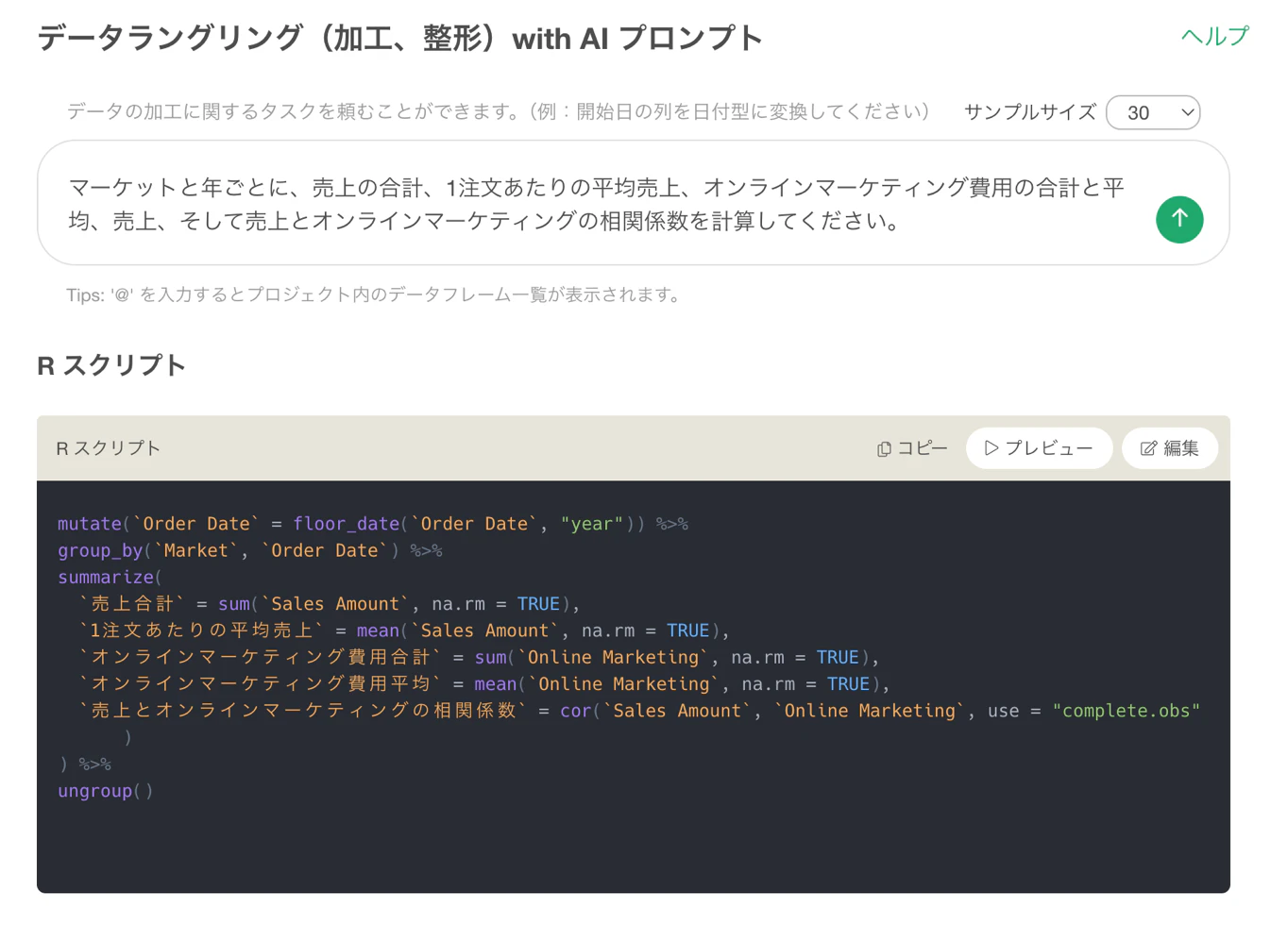
AIによって、データ分析のコードを書くハードルは大きく下がりました。
自然言語でやりたいことを説明すれば、RでもPythonでもSQLでも、かなり実用的なコードが生成されます。
これは、データ分析の世界にとって大きな変化です。
これまでデータ分析を学ぶには、ExploratoryのようなUIツールを使うか、あるいはR、Python、SQLなどのプログラミング言語を学ぶ必要がありました。
データを読み込み、加工し、集計し、可視化し、モデルを作る。
こうした処理を行うには、基本的にはコードを書く力が必要でした。
しかし今では、AIのプロンプトに向かって、こう聞けばよくなっています。
2020年以降のデータに絞って、地域ごとの売上合計を計算してください。
するとAIは、指定されたプログラミング言語、あるいは状況に応じた言語で、それらしいコードを生成してくれます。
では、AIがコードを書いてくれる時代に、私たちはもうプログラミング言語を学ぶ必要はないのでしょうか?
