1.はじめに
UiPathでは通常のRobot Processに加えて、高度な文書処理製品であるDocument Understanding(以降「DU」と略す)が海外では注目を集めています。今回はその中の機能の1つである文章の分類機能にフォーカスをしていきたいと思います。
分類機能については、いくつかの選択肢が用意されており、昨今注目の生成AIを利用した分類機能もありますが、今回はキーワードベースの分類器に着目してお話をしていきたいと思います。

キーワードベースの分類器に着目する理由としては以下の特徴があるため、利用がしやすいのではないかと考えているためです。
- AI Unitsというライセンスを保有していなくても利用ができる。※
- キーワードを登録する形となるため、直感的な利用ができる。
※デジタル化(ドキュメントファイルから文字情報に変換)する際には、OCRエンジンの種類によって必要な場合があります。
2.分類器とは
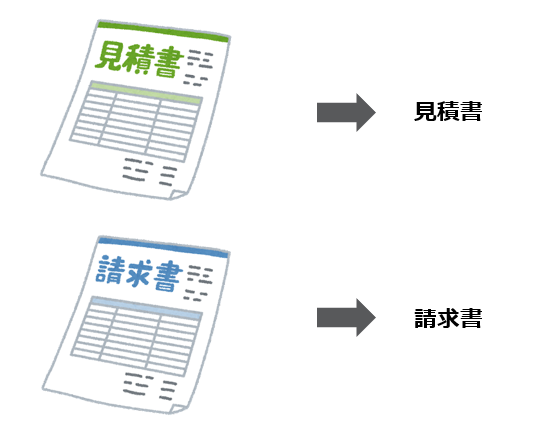
帳票をみて、人が判断するのと同じく、どんな帳票であるかを判断する機能のことを指します。
以下の例では見積書は「見積書」、請求書は「請求書」と分類する機能となります。
3.キーワードベースの分類器の主な仕様
3-1.デジタル化した文字列との完全一致が条件
キーワードとして登録された文字列にデジタル化した文字列が 完全一致 した場合にのみ分類することができます。
デジタル化した文字列とは以下に示す矩形認識した結果の文字列となります。
【PDF埋め込みされた文字を利用した場合 OCR適用Auto/No】
以下の図の右の例では2つの文字列がキーワードとして判断されます。

ワイルドカードやあいまい検索のような設定方法は利用できません。
例えば、「株式会社」がキーワードに登録されていても上記の例では分類されません。
【条件:画像からOCRにより文字をデジタル化した場合 OCR適用Auto/Yes】
日本語の文字は各文字がキーワードとして利用可能となります。

3-2.キーワード設定方法による違い
キーワードの登録の仕方により、AND条件とOR条件の設定が可能となります。
【AND条件】
キーワードを1つのセットとして登録することでAND条件となります。
例えば、「ABC」と「TEST株式会社」の2つが含まれている場合に「請求書」と判断されます。(アルファベットの場合大文字小文字を区別しません)
※「ABC」や「TEST株式会社」のいずれかしか存在しない場合は「請求書」と判断されません。

【OR条件】
キーワードを別のセットとして登録することでOR条件となります。
例えば、「テスト株式会社」と「TEST株式会社」のいずれかが含まれている場合に「請求書」と判断されます。 (アルファベットの場合大文字小文字を区別しません)

