■概要
AWSの有志が開発している生成AI活用アプリである generative-ai-use-cases(略称: GenU) のチャット機能にはAIの回答に対して高評価、低評価をつけるフィードバックの機能があります。
低評価の場合は、具体的な内容を送信することもできます。
これらのユーザーによるAI回答への評価をどう活用するかについて、GenUの公式GitHubでの言及が特になくQiita等での記事でもあまり触れられていなそうだったので、ちょっと自分で考えてみようという内容です。
タイトルで"(その1)"としているのは、今回はいったん案だけ考えてみて実際に仕組みを作ってみるのは続編の"(その2)"にまわさせて頂きたいという意図からです。
■会話データの保存のされ方について
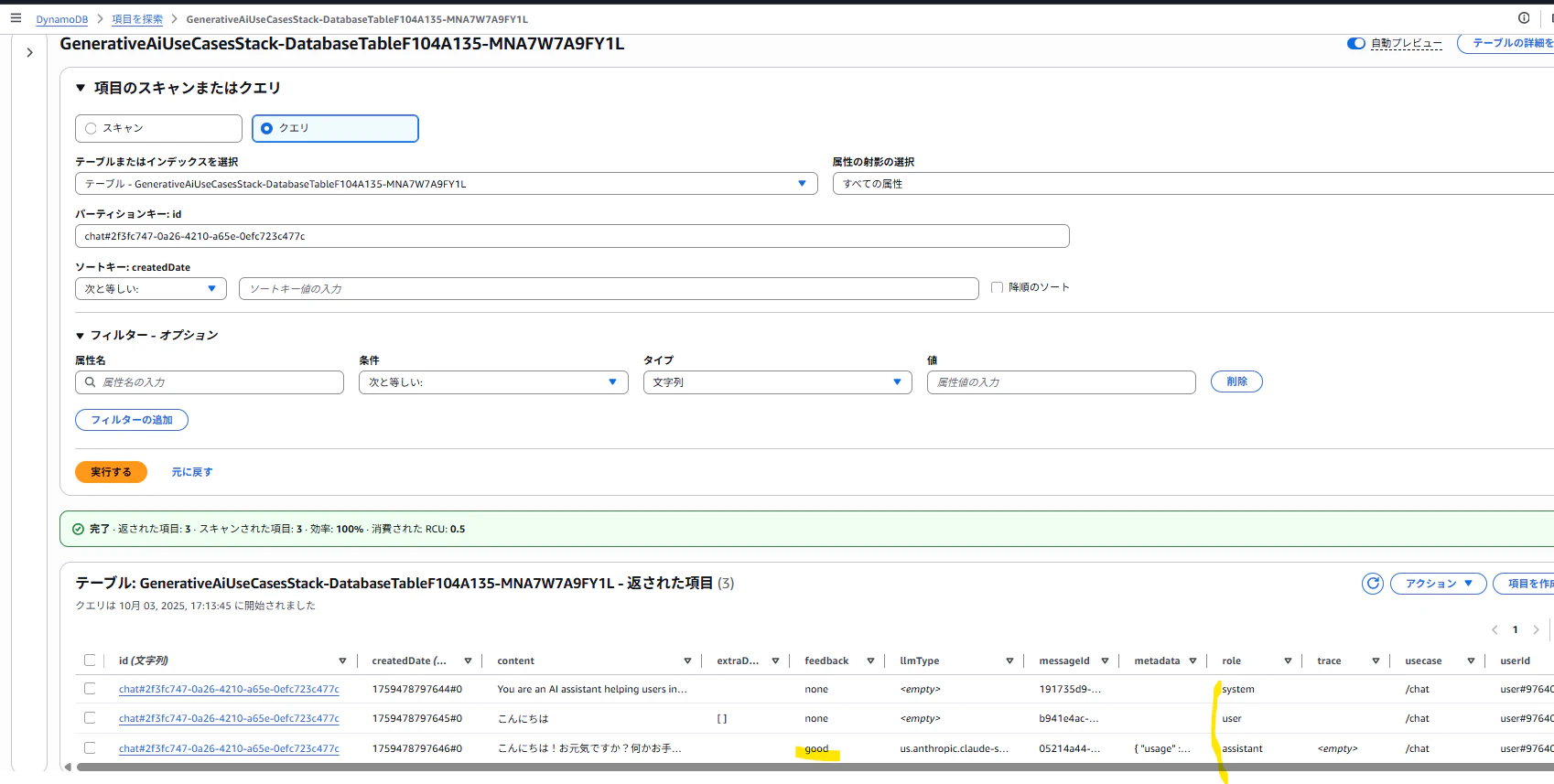
会話の履歴はDynamoDBの「GenerativeAiUseCasesStack-DatabaseTable~」という名前のテーブルに格納されます。
プライマリキーは[パーティションキー:id(String), ソートキー:createdDate(String)]となっており、会話のデータは"chat#"という接頭辞がついて個々のメッセージ単位で格納されます。
パーティションキー(id)を指定してクエリすればユーザーとAIの一連の会話の流れのデータを時系列に沿って取得できる形となっているようです。
例えば、下記画面の会話内容の場合...
