動機
素晴らしいアニメ作品に出会ったとき、「もっとこういう作品を見たい!」 と思いますよね。
そういうとき私はよく監督や脚本の人が過去に手がけた作品を漁ったりします。
しかしながら、アニメ作品というのは一人の人間が作っているものではありません。小説や漫画と違い、ひとつのアニメ作品にも非常に多数のスタッフが関わっています。同じ監督が手がけたアニメだからといって、必ずしも同じような作風になるとは限りません。逆に、監督が違っていても、他に共通するスタッフがいることで似たような作風になったりすることもあります。
監督や脚本など一人だけを追うのは簡単ですが、もっとざっくりと制作スタッフが共通している作品を見つけることはできないでしょうか?
結果その1:検索システム
できました。

↓こちらのページから検索できます。
スタッフが共通するアニメを検索するページ
結果その2:クラスタリング
上述の検索システムに使ったデータを元に、アニメ作品のクラスタリングを行ってみました。
結果、ほぼ制作会社ごとのクラスタに分かれるという、よくよく考えたら至極当然の結果が出ました。
(勘の良い方は、上のスクショ内に写っているタイトルが全てボンズ作品であることに気付いたはず)
↓こちらのページから結果を閲覧できます。
クラスタリング結果を表示するページ
※ノード(オレンジ色の丸)やエッジ(灰色の棒)にカーソルを合わせると詳細が表示されます。
以下、幾つかのクラスターを例に見ていきましょう。
クラスター例その1
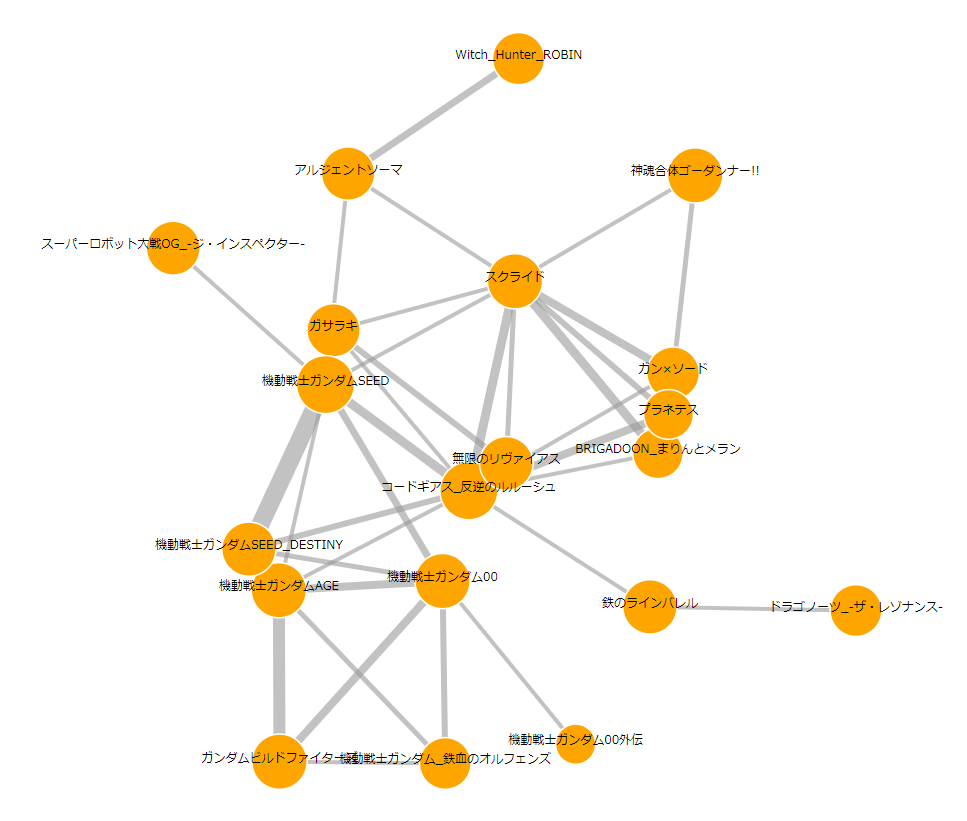
どう見てもサンライズですね。
ちなみにサンライズ作品の中では、「スクライド」が私のイチオシです。
好きなキャラはストレイト・クーガーです。
クラスター例その2
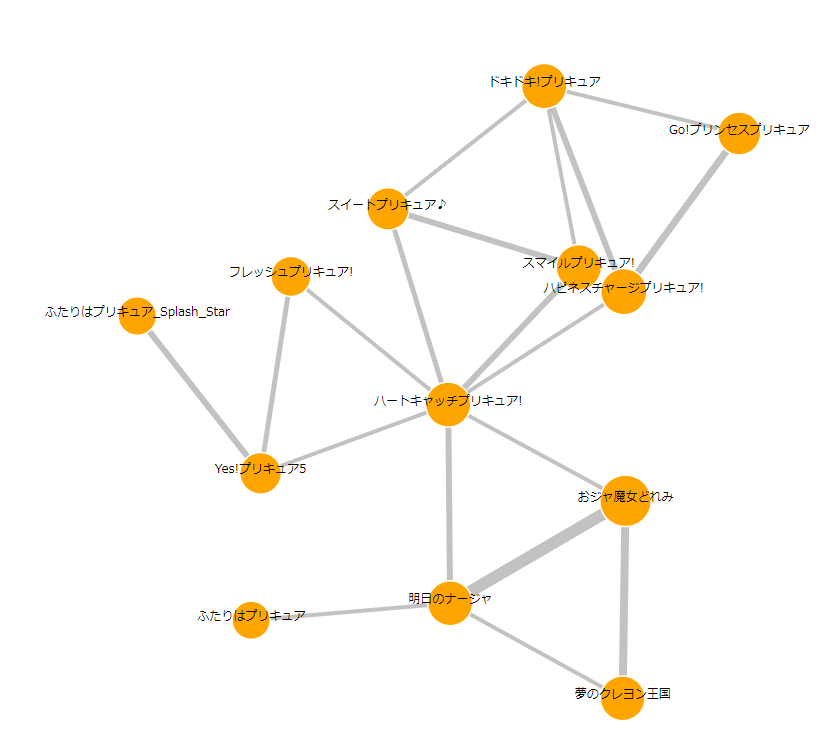
どう見ても東映ニチアサ枠ですね。
ちなみにニチアサ枠の中では、「ハートキャッチプリキュア」が私のイチオシです。
好きなキャラはキュアサンシャインです。
クラスター例その3
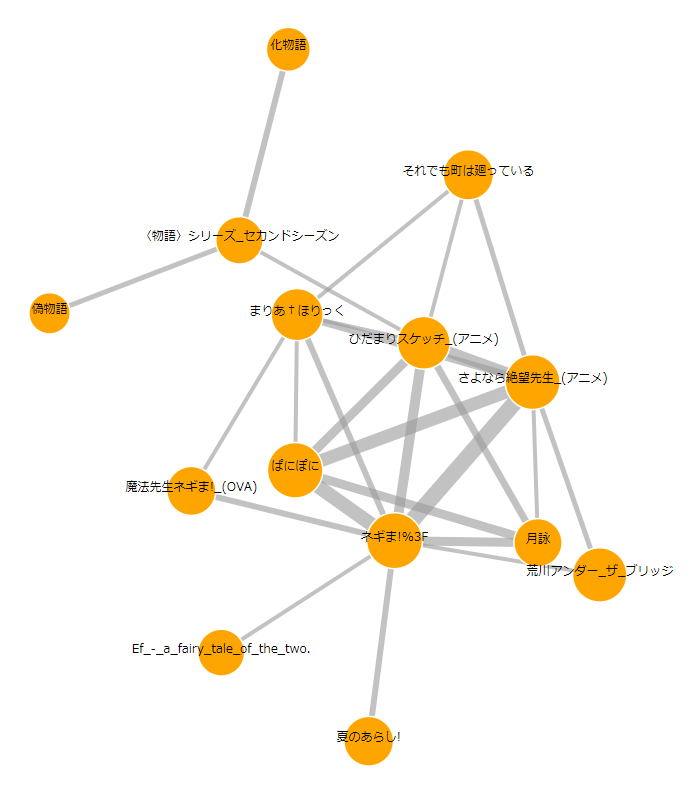
どう見てもシャフトですね。
ちなみにシャフト作品の中では、「さよなら絶望先生」が私のイチオシです。
好きなキャラは日塔奈美です。
クラスター例その4
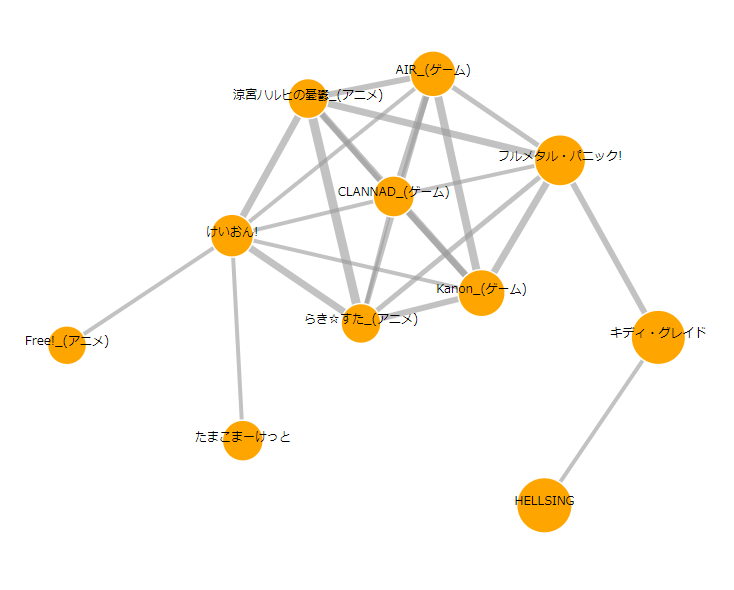
どう見ても京アニ……と言いたいところですが、右下にちょっとGONZOが混じってますね。
これはフルメタル・パニックのアニメ制作会社が1期:ゴンゾ→2期・3期:京アニと変遷したためだと思われます。(さらに4期はXEBECになっている。なにか大人の事情があるのだろうか?)
ちなみに京アニ作品の中では、「響け!ユーフォニアム」が私のイチオシです。
(……が、上の図には含まれていない……理由は後述)
好きなキャラは鎧塚みぞれです。
結論
好きなアニメの制作会社を知っておけばイナフ。
手法
