この記事では、Alibaba Cloud上のDockerコンテナ内で単一ノードのHadoopクラスタを起動するためのDockerの設定方法を紹介します。
本ブログは英語版からの翻訳です。オリジナルはこちらからご確認いただけます。一部機械翻訳を使用しております。翻訳の間違いがありましたら、ご指摘いただけると幸いです。
背景
このチュートリアルの本編に入る前に、このブログで取り上げている主要な製品をいくつか見てみましょう。
まず、Dockerがありますが、これは非常に人気のあるコンテナ化ツールで、ソフトウェアやインストールされている他の依存関係がアプリケーションを実行するコンテナを作成することができます。仮想マシンの話は聞いたことがあるかもしれません。まあ、Dockerコンテナは基本的には仮想マシンの軽量版です。アプリケーションを実行するためのDockerコンテナの作成は非常に簡単で、その場で起動することができます。
次にApache Hadoopですが、これはビッグデータを保存して処理するためのコアとなるビッグデータフレームワークです。HadoopのストレージコンポーネントはHadoop Distributed File system(通常はHDFSと略される)と呼ばれ、Hadoopの処理コンポーネントはMapReduceと呼ばれています。次に、Hadoopクラスタ内で動作するデーモンはいくつかあり、NameNode、DataNode、Secondary Namenode、ResourceManager、NodeManagerなどがあります。
メインチュートリアル
DockerとHadoopがどのようなものか少し分かったところで、Dockerを使って単一ノードのHadoopクラスタを設定する方法を見てみましょう。
まず、このチュートリアルでは、Ubuntu 18.04をインストールしたAlibaba Cloud ECSインスタンスを使用します。次に、このチュートリアルの一環として、このubuntuシステムにDockerがインストールされていると仮定してみましょう。以下、このセットアップの詳細です。


このチュートリアルの前段階として、すべてが正常に稼働していることを確認しておきましょう。まず、インスタンスシステムにdockerがインストールされていることを確認するために、以下のコマンドを実行してマシンにインストールされているdockerのバージョンを確認します。
root@alibaba-docker:~# docker -v
Docker version 18.09.6, build 481bc77
次に、dockerが正常に動作していることを確認するために、簡単なhello worldコンテナを起動します。
root@alibaba-docker:~# docker container run hello-world
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
1b930d010525: Pull complete
Digest: sha256:41a65640635299bab090f783209c1e3a3f11934cf7756b09cb2f1e02147c6ed8
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
このメッセージは、インストールが正しく動作しているように見えることを示しています。
このメッセージを生成するために、Dockerはバックグラウンドで以下の操作を完了しています。
1、DockerクライアントがDockerデーモンに連絡しました。
2、DockerデーモンがDocker Hub(amd64)から「hello-world」イメージを引っ張ってきました。
3、Dockerデーモンはそのイメージから新しいコンテナを作成しました。
4、Dockerデーモンはその出力をDockerクライアントにストリーム配信し、その出力をターミナルに送信します。
もっと野心的なことを試すには、以下のコマンドでUbuntuがインストールされたコンテナを実行することもできます。
$ docker run -it ubuntu bash
次に、Dockerの公式サイトにある無料のDocker IDを使って、イメージの共有やワークフローの自動化などを行うことができます。また、より多くの例やアイデアについては、DockerのGet Startedガイドをチェックしてください。
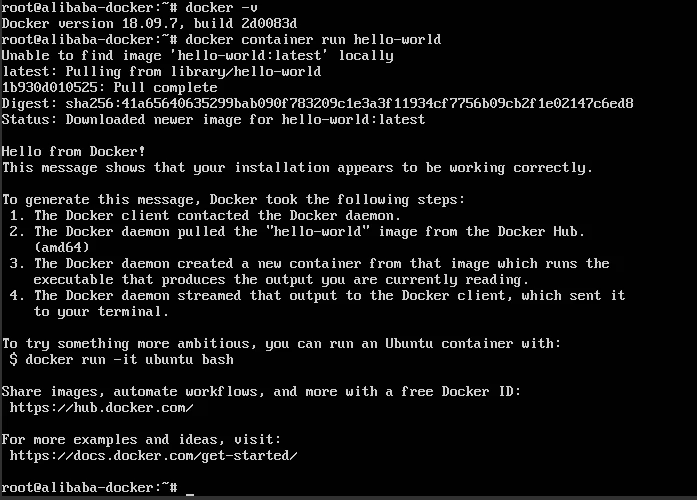
上記のような出力が得られている場合は、インスタンス上でdockerが正常に動作しているので、dockerコンテナ内にHadoopをセットアップすることができます。そのためには、pullコマンドを実行してHadoop上のdockerイメージを取得します。具体的には、Docker Imageというのは、コンテナをデプロイする際に使用する複数のレイヤーを持つファイルです。
root@alibaba-docker:~# docker pull sequenceiq/hadoop-docker:2.7.0
2.7.0: Pulling from sequenceiq/hadoop-docker
b253335dcf03: Pulling fs layer
a3ed95caeb02: Pulling fs layer
69623ef05416: Pulling fs layer
63aebddf4bce: Pulling fs layer
46305a4cda1d: Pulling fs layer
70ff65ec2366: Pulling fs layer
72accdc282f3: Pulling fs layer
5298ddb3b339: Pulling fs layer
ec461d25c2ea: Pulling fs layer
315b476b23a4: Pulling fs layer
6e6acc31f8b1: Pulling fs layer
38a227158d97: Pulling fs layer
