この記事はOpenCV Advent Calendar 2022の21日目の記事です。
はじめに
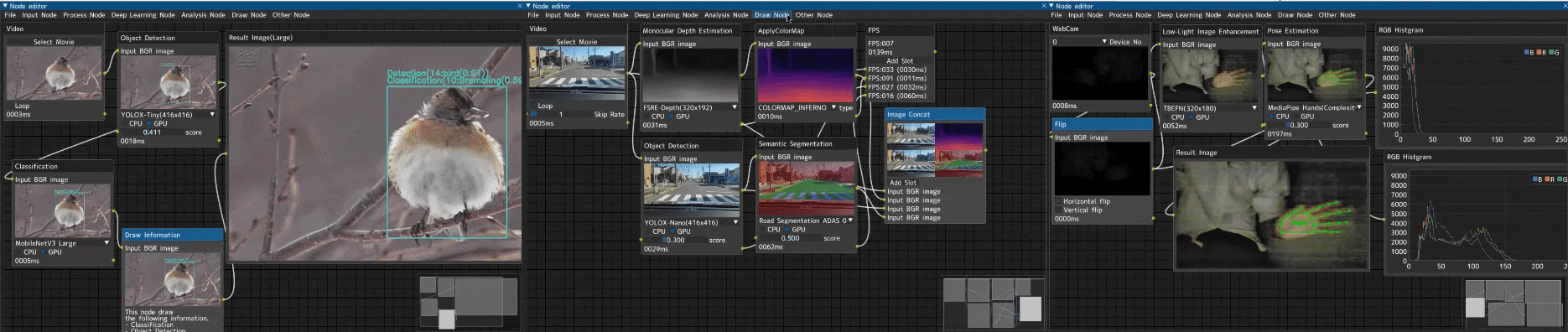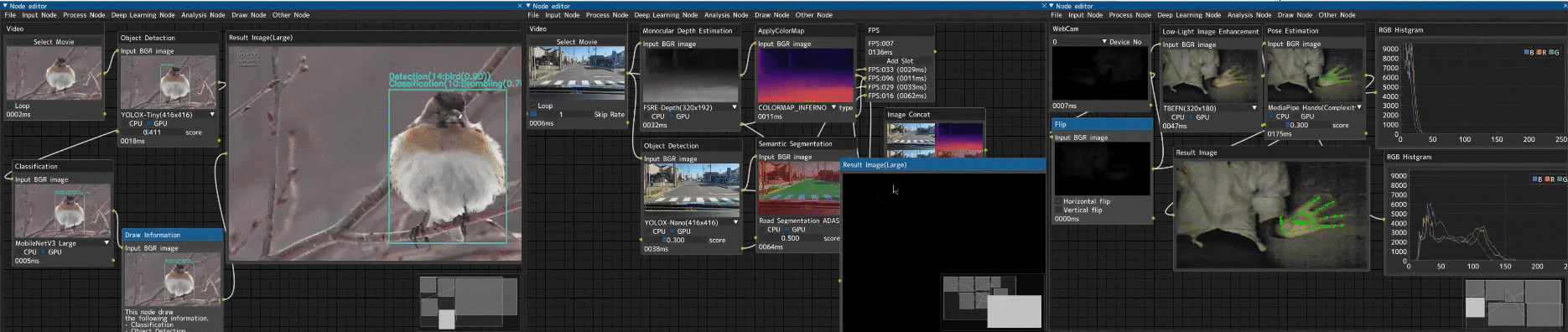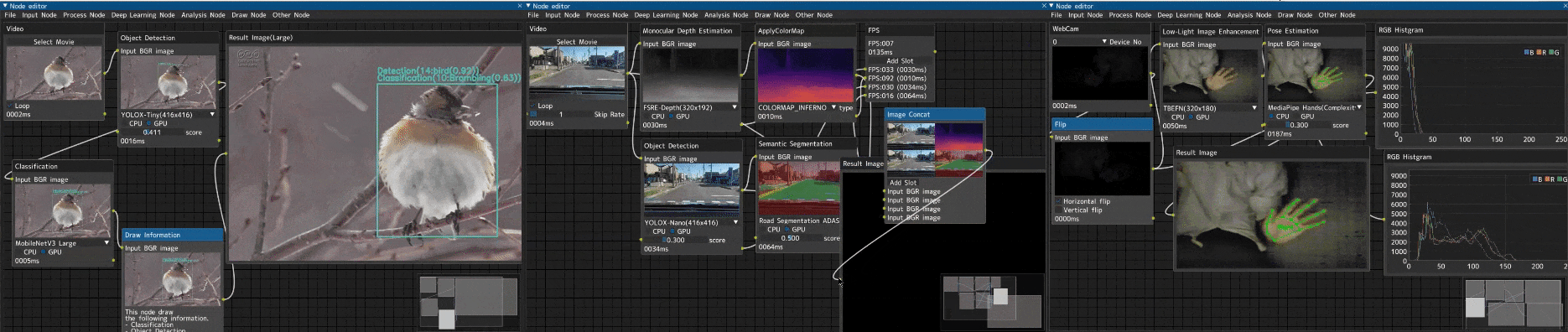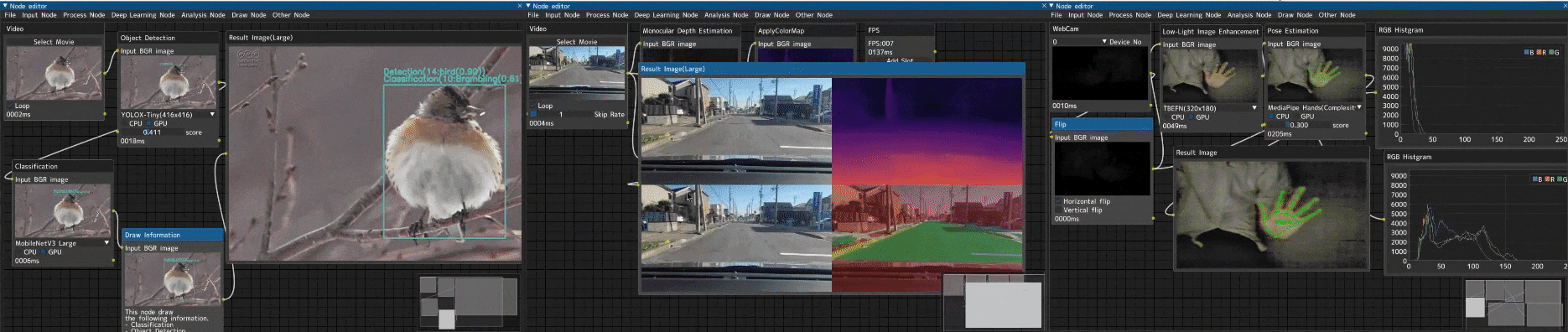
趣味でノードエディタ形式の画像処理ツール「Image-Processing-Node-Editor」を作りました。
その紹介の記事です。中身にOpenCVガッツリ使っているからアドカレOKですよね。。。👀?
ガッツリ使っているという意味では、GUI部分の DearPyGui のほうがガッツリ使っているかもしれませんが🤔
「Image-Processing-Node-Editor」とは
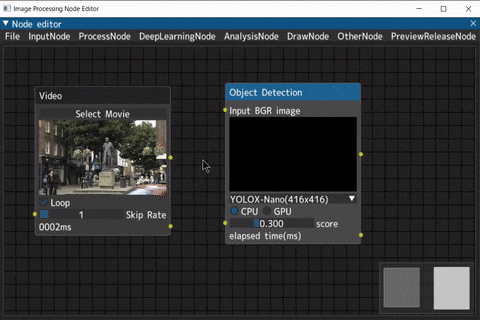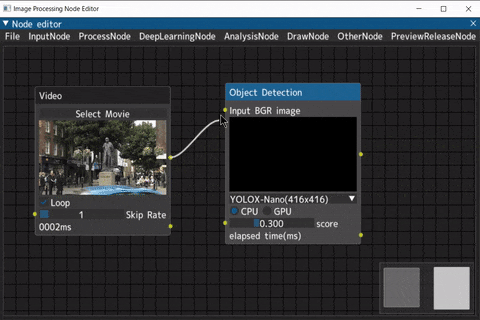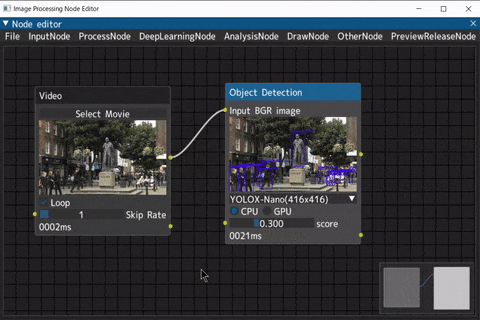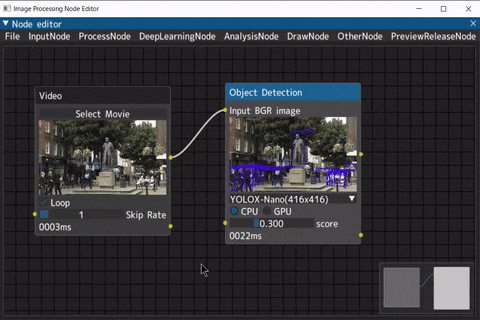
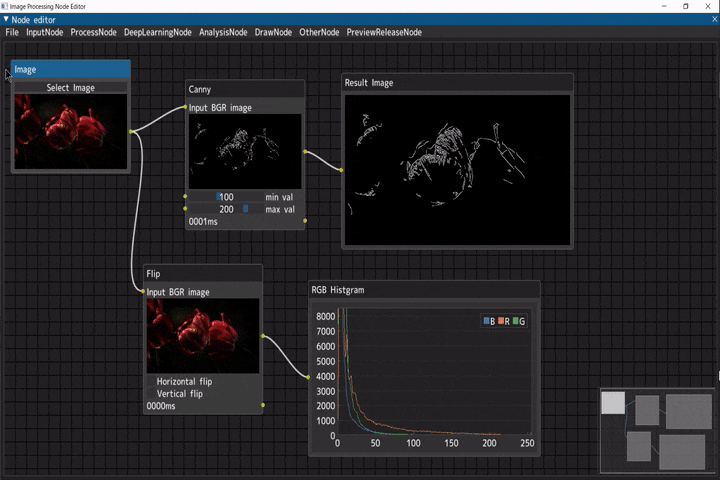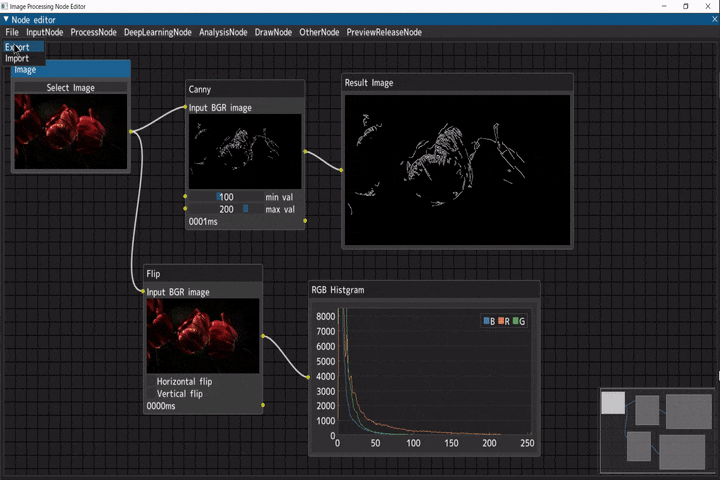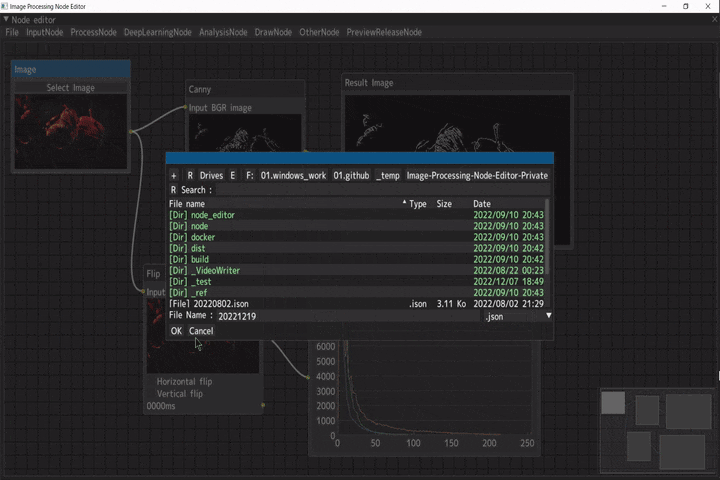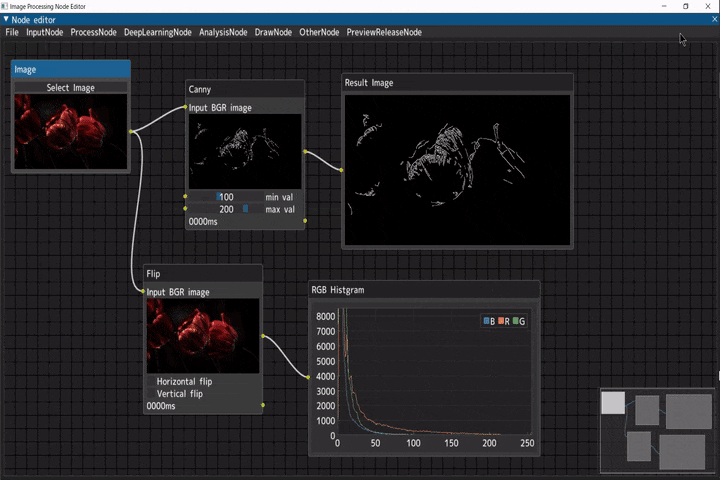
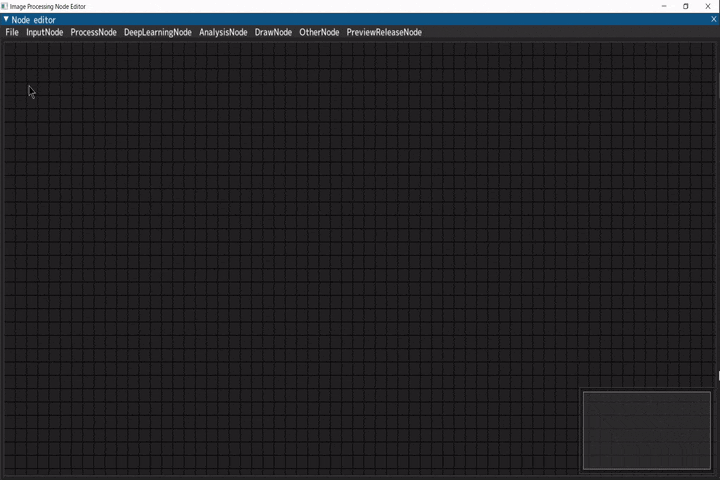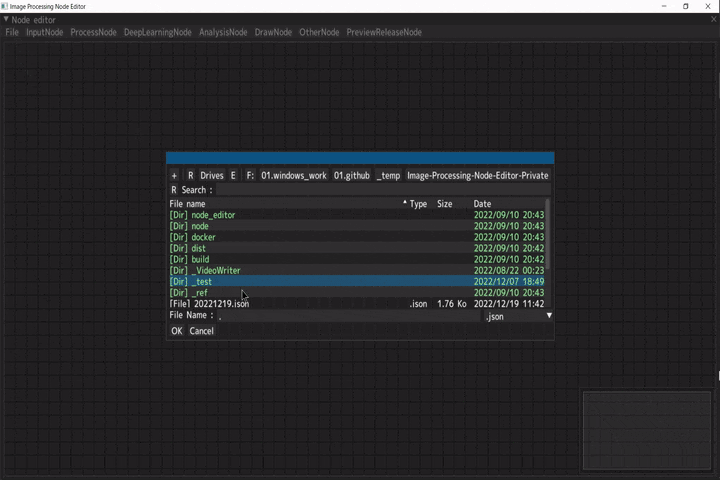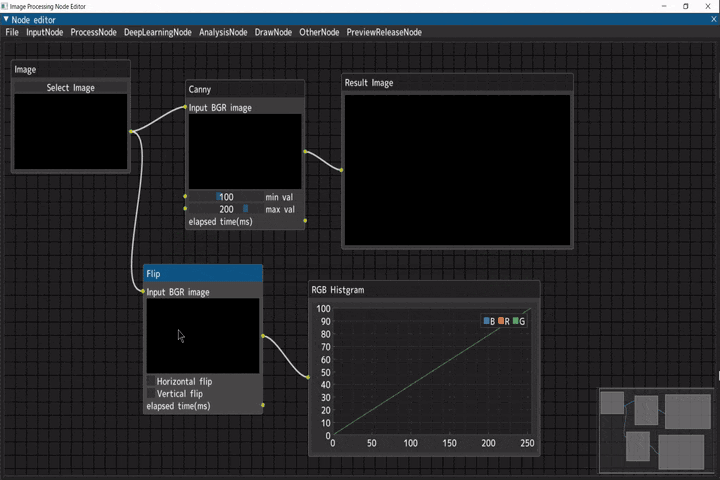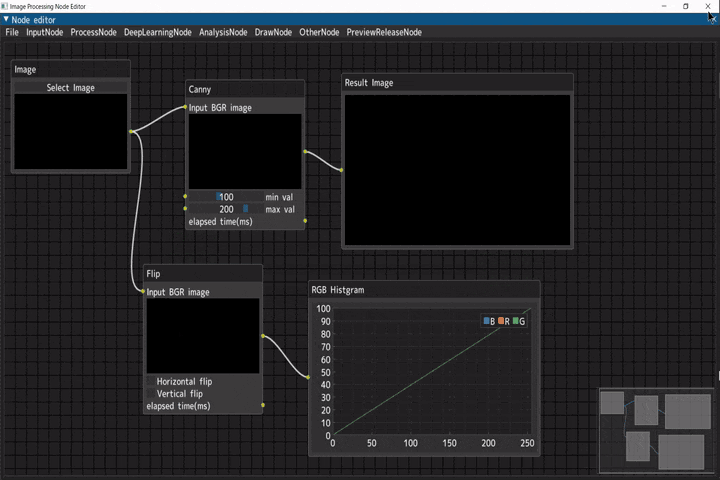
以下のように、ノードを接続していくことで、処理結果を可視化しながら画像処理が行えるツールです。

以下のような特徴があります。
- 主要な処理は全てPython ※ライブラリ部分除く
- 各処理を可視化しながら画像処理が試せる
-
自作ノードの追加が容易 (だと信じている)
記事書くために見直していましたが、イマイチ複雑ですわ、、、😇 - OSS (Apache 2.0ライセンス)
- デフォルトでいくつかのAI機能を搭載
- クラス分類 (Classification)
- 物体検出 (Object Detection)
- セマンティックセグメンテーション (Semantic Segmentation)
- 単眼深度推定 (Monocular Depth Estimation)
- 顔検出/姿勢推定 (Face Detection/Pose Estimation)
- 低照度画像補正 (Low-Light Image Enhancement)
正直言えば、似たようなツールは既に結構あるので、、、
「自己満足」&「自作だから内部を理解していて改造しやすい」程度のツールです。
僕の僕による僕のためのツール🦔
動作例
線画抽出
入力画像に対して線画抽出を行うデモです。
ビデオ入力(Videoノード) → ぼかし(Blurノード) → キャニー(Cannyノード) → 二値化(Thresholdノード)
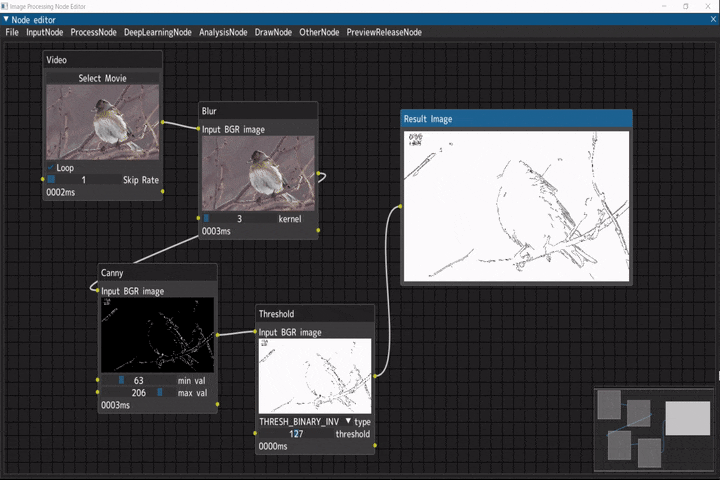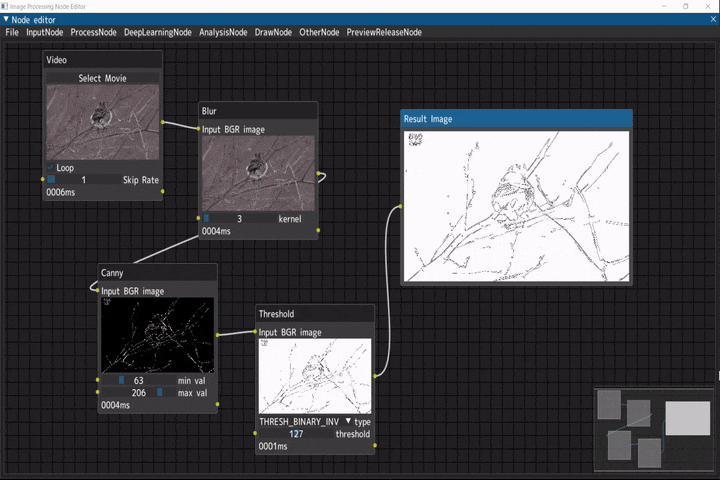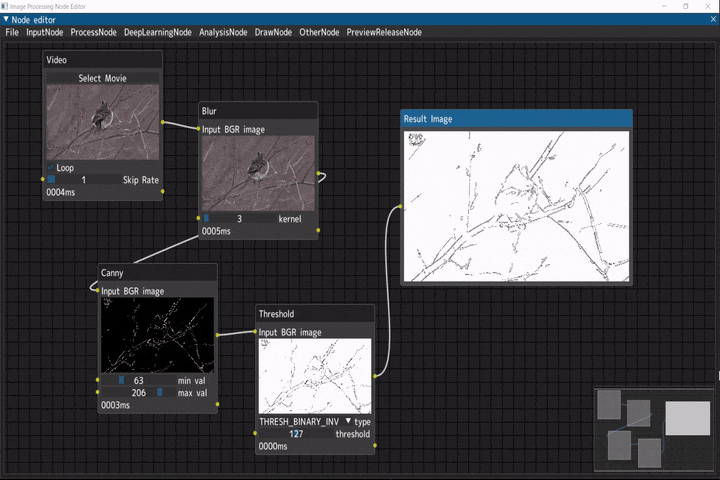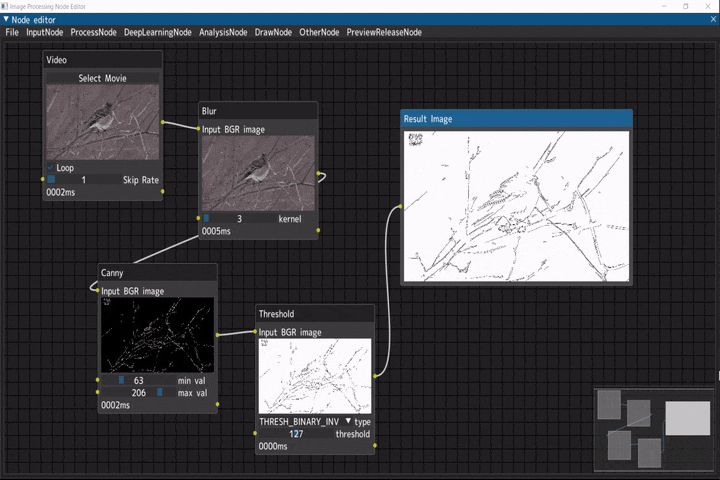
デモ動画には、NHKクリエイティブ・ライブラリーの冬のえさ場(3) ヤマガラ シジュウカラ アトリを使用しています。
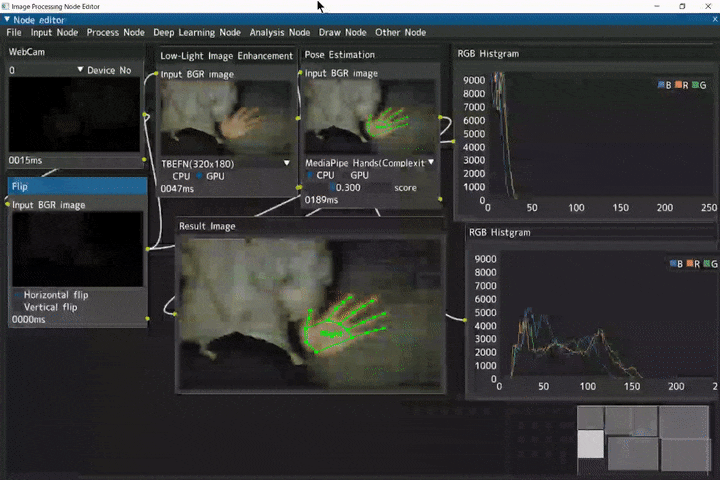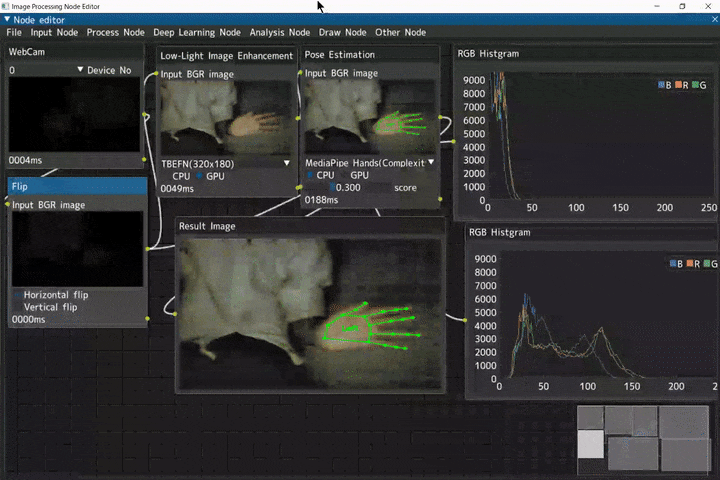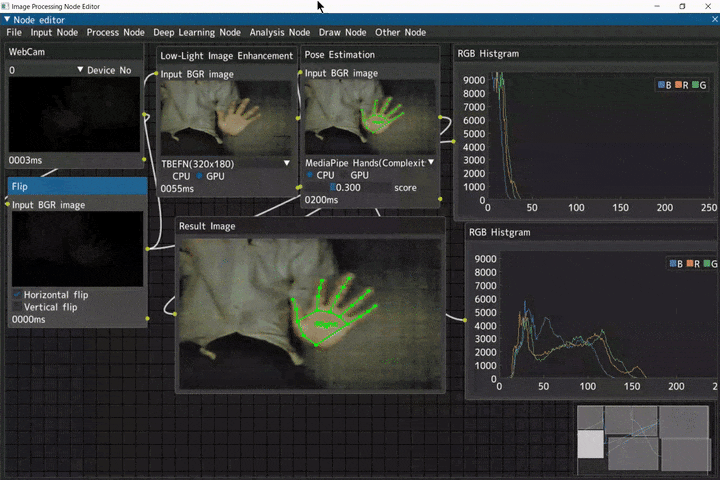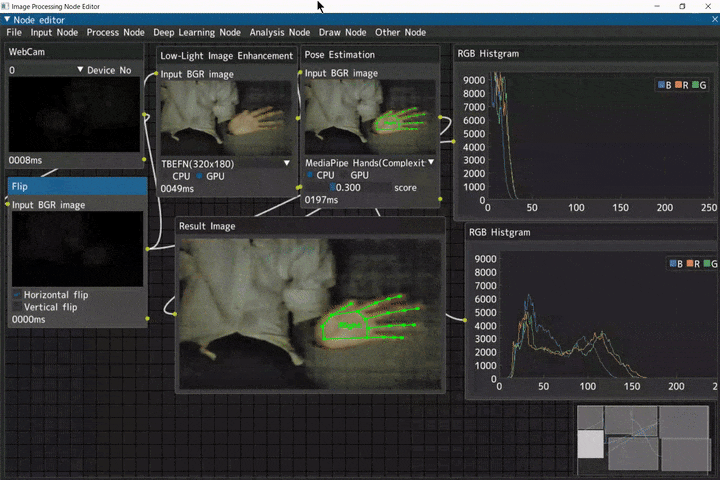
低照度画像補正からの手検出
ほぼ真っ暗の入力画像に対して、低照度画像補正を行い、補正した画像から手検出を行うデモです。
Webカメラ入力(WebCamノード) → 左右反転(Flipノード) → 低照度画像補正(Low-Light Image Enhancementノード) → 手検出(Pose Estimationノード) → RGBヒストグラム表示(RGB Histgramノード)
マルチオブジェクトトラッキング
入力画像に対して、物体検出を行いマルチオブジェクトトラッキングを行うデモです。
ビデオ入力(Videoノード) → 物体検出(Object Detectionノード) → マルチオブジェクトトラッキング(MOTノード)
※MOTノードは試験的なノード
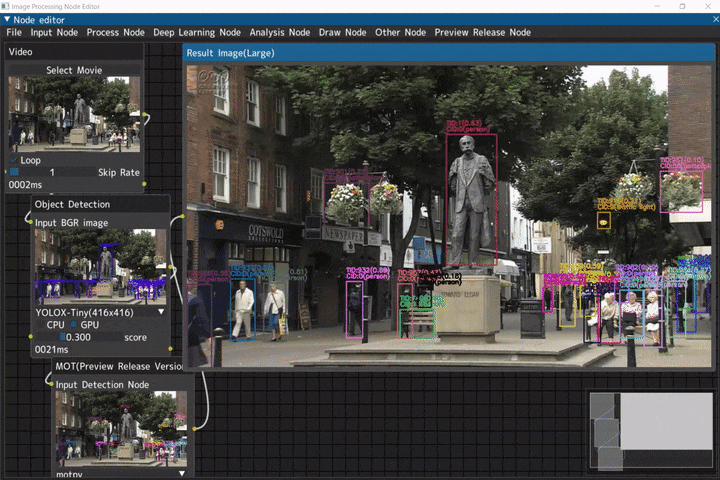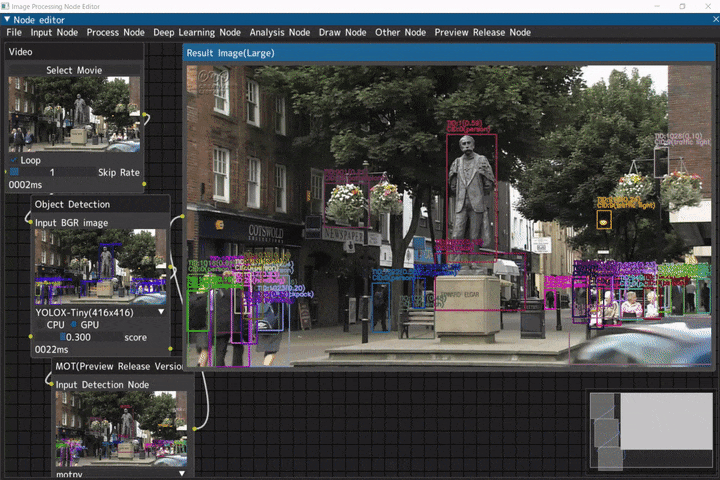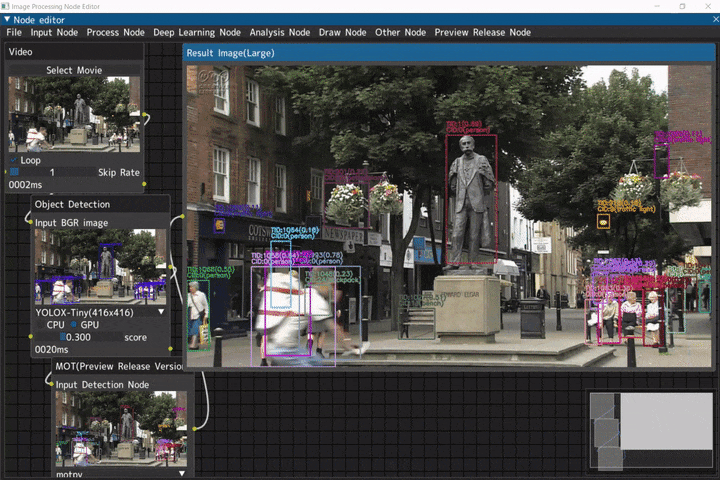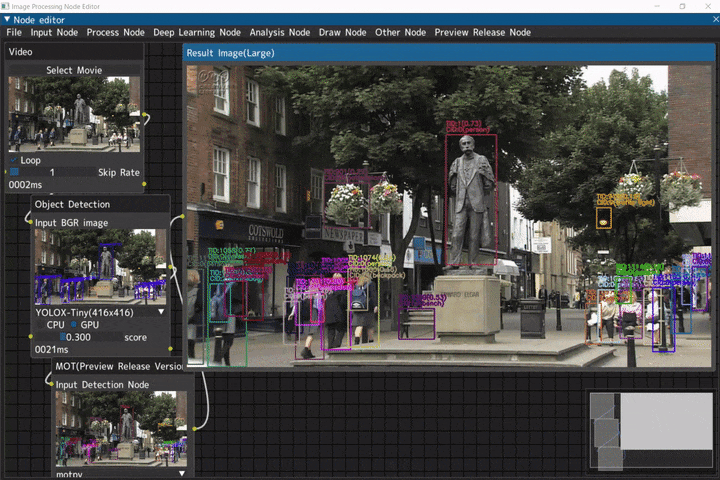