私は、むしろ逆だと考えています。
AI時代に重要になるのは、コードをゼロから書けること以上に、生成されたコードを読んで理解し、検証できることです。
特にデータ分析では、この力がとても重要になります。
なぜなら、データ分析では、コードが動くことと、分析結果が信頼できることは同じではないからです。
これは単なる理論上の懸念ではありません。
たとえば、2026年に行われた「State of Analytics Engineering」という、データに関わる仕事をしている人たちを対象にした調査では、「データに対する信用」を重要な課題として挙げる人の割合が、前年の66%から83%へと上昇しています。
また、シニア・ビジネスリーダーを対象とした別の調査では、回答者の98%がAI関連のデータ品質問題を経験したことがあると回答しています。
つまり、AI時代のデータ分析では、「AIが答えを出してくれる」こと以上に、「その答えを信頼できるのか」が大きな問題になります。
そして、分析結果を信頼するためには、その結果がどのようなプロセスで作られたのかを理解できなければなりません。
どのデータを使ったのか。
どの条件でフィルターしたのか。
どの単位で集計したのか。
欠損値や重複はどう扱ったのか。
どのテーブルと、どの条件で結合したのか。
こうした処理の多くは、コードの中に表れます。
つまり、AIが生成したコードを理解し、検証できなければ、そのコードによって作られた分析結果を本当の意味で信頼することはできません。
そして、コードを理解し検証するために重要になるのが、コードの可読性です。
この記事では、AI時代のデータ分析において、なぜ可読性が重要になるのか。そして、なぜR、特にtidyverseのコードがその点で強いのかを整理します。
データ分析にはあらかじめ用意された「正解」がない
機械学習の予測モデルでは、多くの場合、結果を評価するための明確な基準があります。
たとえば、分類モデルであれば正解ラベル(実測値)があります。
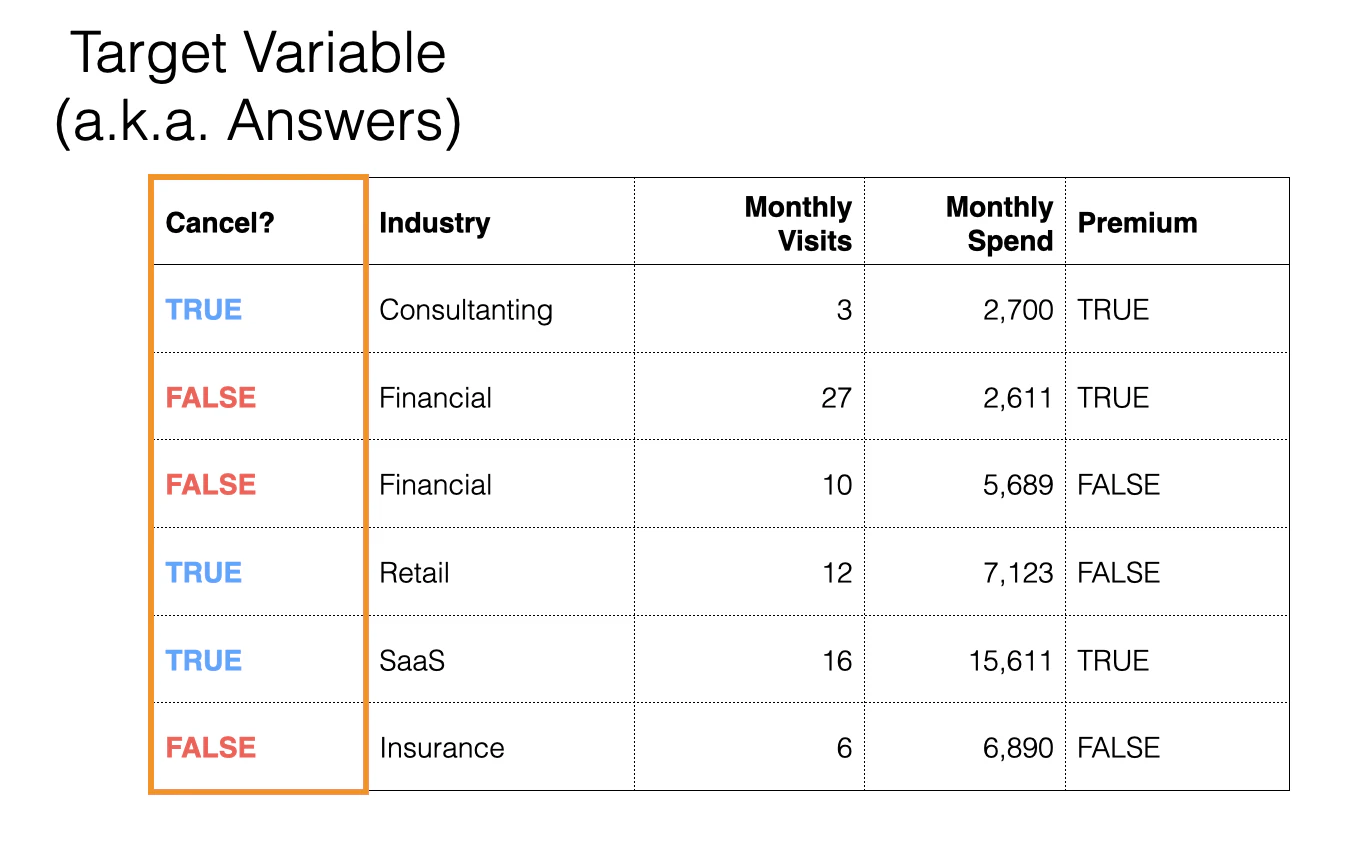
そして、精度、AUC、RMSEなどの指標を使って、モデルがどれくらいうまく機能しているかを評価できます。
一方で、データ分析は少し違います。
データ分析では、最初から明確な正解があるわけではありません。
たとえば、次のような問いを考えてみます。
なぜ今月の売上は下がったのか?
解約率が高い顧客にはどのような特徴があるのか?
マーケティング施策は本当に成果につながっているのか?
これらの問いには、あらかじめ用意された正解ラベルはありません。
データ分析とは、正解を当てにいくというよりも、データを探索しながら、納得できる答えを導いていくものです。
だからこそ、重要になるのは結果だけではありません。
その結果が、どのようなプロセスで作られたのか。
どのデータを使ったのか。どの条件でフィルターしたのか。どの単位で集計したのか。欠損値はどう扱ったのか。他のどういったデータと結合したのか。
こうしたプロセスを理解できなければ、最終的な結果を信頼することはできません。
AIがコードを生成してくれるようになっても、この問題はなくなりません。
むしろ、より重要になります。
なぜなら、自分で書いていないコードによって、分析結果が作られるようになるからです。
読めないコードは信頼できない
AIが生成したコードや分析結果は、一見すると正しそうに見えます。