AND条件とOR条件を組み合わせることももちろん可能となるため、複雑な設定が可能となります。
3-3.キーワード出現位置による違い
キーワードに設定する文字列ははページ先頭に近い文字列であるほど信頼度は高くなります。
| 1ページ目先頭 | 1ページ目3行目 | 2ページ目先頭 | 2ページ目3行目 | 3ページ目先頭 | 3ページ目3行目 | |
|---|---|---|---|---|---|---|
| 信頼度 | 74% | 68% | 59% | 51% | 40% | 29% |
先頭3ページまでに含まれる文字列のみが分類判断に利用されます。
3-4.トレーニング機能
トレーニングスコープを利用することで、新たなキーワードを追加することが可能となります。
キーワード「請求書」のみが登録されていた場合に「御請求書」のタイトルの帳票が来た場合、トレーニングにより自動的にキーワードが追加されます。(詳細についてはデモ動画をご参照ください)
トレーニングスコープは頻出度の高いキーワードに重みづけというものをしていきます。頻出度の高いキーワードに一致した帳票は信頼度が高くなります。
4.他の分類器との違い
主な違いは以下の通りと考えております。
| キーワードベースの分類器 | インテリジェントキーワード分類器 | マシン ラーニング分類器 | Generative Classifier | |
|---|---|---|---|---|
| 分類の単位 | ファイル単位 | ページ単位 | ページ単位 | ページ単位 |
| 分類方法 | 最初の3ページに含まれる文字列をもとに判断 | ページごとの単語ベクトル情報をもとに判断 | ページごとの単語ベクトル情報および座標情報などをもとに判断 | プロンプト文により生成AIが都度判断 |
| 再学習性 | 〇(即時※1) | 〇(即時※1) | 〇 | × |
| 設定容易性 | 〇 | ◎ | △ | ◎※2 |
| AI Units | 0 | 0~5※3 | 0~5※3 | 0.2~ |
インテリジェントキーワード分類器がページ単位での分類ができ便利ですが、キーワード分類器もAI Unitsが不要でかつ人の感覚に近いところで制御できるのが魅力だと考えています。
※1 ファイルに情報が管理されているため、共有フォルダなどを利用することで学習結果を即時反映可能となります。
※2 生成AIによるプロンプト文の内容に依存する部分があり、容易な反面再現性などの難しさがあります。
※3 分類対象のファイルに含まれるページ数に依存します。
5.活用例
5-1.活用例1 Document Understandingの通常処理
請求書から特定の会社を除外し、自動処理対象と手動処理対象を区別して実行したいというユースケースを考えます。
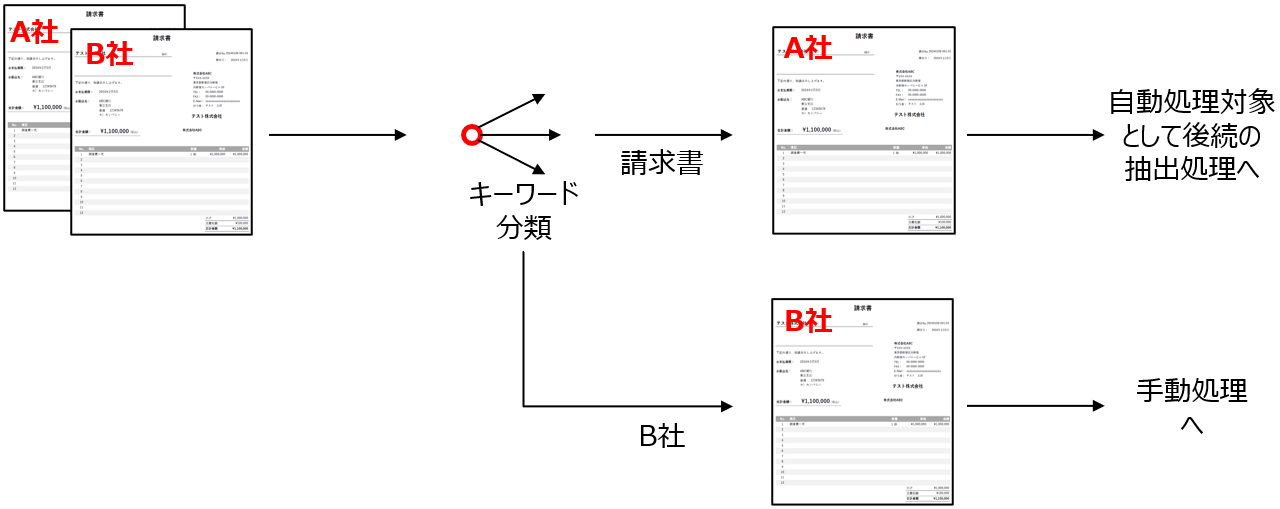
対応方法
請求書と請求書手動という帳票定義を作り、請求書手動に「B社」というキーワードを登録することで簡単に実現することができます。

5-2.活用例2 画像の確認処理
画像に特定のキーワード(例えば、© 2024 UiPath K.K)が含まれていないものを抽出したい
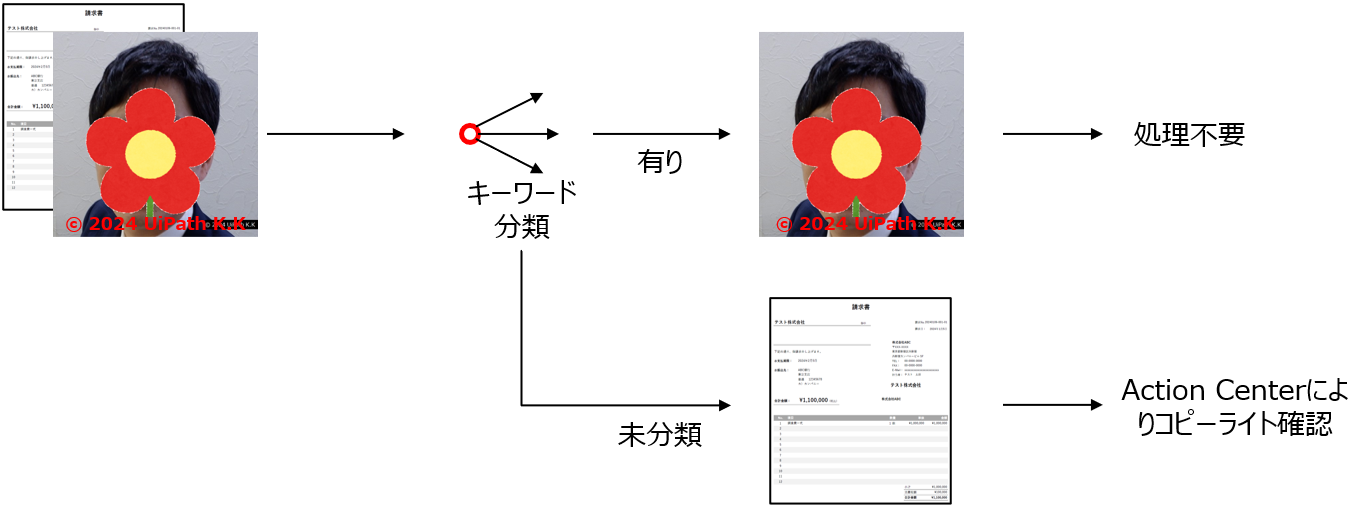
対応方法
以下のように登録したところ、白抜き文字も有りと分類することができました。

「日本語、中国語、韓国語」のOCRエンジンでは「©」を「@」に誤認することがありましたので、ご注意ください。今回のケースでは社名が英語なので、「UiPath ドキュメント OCR」で問題なく分類することを確認しています。
6.最後に
今回のご紹介内容により、少しでもDocument Understandingに興味を持っていただければ幸いです。
本記事はあくまでも個人の見解を述べているものとなりますので、参考情報として頂ければと存じます。