はじめに
- 本記事は、Document Understanding のExtended Language OCR で帳票(スキャンデータ)を読むときの適当なサイズ感の有無を確認した際のメモを載せています。
- 記事の内容は、個人の見解または確認結果であり、UiPath の公式見解ではありません。
- 製品仕様や参考画像は 24.10 バージョンのもので構成しています。
検証に使った画像データ
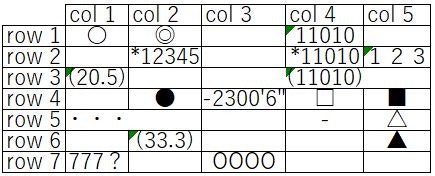
標準 Mサイズ 531*291 実寸
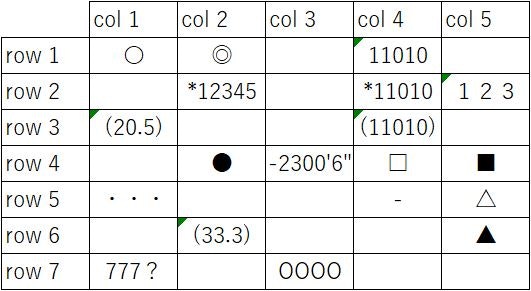
フォント小(6pt) Mサイズ 561*224 実寸
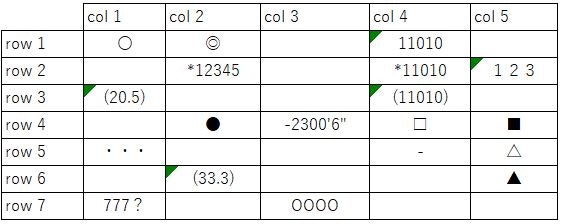
罫線被り Mサイズ 435*176 実寸
検証結果
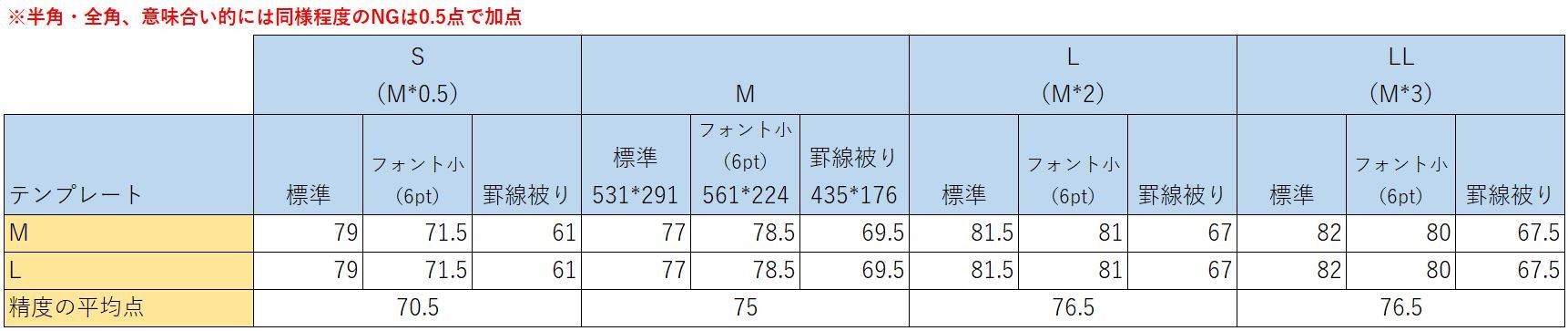
✔ 入力ファイルのサイズを大きくすることで精度が向上する
上例のMサイズのキャプチャに加え、50%のSサイズと200%のLサイズ、300%のLLサイズを用意して精度を確認しました。
その結果、Sサイズでは想定通り読み取り精度は低下しましたが、目視レベルでは十分読み取れそうな標準サイズより、大きくリサイズしたLおよびLLサイズで精度の向上を確認しました。
(Sサイズのサンプル 実寸)
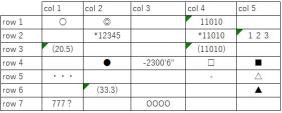
(Lサイズのサンプル ※クリックして実寸をご確認ください)