しかしそれは、意図した分析が行われていることとは別のことです。
たとえば、次のような小さな違いが、分析結果を大きく変えてしまうことがあります。
- フィルター条件が少し違う
- グループ化の単位が違う
- 欠損値が自動的に除外されている
- 結合方法がinner joinになっている
- 日付の範囲が意図とずれている
- 重複データの扱いが違う
こうした違いは、コードを読めなければ気づけません。
つまり、AIがコードを書いてくれる時代には、人間の役割が変わります。
以前は、人間がコードを書く人でした。
しかしこれからは、人間はAIが生成したコードを読む人であり、検証する人になります。
そして、ここで重要になるのがコードの可読性です。
コードを読めなければ、結果を信頼することはできない。
これは、AI時代のデータ分析において非常に重要なポイントだと思います。
Rのコードは、問いに近い形で読める
たとえば、次のような分析をしたいとします。
2020年以降のデータに絞り、地域ごとの売上合計を計算する。
Rでは、次のように書けます。
sales %>%
filter(year >= 2020) %>%
group_by(region) %>%
summarize(total_sales = sum(sales))
ここで使っているのは、Rの中でもデータ分析で広く使われている tidyverse というパッケージ群の書き方です。
Rには、もともと備わっている基本機能、いわゆる「Base R」もあります。 ただし、現在のデータ分析の現場では、データの加工・集計・可視化をより読みやすく書くために、tidyverseがよく使われます。
この記事で「Rのコード」と言う場合、特に断りがない限り、R + tidyverseのコードを指します。
このコードは、プログラミングに詳しくない人でも、ある程度英語が分かれば、処理の流れを自然に追うことができます。
-
filter(year >= 2020)で、2020年以降のデータに絞る -
group_by(region)で、地域ごとにグループ化する -
summarize(total_sales = sum(sales))で、売上合計を計算する
つまり、コードの流れが、分析の意図にかなり近い形になっているのです。
「データを絞る → グループ化する → 集計する」という、分析者が頭の中で考える順番に近い形で、そのままコードとして表現されています。
同じことをPythonのpandasで書くと、たとえば次のようになります。
sales[sales['year'] >= 2020] \
.groupby('region') \
.agg(total_sales=('sales', 'sum')) \
.reset_index()
もちろん、このPythonコードも十分に実用的です。
Pythonやpandasが悪いという話ではありません。Pythonは汎用プログラミング言語として非常に強力ですし、機械学習や深層学習のエコシステムでは大きな強みがあります。
ただし、データ分析の処理を「人間が読んで検証する」という観点では、Rには独自の強みがあります。
Python/pandasのコードには、分析の意図そのものではなく、実装上の都合も少し見えています。
たとえば、次のような部分です。
-
sales['year']のような列アクセス -