システムプロンプト(role:system)、ユーザープロンプト(role:user)、AI回答(role:assistant)の3つ分のDynamoDB Itemが作成されており、AIの回答に対して高評価("good")のアイコンをクリックしているのでrole="assistant"のitemのfeedback属性に"good"という値が記録されているようです。
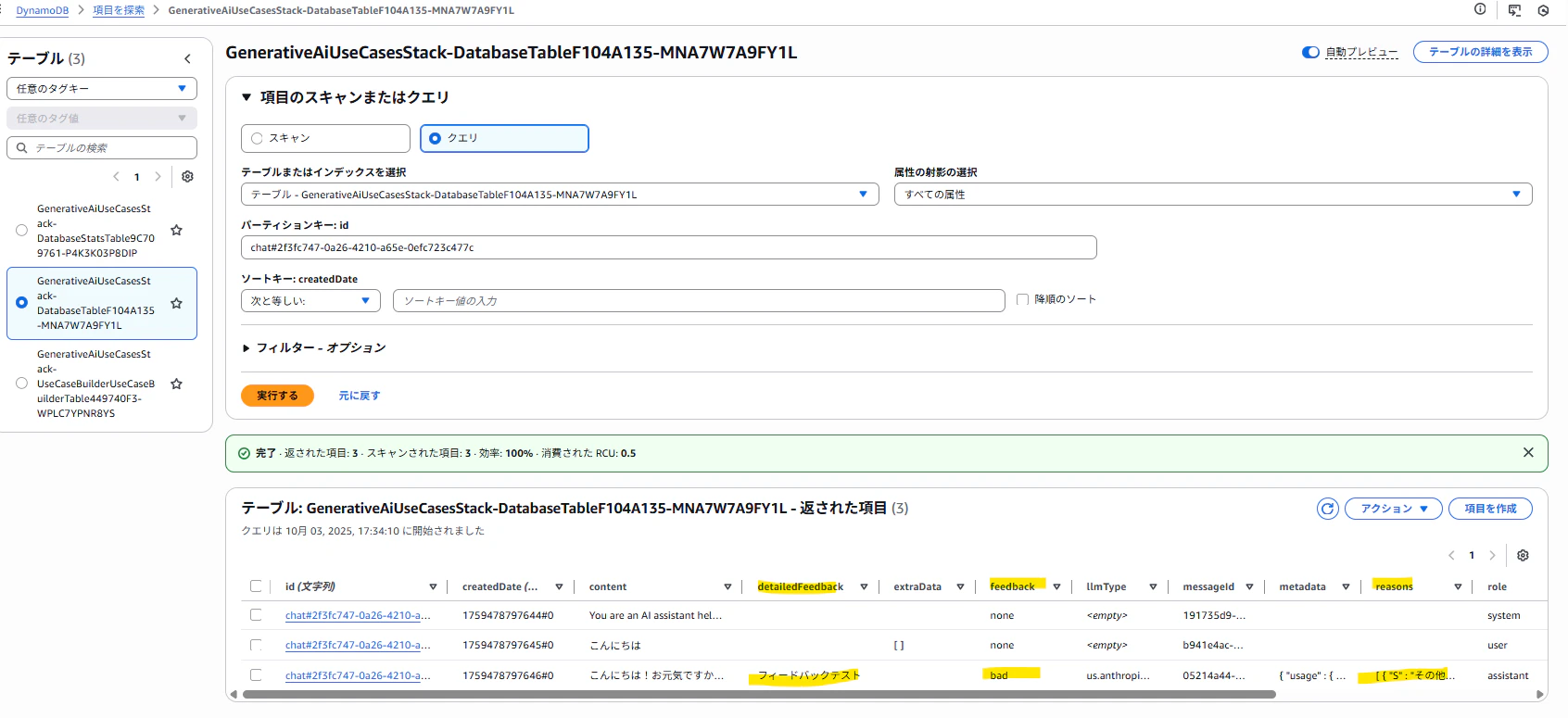
低評価("bad")のアイコンをクリックして理由を入力し送信した場合は、feedback属性には"bad"が記録され、reasons属性には"その他"や"不正確"など選択した値(複数選択可なのでリスト型)、detailedFeedback属性にはテキストボックスに入力された具体的な内容が記録される仕様となっているようです。
■フィードバック内容の出力と確認案
これからが本題となりますが、ユーザーが入力してくれたフィードバックを運用側がどう拾って改善活動などにつなげていくか、ということを考えてみます。
フィードバックに対してリアルタイムに対応する必要はなく、日次くらいで"bad"フィードバックとその内容を運用担当者が確認できればよい想定とします。
案1: GSI(グローバルセカンダリインデックス)を利用したコンソールでのクエリ
まず、「GenerativeAiUseCasesStack-DatabaseTable~」のテーブルには"feedback"属性をパーティションキーとした「FeedbackIndex」という名前のGSI(グローバルセカンダリインデックス)が設定されているようでした。
なので、AWSコンソールからこのGSIを指定して"bad"や"good"など評価が行われたデータのみをクエリ可能です。