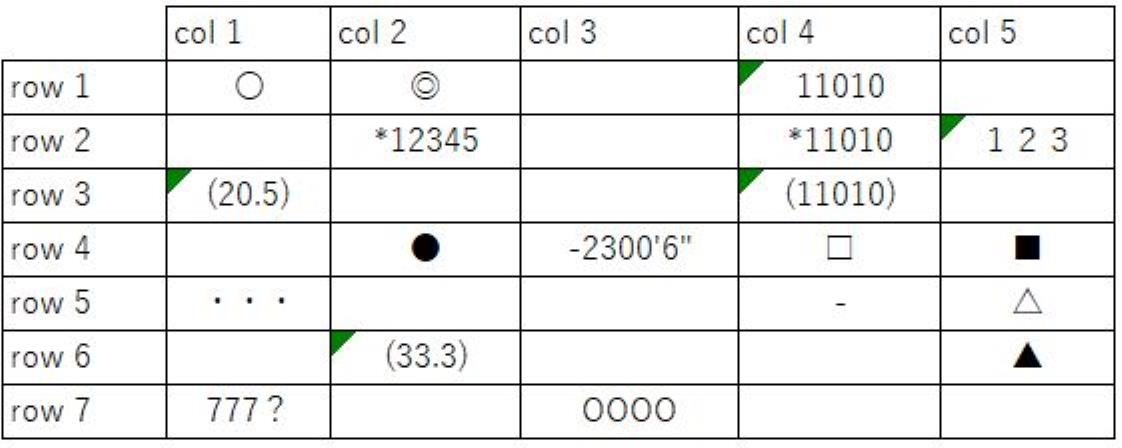
✔ テンプレートの設定は、入力ファイルのサイズに応じて自動拡張・縮小される?
今回の検証では、テンプレートはMとLの2サイズを用意しておこないました。
意外なことに、すべての組み合わせにおいて、テンプレートにもちいた画像サイズが精度に与える影響は確認できませんでした。
※SサイズやLLサイズのテンプレートは試してませんが、それらのサイズでテンプレートの設定自体おこなうことは実際にはないと想像します。
基本的には、精度は入力ファイル(画像ファイル)のサイズに依存する。
このため、リサイズのロジックを追加実装したからといって、必ずしもテンプレートの設定を作り直す必要はなさそうです。
✔ 罫線と文字の間に余白がある場合、"半角英数字"は極小文字も正確に読める
(Mサイズの50パーセントのため)フォントが6ptより小さい次の画像についても、半角英数字は正しく読めている
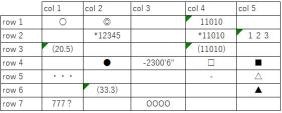
画像および文字が小さい場合、
記号や特殊文字(今回例では「・・・」「?」「〇」「◎」「(括弧)」「□」「■」「-(ハイフン)」「△」「▲」)
はほとんど読めません。
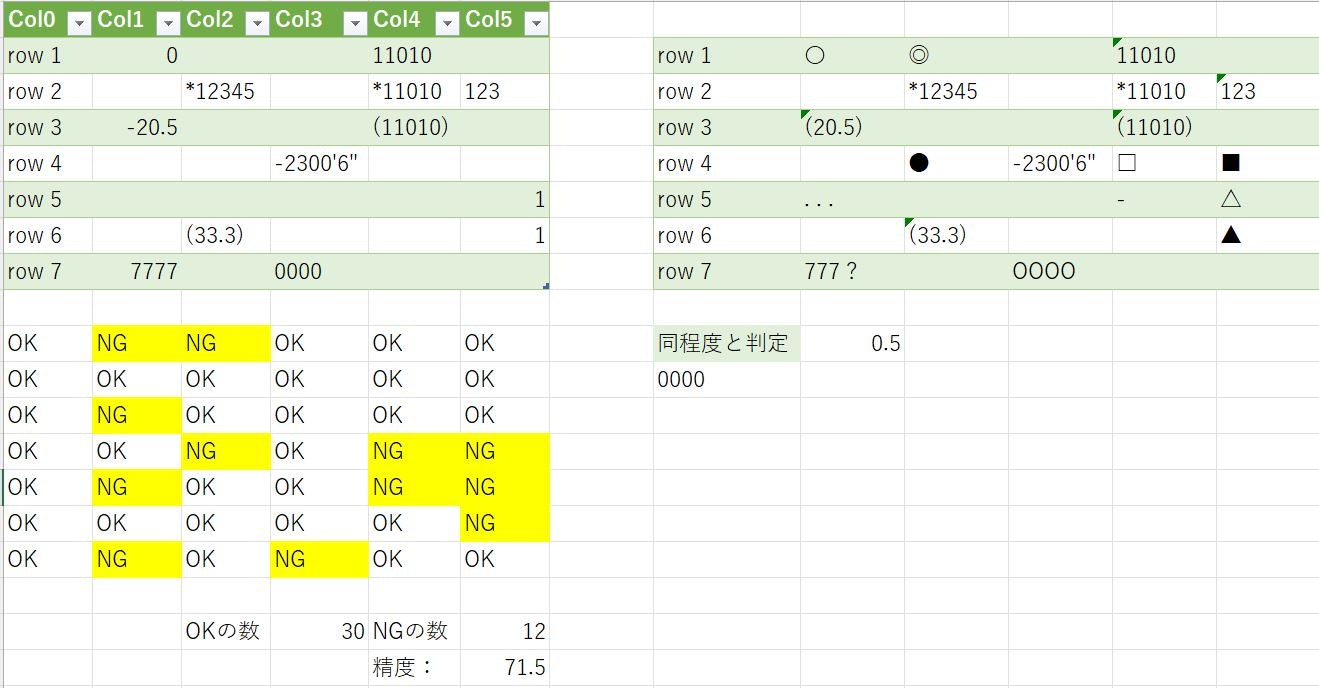
✔ 極大サイズ(LL)でも読めない記号がある
極大サイズでも次の記号や特殊文字は読めません。
今回例では「◎」「■」「△」「▲」
※「■」を「☒」で読んだ箇所は0.5加点しています。
✔ 文字の一部が罫線と被っている、または罫線が近くにあると起きる事象
-
例1 正解