agg(total_sales=('sales', 'sum'))という集計構文 -
.reset_index()というデータ構造を整える処理
これらは、分析の問いそのものではありません。
「2020年以降に絞って、地域ごとに売上を合計する」という問いを実行するために必要な、プログラミング上の手続きです。
一方で、Rのコードでは、その手続きが目立ちません。
分析のロジックが前面に出ます。
この違いが、AI時代には特に重要になります。
なぜなら、分析結果が信頼できるかどうか判断するには、AIが生成したコードを人間が素早く読み、その処理が意図通りかどうかを判断する必要があるからです。
なぜRは読みやすいのか
では、なぜRのコードは読みやすいのでしょうか。
理由はいくつもありますが、ここでは特に重要な3つに絞ります。
- ロジックとロジスティクスが分離されている
- ベクトル化が言語の前提になっている
- NSEによって列名を自然に扱える
順番に見ていきます。
1. ロジックとロジスティクスが分離されている
データ分析のコードには、常に2つの層があります。
ひとつは、ロジックです。
これは「何をしたいのか」です。
たとえば、次のようなものです。
2020年以降のデータに絞りたい。
地域ごとに集計したい。
売上の合計と購買回数を計算したい。
もうひとつは、ロジスティクスです。
これは「コンピューターにどう実行させるのか」です。
たとえば、次のようなものです。
- 列にどうアクセスするか
- 中間結果をどう保持するか
- インデックスをどう扱うか
- 出力の形をどう整えるか
データ分析のコードが読みにくくなるのは、多くの場合、このロジスティクスが前面に出てくるときです。
Rでは、データ操作の多くが動詞として表現されます。
filter()mutate()group_by()summarise()arrange()select()
これらは、分析者が頭の中で考えている操作に近い言葉です。
そのため、コードを読んだときに、実装の詳細よりも分析の流れが見えやすくなります。
先ほどのコードをもう一度見てみます。
sales %>%
filter(year >= 2020) %>%
group_by(region) %>%
summarize(total_sales = sum(sales))
このコードでは、処理の流れが上から下にそのまま読めます。
- データを受け取る
- 条件で絞る
- グループ化する
- 集計する
これは、分析者の思考の流れに近いです。
AIがこのようなコードを生成した場合、人間はそれを読んで、意図と合っているかを確認しやすくなります。
2. ベクトル化が言語の前提になっている
Rの大きな特徴のひとつに、ベクトル化があります。
ベクトル化とは、データを1行ずつ処理するのではなく、列全体やベクトル全体に対して一度に処理を適用できる仕組みです。

たとえば、売上を1.1倍したいとします。
Rでは、次のように書けます。
sales * 1.1
これは、salesに含まれるすべての値に対して、1.1倍の計算を適用します。
一方で、Pythonの通常のリストでは、次のように書きます。
[s * 1.1 for s in sales]
これは、1つの値を処理し、次の値に移るというループ処理が行われています。
さらに、条件付きの計算を考えてみます。
salesが100を超えている場合、10%割引を適用する。