デモ動画には、NHKクリエイティブ・ライブラリーのイギリス ウースターのエルガー像を使用しています。
車載動画に対する複数種の画像解析
入力画像に対して、複数の画像解析を行い実行結果を結合するデモです。
ビデオ入力(Videoノード) → 以下解析処理 → 画像結合(Image Concatノード) → FPS計測(FPSノード)
- 単眼深度推定(Monocular Depth Estimation) → 疑似カラー(ApplyColorMapノード)
- セマンティックセグメンテーション(Semantic Segmentationノード)
- 物体検出(Object Detectionノード)
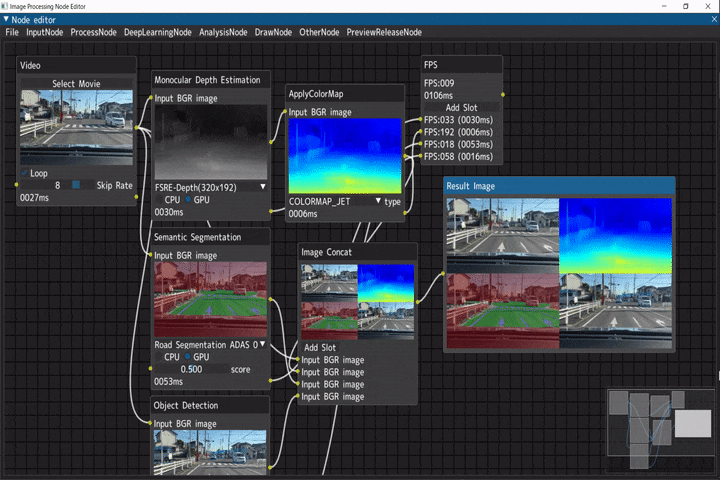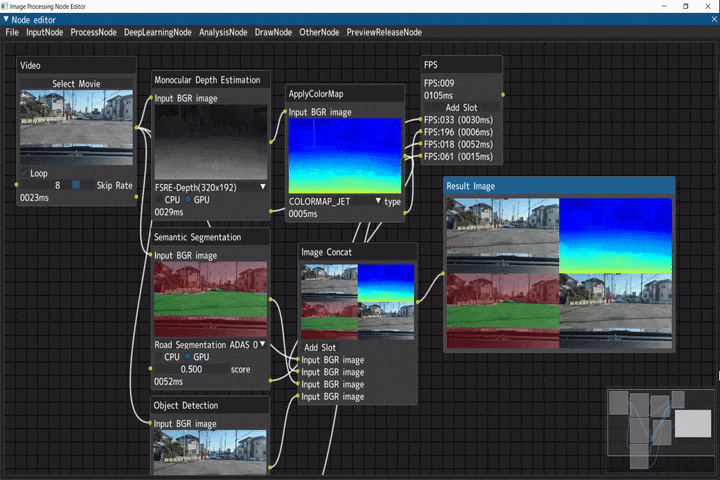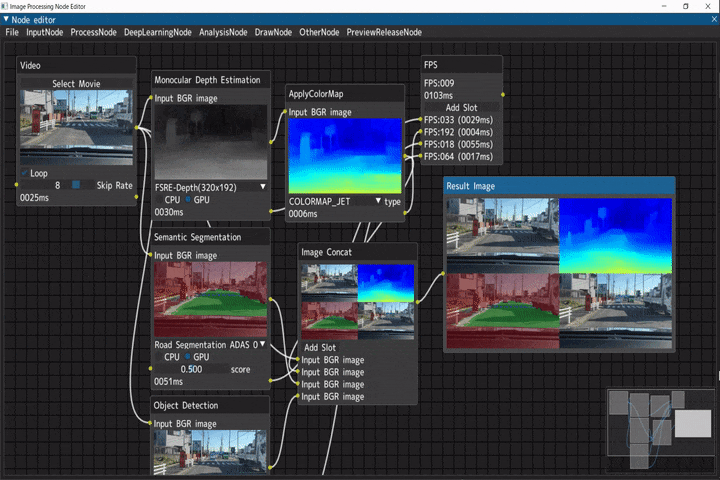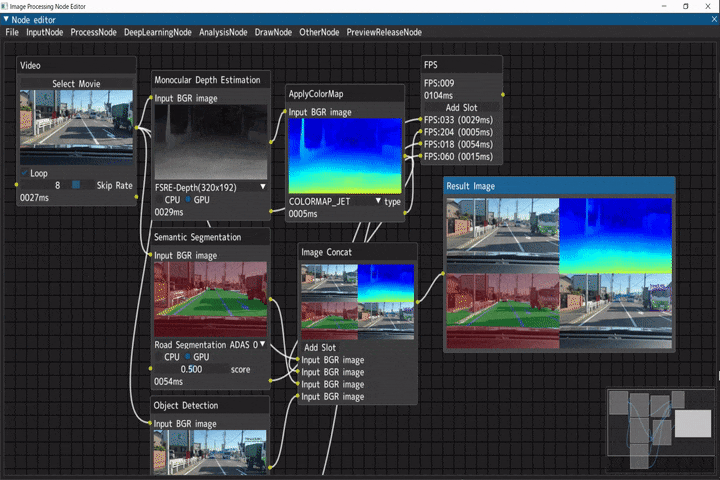
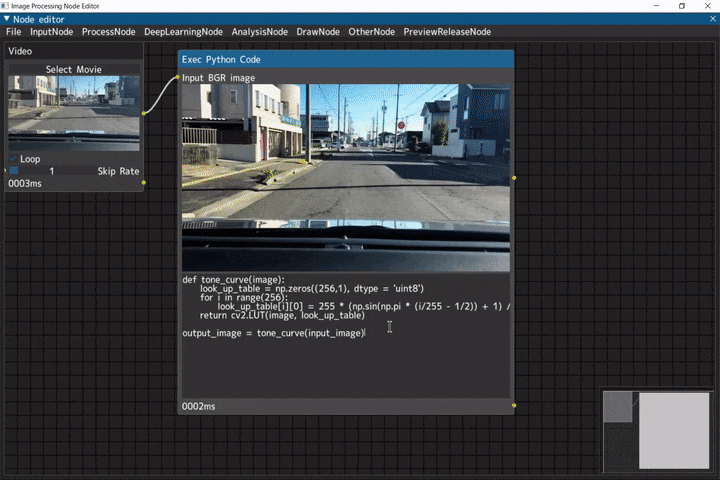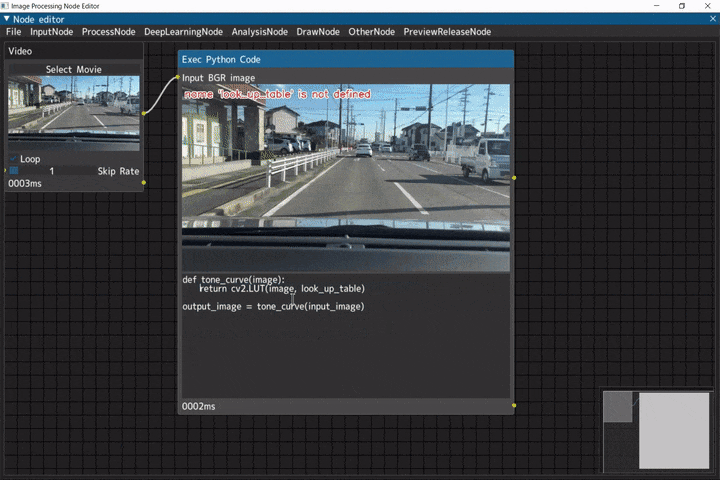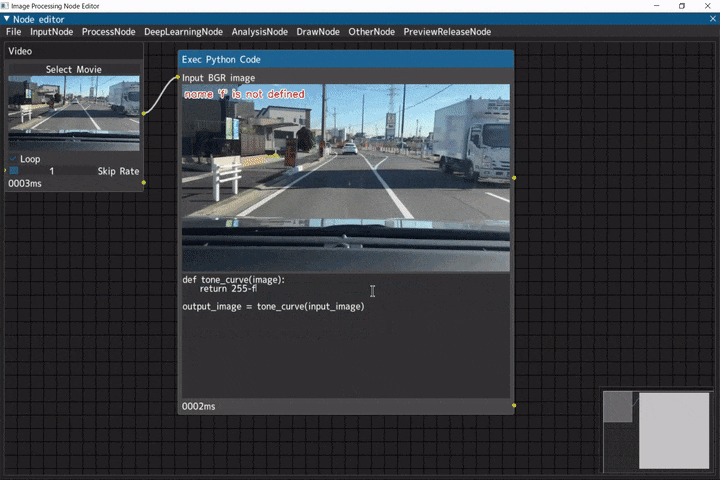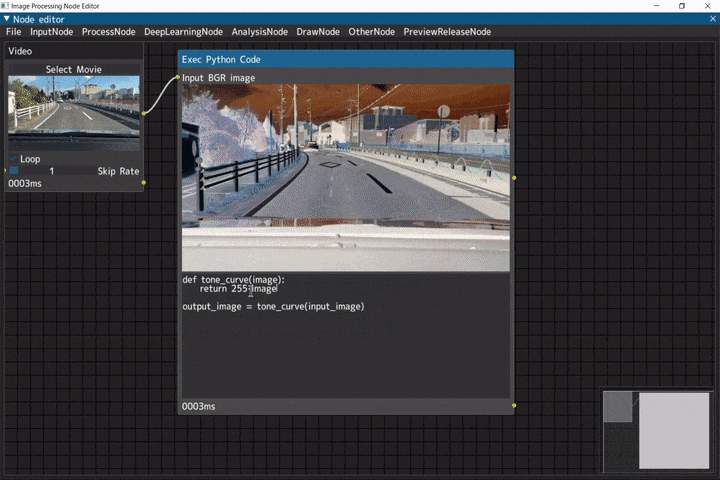
Python実行ノード
Pythonのコードを扱うデモです。
ノードへの入力画像は「input_image」、ノードからの出力画像は「output_image」の変数に格納されています。
ビデオ入力(Videoノード) → Python実行ノード(Exec Python Codeノード)
※Exec Python Codeノードは試験的なノード
インストール方法
GitHubリポジトリの README#installation を参照ください。
からあげさんの「画像処理ツール「Image-Processing-Node-Editor」インストール方法」も参考になると思います。素晴らしい記事をありがとうございます🦔
基本的な操作
基本的な操作は以下の3つです。
ノード生成
メニューから作成したいノードを選びクリック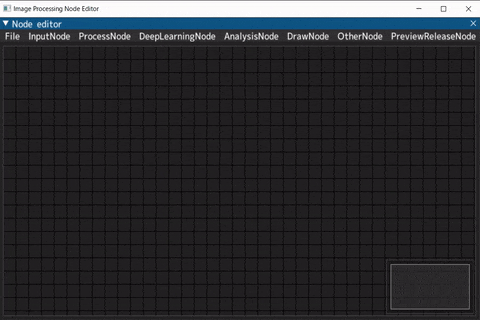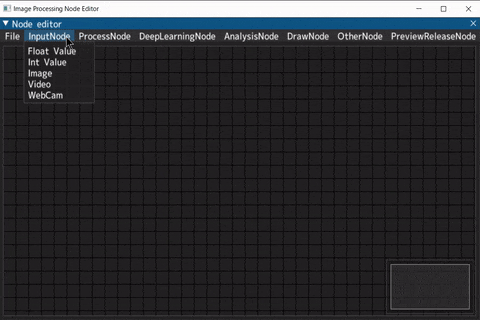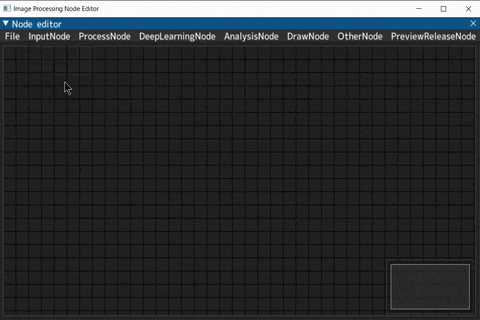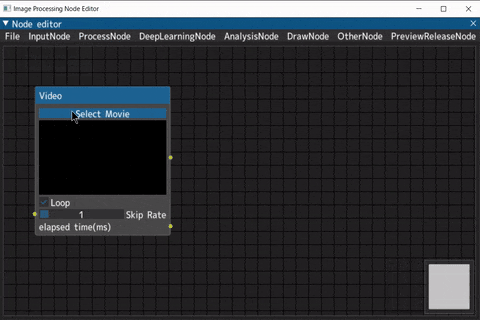
ノード接続
出力端子をドラッグして入力端子に接続
端子に設定された型同士のみ接続可能
ノード削除
削除したいノードを選択した状態で「Del」キー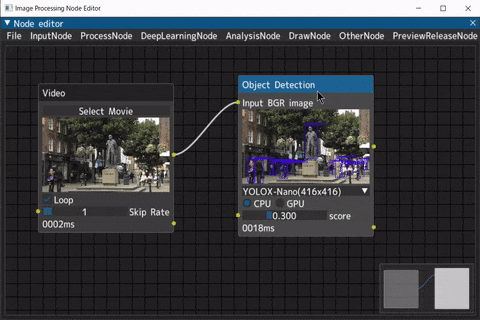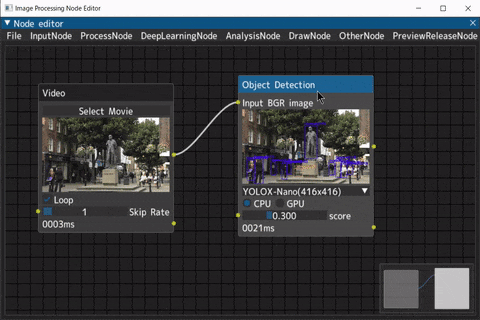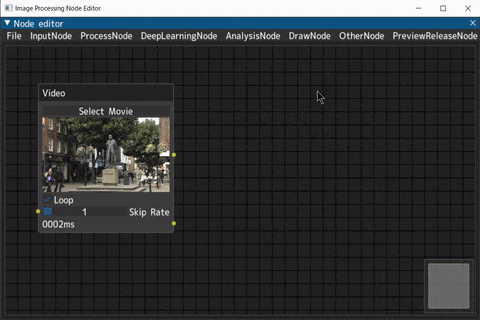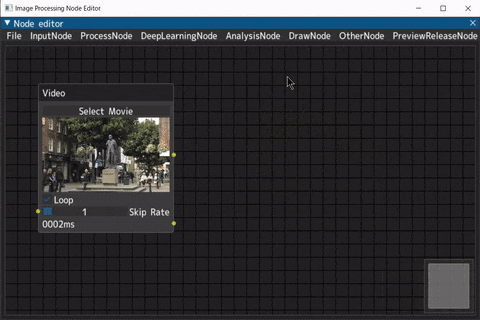
ノード
GitHubリポジトリの README#node を参照ください。
ざっくり言うと以下の種別のノードがあります。
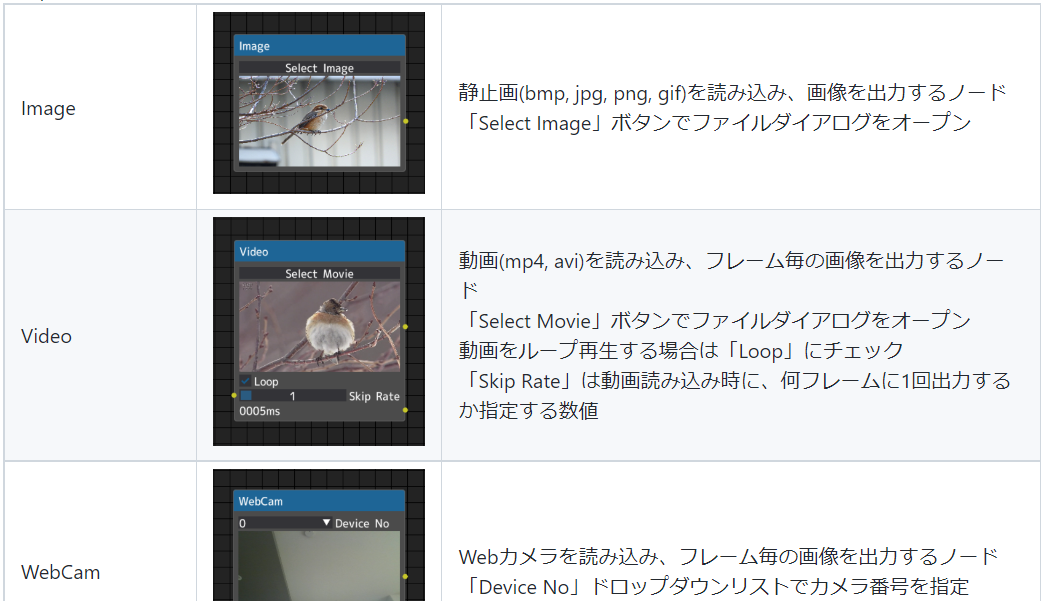
画像入力に関わるノード(Input Node)
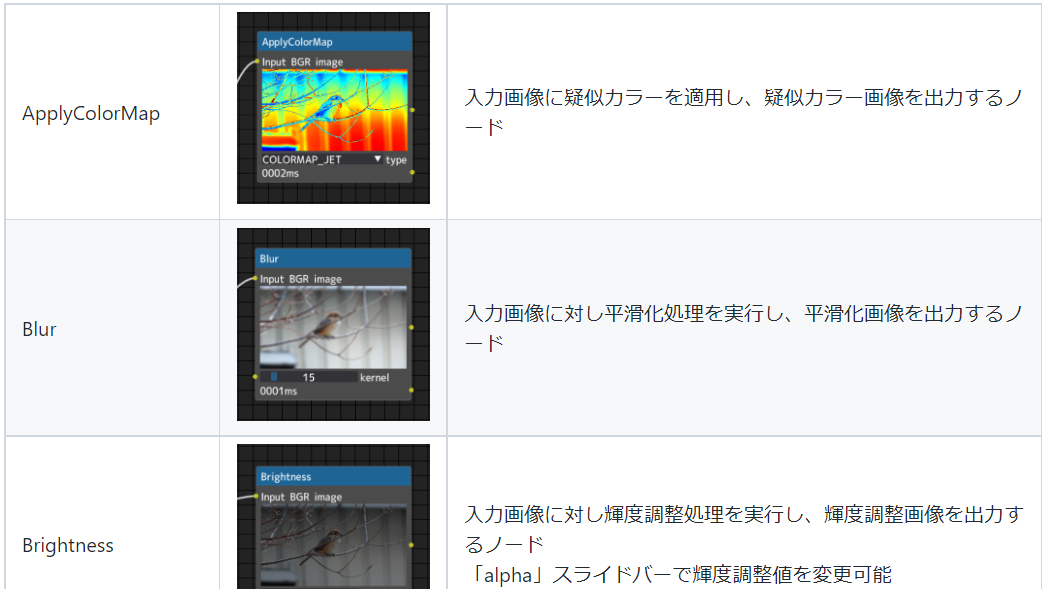
画像処理に関わるノード(Process Node)
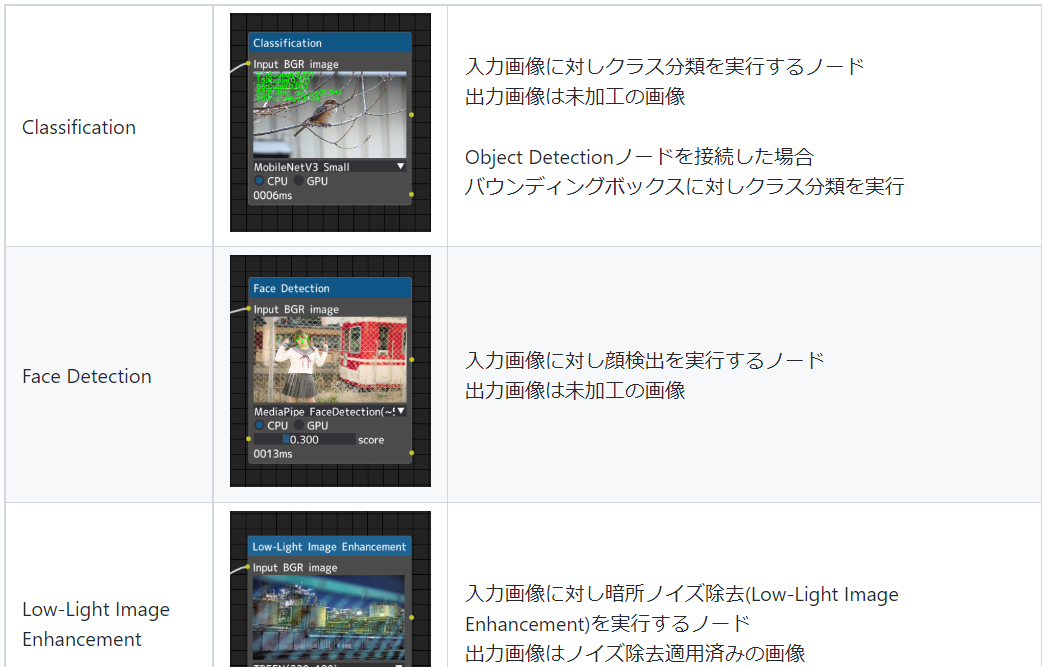
ディープラーニングに関わるノード(Deep Learning Node)
解析に関わるノード(Analysis Node)
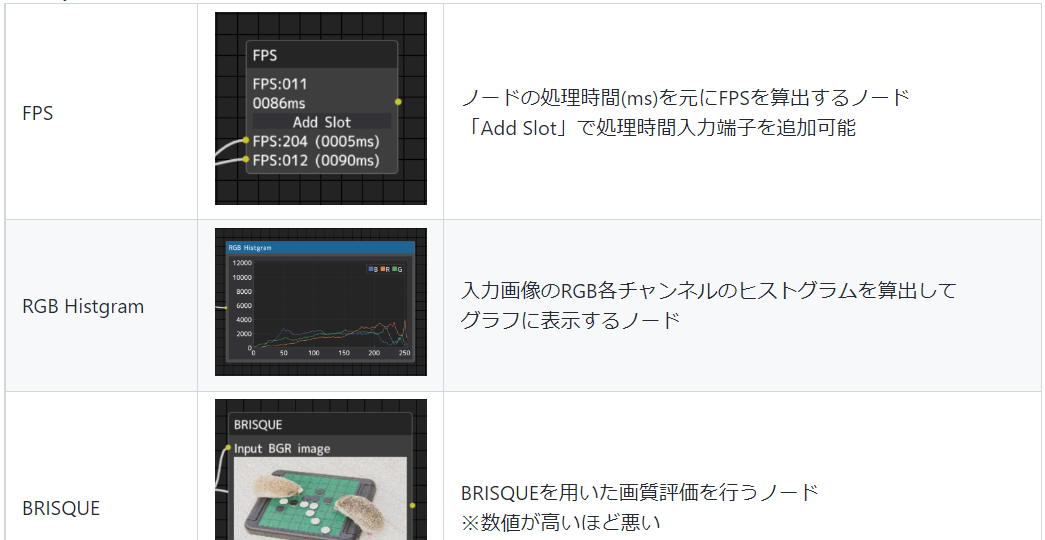
描画に関わるノード(Draw Node)
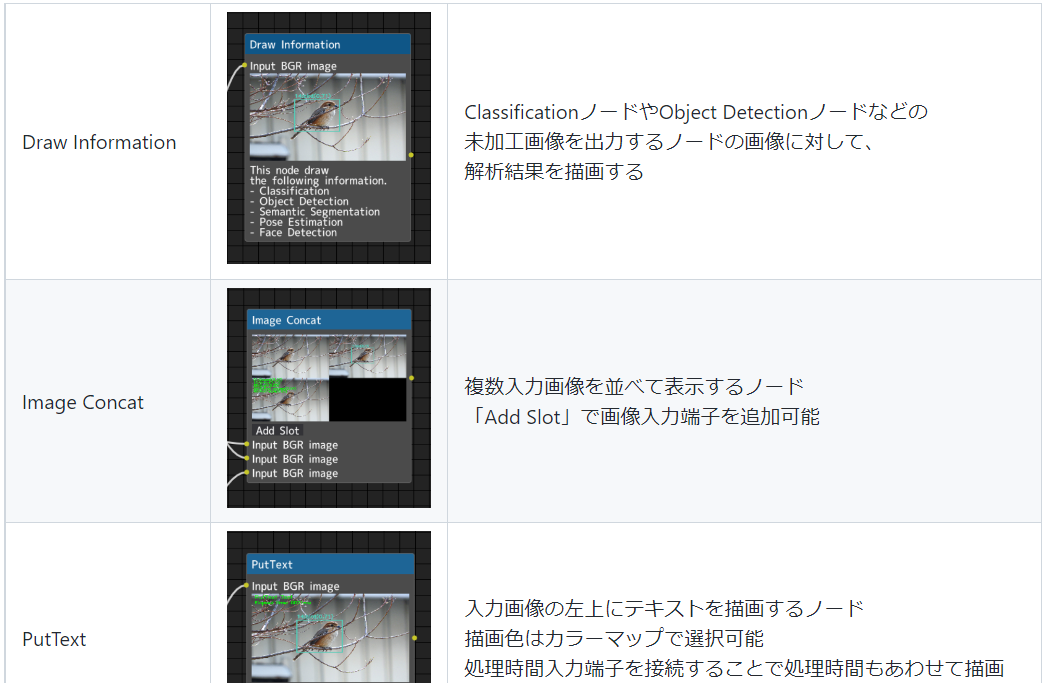
その他、上記以外のノード(Other Node)
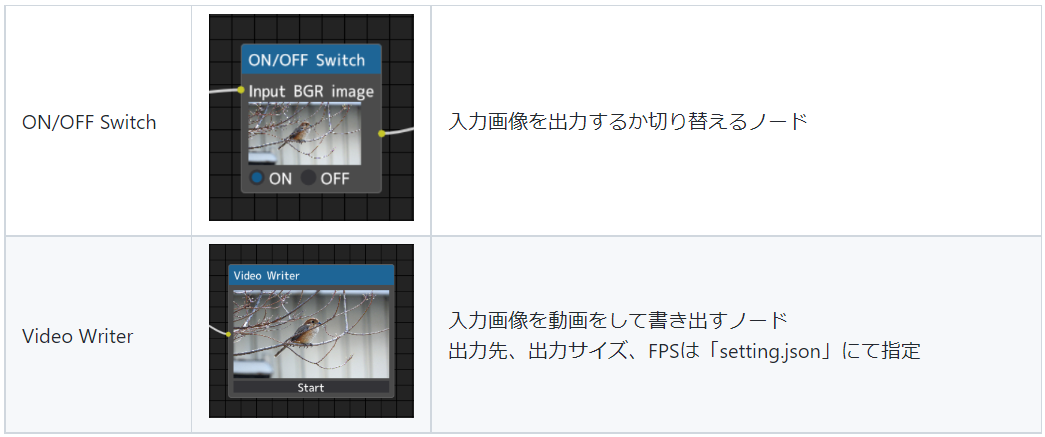
試験的なノード(Preview Release Node)
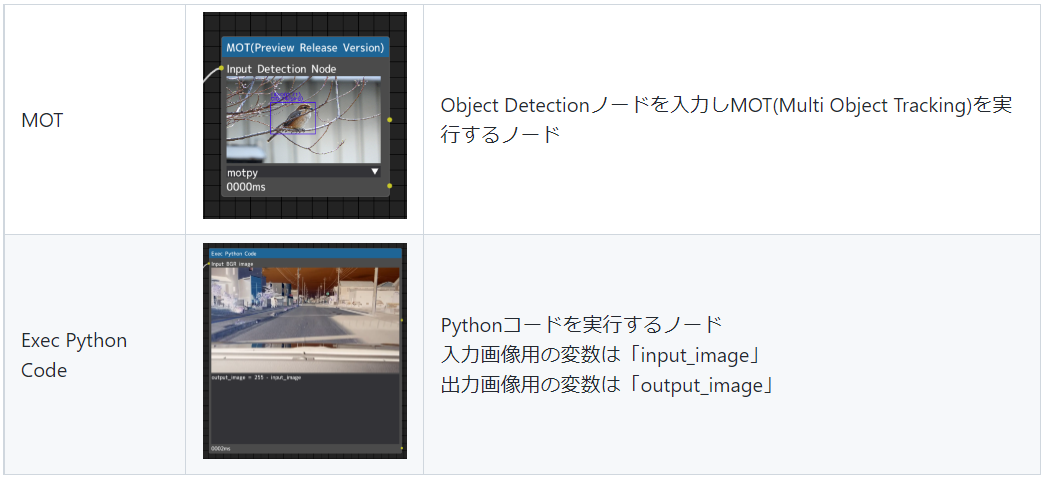
試験的なノード ※別リポジトリ公開
エクスポート/インポート
ノードエディターのノードの接続状態をjsonファイルでエクスポートすることが出来ます。
エクスポートしたjsonファイルはインポートして、ノードの接続状態を復元することが出来ます。
初期設計をミスって、ノードを一度も追加していない状況でしかインポート出来ない問題がありますが、、、😇
処理概要
細かい処理などは省いていますが、
ノードエディタとノード動作をザックリ書くと以下のような感じです。
ノード追加方法
ノードは「Image-Processing-Node-Editor/node」配下のディレクトリに、
Pythonスクリプトを置くと、動的インポートされます。
