はじめに
- 本記事は、IXPを分類器として利用する方法を扱います。
- 記事の内容は、個人の見解または確認結果であり、UiPath の公式見解ではありません。
- 製品仕様や参考画像は2026年4月21日時点(先行環境)のもので構成しています。
IXPで分類するメリット
通常、UiPathでAIをもちいた分類処理をおこなう場合、Agent Builder を利用するかとおもいます。
こちらは王道ですが、次の様なケースではIXPで分類した方が得することが多いので、該当する方は最後までお読みいただければとおもいます。
- Studio Web でワークフローを開発している
- ドキュメントファイルを渡して分類処理をしたい
- 入力ファイルに複数のドキュメント(請求書、領収書、他)が含まれることがある
何故上記のケースだと得するかと言いますと、
まず、ライセンスの観点でお得です。
- Agent:標準モデルの1LLMコール → 1 + ファイル分析ツール(Analyze Files)の1LLMコール → 1 = 計 2 エージェントユニットを消費します。
-
IXP:1ページ 1 AIユニットを消費します。
※厳密には エージェントユニット ≠ AIユニット のため、単純比較はできませんが、トークン数でユニットを追加消費する Agent よりIXPの方が課金料を計算しやすいのもメリットですね

デスクトップのStudioで開発する場合、デジタル化をあらかじめおこなっておくことでファイル分析ツール(Analyze Files)の1LLMコールは省略できます。
次に、複数ページのドキュメントで、異なるタイプのドキュメントを含む場合、前処理で1ページ毎に分割するのが一般的ですが、IXPで分類と抽出をセットでおこなってしまえばファイル分割工程も省略できるのです!
(タクソノミー例)
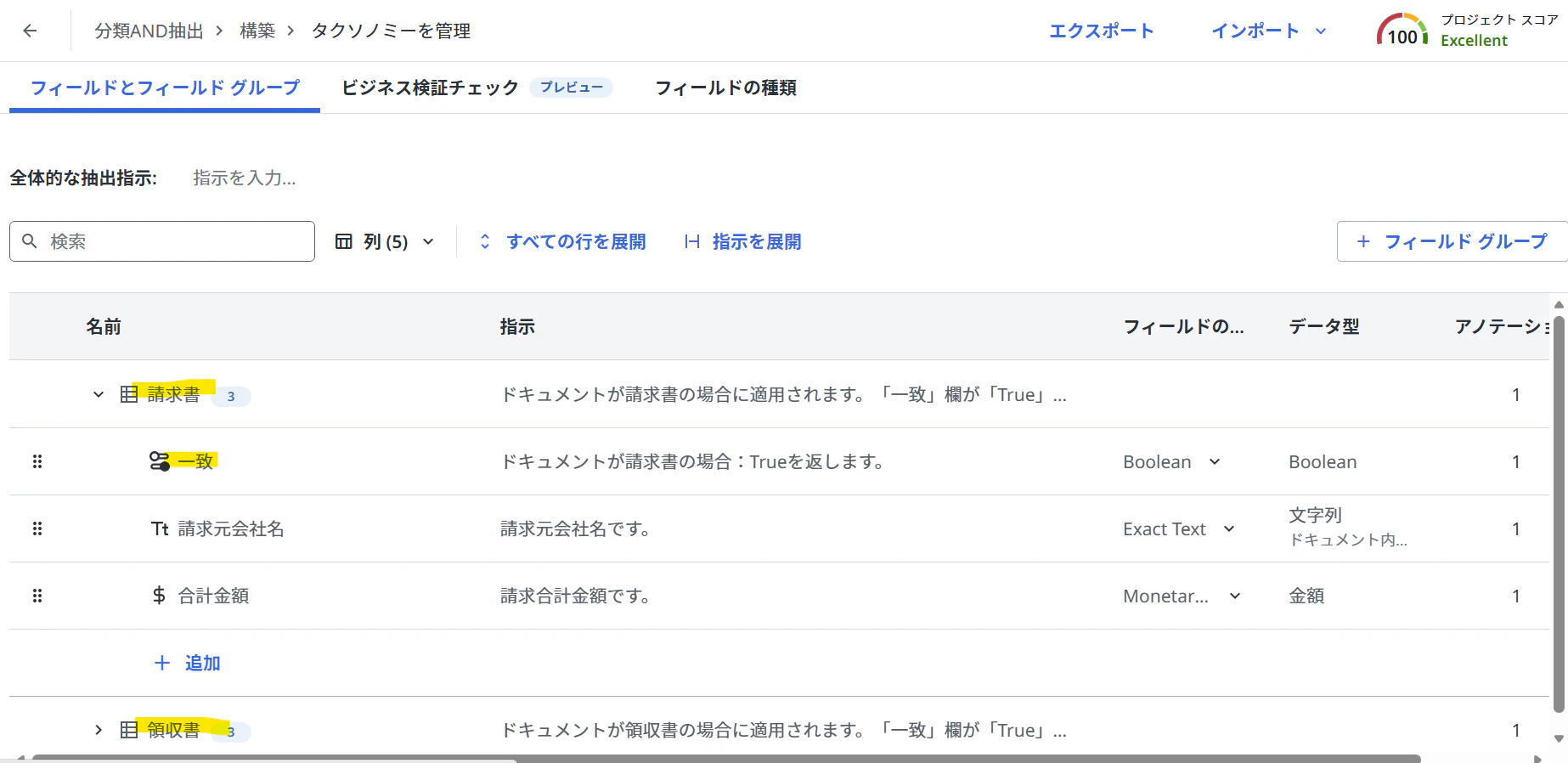
- フィールドグループ1:ドキュメントが〇〇の場合に適用されます。「一致」欄が「True」の場合に他のフィールドの値を抽出します。「False」の場合は空を返却してください。