Rでは、'ifelse' という条件付きの計算を行う関数を使って、次のように書けます。
ifelse(sales > 100, sales * 0.9, sales)
ここには、次の3つがそのまま表現されています。
- 条件:
sales > 100 - 条件を満たす場合:
sales * 0.9 - 条件を満たさない場合:
sales
これはExcelのIF関数と非常に近いものです。
先ほどのPythonの場合は、次のようになります。
[s * 0.9 if s > 100 else s for s in sales]
ただ、Pythonでは使うライブラリによって様々な書き方があり、例えば、pandasとNumPyというライブラリを使った場合は、Pythonでもベクトル化された処理は可能です。
df['sales'] = np.where(df['sales'] > 100, df['sales'] * 0.9, df['sales'])
ただし、Rではベクトル化が言語の基本的な前提になっているため、使うパッケージによって違う書き方や処理の仕方を覚える必要はありません。
そのためRの場合、分析者は自然に「行を1つずつ処理する」のではなく、「列全体に対して変換を行う」という考え方になります。
これは可読性にも大きく影響します。
というのも、データ分析では、多くの場合、私たちは頭の中で行単位の処理ではなく、列単位の変換を考えているからです。
例えば、売上列を変換する。日付列から月を取り出す。顧客ごとに集計する。カテゴリごとに平均を計算する。といった具合です。
ベクトル化が前提のRのコードは、この思考に近い形で書くことができるため、結果として人間にとってはともて読みやすいものとなります。
3. NSEによって列名を自然に扱える
Rの読みやすさを支えているもうひとつの重要な仕組みが、NSEと言われるものです。
NSEとは、Non-Standard Evaluationの略で、日本語では「非標準評価」と呼ばれたりします。
少し難しく聞こえますが、データ分析の観点では、次のように考えるとわかりやすいです。
データフレームの列名を、普通の変数のように書ける仕組み。
たとえば、売上からコストを引いて利益を計算したいとします。
Rでは、次のように書きます。
df %>%
mutate(profit = sales - cost)
これは、文字通り、
profitは、salesからcostを引いたもの。
といったものです。
列名を引用符で囲む必要はありません。
一方で、Python/pandasでは、一般的に次のように書きます。
df['profit'] = df['sales'] - df['cost']
df['sales']のように、毎回データフレーム名を指定し、列名をクオートで囲む必要があります。
このコードが難しいというわけではありませんが、Rの方が余計な記号や構造が少ないため、分析の意図を理解しやすくなります。
そしてこの違いは、処理が複雑になるほど大きくなります。
たとえば、地域ごとに平均売上を計算する場合、Rでは次のように書きます。
df %>%
group_by(region) %>%
summarise(avg_sales = mean(sales))
これは、そのまま次のように読むことができます。
region(地域)でグループ化し、salesのmean(平均)をavg_salesとして計算する。