319a3b8afa25: Pulling fs layer
11e1e16af8f3: Pulling fs layer
834533551a37: Pulling fs layer
c24255b6d9f4: Pulling fs layer
8b4ea3c67dc2: Pulling fs layer
40ba2c2cdf73: Pulling fs layer
5424a04bc240: Pulling fs layer
7df43f09096d: Pulling fs layer
b34787ee2fde: Pulling fs layer
4eaa47927d15: Pulling fs layer
cb95b9da9646: Pulling fs layer
e495e287a108: Pulling fs layer
3158ca49a54c: Pulling fs layer
33b5a5de9544: Pulling fs layer
d6f46cf55f0f: Pulling fs layer
40c19fb76cfd: Pull complete
018a1f3d7249: Pull complete
40f52c973507: Pull complete
49dca4de47eb: Pull complete
d26082bd2aa9: Pull complete
c4f97d87af86: Pull complete
fb839f93fc0f: Pull complete
43661864505e: Pull complete
d8908a83648e: Pull complete
af8b686deb23: Pull complete
c1214abd7b96: Pull complete
9d00f27ba8d2: Pull complete
09f787a7573b: Pull complete
4e86267d5247: Pull complete
3876cba35aed: Pull complete
23df48ffdb39: Pull complete
646aedbc2bb6: Pull complete
60a65f8179cf: Pull complete
046b321f8081: Pull complete
Digest: sha256:a40761746eca036fee6aafdf9fdbd6878ac3dd9a7cd83c0f3f5d8a0e6350c76a
Status: Downloaded newer image for sequenceiq/hadoop-docker:2.7.0
次に、以下のコマンドを実行して、システム上に存在するドッカーイメージのリストを確認します。
root@alibaba-docker:~#:~$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest fce289e99eb9 5 months ago 1.84kB
sequenceiq/hadoop-docker 2.7.0 789fa0a3b911 4 years ago 1.76GB
それが終わったら、Dockerコンテナの中でHadoopのdockerイメージを実行します。
root@alibaba-docker:~# docker run -it sequenceiq/hadoop-docker:2.7.0 /etc/bootstrap.sh -bash
/
Starting sshd: [ OK ]
Starting namenodes on [9f397feb3a46]
9f397feb3a46: starting namenode, logging to /usr/local/hadoop/logs/hadoop-root-namenode-9f397feb3a46.out
localhost: starting datanode, logging to /usr/local/hadoop/logs/hadoop-root-datanode-9f397feb3a46.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/local/hadoop/logs/hadoop-root-secondarynamenode-9f397feb3a46.out
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/logs/yarn--resourcemanager-9f397feb3a46.out
localhost: starting nodemanager, logging to /usr/local/hadoop/logs/yarn-root-nodemanager-9f397feb3a46.out
bash-4.1#
上記の出力では、コンテナがすべての Hadoop デーモンを一つずつ起動していることがわかります。すべてのデーモンが起動していることを確認するために、jpsコマンドを実行します。
bash-4.1# jps
942 Jps
546 ResourceManager
216 DataNode
371 SecondaryNameNode
126 NameNode
639 NodeManager
bash-4.1#
jpsコマンドを実行して上記のような出力が出れば、全てのhadoopデーモンが正常に動作していることが確認できます。その後、以下のようにdockerコマンドを実行して、dockerコンテナの詳細を取得します。
root@alibaba-docker:~# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9f397feb3a46 sequenceiq/hadoop-docker:2.7.0 "/etc/bootstrap.sh -…" 5 minutes ago Up 5 minutes 2122/tcp, 8030-8033/tcp, 8040/tcp, 8042/tcp, 8088/tcp, 19888/tcp, 49707/tcp, 50010/tcp, 50020/tcp, 50070/tcp, 50075/tcp, 50090/tcp determined_ritchie