- 一致:ドキュメントが〇〇の場合:Trueを返します。
- 任意フィールド
- フィールドグループ2:ドキュメントが□□の場合に適用されます。「一致」欄が「True」の場合に他のフィールドの値を抽出します。「False」の場合は空を返却してください。
- 一致:ドキュメントが□□の場合:Trueを返します。
- 任意フィールド
(実装例)
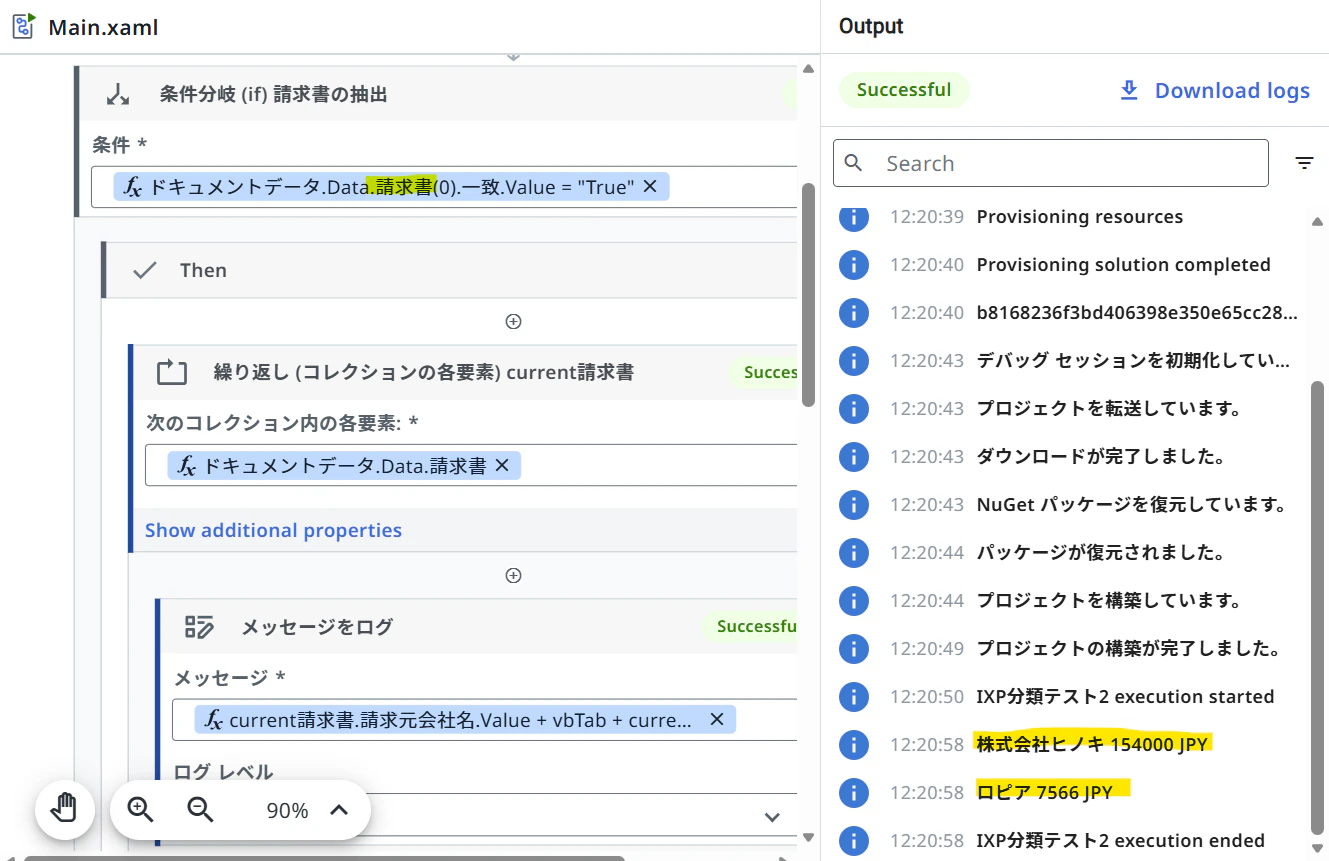
ドキュメントデータ.Data.{フィールドグループ名}.一致.Value = "True"
の様に、パッと見でわかりやすいソースを記述できます。
さらに、これが最推しポイントですが、
出力されるデータオブジェクトの構造がブレない点です。
どんなに制御文をしっかり記述してもLLMの出力がブレることってありますよね?わたしは今日もエージェント案件で悩まされています。
IXPで分類・抽出すれば
エージェントの出力をParseする処理エラーとか、壊れたJSONの逆シリアル化エラーとかとはおさらばです!
分類器に特化するならこんな感じ?
間取り図の画像ファイルを分類するシンプルな例を一つ
(タクソノミー例)
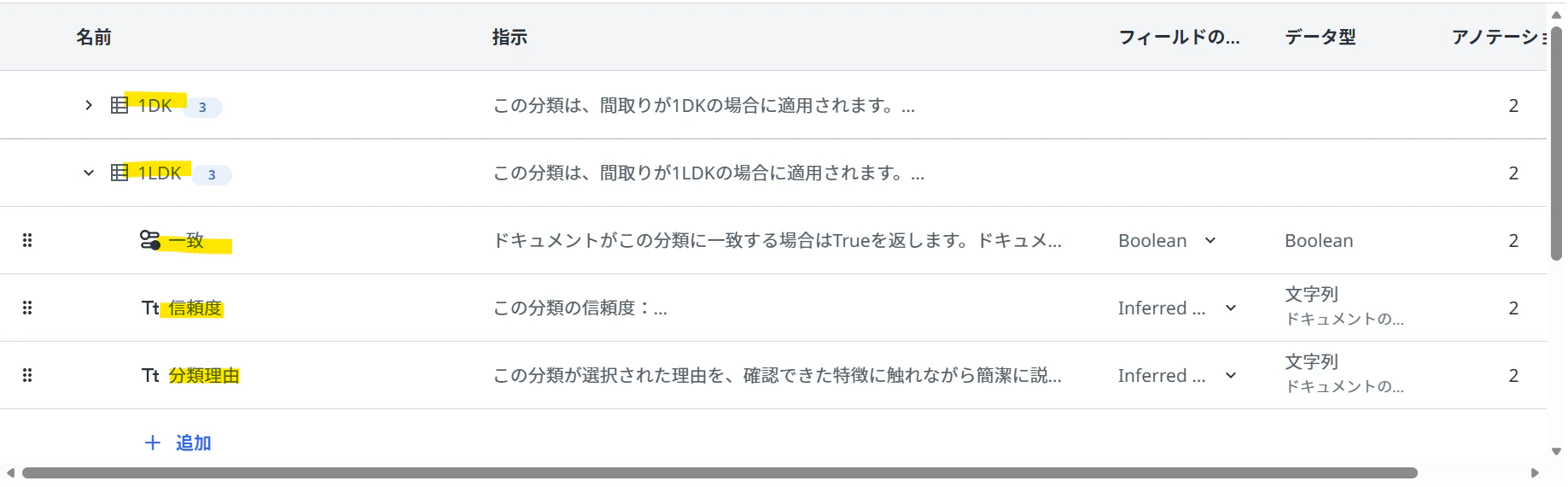
- 1DK:この分類は、間取りが1DKの場合に適用されます。
- 一致:ドキュメントがこの分類に一致する場合はTrueを返します。ドキュメントのどの部分もこの分類に一致しない場合のみFalseを返します。
- 信頼度:この分類の信頼度:\n高=明確な特徴あり。\n中=いくつかの特徴はあるが弱い。\n低=ほとんど一致しないか、極めて特徴が弱い。
- 分類理由:この分類が選択された理由を、確認できた特徴に触れながら簡潔に説明します。
- 1LDK:この分類は、間取りが1LDKの場合に適用されます。\n補足:1DKはDKの面積が8畳未満。LDKは8畳以上でソファやリビングテーブルを配置できます。