同じ処理は、Python/pandasの場合、次のようになります。
df.groupby('region')['sales'].mean().reset_index(name='avg_sales')
ここでは、列名が文字列として指定され、さらにreset_index()のような構造調整も入ります。
繰り返しますが、これは単純にPythonが悪いとか良くないといった話ではありません。
ただ、AIが生成したコードを人間が読んで検証するという観点では、余計な構造が少なく、分析の意図に近いRのコードの方が有利だということです。
RにおけるNSEのサポートは、Rのコードを「計算手順」ではなく、「分析の表現」に近づけてくれるのです。
AI時代には「書く」より「読む」ことが重要になる
AIがコードを書いてくれる時代には、プログラミングの役割が変わります。
これまでは、プログラミングと言えば、主にコードを書くことでした。
しかし、AIがコードを生成できるようになると、人間にとってより重要になるのは、コードを書くことそのものではなくなります。
重要なのは、生成されたコードを読んで、理解し、検証し、必要に応じて修正できることです。
特にデータ分析では、これは非常に重要です。
なぜなら、分析結果には常に責任が伴うからです。
もしAIが生成したコードが、意図と少し違う条件でデータを絞っていたらどうでしょうか。
もし集計単位が思っていたものと違っていたらどうでしょうか。
もし欠損値や重複行の扱いが想定と違っていたらどうでしょうか。
コードが読めなければ、こうしたことに気づくことはできません。
しかし、ビジネスでは、出力された数字をもとに意思決定が行われ、出力されたチャートをもとに議論が進み、出力されたKPIをもとに施策が評価されるのです。
だからこそ、AI時代において可読性は単なる好みの問題ではありません。
それは、分析結果を信頼するための土台なのです。
可読性は、信頼性・再現性・インタラクティビティにつながる
これまで見てきたように、コードが読みやすいと、結果に対する信頼を向上することができます。
データの加工や分析の処理の流れを追い、自分の意図と合っているかを確認できるからです。
しかし、コードの可読性のメリットはそれだけではありません。
コードの可読性は、分析を再現性にも役立ちます。
同じ処理を来週、来月、別のデータに対してもう一度実行したいとき、コードが読めれば、そのコードを必要な箇所だけアップデートすることで、そのコード自体を再利用できます。AIに毎回頼んで新しいコードを生成してもらう必要はありません。
AIをふだん毎日のように使っている人であればわかると思いますが、同じ質問に対して、全く同じ答え(この場合はコード)が返ってくるとは限りません。
さらに、コードの可読性は分析をよりインタラクティブなものにするのにも役立ちます。
データ分析は、1回の処理で終わるものではありません。
ひとつの結果を見ると、次の問いが生まれます。
- 月別ではどうか?
- さらに、地域別ではどうか?
- マーケティング施策の前後で変化はあるか?
- さらに、新規顧客と既存顧客に分けると違いはあるか?
このように、データ分析は問いと答えを行き来する反復的なプロセスです。コードが読めれば、AIに毎回依頼し直し、返ってくる答えを待つ必要はありません。
- フィルターを少し変えてみる。
- グループ化の単位を変えてみる。
- 計算式を追加してみる。
