TL;DR
-
ST_SnapToGridにより、素朴にポリゴンで集計するより500倍くらいコストを小さく出来た(所要時間ではないことに留意)
-- 3次メッシュで集計する例
CREATE TABLE grid_agg AS (
WITH points AS (
-- 最近傍のグリッドにスナップされるので、各点がメッシュの中心となるようなグリッドを定義する
SELECT ST_SnapToGrid(
geom,
(1 * 0.0125) * 0.5, (0.666666666 * 0.0125) * 0.5, -- origin = origin_pos - size / 2
1 * 0.0125, 0.666666666 * 0.0125 -- size
) as geom
FROM poi
)
SELECT
-- メッシュの中心の座標からメッシュを図形を作成する
ST_MakeEnvelope(
ST_X(geom) - (1 * 0.0125) * 0.5,
ST_Y(geom) - (0.666666666 * 0.0125) * 0.5,
ST_X(geom) + (1 * 0.0125) * 0.5,
ST_Y(geom) + (0.666666666 * 0.0125) * 0.5
) as geom,
COUNT(geom) as count
FROM points
GROUP BY geom
);
メッシュ集計について
- 素朴には以下の手順が考えられる:
- メッシュのポリゴンを作成する
- ポイントデータと空間結合する
- たぶんこの方法は遅い(ポリゴンを作成するのがめんどう・空間結合がかなりコストかかるはず)
- ポイントデータの集計にそういう行儀の良い方法を取る必要はないだろうから、
ST_SnapToGridを利用してポイントデータをグルーピングする手法をとってみる-
ST_SnapToGridで、定義したグリッドに地物を「寄せる」 - 寄せた後の地物で
GROUP BYし、COUNTで数を集計する
-
検証
-
一定の範囲内にポイントを作成する(ここでは100万ポイント。なお1000万ポイントでもリーズナブルな速度で動作した。1億だとそもそもポイントを作るのが大変だった。)
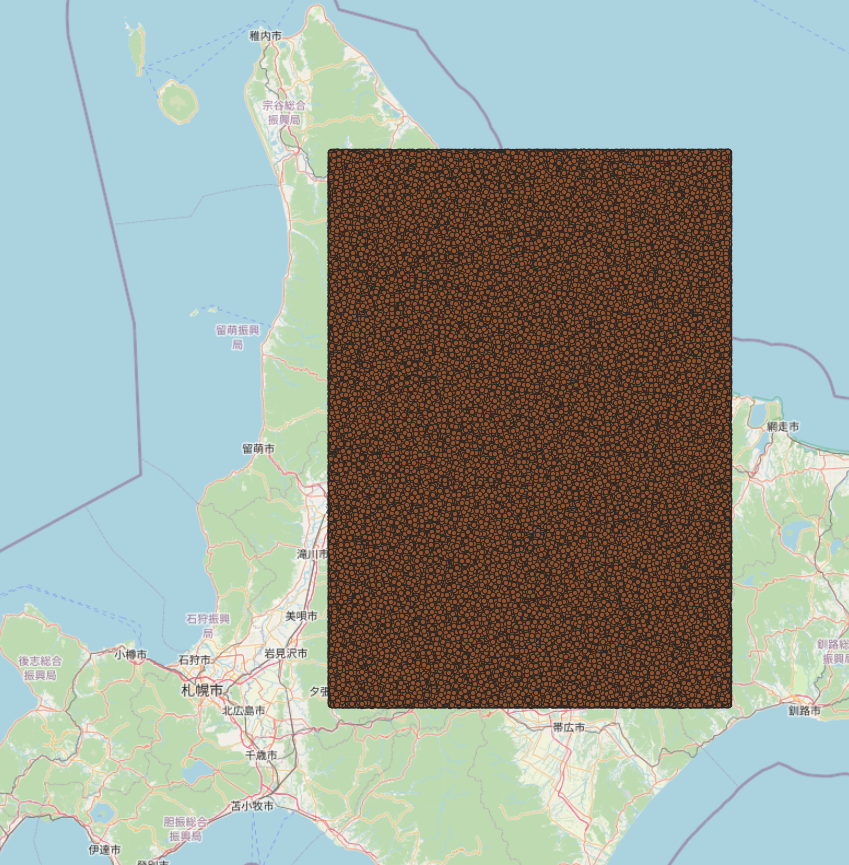 ©︎OpenStreetMap Contributors.