ノードの実装は、DpgNodeABCクラスを継承したNodeクラスを作成し、その各メソッドを作りこんでいく感じです。
例えば、ぼかしノードは以下のような実装になっています。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import time
import cv2
import numpy as np
import dearpygui.dearpygui as dpg
from node_editor.util import dpg_get_value, dpg_set_value
from node.node_abc import DpgNodeABC
from node_editor.util import convert_cv_to_dpg
def image_process(image, kernel_size):
image = cv2.blur(image, (kernel_size, kernel_size))
return image
class Node(DpgNodeABC):
_ver = '0.0.1'
node_label = 'Blur'
node_tag = 'Blur'
_min_val = 1
_max_val = 128
_opencv_setting_dict = None
def __init__(self):
pass
def add_node(
self,
parent,
node_id,
pos=[0, 0],
opencv_setting_dict=None,
callback=None,
):
# タグ名
tag_node_name = str(node_id) + ':' + self.node_tag
tag_node_input01_name = tag_node_name + ':' + self.TYPE_IMAGE + ':Input01'
tag_node_input01_value_name = tag_node_name + ':' + self.TYPE_IMAGE + ':Input01Value'
tag_node_input02_name = tag_node_name + ':' + self.TYPE_INT + ':Input02'
tag_node_input02_value_name = tag_node_name + ':' + self.TYPE_INT + ':Input02Value'
tag_node_output01_name = tag_node_name + ':' + self.TYPE_IMAGE + ':Output01'
tag_node_output01_value_name = tag_node_name + ':' + self.TYPE_IMAGE + ':Output01Value'
tag_node_output02_name = tag_node_name + ':' + self.TYPE_TIME_MS + ':Output02'
tag_node_output02_value_name = tag_node_name + ':' + self.TYPE_TIME_MS + ':Output02Value'
# OpenCV向け設定
self._opencv_setting_dict = opencv_setting_dict
small_window_w = self._opencv_setting_dict['process_width']
small_window_h = self._opencv_setting_dict['process_height']
use_pref_counter = self._opencv_setting_dict['use_pref_counter']
# 初期化用黒画像
black_image = np.zeros((small_window_w, small_window_h, 3))
black_texture = convert_cv_to_dpg(
black_image,
small_window_w,
small_window_h,
)
# テクスチャ登録
with dpg.texture_registry(show=False):
dpg.add_raw_texture(
small_window_w,
small_window_h,
black_texture,
tag=tag_node_output01_value_name,
format=dpg.mvFormat_Float_rgb,
)
# ノード
with dpg.node(
tag=tag_node_name,
parent=parent,
label=self.node_label,
pos=pos,
):
# 入力端子
with dpg.node_attribute(
tag=tag_node_input01_name,
attribute_type=dpg.mvNode_Attr_Input,
):
dpg.add_text(
tag=tag_node_input01_value_name,
default_value='Input BGR image',
)
# 画像
with dpg.node_attribute(