以下は手法に興味がある人向けのざっくりとした解説です。データ収集、データ処理、可視化の三段階に分けて解説します。それぞれの段階で使った言語が異なります(Python, R, JavaScript)。
ちなみにPythonもJavaScriptもGitHubもQiitaも初めて触ったIT素人のアニメオタクなので、解説が下手だったり間違ってたりしても怒らないでくださいね……そのときは優しくコメント欄でアドバイスしてね……。
1. データ収集(Python - SPARQLWrapper)
今回使ったデータベースはDBpedia Japanese、つまりWikipediaの日本語版記事です。
(尚DBpedia Japaneseの更新は2016-04-07で止まっています。頼むから更新して。)
SPARQLというRDFクエリ言語が必要です。PythonではSPARQLWrapperというモジュールを介して使えます。
まず予め、全アニメ作品のリスト(anime_list)を作っておきます(ここでいう「全」とは、あくまでもWikipediaに記事が存在するという意味での「全」です)。
select distinct ?s where {?s a dbpedia-owl:Anime.}
注意点ですが、なぜかこのままだと一部のアニメは変な名前で入っちゃってます。例えば大本の記事名が艦隊これくしょん_-艦これ-である場合、艦隊これくしょん_-艦これ-__艦隊これくしょん_-艦これ-__1で入ります(Wikipediaの仕様なのかDBpediaの仕様なのかよくわからない……)。なので、シェル上でsed s@.*__@@などして余計な部分を取り除きましょう。そうすると一部重複も出てきちゃうので、uniqも忘れずに。
また、一部のアニメ映画(「秒速5センチメートル」や「となりのトトロ」など)は"Anime"ではなく"Film"扱いになっているため、今回は対象外です。つまりTVアニメだけを対象にした解析になっています。ただし、なぜかナウシカなどは"Film"ではなく"Anime"になっているため、今回の解析に含まれています。Wikipedia、統一感がない……。
同様に、全アニメ制作スタッフのリスト(animator_list)を作っておきます。
select distinct ?o where {<http://ja.dbpedia.org/resource/アニメ関係者一覧> <http://dbpedia.org/ontology/wikiPageWikiLink> ?o .}
このままだとanimator_listには外人声優や「漫画」「アニメ」などのキーワードが混ざっているので、適当に集合演算で取り除きましょう。
次に、「あるアニメにあるスタッフが関わっている」=「Wikipediaで記事がリンクされている」と考え、このアニメ-スタッフの関係性を網羅的に取得します。Wikipediaの記事は相互リンクしていない場合が多いため、どちらか一方でもリンクしていたら、「関係がある」としています。