-
例1 誤り

-
例2 正解
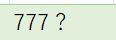
-
例2 誤り

-
例3 正解

-
例3 誤り

-
例4 正解

-
例4 誤り

-
例5 正解

-
例5 誤り

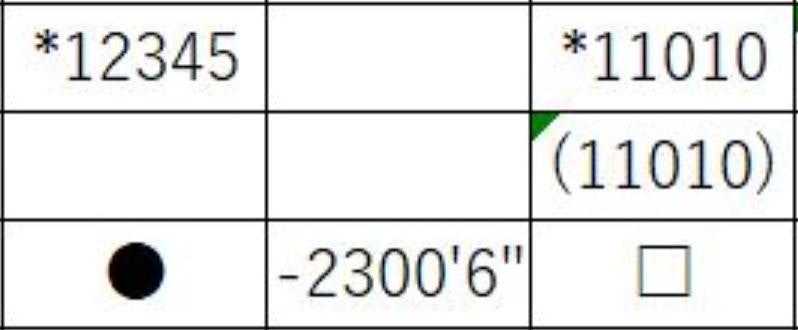
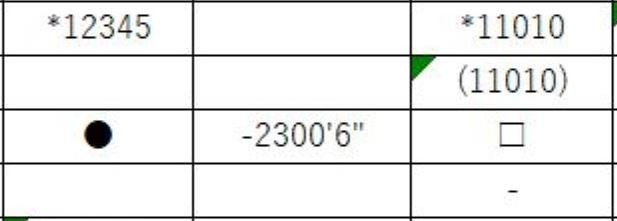
✔ 適当なサイズ感は?
LサイズとLLサイズでは精度の平均点は変わらないため、80点を超えてる画像データから実寸の参考画像(一部)を以下に載せます↓↓
標準のLLサイズ
フォント小のLサイズ
さいごに
いかがでしたでしょうか。
個人的には、入力ファイルのサイズを変えるときはテンプレートの設定直しが必須だと思い込んでたので、入力ファイルのサイズに合わせて自動拡大・縮小してくれてそうな点に気付けたのと、かなり小さい文字でも半角英数字なら安定して読めるのがわかったことが収穫でした!
最後までお読みいただきありがとうございます(・ω・)ノ