- 一致:ドキュメントがこの分類に一致する場合はTrueを返します。ドキュメントのどの部分もこの分類に一致しない場合のみFalseを返します。
- 信頼度:この分類の信頼度:\n高=明確な特徴あり。\n中=いくつかの特徴はあるが弱い。\n低=ほとんど一致しないか、極めて特徴が弱い。
- 分類理由:この分類が選択された理由を、確認できた特徴に触れながら簡潔に説明します。
(レスポンス例 - Dataプロパティ)
{
"_1DK": [
{
"一致": {
"Value": "True",
"Confidence": 0.9381582,
"OcrConfidence": -1.0
},
"信頼度": {
"Value": "高",
"Confidence": 0.99571484,
"OcrConfidence": -1.0
},
"分類理由": {
"Value": "間取り図には「洋室6帖」と「キッチン6帖」が示されており、DKの面積が6畳であるため、1DKに分類されます。",
"Confidence": 8.3489605E-05,
"OcrConfidence": 0.29
}
}
],
"_1LDK": [
{
"一致": {
"Value": "False",
"Confidence": 0.99899894,
"OcrConfidence": -1.0
},
"信頼度": {
"Value": "低",
"Confidence": 0.9901047,
"OcrConfidence": -1.0
},
"分類理由": {
"Value": "間取り図には「洋室6帖」と「キッチン6帖」が示されており、LDKの条件である8畳以上のリビングダイニングキッチンではないため、1LDKには該当しません。",
"Confidence": 3.9897746E-05,
"OcrConfidence": 0.29
}
}
]
ドキュメントデータを抽出の出力(IDocumentData)からの分類結果・分類理由の取得方法↓↓