tag=tag_node_output01_name,
attribute_type=dpg.mvNode_Attr_Output,
):
dpg.add_image(tag_node_output01_value_name)
# カーネルサイズ
with dpg.node_attribute(
tag=tag_node_input02_name,
attribute_type=dpg.mvNode_Attr_Input,
):
dpg.add_slider_int(
tag=tag_node_input02_value_name,
label="kernel",
width=small_window_w - 80,
default_value=5,
min_value=self._min_val,
max_value=self._max_val,
callback=None,
)
# 処理時間
if use_pref_counter:
with dpg.node_attribute(
tag=tag_node_output02_name,
attribute_type=dpg.mvNode_Attr_Output,
):
dpg.add_text(
tag=tag_node_output02_value_name,
default_value='elapsed time(ms)',
)
return tag_node_name
def update(
self,
node_id,
connection_list,
node_image_dict,
node_result_dict,
):
tag_node_name = str(node_id) + ':' + self.node_tag
input_value02_tag = tag_node_name + ':' + self.TYPE_INT + ':Input02Value'
output_value01_tag = tag_node_name + ':' + self.TYPE_IMAGE + ':Output01Value'
output_value02_tag = tag_node_name + ':' + self.TYPE_TIME_MS + ':Output02Value'
small_window_w = self._opencv_setting_dict['process_width']
small_window_h = self._opencv_setting_dict['process_height']
use_pref_counter = self._opencv_setting_dict['use_pref_counter']
# 接続情報確認
connection_info_src = ''
for connection_info in connection_list:
connection_type = connection_info[0].split(':')[2]
if connection_type == self.TYPE_INT:
# 接続タグ取得
source_tag = connection_info[0] + 'Value'
destination_tag = connection_info[1] + 'Value'
# 値更新
input_value = int(dpg_get_value(source_tag))
input_value = max([self._min_val, input_value])
input_value = min([self._max_val, input_value])
dpg_set_value(destination_tag, input_value)
if connection_type == self.TYPE_IMAGE:
# 画像取得元のノード名(ID付き)を取得
connection_info_src = connection_info[0]
connection_info_src = connection_info_src.split(':')[:2]
connection_info_src = ':'.join(connection_info_src)
# 画像取得
frame = node_image_dict.get(connection_info_src, None)
# カーネルサイズ
kernel_size = int(dpg_get_value(input_value02_tag))
# 計測開始
if frame is not None and use_pref_counter:
start_time = time.perf_counter()
if frame is not None:
frame = image_process(frame, kernel_size)
# 計測終了
if frame is not None and use_pref_counter:
elapsed_time = time.perf_counter() - start_time
elapsed_time = int(elapsed_time * 1000)
dpg_set_value(output_value02_tag,
str(elapsed_time).zfill(4) + 'ms')