以下のコマンドを実行して、コンテナが動作しているIPアドレスを取得します。
bash-4.1# ifconfig
eth0 Link encap:Ethernet HWaddr 02:42:AC:11:00:02
inet addr:172.17.0.2 Bcast:172.17.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:93 errors:0 dropped:0 overruns:0 frame:0
TX packets:21 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:9760 (9.5 KiB) TX bytes:1528 (1.4 KiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:65536 Metric:1
RX packets:3160 errors:0 dropped:0 overruns:0 frame:0
TX packets:3160 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:455659 (444.9 KiB) TX bytes:455659 (444.9 KiB)
上記の出力から、dockerコンテナが172.17.0.2で動作していることがわかります。これに続いて、HadoopクラスタのWebインタフェースは、ポート50070でアクセスすることができます。だから、あなたのブラウザ、具体的にはMozilla Firefoxブラウザをubuntuマシンで開き、172.17.0.2:50070に移動することができます。Hadoop Overview Interfaceが開きます。下の出力から、Hadoopがデフォルトのポートである9000番ポートで実行されていることがわかります。
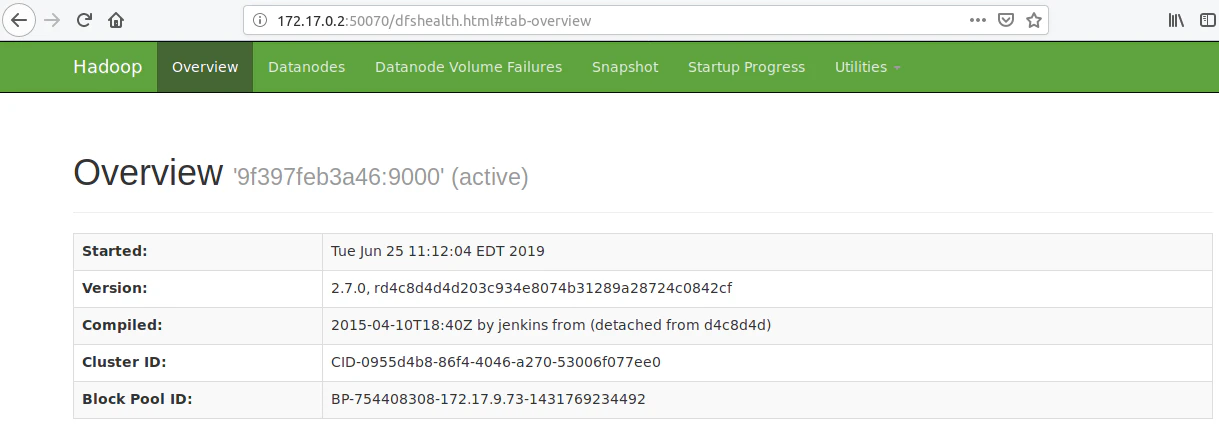
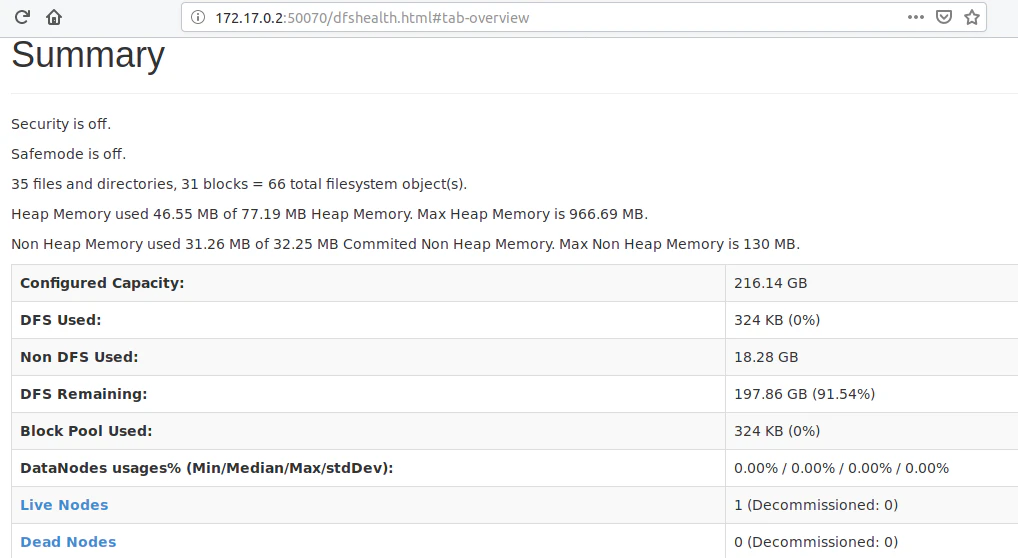
ここで "Summary "までスクロールすると、dockerコンテナ内で稼働しているHadoopクラスタの詳細が表示されます。Live Node 1は、1つのデータノードが稼働していることを意味します(単一ノード)。
Hadoop分散ファイルシステム(HDFS)にアクセスするには、「ユーティリティ」→「ファイルシステムを参照」と進みます。デフォルトではHDFSに存在するユーザーディレクトリを見つけることができます。

これでdockerコンテナの中に入りました。コンテナの中には、ubuntuのデフォルトのターミナルシェルではなく、bashシェルが入っています。dockerコンテナ内のHadoopクラスタ上でwordcount mapreduceプログラムを実行してみましょう。このプログラムは、テキストを含む入力を取り、キーと値のペアとして出力を与えます。まず最初に行うことは、Hadoopのホームディレクトリに移動することです。
bash-4.1# cd $HADOOP_PREFIX
次に、wordcountプログラムがプリインストールされているhadoop-mapreduce-examples-2.7.0.jarファイルを実行します。すると以下のように出力されます。
bash-4.1# bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.0.jar grep input output 'dfs[a-z.]+'
19/06/25 11:28:55 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
19/06/25 11:28:58 INFO input.FileInputFormat: Total input paths to process : 31
19/06/25 11:28:59 INFO mapreduce.JobSubmitter: number of splits:31
19/06/25 11:28:59 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1561475564487_0001
19/06/25 11:29:00 INFO impl.YarnClientImpl: Submitted application application_1561475564487_0001
19/06/25 11:29:01 INFO mapreduce.Job: The url to track the job: http://9f397feb3a46:8088/proxy/application_1561475564487_0001/
19/06/25 11:29:01 INFO mapreduce.Job: Running job: job_1561475564487_0001
19/06/25 11:29:22 INFO mapreduce.Job: Job job_1561475564487_0001 running in uber mode : false
19/06/25 11:29:22 INFO mapreduce.Job: map 0% reduce 0%
19/06/25 11:30:22 INFO mapreduce.Job: map 13% reduce 0%
19/06/25 11:30:23 INFO mapreduce.Job: map 19% reduce 0%
19/06/25 11:31:19 INFO mapreduce.Job: map 23% reduce 0%
19/06/25 11:31:20 INFO mapreduce.Job: map 26% reduce 0%
19/06/25 11:31:21 INFO mapreduce.Job: map 39% reduce 0%
