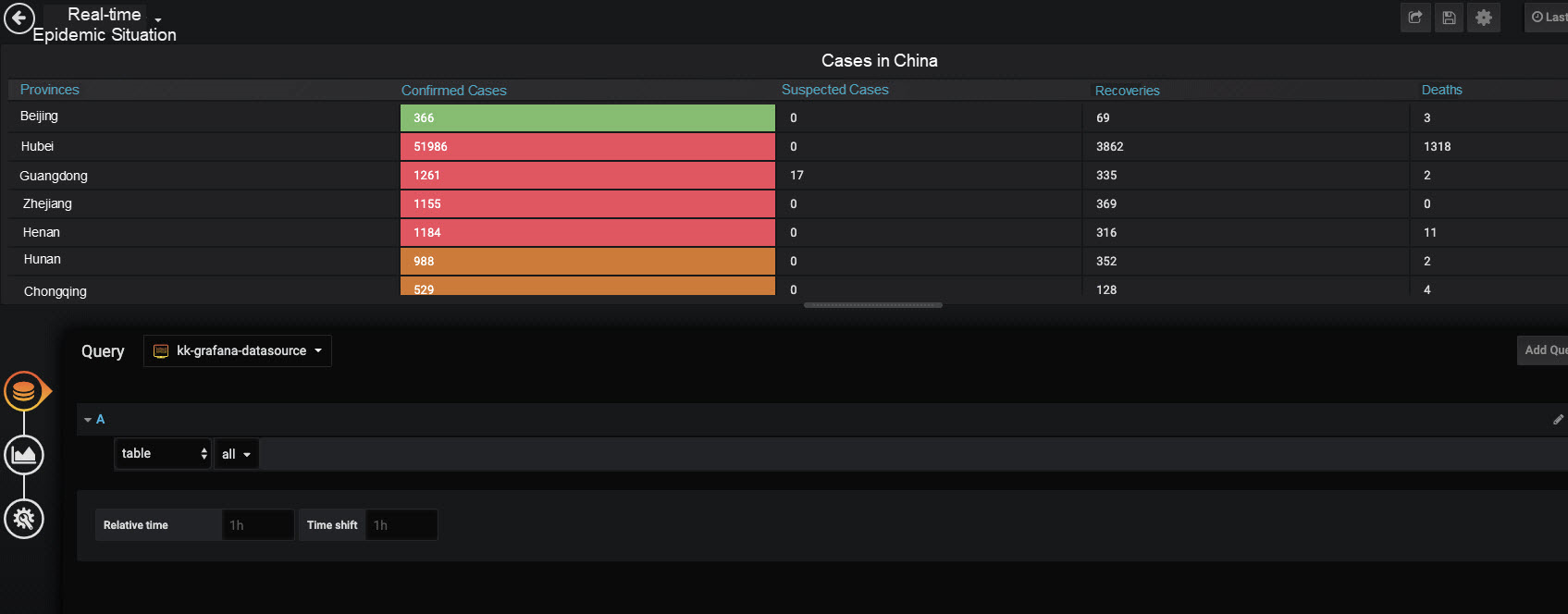
結果
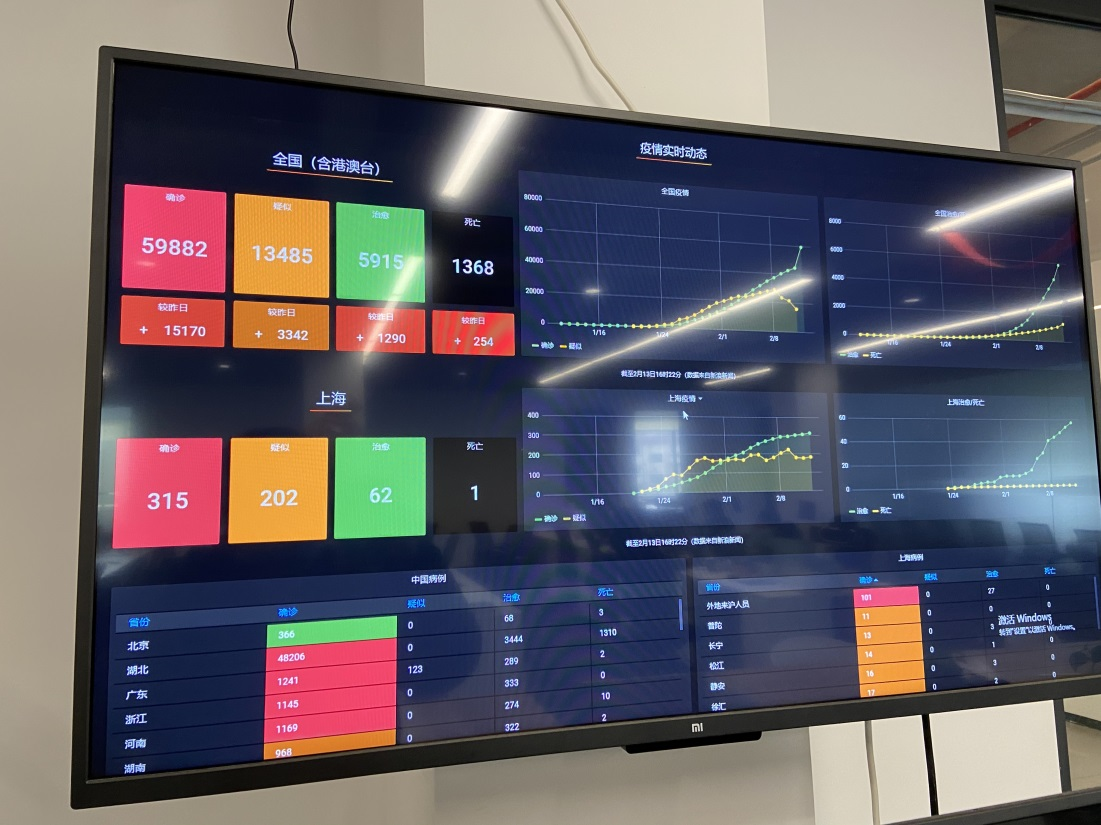
全体的な仕上がりは問題なく、同社の流行状況ダッシュボードとして使用されています。ここでは、当社では比較的画面の小さいXiaomi TVを使用しているため、フォントや表示パネルを拡大してデモ性を高めています。
ビルディング
コードをDockerイメージにパッケージ化した後は、どのような環境でも、Kubernetesクラスタでもコードを実行することができます。イメージはDocker Hubにアップロードされており、そこから引っ張ってきてすぐに使えるようになっています。
# Dockerfile
FROM python:3.7.3-alpine3.9
LABEL maintainer="sunnydog0826@gmail.com"
COPY . /app
RUN echo "https://mirrors.aliyun.com/alpine/v3.9/main/" > /etc/apk/repositories \
&& apk update \
&& apk add --no-cache gcc g++ python3-dev python-dev linux-headers libffi-dev openssl-dev make \
