The Complete Guide to Migrating a Salesforce Knowledge Base
Salesforce ナレッジ記事の移行には、次の 2 つの一般的な課題があります。
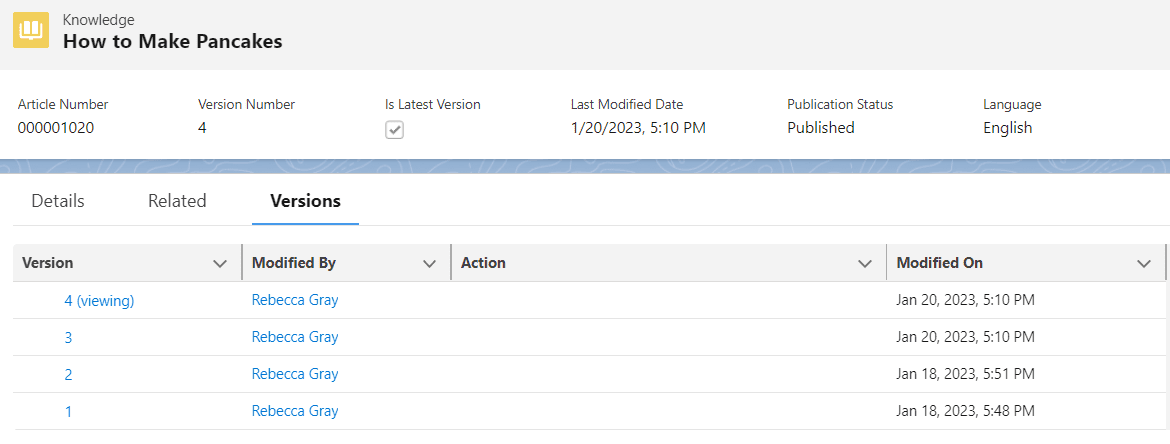
ナレッジのバージョン管理とインポート
Salesforce ナレッジ記事をサポートするデータモデルには、レコードが変更されるたびに自動的に記事のバージョン管理が行われます。標準のレコード編集の代わりに、ナレッジ記事内のテキストを変更するには、ユーザーは記事の新しいバージョンを作成する必要があります。したがって、改訂された記事がプライマリ バージョンとなり、古いバージョンはドラフト ステータスに移行します。記事のバージョンを作成すると、バージョン番号が割り当てられますが、これは変更できません。これらのナレッジ記事は、会社の製品やテクノロジーに合わせて頻繁に編集されます。Salesforce には記事のインポートと別個の Knowledge API に関する厳しい要件があるため、これにより記事の移行に課題が生じます。
ナレッジ API を理解する
Salesforce ナレッジの読み込みがなぜ非常に難しいのかを理解するには、まず、Salesforce ナレッジが標準データ API とは異なる API を使用していることを理解する必要があります。この API は、対応する制限付きでナレッジ記事を移行するために必要な特定の機能をサポートします。
- ドラフト記事の公開または作成
一度に 1 つのバージョンの記事をドラフト状態にできます。したがって、あるバージョンがドラフト状態にあり、新しいドラフトを作成するために別のリクエストが行われた場合、Salesforce へのリクエストは失敗します。同様に、記事には公開バージョンを 1 つだけ含めることができます。
2. 公開された記事のアーカイブ
サポートされる公開されたナレッジ記事のバージョンは 1 つだけであり、古いバージョンはすべてアーカイブする必要があります。記事が公開されているときに、Knowledge API を使用してこの記事の新しい公開バージョンをプッシュしようとすると、リクエストは失敗します。最初に元の記事をアーカイブ状態に移行する必要があります。
ナレッジバージョン
ナレッジ記事を移行する最初のステップは、このナレッジ API を使用して記事の最も古いバージョンをアップロードすることです。記事には、変更できない永続的なバージョン番号が自動的に割り当てられます。次に、ナレッジ記事のすべてのバージョンが、2 番目に古いバージョンから新しい古い順にアップロードされます。
画像
Salesforce は、API を介した標準クエリでは容易にアクセスできない別の場所に画像を保存します。たとえば、ナレッジ記事に画像を挿入すると、画像は記事レコードに視覚的に表示されますが、実際に記事内にあるのはハイパーリンクです。Salesforce は実際の画像を別のシステムに保存します。したがって、Salesforce ナレッジを適切にバックアップするには、画像を取得するために記事とこのファイル サブシステムへの別の抽出が必要です。この Salesforce コンテンツの保存方法では、画像をインポートするには生データを復元する必要があることも意味します。インポート後、Salesforce は生のコンテンツをサブシステムに自動的に移行し、新しいハイパーリンクを生成します。
ナレッジベースを新しい Salesforce インスタンスに移行するにはどうすればよいですか?