例えば各アニメ作品に対して、そこからリンクしているスタッフのリストを取得する場合は、こんな感じです。
anime_to_animator_list = []
for anime in anime_list:
sparql.setQuery(r'''
select distinct * where { <http://ja.dbpedia.org/resource/''' + anime + r'''> <http://dbpedia.org/ontology/wikiPageWikiLink> ?o . }
''')
temp = []
response = sparql.query().convert()
for result in response["results"]["bindings"]:
temp.append(re.sub('.*/resource/',"",result["o"]["value"]))
intersect=list(set(animator_list)&set(temp))
anime_to_animator_list.append(intersect)
これを逆(各スタッフに対して、そこからリンクしているアニメ作品のリストを取得)についてもやっておいて、二つのデータを統合し、アニメ-スタッフの関係性をファイル出力しておきます。
2. データ処理(R - igraph)
ここからのデータ処理はRを使います。グラフ関係のライブラリはPythonよりRの方が充実しているので。
まず、Pythonで出力したファイルを読みこんで、アニメ-スタッフの関係性から、アニメ-アニメの関係性を作っていきます。つまり、二つのアニメの中で共通するスタッフを、全組み合わせに対して列挙していきます。アニメが3500作品ほどあるので、約600万の組み合わせについて計算しなければなりません。今回は隣接行列の上三角を求めるにあたって、行方向のみをdoParallelのforeachで並列化したところ、4コアで5時間くらいかかりました。
for (i in 1:(imax-1)){
animators_i<-as.character(edges[edges[,1]==anime_list[i],2])
temp<-foreach(j=(i+1):imax,.combine='rbind') %dopar%{ #ここのdoparが並列化しているところ
animators_j<-as.character(edges[edges[,1]==anime_list[j],2])
common_animators<-intersect(animators_i,animators_j)
if(length(common_animators)>0){
list(as.character(anime_list[i]),as.character(anime_list[j]),length(common_animators),paste(common_animators,collapse = "\n"))
}
}