19/06/25 11:32:11 INFO mapreduce.Job: map 39% reduce 13%
19/06/25 11:32:13 INFO mapreduce.Job: map 42% reduce 13%
19/06/25 11:32:14 INFO mapreduce.Job: map 55% reduce 15%
19/06/25 11:32:18 INFO mapreduce.Job: map 55% reduce 18%
19/06/25 11:32:59 INFO mapreduce.Job: map 58% reduce 18%
19/06/25 11:33:00 INFO mapreduce.Job: map 61% reduce 18%
19/06/25 11:33:02 INFO mapreduce.Job: map 71% reduce 19%
19/06/25 11:33:05 INFO mapreduce.Job: map 71% reduce 24%
19/06/25 11:33:45 INFO mapreduce.Job: map 74% reduce 24%
19/06/25 11:33:46 INFO mapreduce.Job: map 81% reduce 24%
19/06/25 11:33:47 INFO mapreduce.Job: map 84% reduce 26%
19/06/25 11:33:48 INFO mapreduce.Job: map 87% reduce 26%
19/06/25 11:33:50 INFO mapreduce.Job: map 87% reduce 29%
19/06/25 11:34:28 INFO mapreduce.Job: map 90% reduce 29%
19/06/25 11:34:29 INFO mapreduce.Job: map 97% reduce 29%
19/06/25 11:34:30 INFO mapreduce.Job: map 100% reduce 32%
19/06/25 11:34:32 INFO mapreduce.Job: map 100% reduce 100%
19/06/25 11:34:32 INFO mapreduce.Job: Job job_1561475564487_0001 completed successfully
19/06/25 11:34:32 INFO mapreduce.Job: Counters: 50
File System Counters
FILE: Number of bytes read=345
FILE: Number of bytes written=3697508
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=80529
HDFS: Number of bytes written=437
HDFS: Number of read operations=96
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Killed map tasks=1
Launched map tasks=32
Launched reduce tasks=1
Data-local map tasks=32
Total time spent by all maps in occupied slots (ms)=1580786
Total time spent by all reduces in occupied slots (ms)=191081
Total time spent by all map tasks (ms)=1580786
Total time spent by all reduce tasks (ms)=191081
Total vcore-seconds taken by all map tasks=1580786
Total vcore-seconds taken by all reduce tasks=191081
Total megabyte-seconds taken by all map tasks=1618724864
Total megabyte-seconds taken by all reduce tasks=195666944
Map-Reduce Framework
Map input records=2060
Map output records=24
Map output bytes=590
Map output materialized bytes=525
Input split bytes=3812
Combine input records=24
Combine output records=13
Reduce input groups=11
Reduce shuffle bytes=525
Reduce input records=13
Reduce output records=11
Spilled Records=26
Shuffled Maps =31
Failed Shuffles=0
Merged Map outputs=31
GC time elapsed (ms)=32401
CPU time spent (ms)=19550
Physical memory (bytes) snapshot=7076614144
Virtual memory (bytes) snapshot=22172876800
Total committed heap usage (bytes)=5196480512
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=76717
File Output Format Counters
Bytes Written=437
19/06/25 11:34:32 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