「アクション>結果をCSVにダウンロードする」操作でクエリ結果をCSV形式でダウンロードすることも可能です。
検索された"id"の値でテーブルをクエリし直すことでAIの回答だけでなくユーザー入力プロンプトなど一連の会話の内容も確認可能です。
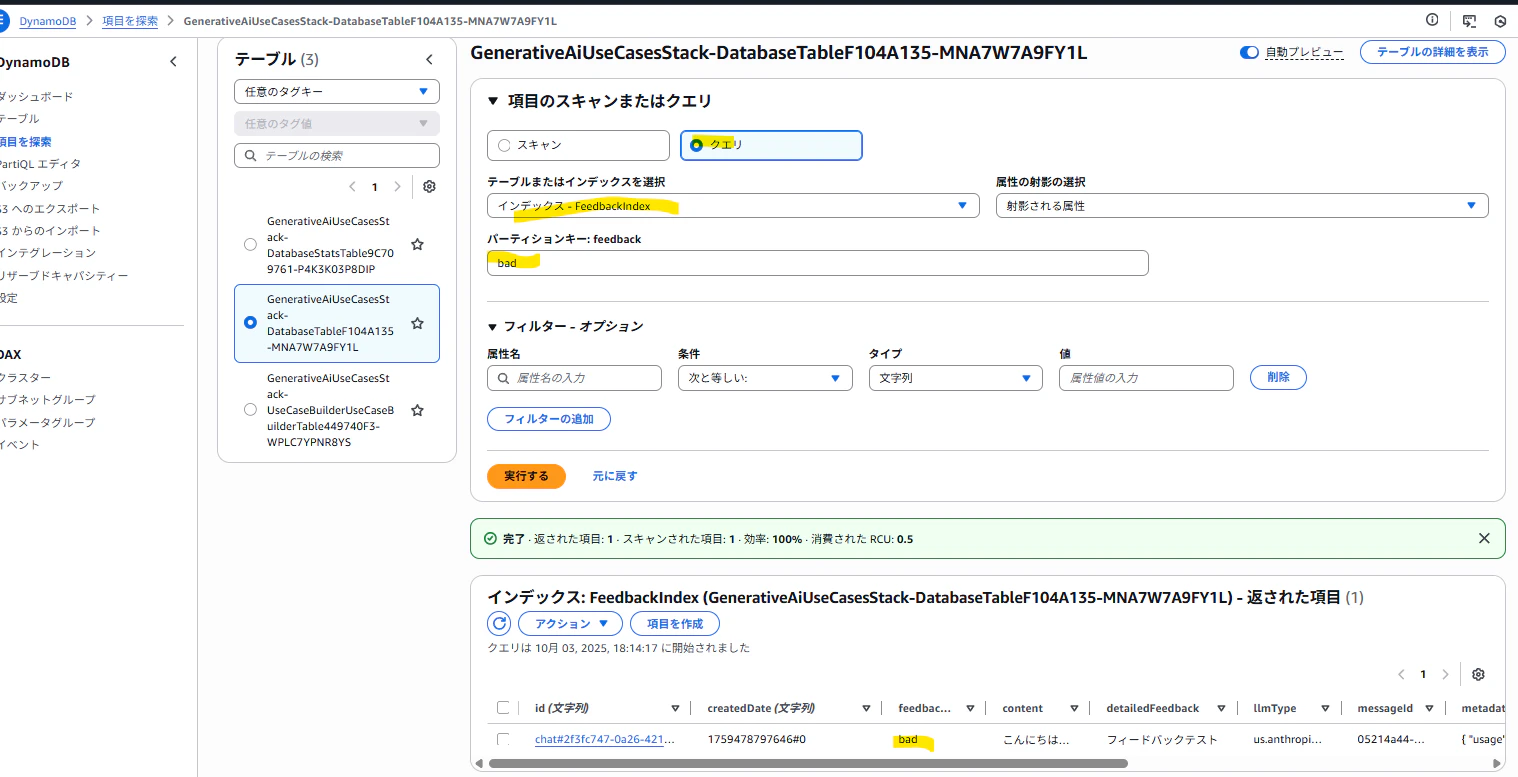
この方法はAWS管理コンソールから簡単に実施できます。
ただ、多数のユーザーと大量の会話データが存在する状況ではこの方法はどうなんだろうという気がしましたし、手作業が必要で自動化できていないのが気になりました。
案2: S3へのエクスポートとAthenaでのクエリ&BIツール(QuickSight)で可視化
DynamoDBにはキャパシティユニットを消費せずにデータをS3にエクスポートする機能がありますが、エクスポートはバックアップデータから行われるためPITR(Point-in-Time Recovery)が有効になっている前提となります。
しかしながら、GenUが作成する「GenerativeAiUseCasesStack-DatabaseTable~」のテーブルはPITRが有効になっていません。
参考:Amazon S3 への DynamoDB データのエクスポート: 仕組み
なので、S3にエクスポートするためには
- PITRを有効にするようにGenUをカスタマイズしてデプロイの上でS3へのエクスポート機能を使う
- Lambda関数などで先述のGSIを用いたクエリを実行し"good"や"bad"のデータのみを抽出し、S3に出力する
前者の方法はGenUのソース(CDKのtypescriptコード)にカスタマイズを入れる必要があり、PITR分の追加コストもかかるため個人的には避けたいところかなと思いました。