a2a<-rbind(a2a,temp)
print(i) #現在の計算がどの行まで進んでいるかの確認
}
これをデータフレームにして、CSVファイルで出力したら70MBくらいになります。上で紹介した検索システムは、このCSVファイルをGitHubにアップロードして使っています(100MB以上のものはアップロードできないので、結構ギリギリでした)。
さて、次にグラフ化(ネットワーク化)です。igraphのgraph.data.frameを使います。
ただし、すべてのデータを使うと平均次数500という密なグラフになってしまうので、重みが**上位0.1%**のエッジ(共通スタッフの人数が11人以上の関係性)以外を剪定し、平均次数4.2の疎なグラフにしました。この時点でかなりのアニメ作品が落とされてしまいますが(3495作品→580作品)、このぐらいしないと人間の目にはゴチャゴチャしすぎてよくわからないグラフになってしまうし、クラスタリング結果も芳しくないです。上でお見せした京アニクラスタに「響け!ユーフォニアム」が含まれていない理由はこの剪定のためです(元データ自体には含まれているので、検索すると出てきます。重みの最大値が9なので、確かに剪定の対象に入っていることがわかります)。
グラフの作成が終わったら、クラスタリングです。大きく分けて二段階あります。
まず、clustersあるいはdecompose.graphを使って、連結成分を分離します。今回はこれで18個の連結成分に分かれました。1番目の連結成分のサイズ(ノード数)が535で、他はサイズが一桁と小さいので、最大連結成分(1番目の大きなクラスタ)に対して更にコミュニティ検出(グラフ・クラスタリング)を行いました。今回はspinglass.communityを使いました。Pottsモデルをシミュレーテッド・アニーリングで解く統計力学的な手法です。この手法は他の手法より時間はかかるが、尤もらしい結果が出るという専らの評判です。しかしなぜか非連結なクラスタを返すことがあったので、今回1クラスタ1連結成分になるまでwhileループしました。結果、さらに最大連結成分が24個のクラスタに分かれました。これで都合、18 + 24 - 1 = 41個のクラスタが得られました。上でお見せしたクラスタリング結果のページでは、1~24番目が最大連結成分内のクラスタ、25~41番目が他の連結成分になっています。
こうして作った各クラスタのグラフはplotやtkplotで可視化できますが、今回はJavaScriptのd3.jsでの可視化に向けて、jsonファイルで出力しておきます。グラフのjsonファイルの出力は、networkD3のigraph_to_networkD3とjsonliteのwrite_jsonを組み合わせれば簡単にできます。ただしigraph_to_networkD3後はエッジの重みなどの情報は落ちてしまうので、適宜自分で付け加えましょう。
ひとつ大事なことを補足しておきますが、日本語の文字列を扱う以上、エンコードのトラブルがよく起きます。何はともあれ