&& pip3 install -r /app/requestments.txt -i http://mirrors.aliyun.com/pypi/simple --trusted-host mirrors.aliyun.com
WORKDIR /app
ENTRYPOINT ["uwsgi","--ini","uwsgi.ini"]
ランニング・イット
- 画像を引っ張る。
docker pull guoxudongdocker/feiyan-datasource
- 画像を実行します。
docker run -d --name datasource -p 8088:3000 guoxudongdocker/feiyan-datasource
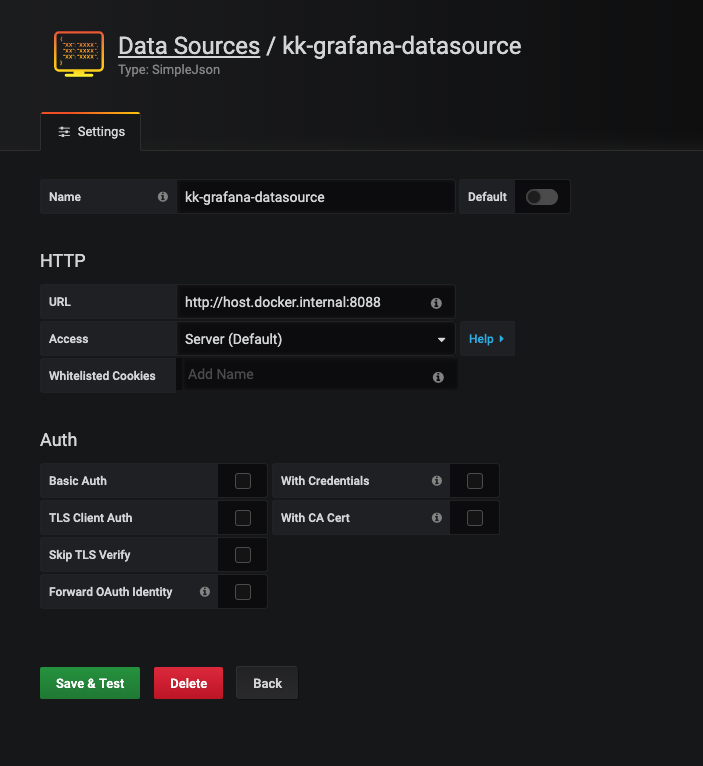
- データソースを追加します。
SimpleJson データソースを選択し、[追加] をクリックして、データソースのアドレスを入力します。
-
ダッシュボードをインポートする
Upload.jsonファイルをクリックし、wuhan2020-grafana/dashboard.jsonを選択します。
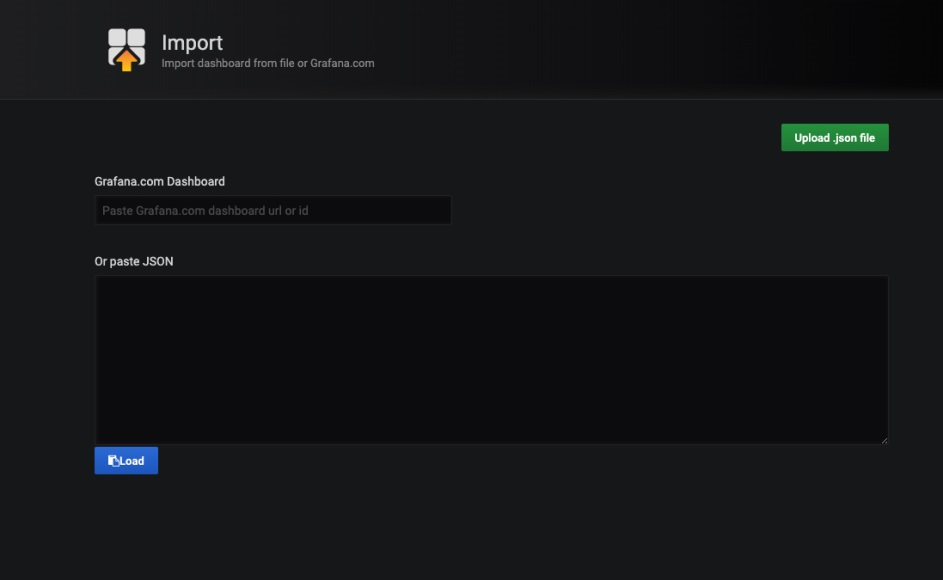
-
(オプション) デプロイにKubernetesを使用します。
kubectl apply -f deploy.yaml
概要
これを書いている2月中旬の時点では、中国の確定症例数はまだ急速に増加していますが、幸いなことに疑われる症例数の伸び率は低下し始めています。確定症例数の増加率は着実に増加しており、回収数も増加していることがわかる。上海は他の地域に比べて、多くの人が職場復帰しているにもかかわらず、症例数が大きく増えていません。その一環として、住宅街の厳しい取締りが効果を発揮し始めている。現在、上海では、中国初の回復を記録したのと同様に、死亡者はまだ1名のみである。一般的には、私たちが予防に注意を払い、家にいる限り、流行を克服し、この困難な時期を乗り越えることは間違いありません。
ダッシュボードをインポートするためのJSONファイルと、KubernetesをデプロイするためのYMALファイルはGitHubにあります。プロジェクトのアドレスはこちらです。https://github.com/sunny0826/wuhan2020-grafana
世界中で発生しているコロナウイルスとの戦いを継続する一方で、アリババクラウドはその役割を果たし、コロナウイルスとの戦いで他の人たちを助けるためにできる限りのことをしていきたいと考えています。お客様の事業継続をサポートする方法については、https://www.alibabacloud.com/campaign/fight-coronavirus-covid-19でご確認ください。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