後者の方法はRCU(Read Capacity Units)を消費しますが、わざわざAI回答に対して"bad"などの評価を入れられたデータは会話データ全体のほんの一部だと想定するとこれでアリのような気がしました。
■"(その2)"に向けて
いったん試してみるフィードバックデータ活用案としては
「Lambda関数でGSIを用いたクエリでDynamoDBのデータを抽出しS3に出力する」
および
「Athenaでのクエリ&QuickSightで可視化」
「GenUに管理者専用画面を追加して可視化」
に決めたので、続編の"(その2)"記事では実際にその仕組みを作成し可視化まで試してみたいと思います。
AWS Lamdba等のリソースはCDK(Cloud Development Kit)で作成しソースはGitHubで公開する予定です。
それではまた。
~追記(2026-04-04):方針変更します~
当初は「QuickSightで可視化」としたのですが、QuickSightの利用にはそれなりにコスト(料金)もかかりますし既に運用しているならともかくFeedbackの確認のためだけにQuickSight利用を追加するのもなあ...と思い直しました。
ですのでGenUに管理者専用の画面を追加して、GenU上で管理者ユーザーのみがFeedbackの内容確認を行えるように下記方針に変えました。
- GenUに管理者専用機能を追加
- 管理者用画面でフィードバック情報を参照可能とする
- フィードバック情報はバックエンドAPIを通じてAthenaでクエリ
前者の「GenUに管理者専用機能を追加」については別記事でやってみており、そちらの記事(GenUに管理者用機能(画面とAPI)を追加してみる)をご参照頂けると幸いです。