# 描画
if frame is not None:
texture = convert_cv_to_dpg(
frame,
small_window_w,
small_window_h,
)
dpg_set_value(output_value01_tag, texture)
return frame, None
def close(self, node_id):
pass
def get_setting_dict(self, node_id):
tag_node_name = str(node_id) + ':' + self.node_tag
input_value02_tag = tag_node_name + ':' + self.TYPE_INT + ':Input02Value'
kernel_size = dpg_get_value(input_value02_tag)
pos = dpg.get_item_pos(tag_node_name)
setting_dict = {}
setting_dict['ver'] = self._ver
setting_dict['pos'] = pos
setting_dict[input_value02_tag] = kernel_size
return setting_dict
def set_setting_dict(self, node_id, setting_dict):
tag_node_name = str(node_id) + ':' + self.node_tag
input_value02_tag = tag_node_name + ':' + self.TYPE_INT + ':Input02Value'
kernel_size = int(setting_dict[input_value02_tag])
dpg_set_value(input_value02_tag, kernel_size)
ちょっと追加で説明を書いていきます。コメントを細かめに追記🏃
インポート部分
# GUIライブラリのDearPyGui
import dearpygui.dearpygui as dpg
# 指定したDearPyGuiパーツから値を取得/設定するためのラッパー関数
from node_editor.util import dpg_get_value, dpg_set_value
# ノード用の抽象クラス
from node.node_abc import DpgNodeABC
# OpenCV形式の画像データからDearPyGui用のテクスチャに変換する関数
from node_editor.util import convert_cv_to_dpg
画像処理部分
特筆すべきことは無いのですが、、、
image_process() はクラスメソッドじゃないので、この関数名である必要はありません👻
update()の中でべた書きしても問題無し。
def image_process(image, kernel_size):
image = cv2.blur(image, (kernel_size, kernel_size))
return image
クラス変数部分
class Node(DpgNodeABC):
# ノードのバージョン
# インポート時にバージョンが異なると読み込みエラーとなる
_ver = '0.0.1'
# ノードのラベル
# メニューバーに表示される
node_label = 'Blur'
# ノードのタグ名
# ノードエディタ内でノードを識別するために使用される
# システム内でユニークな名称になっていなければいけない(重複するとエラー)
node_tag = 'Blur'
# クラス内で使用する定数定義
# 「_ver」「node_label」「node_tag」以外の変数は
# システム上、特別な意味を持つわけではないので必要に応じて作成
_min_val = 1
_max_val = 128
# node_editor/setting/setting.json の設定内容を保持するための変数
_opencv_setting_dict = None
コンストラクタ部分
特に無し。
ノード追加時ではなく、ノードエディタ起動時に実行したい処理があれば書く。
ただし、ここに処理を追加するとノードの使用有無に関わらず
ノードエディタの起動時間が長くなるため注意。
def __init__(self):
pass
ノード追加イベント部分
主にノードのGUIや初期化に関わる処理を書く部分。
基本的にはDearPyGuiのパーツを順次追加している個所なのですが、、、
ノードとノードの入出力名をユニークにするための命名を、
型名とコロン区切りの文字列を手でゴリゴリ書く形にしてしまったことを若干後悔。。。
もっと自動的な仕組みを考えるか、共通関数化しておけば良かった😇
tag_node_name = str(node_id) + ':' + self.node_tag
tag_node_input01_name = tag_node_name + ':' + self.TYPE_IMAGE + ':Input01'
def add_node(
self,
parent,
node_id,
pos=[0, 0],
opencv_setting_dict=None,