©︎OpenStreetMap Contributors. -
冒頭のSQLを実行する(1秒未満で完了する、cost=1106505.39)
QUERY PLAN -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- ----------- Finalize GroupAggregate (cost=114692.88..1106505.39 rows=1000000 width=72) Group Key: (st_snaptogrid(poi.geom, '0.00625'::double precision, '0.0041666666625'::double precision, '0.0125'::double precision, '0.008333333325'::double precision)) -> Gather Merge (cost=114692.88..322338.72 rows=833334 width=72) Workers Planned: 2 -> Partial GroupAggregate (cost=113692.85..225151.28 rows=416667 width=72) Group Key: (st_snaptogrid(poi.geom, '0.00625'::double precision, '0.0041666666625'::double precision, '0.0125'::double precision, '0.008333333325'::double precis ion)) -> Sort (cost=113692.85..114734.52 rows=416667 width=64) Sort Key: (st_snaptogrid(poi.geom, '0.00625'::double precision, '0.0041666666625'::double precision, '0.0125'::double precision, '0.008333333325'::double p recision)) -> Parallel Seq Scan on poi (cost=0.00..63610.04 rows=416667 width=64) JIT: Functions: 10 Options: Inlining true, Optimization true, Expressions true, Deforming true (12 rows)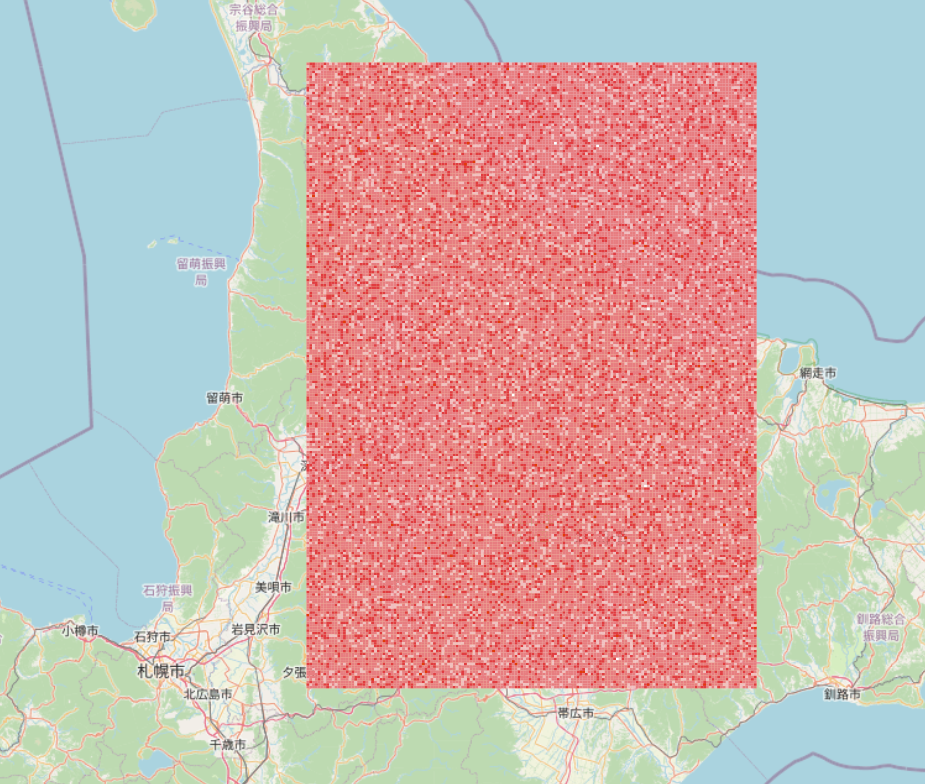 ©︎OpenStreetMap Contributors.
©︎OpenStreetMap Contributors. ポイントの疎密と見比べると集計できていそう
ポイントの疎密と見比べると集計できていそう
参考:ちゃんとポリゴンで集計する場合のコストを調べておく
-
3次メッシュのグリッドのテーブルを作成しておく(QGISの地域メッシュプラグインからPostGISに直接書き込めて便利だった)
-
グリッドのテーブルに空間インデックスを作成しておく(以下では
thirというテーブル、thirdをタイポした) -
SQLを実行する(cost=639598488.91、前述の手法の578倍)
CREATE TABLE grid_agg_poly AS ( SELECT thir.geom AS geom, COUNT(poi.geom) AS count FROM thir LEFT JOIN poi ON ST_Contains(thir.geom, poi.geom) GROUP BY thir.geom ); QUERY PLAN -------------------------------------------------------------------------------------------------------------- Finalize GroupAggregate (cost=639313115.89..639598488.91 rows=1126400 width=128) Group Key: thir.geom -> Gather Merge (cost=639313115.89..639575960.91 rows=2252800 width=128) Workers Planned: 2 -> Sort (cost=639312115.87..639314931.87 rows=1126400 width=128) Sort Key: thir.geom -> Partial HashAggregate (cost=624894942.36..639146644.15 rows=1126400 width=128) Group Key: thir.geom Planned Partitions: 16 -> Nested Loop Left Join (cost=0.29..588128721.15 rows=331413825 width=152) -> Parallel Seq Scan on thir (cost=0.00..27681.33 rows=469333 width=120) -> Index Scan using poi2_geom_idx on poi2 (cost=0.29..1252.06 rows=100 width=32) Index Cond: (geom @ thir.geom) Filter: st_contains(thir.geom, geom) JIT: Functions: 12 Options: Inlining true, Optimization true, Expressions true, Deforming true (17 rows)
参考リンク
宣伝
「位置エン本」に続く第2作、現場のプロがわかりやすく教える位置情報デベロッパー養成講座: デジタルマップ配信のためのサーバーサイド実装が2024年8月末に発売されます。PostGISの説明に注力しているほか、ラスター配信のテーマとして衛星データを取り扱っています。興味のある方はぜひ書店でご覧になってください。