そうした小さな変更を自分で直接コードに加えることで、即実行し、即確認することができます。
その結果、分析のスピードを思考のスピードに近づけることができるようになります。
私たちがExploratoryで重視していること
実は、この可読性による「信頼性」、「再現性」、そして「インタラクティブ性」という考え方は、Exploratoryを作るうえでも重要な前提になっています。
例えば、Exploratoryでは、自然言語でデータ加工の指示を入力すると、AIがRのコードを生成します。
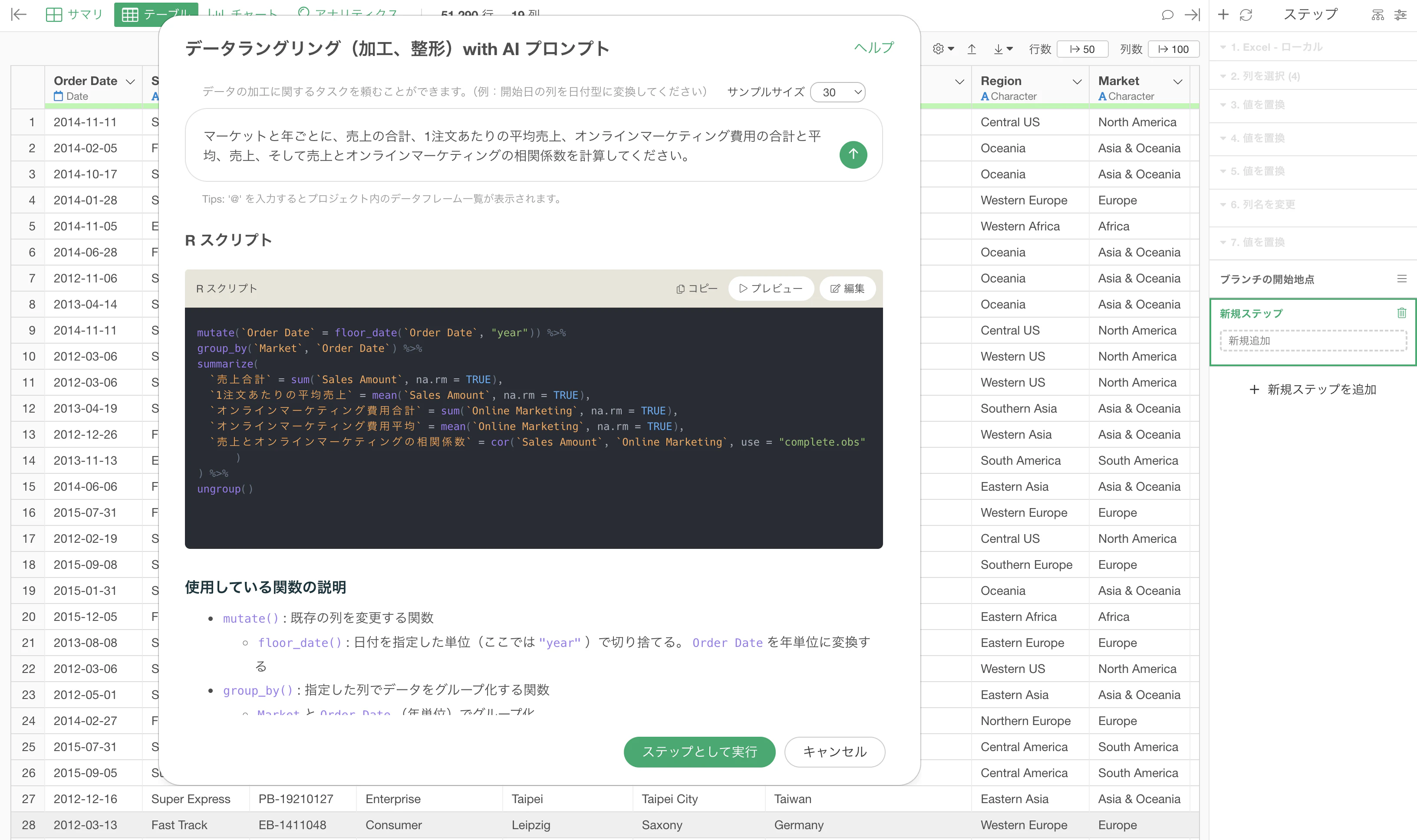
ただし、そのコードは裏側に隠されるわけではありません。
ユーザーが読める形で表示され、ユーザーが編集することもできます。
そして、実行したコードは、データラングリング(加工)のステップとして残ります。
つまり、AIで素早くコードを生成しながらも、その処理を確認し、修正し、再実行できるようになっています。
これは、AI時代のデータ分析では、コードを生成できること以上に、そのコードを読んで信頼できることが重要だと考えているからです。
まとめ
AIによって、コードを書くことはこれまでよりもはるかに簡単になりました。
しかし、データ分析において重要なのは、コードが書ける、または生成できることだけではありません。
そのコードが何をしているのかを理解できること。その結果を信頼できること。必要に応じて修正し、再利用できること。
こうしたことが、AI時代にはますます重要になります。
つまり、プログラミングが不要になるのではなく、むしろプログラミングの役割が変わるということです。
中心となる軸が**「コードを書くこと」ことから、「コードを読み、理解し、検証すること」へ変わる**ということです。
そして、この新しい世界におけるデータ分析やデータサイエンスにおいては、Rの可読性が大きな強みになるのです。
ロジックとロジスティクスが分離され、ベクトル化を前提にし、NSEによって列名を自然に扱えるRのコードは、データ分析の問いに近い形で読めます。
その結果、コードが機械への命令ではなく、人間の思考を表現するものに近づくのです。
AIがコードを書く時代だからこそ、読めるコードこそが、信頼できるデータ分析の土台になるのだと思います。
Exploratoryを使ってRの可読性を体験する
もし「AI時代には、コードを書くこと以上に、コードを読んで理解できることが重要になる」という考えに共感いただけたなら、ぜひ一度実際に試してみてください。
Exploratoryでは、データに対してやりたいことを自然言語で説明すると、AIによって「読みやすいRのコード」が生成されます。
そして、生成されたコードはそのまま確認でき、何をしているのかを理解しながら、分析を進めていくことができます。
AIに何度も「答え」を作り直してもらうのではなく、自分で分析の中身を確認し、修正し、少しずつ発展させていく、
そのようにデータ分析を進めていくことができます。
👉 Exploratoryをダウンロード
https://exploratory.io/download
まだアカウントをお持ちでない方は、こちらから登録して30日間の無料トライアルを始められます。
https://exploratory.io/
ご質問やフィードバックがあれば、いつでもお気軽にご連絡ください。
kan@exploratory.io