callback=None,
):
# タグ名
# ノード名は「ノードID」+「:」+「ノードタグ名」のルールで作成し
# システム上ユニークにする
tag_node_name = str(node_id) + ':' + self.node_tag
# ノードの入力名は「ユニークなタグ名」+「:」+「型名」+「:」+「InputXX」
# ここで指定した型と同じ型のノード出力のみ接続できる
# 'InputXX'は任意の名称で可
tag_node_input01_name = tag_node_name + ':' + self.TYPE_IMAGE + ':Input01'
# ノードの入力の値名は「ユニークなタグ名」+「:」+「型名」+「:」+「InputXXValue」
# 'InputXXValue'は任意の名称で可
tag_node_input01_value_name = tag_node_name + ':' + self.TYPE_IMAGE + ':Input01Value'
tag_node_input02_name = tag_node_name + ':' + self.TYPE_INT + ':Input02'
tag_node_input02_value_name = tag_node_name + ':' + self.TYPE_INT + ':Input02Value'
# ノードの出力名は「ユニークなタグ名」+「:」+「型名」+「:」+「OutputXX」
# ここで指定した型と同じ型のノード入力のみ接続できる
# 'OutputXX'は任意の名称で可
tag_node_output01_name = tag_node_name + ':' + self.TYPE_IMAGE + ':Output01'
# ノードの出力の値名は「ユニークなタグ名」+「:」+「型名」+「:」+「OutputXXValue」
# 'OutputXXValue'は任意の名称で可
tag_node_output01_value_name = tag_node_name + ':' + self.TYPE_IMAGE + ':Output01Value'
tag_node_output02_name = tag_node_name + ':' + self.TYPE_TIME_MS + ':Output02'
tag_node_output02_value_name = tag_node_name + ':' + self.TYPE_TIME_MS + ':Output02Value'
# OpenCV向け設定
self._opencv_setting_dict = opencv_setting_dict
# 'process_width'、'process_height'はノード上の小窓のサイズ
small_window_w = self._opencv_setting_dict['process_width']
small_window_h = self._opencv_setting_dict['process_height']
# 'use_pref_counter'は処理計測の使用有無
use_pref_counter = self._opencv_setting_dict['use_pref_counter']
# 初期化用黒画像
black_image = np.zeros((small_window_w, small_window_h, 3))
black_texture = convert_cv_to_dpg(
black_image,
small_window_w,
small_window_h,
)
# テクスチャ登録
with dpg.texture_registry(show=False):
dpg.add_raw_texture(
small_window_w,
small_window_h,
black_texture,
tag=tag_node_output01_value_name,
format=dpg.mvFormat_Float_rgb,
)
# ノード
with dpg.node(
tag=tag_node_name,
parent=parent,
label=self.node_label,
pos=pos,
):
# 入力端子
with dpg.node_attribute(
tag=tag_node_input01_name,
attribute_type=dpg.mvNode_Attr_Input,
):
dpg.add_text(
tag=tag_node_input01_value_name,
default_value='Input BGR image',
)
# 画像
with dpg.node_attribute(
tag=tag_node_output01_name,
attribute_type=dpg.mvNode_Attr_Output,
):
dpg.add_image(tag_node_output01_value_name)
# カーネルサイズ
with dpg.node_attribute(
tag=tag_node_input02_name,
attribute_type=dpg.mvNode_Attr_Input,
):
dpg.add_slider_int(