Salesforce ナレッジを移行する全体的なアプローチは、他の Salesforce 移行プロジェクトと同じパターンに従います。まずデータを抽出し、必要に応じて変換してから、新しい Salesforce 組織にロードする必要があります。

標準的な抽出、変換、ロード (ETL) 手法は、これらの移行プロジェクトを説明する最も簡単な方法です。ただし、Salesforce のカスタム データ モデルと複雑な API の複雑さを理解するソリューションを活用することが重要です。たとえば、CapStorm のソリューションは、画像のエクスポート/インポートや記事のバージョン管理の制約を含む、Salesforce のナレッジ記事データ モデルをサポートしています。
この投稿では、エンドツーエンドのプロジェクト管理のサンプル フレームワークなど、その他の Salesforce 移行リソースを見つけることができます。
Salesforce でのナレッジベースの移行を確実に成功させるにはどうすればよいですか?
ETL プロセスに従って、Salesforce ナレッジ記事の移行を含む Salesforce 移行を効率的に実行する方法をもう少し詳しく見てみましょう。
抽出
この手順では、ナレッジを含むデータをソース システム (通常は Salesforce) からステージング環境にプルする必要があります。この抽出に使用されるソリューションでは、ナレッジ記事本文のテキストと埋め込まれた画像またはビデオの両方を取得することが重要です。画像には復元できないため、ハイパーリンクだけでなく生のコンテンツが含まれている必要があります。
CapStorm の CopyStorm アプリケーションを使用すると、ナレッジ記事、画像、他のオブジェクトで使用される画像 (画像を含むリッチ テキスト フィールドも含む) を含む、Salesforce データ、メタデータ、スキーマの増分抽出が可能になります。Salesforce ユーザはカットオーバー日までに新しいデータを入力し、レコードを変更するため、ソース Salesforce インスタンスの静的な性質を考慮して増分抽出が重要です。さらに、新しいデータまたは変更されたデータのみを取得する抽出では、段階的に実行できる移行プロジェクトが必要となり、最終的なカットオーバー日のかなり前にコアデータセットを新しい Salesforce 組織に移行できます。
変換
データ変換の実行はさまざまな方法で実行できますが、最も簡単なのは、移行ステージング データベースを使用してデータを操作することです。ただし、移行ステージング データベースの使用は、より単純なシナリオでのみ必要になる場合があります。たとえば、Salesforce のデフォルト項目を使用するナレッジベースを、同じ項目セットを使用する Salesforce 組織に移行する場合は、この手順を省略できます。
より複雑なシナリオでは、データ変換では、データセットをターゲットの Salesforce 組織の形式に変換するためにデータベースの移行が必要になります。CapStorm は、ターゲット データベース スキーマを作成し、オブジェクトとフィールドのセットアップを Salesforce から直接複製し、リレーショナル データベース内に Salesforce データ構造の 1:1 マッピングを作成することで、このプロセスを簡素化します。
読み込み中
ほとんどの Salesforce データ移行で最も複雑な部分は、ステージング領域から Salesforce にデータを移動することです。これは主に Salesforce データの関係が原因で、個々のレコード間の接続により、データが特定のロード順序を必要とすることを意味します。ナレッジ記事には、オブジェクト固有のいくつかの特異点とともにこれらの制限も含まれています。
CapStorm のアプリケーションは、Knowledge API の認識、バージョン管理要件、画像の移動など、Salesforce ナレッジをシームレスに移行します。