はじめに
- 本記事では、インテリジェント キーワード分類器の挙動(仕様)を確認した際の備忘禄です。
- 記事の内容は、個人の見解または確認結果であり、UiPath の公式見解ではありません。
- 製品仕様や参考画像は 23.10 バージョンのもので構成しています。
インテリジェント キーワード分類器とは?
インテリジェント キーワード分類器は、UiPath Document Understanding の機能の一つで、特定のドキュメントファイルから学習した単語ベクトルを使用して、入力されたドキュメントの分類を実行します。
Studio 上に 「分類スコープ」と「インテリジェントキーワード分類器」アクティビティ を配置・設定することで分類を実行できます。
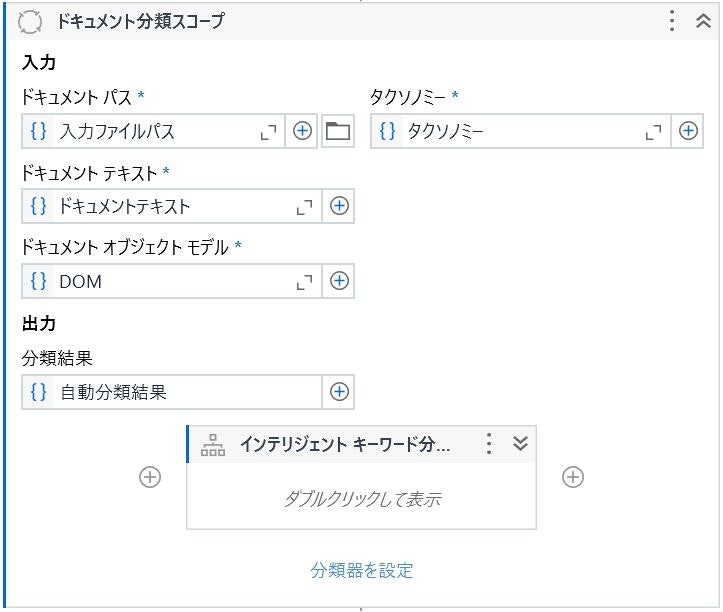
ドキュメントのトレーニングは「インテリジェントキーワード分類器」アクティビティの 「学習を管理」 のリンクよりおこなえます。
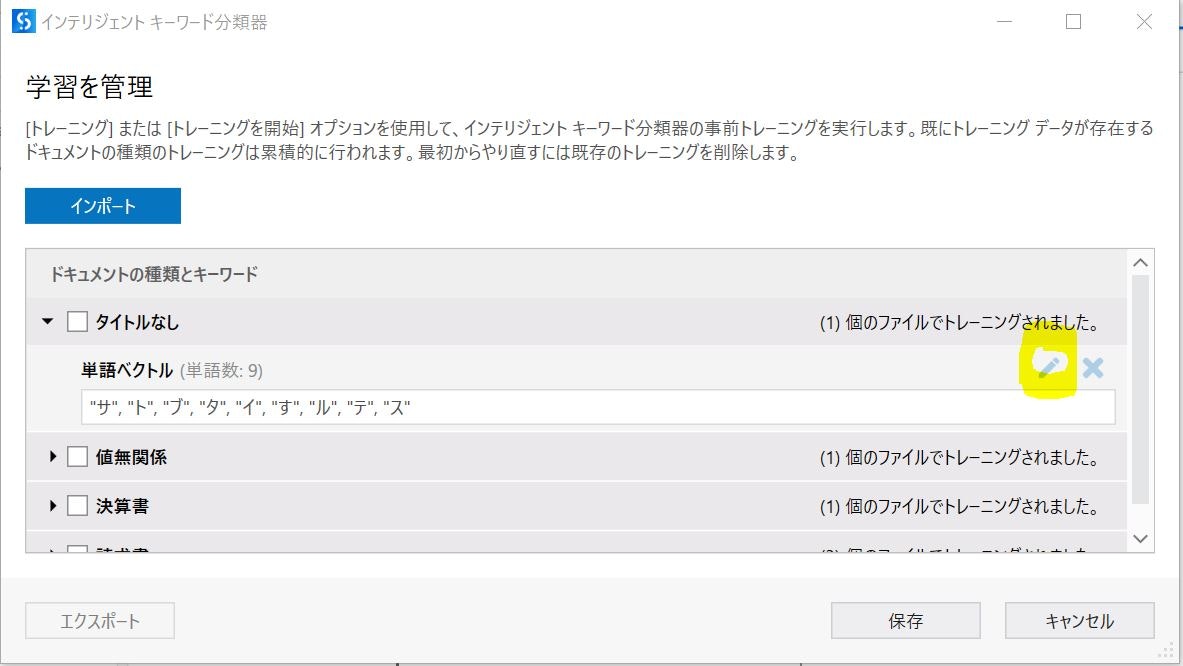
「キーワード分類器」とは異なり、設定値をマニュアルで修正することはできません。
ドキュメントを読み込ませることでトレーニングをおこないます。
キーワード分類器を詳しく知りたい方は次の記事をご参照ください。
https://qiita.com/tomohiroArai/items/07a39515068c7b6e492b
インテリジェントキーワード分類器は学習結果をローカル(※)に保持します。
※:{プロジェクトフォルダ}\DocumentProcessing\IntelligentKeywordClassifierLearningFile.json
学習結果はどんな内容?