tag=tag_node_input02_value_name,
label="kernel",
width=small_window_w - 80,
default_value=5,
min_value=self._min_val,
max_value=self._max_val,
callback=None,
)
# 処理時間
if use_pref_counter:
with dpg.node_attribute(
tag=tag_node_output02_name,
attribute_type=dpg.mvNode_Attr_Output,
):
dpg.add_text(
tag=tag_node_output02_value_name,
default_value='elapsed time(ms)',
)
return tag_node_name
ノード更新イベント
作成されたノードの先頭から順に呼び出される。
ノードの表示更新や画像処理を行う部分。
ノード追加と同様、タグの解釈部分をもう少し関数化すれば良かったと後悔中。。。👻
update()の引数の「connection_list」「node_image_dict」「node_result_dict」には、
それぞれ以下の情報が入っている。
- connection_list:自ノードに関わる [ノードの出力, ノードの入力] のペアのリスト
例:[
['2:IntValue:Int:Output01', '3:Blur:Int:Input02'],
['1:WebCam:Image:Output01', '3:Blur:Image:Input01']
] - node_image_dict:各ノードの画像処理結果
例:{
'1:WebCam': array([[[255, 255, 255],
[255, 255, 255],
[255, 255, 255],
(略)
} - node_result_dict:物体検出結果などの画像以外の情報
例:{
'1:WebCam': None,
'2:ObjectDetection': {
'bboxes': [[440.2642517089844, 298.6780090332031, 899.7108154296875, 714.1022338867188]],
'scores': [0.8132189512252808],
'class_ids': [0.0],
(略)
}
def update(
self,
node_id,
connection_list,
node_image_dict,
node_result_dict,
):
tag_node_name = str(node_id) + ':' + self.node_tag
input_value02_tag = tag_node_name + ':' + self.TYPE_INT + ':Input02Value'
output_value01_tag = tag_node_name + ':' + self.TYPE_IMAGE + ':Output01Value'
output_value02_tag = tag_node_name + ':' + self.TYPE_TIME_MS + ':Output02Value'
small_window_w = self._opencv_setting_dict['process_width']
small_window_h = self._opencv_setting_dict['process_height']
use_pref_counter = self._opencv_setting_dict['use_pref_counter']
# 接続情報確認
connection_info_src = ''
for connection_info in connection_list:
connection_type = connection_info[0].split(':')[2]
if connection_type == self.TYPE_INT:
# 接続タグ取得
source_tag = connection_info[0] + 'Value'
destination_tag = connection_info[1] + 'Value'
# 値更新
input_value = int(dpg_get_value(source_tag))
input_value = max([self._min_val, input_value])
input_value = min([self._max_val, input_value])
# connection_list の接続先情報を元に値を上書き
dpg_set_value(destination_tag, input_value)
if connection_type == self.TYPE_IMAGE:
# 画像取得元のノード名(ID付き)を取得
connection_info_src = connection_info[0]
connection_info_src = connection_info_src.split(':')[:2]
connection_info_src = ':'.join(connection_info_src)
