はじめに
- 本記事は、Document Understanding の「正規表現ベースの抽出器」アクティビティの使い方を扱います。
- 記事の内容は、個人の見解または確認結果であり、UiPath の公式見解ではありません。
- 製品仕様や参考画像は 24.10 バージョンのもので構成しています。
「正規表現ベースの抽出器」

UiPath.IntelligentOCR.Activities パッケージに含まれるアクティビティで、「データ抽出スコープ」アクティビティの中に配置して使います。
開発者の方には使いやすく、AI Unit も消費しない(デジタル化と正規表現抽出器のアクティビティは無料です! ※DU契約はある前提)お勧めアクティビティなのですが、意外にもGoogle検索して使い方の記事がヒットしなかったので書きます。
使い方
まず、抽出までのミニマム構成は以下の様なかたちです。
(タクソノミー読み込みとデジタル化の部分の説明は省略します。)
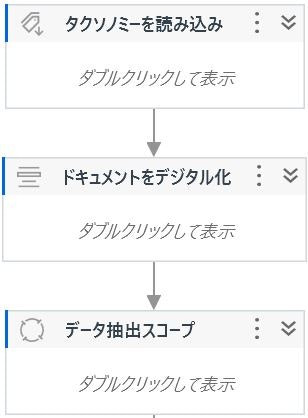
- タクソノミーの読み込み(あらかじめタクソノミーの設定が必要です。)
- デジタル化(「ドキュメントをデジタル化」アクティビティを使用)
- 正規表現抽出(「データ抽出スコープ」と「正規表現ベースの抽出器」アクティビティを使用)
「データ抽出スコープ」や「検証ステーションを表示」アクティビティの利用予定がない場合、タクソノミーの設定は不要のため、次のアクティビティでデジタル化したテキストで正規表現抽出することもできます。
「一致するパターンを探す」アクティビティ(旧名称:「一致する文字列を取得」)

データ抽出スコープの設定箇所は大きく次の3つ

➀:入出力の変数・引数を指定する
➁:正規表現の式を設定する
➂:使用する抽出器および項目を設定する
➀は見たままなので、➁と➂を詳細補足します。
式を設定(➁番)

式を設定したい項目の「編集」ボタンを押下します。

正規表現欄(※)から「カスタム」を選び、値に正規表現の式を入力します。
※:選択肢
- リテラル
- 数字
- 指定の文字
- 指定外の文字
- 任意の1文字
- 任意の英数字
- 空白
- 行頭
- 行末
- カスタム
- メールアドレス
- URL
- 米国形式の日付
- 米国形式の電話番号
正規表現が苦手な方は、「カスタム」ではなく、下図の様にオプションを一つずつ選んで設定してみてください。

「キャプチャ」オプションのチェックをONにしましょう!
あわせて、「正規表現ベースの抽出器」のプロパティの「視覚的配置を使用」も「True」にしましょう!