options(encoding="UTF-8")
と
iconv("なんか日本語の文字列",from="Shift-JIS",to="UTF-8")
を覚えておくと便利です。
3. 可視化(JavaScript - d3.js)
グラフはd3.jsのforceを使って可視化できます。
なぜforceを使うのか? それは意味もなくガチャガチャ動いてカッコいいからだ!
forceのサンプルコードはあちこちに転がっているので、グラフのjsonファイルさえちゃんとしていれば、割と簡単に実装できます(d3.jsはcsvファイルを読み込むのも可能みたいですが、今回は自分がjsonファイルの取り扱いを勉強したかったというのもあって、あまり調べていません)。以下では私が躓いた点だけを述べます。
- d3.jsはv3とv4以降では関数名などが大きく違う。v3の方がサンプルコード多いので、今回は思い切ってv3を使った。
- Windowsのローカル環境でChromeを使ってJavaScriptの動作を確認する場合、デフォルトではローカルファイルへのアクセスに制限があるため、コマンドプロンプトからオプション
--allow-file-access-from-filesをつけて立ち上げる。 - 外部サーバーにホスティングされたJavaScriptのファイルにアクセスする場合は、ブラウザの安全装置?を回避するため、http:やhttps:部分を省いて
<script src="//d3js.org/d3.v3.min.js">のように書く。
以上、かなりざっくりとした説明でしたが、少しでも皆さんのお役に立てると幸いです。
参考にしたサイト
私が参考にしたサイト群をご紹介しておきます。
特に一番上のサイトはやりたいことに近かったので、非常に参考になりました。感謝。
DBpediaから科学者の情報を取得→Rでクラスタリング(K-means)→結果をD3.jsで可視化
SPARQLクエリ集
SPARQL入門
RDF用クエリ言語SPARQL
グラフ・ネットワーク分析で遊ぶ(4):コミュニティ検出(クラスタリング)
Rでグラフクラスタリング
Rでウイスキー分析(2/3) ネットワーク分析
R+igraph
テキスト読込型のデータベース製作工程
GitHub Pages を使った静的サイトの公開方法が、とても簡単になっていた
[d3.js Force Simulation の世界]
(https://qiita.com/junkoda/items/2d12ecdd3b4b5c99d994)
d3.jsでスゴイっぽい図(force layout)を作ってみたら思ったより簡単だった件
D3 with GitHub Pages
force with link labels
【JavaScript】D3.js ~ グラフをクリアにする ~
Windows版chromeでローカルファイルに直接アクセスする方法[オレ得JavaScriptメモ]
いい加減、<script src="http://.. と書くのはやめましょう