# 画像取得
frame = node_image_dict.get(connection_info_src, None)
# カーネルサイズ
kernel_size = int(dpg_get_value(input_value02_tag))
# 計測開始
if frame is not None and use_pref_counter:
start_time = time.perf_counter()
if frame is not None:
frame = image_process(frame, kernel_size)
# 計測終了
if frame is not None and use_pref_counter:
elapsed_time = time.perf_counter() - start_time
elapsed_time = int(elapsed_time * 1000)
dpg_set_value(output_value02_tag,
str(elapsed_time).zfill(4) + 'ms')
# 描画
if frame is not None:
texture = convert_cv_to_dpg(
frame,
small_window_w,
small_window_h,
)
dpg_set_value(output_value01_tag, texture)
return frame, None
ノード削除イベント
ノードの削除時の後処理を書く部分。
ノード追加時に何かリソースを確保した場合などは、ここに解放処理を書く。
def close(self, node_id):
pass
エクスポートイベント
エクスポート時の処理を書く部分。
エクスポート時に保持したいGUI上の設定値などをDict形式で返却する。
def get_setting_dict(self, node_id):
tag_node_name = str(node_id) + ':' + self.node_tag
input_value02_tag = tag_node_name + ':' + self.TYPE_INT + ':Input02Value'
kernel_size = dpg_get_value(input_value02_tag)
pos = dpg.get_item_pos(tag_node_name)
setting_dict = {}
setting_dict['ver'] = self._ver
setting_dict['pos'] = pos
setting_dict[input_value02_tag] = kernel_size
return setting_dict
インポートイベント
インポート時の処理を書く部分。
インポート時に復元したいGUI上の設定値などがあれば、エクスポートイベントとあわせて書く。
def set_setting_dict(self, node_id, setting_dict):
tag_node_name = str(node_id) + ':' + self.node_tag
input_value02_tag = tag_node_name + ':' + self.TYPE_INT + ':Input02Value'
kernel_size = int(setting_dict[input_value02_tag])
dpg_set_value(input_value02_tag, kernel_size)
長々と色々書きましたが、、、 追加したい処理に近いノードのスクリプトをコピーして改造するのが良いかも👀
その他
- からあげさんに、ノード追加のプルリクエストいただきました。
ありがとうございます🙌
IPNE(Image-Processing-Node-Editor)を使って画像処理フィルタのテスト中。グリグリ値をいじれるの楽しいですね。
— からあげ (@karaage0703) July 8, 2022
UIが分かりづらいし微妙かなと思いつつもPRhttps://t.co/H2rMFBiLZ5 pic.twitter.com/5Nnyjj4tdD - airpocketさんに、自作のアルファブレンドノードの作例をご連絡いただきました。
ありがとうございます🙌うぉーーーーー
— airpocket (@AirpocketRobot) December 15, 2022
せみ捕り名人からシリアル通信で音圧マップ流して、 @KzhtTkhs さん謹製のImage Processing Node Editor用に作った自作ノードでデータ受けて、これまた自作のアルファブレンドノードでカメラ画像とリアルタイム合成できた!
これは楽しすぎるー。
やはり @KzhtTkhs 様は神です!! pic.twitter.com/gzEPonhjzO -
motojinc25/WeDXという凄いツールがImage-Processing-Node-Editorを参考にしていただいたと聞いています🙌

- あと、風の噂ですが、、、
ROSのPub/Subを受け取って連携する改造をされている方もいるとか。。。👀
ROSとの連携もかなり面白い使い方だと思いますね🤔 - ちなみに僕は仕事で自作モデルを組み込んで検証ツールにしています🦔