シンプルに、キーワード毎のスコアを保持しています。
たとえば、請求書っていうドキュメントを定義して、2枚ほどOCRでサンプルを学習したときのサンプルイメージを以下に貼ります↓↓
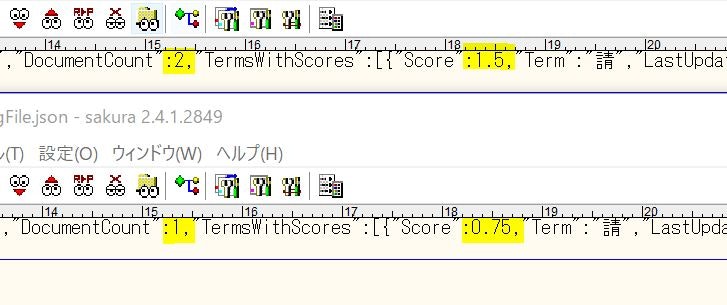
1ファイル学習後の「請」の字のスコアが「0.75」
2ファイル学習後が「1.5」
1回の学習で得られるスコアについては、手元の結果を見る限り、確度が高いものが0.7~0.8、低いものだと0.2くらいまで下がります。
学習する度に、このスコアはキーワード単位で加算されていきます。
(上の請求書の例でいえば、100ファイル学習したらスコアは75とかになります。(おそらく))

スコアはページ上に出現するのが早い、また出現回数が多いものが高くなる(「サブタイトルです。テストです。」という文章の学習結果で「サ」の次が「ト」になっているが、これは「ト」の出現回数が2回のため。「す」も同様。)
スコアは高ければ高いほどよいのか?
いいえ!!(答えはNOです)
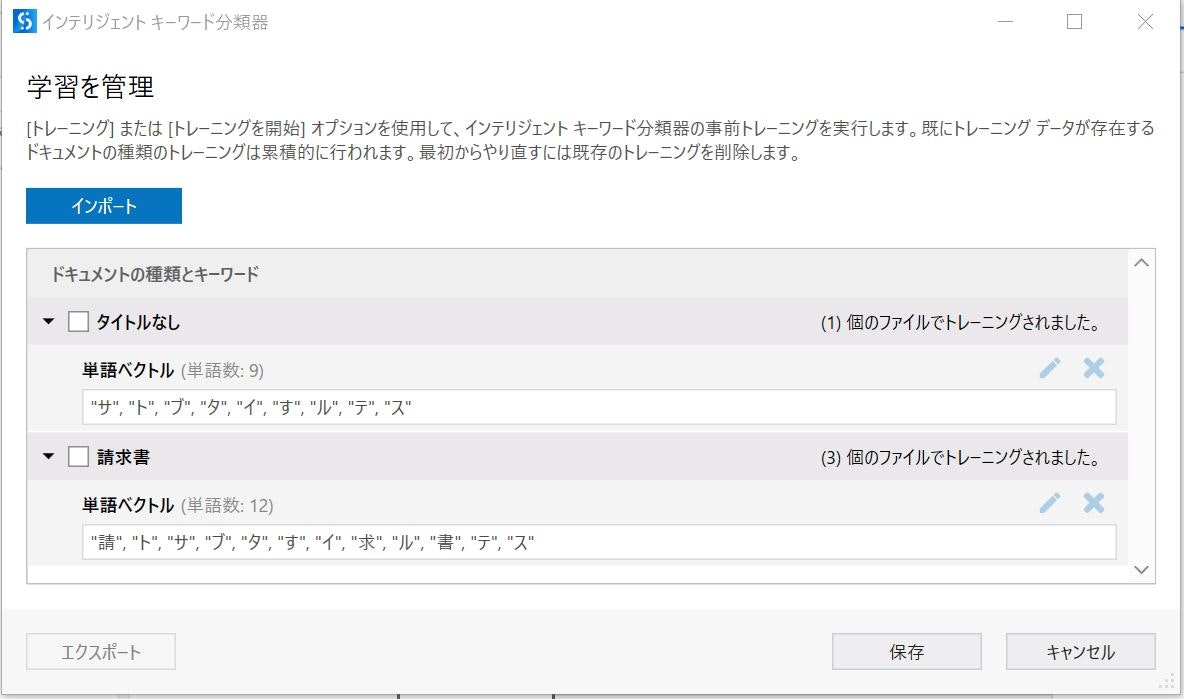
タイトルに「請求書」や「請」といった文字を含んで学習したドキュメント種類:『請求書』は「サ」の文字のスコアが「1.92」です。
これに対して、ドキュメント種類:『タイトルなし』の「サ」の文字スコアは「0.75」です。
「請」の字を含まないドキュメントを入力した場合、スコアが優先されるとしたら、ドキュメント種類:『請求書』に分類されるはずですが、正しく『タイトルなし』に分類されます!
スコアより、最初に一致したキーワードの順位が高いものが優先される
スコアは低くても、学習されていれば分類されるのか?
おそらくいいえ!(答えはNOです)

