はじめに
グラフ理論で用いられるアルゴリズムであるUnion-Findについてなるべく簡単に解説しました。私も初学者ですので簡単な説明しかできませんが、なるべく伝わりやすく解説しました。なので読者としては初学者を対象としています。また、ソースコードにはJavaを用いています。AtCoderなどで用いるソースコードは私の書いたコードではなく、おまけに載っているリンクから飛ぶコードを用いた方が良いです。
目次
- グラフ理論の最低知識
- Union-findとは
- Union-findの工夫①
- Union-findの工夫②
- Union-Findの実装
- Union-findの例題
- まとめ
- おまけ
グラフ理論の最低知識
今回のグラフ理論を解くにあたって必要な知識をあげておきます。そもそもグラフとは点の集合と辺の集合のペアのことです。定義はさておき以下の図のようなものです。それぞれの点を頂点やノード、点を繋ぐ線のことを辺やエッジと呼びます。
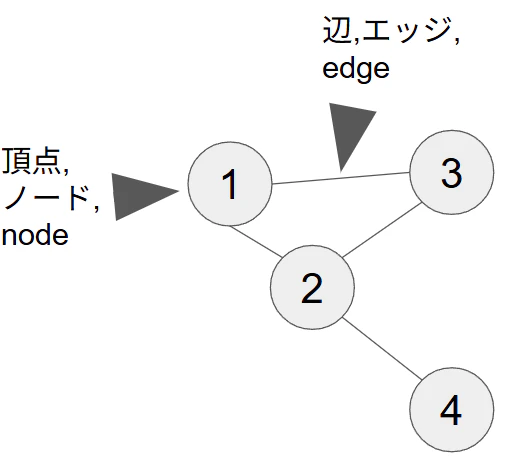
ちなみにこの例のように多重線や自己ループを含まないグラフのことを単純グラフと呼びます。さらに辺に重みが付いていて、矢印になっているものがあります。これを有向グラフと言い、今回のように向きが無いものを無向グラフと呼びます。最低限このあたりを抑えておけば今回の問題で困ることは無いと思います。

Union-Findとは
Union-Findとはデータの結合状態を木構造で管理するアルゴリズムです。要するにグラフが連結しているかどうかの判定を行うことが出来ます。木構造というのはグラフの一種で、以下のような形をしています。木を逆さまにした形で、一番上が根やルートノードと言われます。最初はそれぞれの頂点は独立していますが、それらをつなぎ合わせていって木を作る流れになります。根に近い方の繋がっているノードを親、親から見て根から遠い方に繋がっているノードを子と言います。以下の木構造は計算を高速にする工夫がされていないUnion-Findの例なので注意してください。
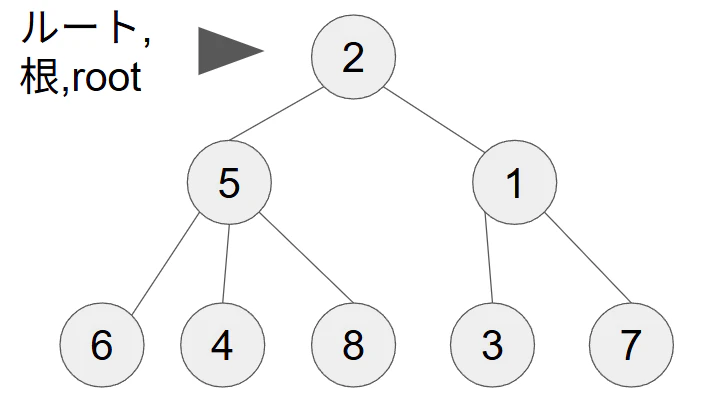
Union-Findはかなり高速で、効率を良くした場合O(log(n))より早いO(α(n))です。ここでα(n)はアッカーマンの逆関数です。アッカーマンの逆関数について私も厳密には理解していませんが、簡単に言うと、nが$10^{80}$になってもα(n)の値が4以下に収まるとの事なので、実質的にO(1)とみなせるくらい高速です。
