この記事で作成できるもの
作れるもの: ひらがなを手書き → 候補表示 → タップで文字確定できるIME
- 手書きでひらがなを入力
- 認識候補を表示(複数)
- タップで確定→未確定文字列に反映
- かな漢字変換でN-best候補表示
1. PyTorch を使用してひらがなを識別するモデルを作成する
手書きひらがなの学習データを自作したいと考え、まずは tkinter の Canvas を使ってGUIアプリを作りました。マウスの左クリックを検知して線を描画し、ラベル付きの画像を jsonl形式 で保存できるようにしています。

しかし、マウス入力で「ひらがな1文字につき100枚」を作成していたところ、1時間で約500文字分 しか収集できず、作業効率に課題がありました。そこで、Android で手書きデータを保存できるアプリ を作れば、より効率的にデータを集められるのではないかと考えました。
一方で、データ量を確保するために tomoe_data のストローク情報も活用しています。tomoe_data を使って、1文字あたり6000枚 の画像を生成しました。生成時には、文字サイズの変更、ストローク長の変化、回転などの変換を加えてバリエーションを増やしています。
現在(2026年2月2日)使用しているモデルは、まず tomoe_data で学習したモデル を作り、その後、自分で作成した手書きデータを追加学習する、という手順で作成しました。
また、Android で PyTorch を使用したところ、16 KB ページサイズのサポートに関するエラーが発生し、Play Store にリリースできませんでした。そこで、PyTorch を NDK r29 で再ビルドして対応しました。
2. かな漢字変換エンジンを実装する
今回のプロジェクトでは、かな漢字変換エンジンを C++ で実装しました。辞書には mozc の OSS 辞書データ(dictionary_oss)を使用しています。
C++ を採用した理由は、将来的に 他のプラットフォームでも再利用できるようにするためです。かな漢字変換エンジン自体は以前 Kotlin で実装した経験があり、基本ロジックはそのまま移植しています。
実装は、読み・単語・中間テーブルを LOUDS 形式で辞書化し、それを使って変換用のグラフを構築します。探索には A* アルゴリズムを用い、スコアの低い順に複数の変換候補を取得できるようにしています。
3. 未確定文字列の実装
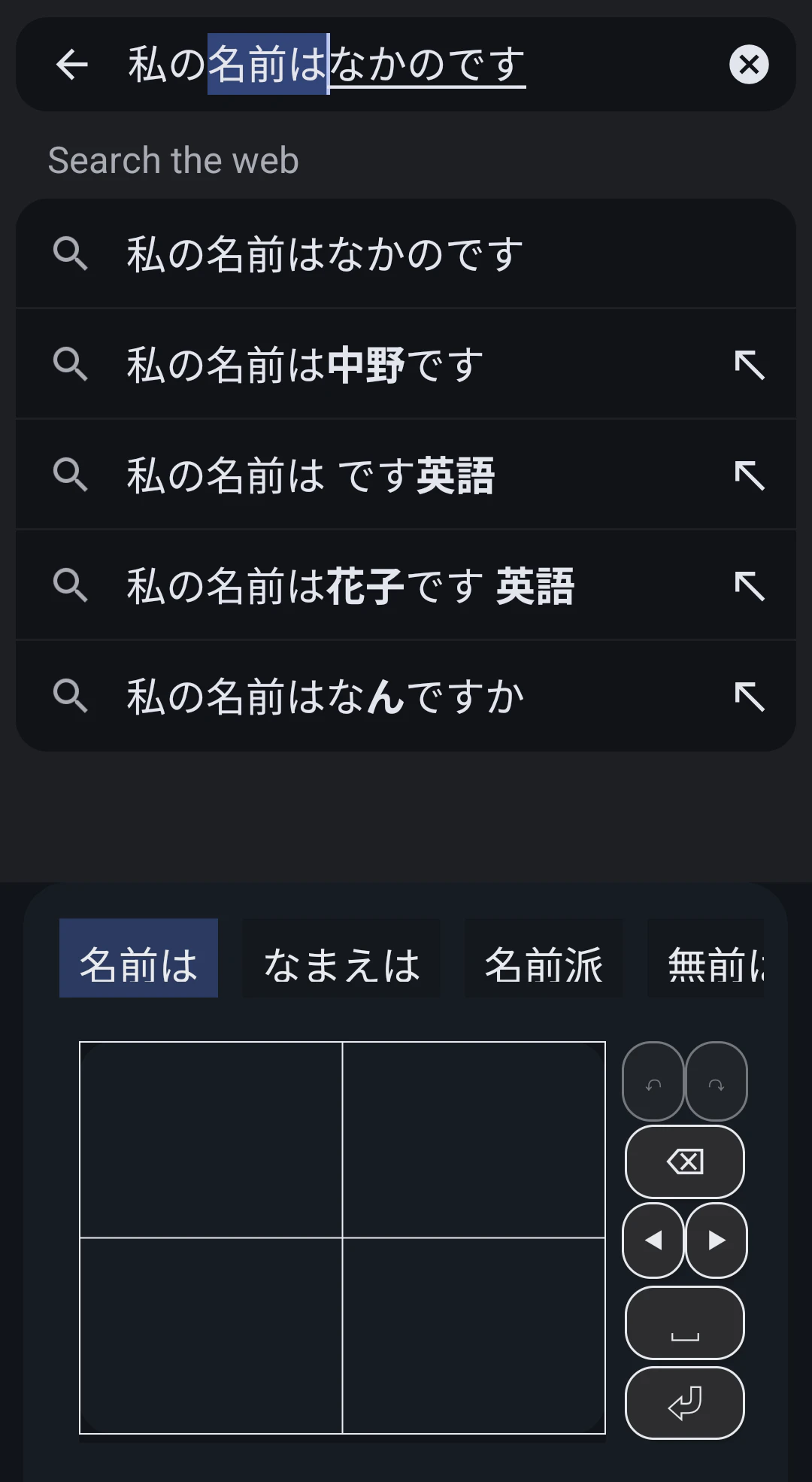
ユーザーが入力中のひらがな未確定文字列は、Spannableの bgRangeとulRangeでトラッキングしています。
-
bgRangeは青い背景付きの未確定文字列です。ユーザーが入力する文字は、常にbgRangeの末尾に追加されます。 -
ulRangeは 下線のみを付けた未確定文字列で、変換対象以外の文字列です。
また、カーソルキー操作に応じて bgRange と ulRange の範囲を入れ替えられるようにしています。さらに、変換候補が確定したタイミングで ulRange に文字列が残っている場合は、bgRange にその文字列を代入して、未確定状態の整合性を保つようにしています。
まとめ
本記事では、「ひらがなを手書き → 候補表示 → タップで文字確定できるIME」 を作るために取り組んだ全体像を紹介しました。
-
手書き認識(PyTorch)
tomoe_dataを使って生成したデータで事前学習し、その後 自作の手書きデータで追加学習する2段階で精度を底上げしました。
また、Android での配布を見据えると推論ライブラリの制約が出るため、PyTorchの16KBページサイズ問題に対応するためにNDK r29で再ビルドも行いました。 -
かな漢字変換(C++)
mozc の OSS 辞書(dictionary_oss)を使い、読み・単語・中間テーブルを LOUDS形式で辞書化して変換グラフを構築。探索は A* を用いて、スコアの低い順に 複数候補(N-best) を返せるようにしています。 -
未確定文字列
入力中の未確定状態はSpannableのbgRange/ulRangeで管理し、カーソル操作・確定タイミングでも状態が破綻しないように整合性を保つ設計にしました。