はじめに
TreasureDataを利用するとお気軽にHadoopなどのBigdata環境を利用できるのですが、RDB感覚で利用できるのが良い点と言えばよい点なのですが、RDBでもいいならMySQLとかでいいよね。って話なのでやっぱり苦手なこともあります。
とりあえずRDBしか触ったことないけどTreasureDataでクエリ書こうと思っている方向けに書いてます。
注)私はTreasureDataの中の人じゃないです。あしからず。
悪い例
とりあえずRDB使っていると下のようなSQLを書きたくなりますね。でも、あなたのBigDataって、テーブルの中に何億件のデータがありますか?よく考えて!
また、TreasureDataの内部の仕組みはtime別にストレージを区切って、さらにカラムナー型(カラムごとに縦割り)で保存しています。(詳しくはPlazma - Treasure Data’s distributed analytical database -)
そんなわけでとりあえずのビールじゃなくてとりあえずの「*(アスタリスク)」は絶対ダメ!
sample_datasets
select * from www_access
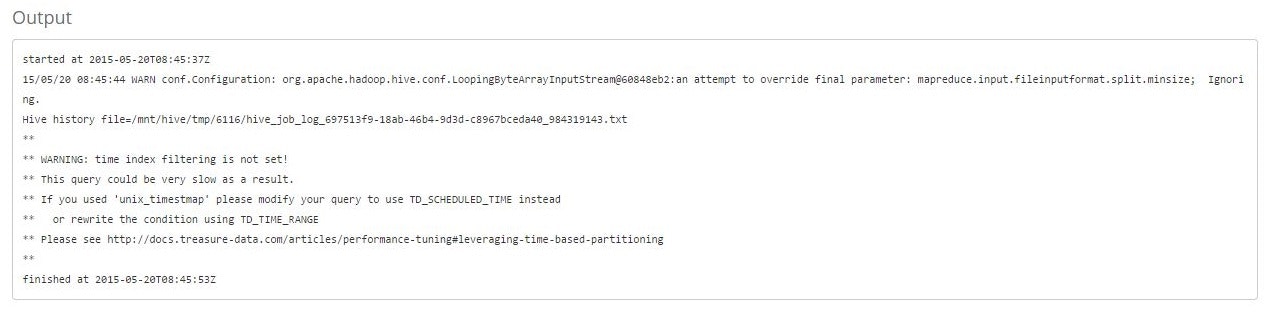
↑これがログですが、よく見ると下のようなエラーがでてます。
Output
**
** WARNING: time index filtering is not set!
** This query could be very slow as a result.
** If you used 'unix_timestmap' please modify your query to use TD_SCHEDULED_TIME instead
** or rewrite the condition using TD_TIME_RANGE
** Please see http://docs.treasure-data.com/articles/performance-tuning#leveraging-time-based-partitioning
**
翻訳します。
Output
警告:timeの指定されてないぞ!
このクエリって超遅くなる可能性があるよ。
もしも、unix_timestampってのを利用してtimeの条件を指定している気になっているなら、TD_SCHEDULED_TIME ってのがあるから書き直して。timeの範囲を指定したい場合はTD_TIME_RANGEってのがあるから使って。
てか、ドキュメントをもっかい見てね。
このクエリって超遅くなる可能性あるぞ!!
ドキュメントをもっかい見てね!
いい例
そんなわけで今回は1回目なので2点だけ
- SELECTの後ろは必要なカラム名だけを書こう!
- timeの条件指定を独自関数を利用してする!
sample_datasets
select time,user,host from www_access
where TD_TIME_RANGE(time,"2014-10-01","2014-10-31","JST")

あ、エラーが出なくなった。