既定(False)の動作(仕様)がいまいちわかりませんが、このオプションをTrueにすることで私は期待結果を得られています。

正規表現オプションについて

指定できるオプションと意味
| オプション | 意味 |
|---|---|
| IgnoreCase | アルファベットの大文字と小文字を区別しない |
| Multiline | ^と$は、各行の行頭と行末に一致する。なお、指定しない場合は、^と$はテキスト全体の先頭と末尾のみに一致する |
| ExplicitCapture | 名前のない部分式はキャプチャしない |
| Compiled | 繰り返して実行する場合、検索速度が少し向上する |
| Singleline | .(ピリオド)が、改行文字にも一致する |
| IgnorePatternWhitespace | パターンに含まれる空白文字を無視する。また、パターン内の#文字以降もコメントとして無視する |
| RightToLeft | テキストを右から左の順で検索する |
| ECMAScript | ECMAScript(標準JavaScript)の正規表現エンジンと同じ動作となる。たとえば、\dは全角数字には一致しない |
| CultureInvariant | 自然言語に固有の事情を無視する。たとえば、トルコ語ではiの大文字がIではないため、大文字と小文字を区別しない検索で意図しない結果となる場合がある |
上記のオプション説明は津田先生の公式ガイドを参考にさせていただきました。
公式ガイドを購入したい方はこちら!
抽出器を設定(➂番)
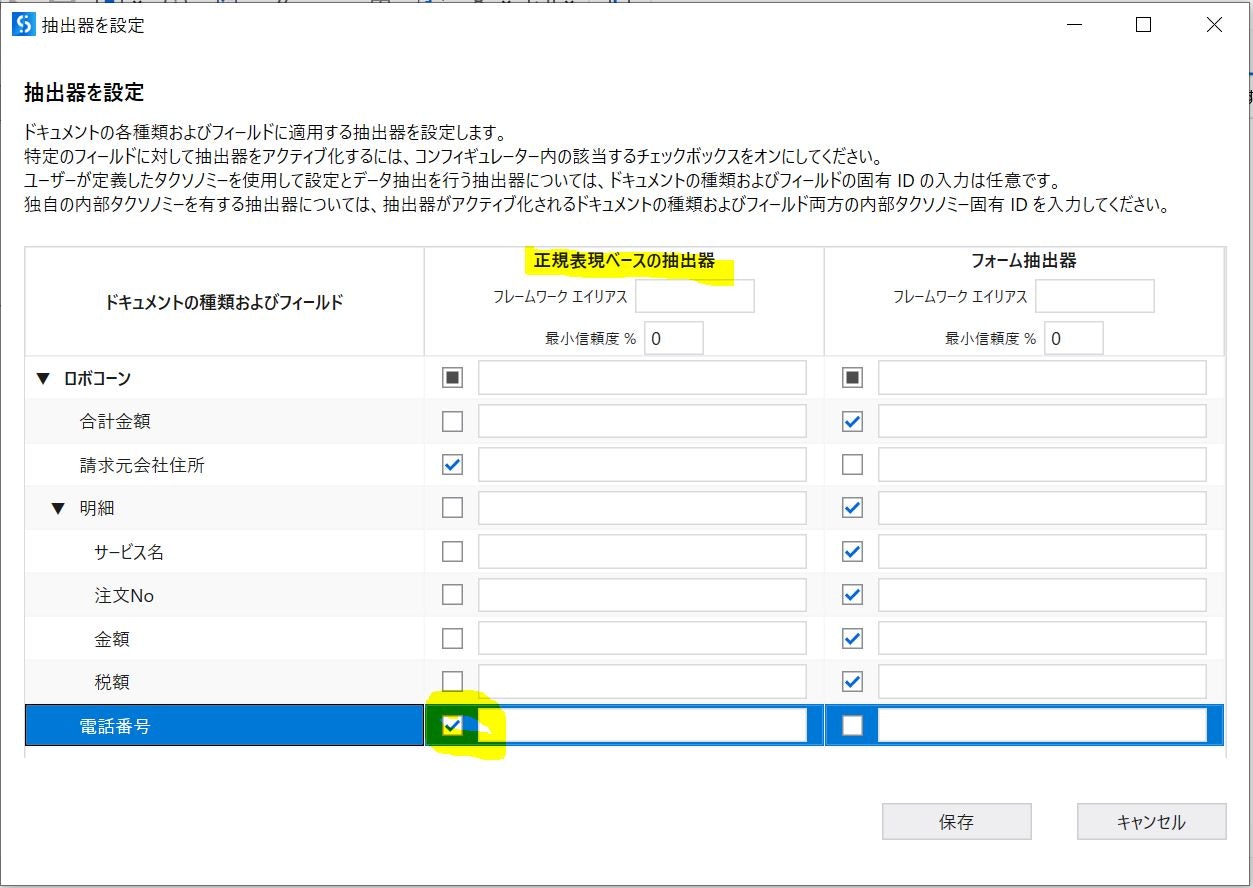
正規表現で抽出したい項目のチェックをONにします。
フォーム抽出器やマシンラーニング抽出器など、他の抽出器と併用した(他の抽出器もチェックをONにした)際の挙動ですが、下図の様にフォーム抽出器が信頼度86%であっても、正規表現抽出器で値がとれた場合は正規表現抽出器の結果が優先されます。
(フォーム抽出器単体)

(併用)

補足:正規表現で結果が2件とれてきたため、1件あたりの信頼度は50%
なお、正規表現とフォーム抽出器ともに最小信頼度を80%に指定すれば、正規表現抽出器で値がとれなくなるため、フォーム抽出器の86%のもの1件となります。


さいごに
いかがでしたでしょうか。
定型フォーマットのドキュメントであれば、正規表現抽出だけでも事足りることもあるかとおもいます。
まだ触ったことがない方は是非使ってみてください。
最後までお読みいただきありがとうございます(・ω・)ノ