//分類結果の取得(「一致」欄が True で「信頼度」が『高』で最初にヒットしたフィールドグループ名を取得)
Newtonsoft.Json.Linq.JObject.Parse(Newtonsoft.Json.JsonConvert.SerializeObject(documentData.Data)).Properties().Where(Function(p) p.Value.Any(Function(x) x("一致")("Value").ToString() = "True" AndAlso x("信頼度")("Value").ToString() = "高")).Select(Function(p) p.Name).FirstOrDefault()
//分類理由を取得
Newtonsoft.Json.Linq.JObject.Parse(Newtonsoft.Json.JsonConvert.SerializeObject(自動分類結果.Data)).Properties().SelectMany(Function(p) p.Value).Where(Function(x) x("一致")("Value").ToString() = "True" AndAlso x("信頼度")("Value").ToString() = "高").Select(Function(x) x("分類理由")("Value").ToString()).FirstOrDefault()
さいごに
いかがでしたでしょうか。

ガイド上、1200フィールドまでは安定的に値取得ができると書いてあるので、単純計算で300帳票くらいまでであれば分類できるかもしれません。
※300帳票分もタクソノミー定義するなんて現実的な運用ではないのであり得ませんが(笑)
たまに特殊なプロンプト指示をしなければならないレイアウトがある、とかであれば
分類と抽出をセットでおこなえば1個のモデルで済みますしメリットありますね(*´ω`)
最後までお読みいただきありがとうございますm(_ _)m