19/06/25 11:34:33 INFO input.FileInputFormat: Total input paths to process : 1
19/06/25 11:34:33 INFO mapreduce.JobSubmitter: number of splits:1
19/06/25 11:34:33 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1561475564487_0002
19/06/25 11:34:33 INFO impl.YarnClientImpl: Submitted application application_1561475564487_0002
19/06/25 11:34:33 INFO mapreduce.Job: The url to track the job: http://9f397feb3a46:8088/proxy/application_1561475564487_0002/
19/06/25 11:34:33 INFO mapreduce.Job: Running job: job_1561475564487_0002
19/06/25 11:34:50 INFO mapreduce.Job: Job job_1561475564487_0002 running in uber mode : false
19/06/25 11:34:50 INFO mapreduce.Job: map 0% reduce 0%
19/06/25 11:35:04 INFO mapreduce.Job: map 100% reduce 0%
19/06/25 11:35:18 INFO mapreduce.Job: map 100% reduce 100%
19/06/25 11:35:19 INFO mapreduce.Job: Job job_1561475564487_0002 completed successfully
19/06/25 11:35:19 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=291
FILE: Number of bytes written=230543
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=570
HDFS: Number of bytes written=197
HDFS: Number of read operations=7
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=10489
Total time spent by all reduces in occupied slots (ms)=12436
Total time spent by all map tasks (ms)=10489
Total time spent by all reduce tasks (ms)=12436
Total vcore-seconds taken by all map tasks=10489
Total vcore-seconds taken by all reduce tasks=12436
Total megabyte-seconds taken by all map tasks=10740736
Total megabyte-seconds taken by all reduce tasks=12734464
Map-Reduce Framework
Map input records=11
Map output records=11
Map output bytes=263
Map output materialized bytes=291
Input split bytes=133
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=291
Reduce input records=11
Reduce output records=11
Spilled Records=22
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=297
CPU time spent (ms)=1610
Physical memory (bytes) snapshot=346603520
Virtual memory (bytes) snapshot=1391702016
Total committed heap usage (bytes)=245891072
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=437
File Output Format Counters
Bytes Written=197
mapreduceプログラムの実行が終了したら、以下のコマンドを実行して出力を確認します。
bash-4.1# bin/hdfs dfs -cat output/*
6 dfs.audit.logger
4 dfs.class
3 dfs.server.namenode.
2 dfs.period
2 dfs.audit.log.maxfilesize
2 dfs.audit.log.maxbackupindex
1 dfsmetrics.log
1 dfsadmin
1 dfs.servers
1 dfs.replication
1 dfs.file
bash-4.1#
これで、Dockerを使った単一ノードのHadoopクラスタのセットアップに成功しました。DockerとHadoopについては、Alibaba Cloudの他の記事を参考にしてみてください。
アリババクラウドは日本に2つのデータセンターを有し、世界で60を超えるアベラビリティーゾーンを有するアジア太平洋地域No.1(2019ガートナー)のクラウドインフラ事業者です。
アリババクラウドの詳細は、こちらからご覧ください。
アリババクラウドジャパン公式ページ