『値無関係』というドキュメント種類をつくり、「test」というキーワードを含めて学習させます。「test」は最低スコアの「0.18」で学習された状態です。
ここに対して「hogehoge test」という文字を含んだドキュメントを入力します。
すると、「ClassificationResult[0] { }」で分類されないのです!
だがしかし、「ほげほげテストです。 これでどうなる?? test」で入力すると分類されるのです!!
そこで、どのドキュメントにも「テスト」というキーワードは学習させているため、「テスト」で入力してみると分類されないのです!
実際のユースケースでは問題ないとおもいますが、入力ファイルに含まれる文字数(キーワード数)が10個未満だと学習済みでも分類されない可能性があります。
学習スコア・順位ともに高いが分類されない。。。
まず、デジタル化の結果をご確認ください。
PDFとOCRでは、キーワードの認識単位が異なります。
PDFであれば、およそ単語単位でキーワード認識されますが、OCR(CJK-OCR)では1文字ずつ結果が返却されます。
このため、「"請","求","書"」が学習済みであっても『請求書』で入力された場合は一致しません。(分類されません)
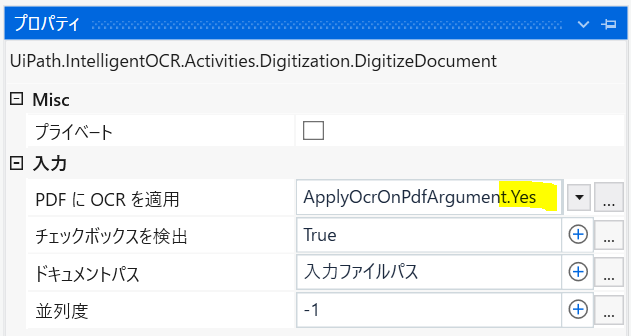
学習済みデータが「"請","求","書"」の様に1文字単位の場合、「ドキュメントをデジタル化」のプロパティの「PDFにOCRを適用」に「Yes」を指定することで1文字単位で比較することもできます。
さいごに
スコアの計算ロジックの詳細はわかりませんが、およその傾向・特徴などは上記でご理解いただけるかなとおもいます。
インテリジェントキーワード分類器をはじめて利用される方の参考になればと書かせていただきました。
以上 最後までお読みいただきありがとうございます(・ω・)ノ