オーダー数について分からない方は以下の記事が参考になります。簡単に言うとどのくらいの計算量がかかるかを表したものでO()の括弧の中が小さければ計算量が少なく、優秀なアルゴリズムだと言えます。
https://qiita.com/drken/items/872ebc3a2b5caaa4a0d0
Union-FindにはUnion-Findの処理を高速にする2つの工夫がされています。この工夫が無ければ、計算量はO(n)で何も早くないただ木構造でグラフの連結を管理しただけになってしまいます。
Union-Findの工夫①
Union-Findでは2つの工夫をすることで計算速度を向上しており、片方を行うだけでも高速化できます。以下の先ほどの例では何も工夫がされていない状態のUnion-Findです。2つのノードが結合しているかどうかは2つのノードのルートノードが同じかどうかを見ればよいです。例えばこのまま6と7が結合しているかどうかを求めてみると、6の親は5、5の親は2、2はルートノードなので次に行く、7の親は1、1の親は2で両方ルートノードが同じというように、判定までに時間がかかってしまいます。簡単にいうと木の高さ分毎回親ノードをたどっていかなければいけません。
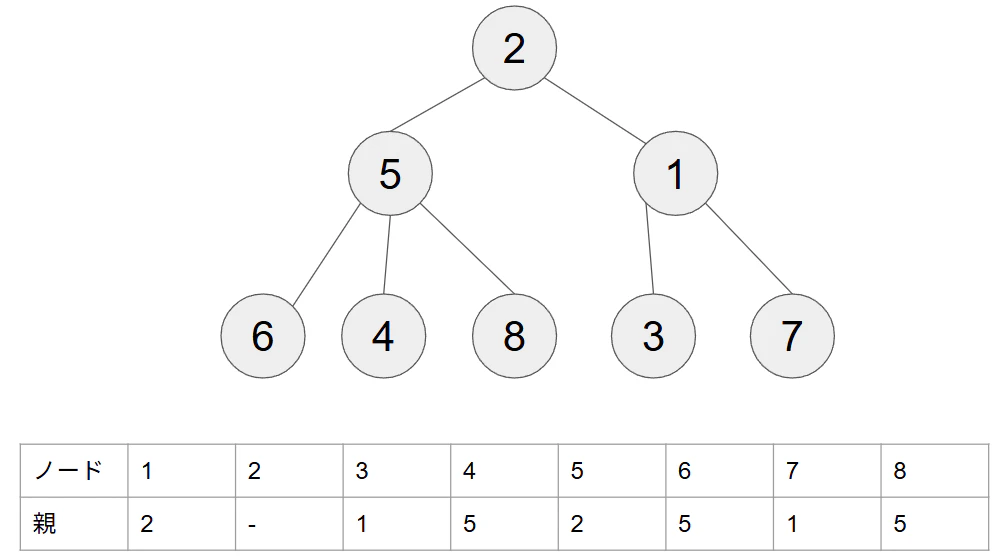
そこで、工夫の1つ目は全てのノードの親をルートノードにしてしまうことです。調べてみるとこの工夫は経路圧縮と呼ばれるようです。こうすることで、どのノードがどのグラフに属しているのかを高速に検索することが出来ます。
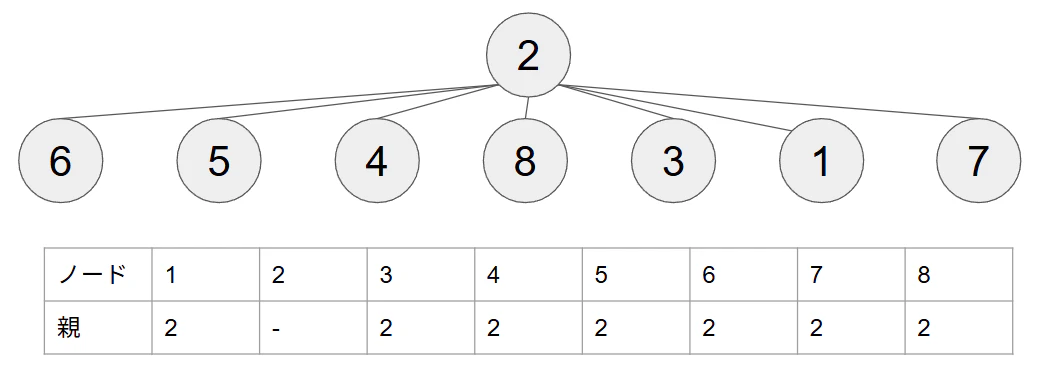
こちらの工夫だけでも計算量がO(log(n))となります。
Union-Findの工夫②
工夫の2つ目は木を結合する際に、木の高さが低い方を高い方に結合することです。木の高さをランクとすることが多く、この記事内ではランクの工夫と呼ぶことにします。図解すると以下のようになります。あまり高速になっていない気もしますが、この工夫をするだけでも計算量がO(log(n))になります。
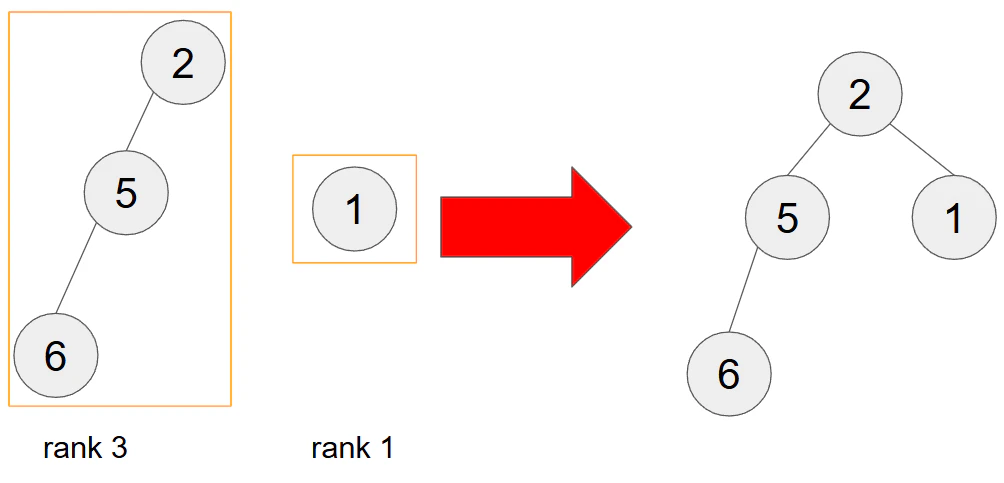
逆にランクが高い方を低い方に結合するとどうなるかを考えます。ランクが同じ、もしくは低い方に木を結合すると、以下のように大きい木の高さが高くなるので、紹介する経路圧縮の時に使う、親のノードを探索する回数が増えます。
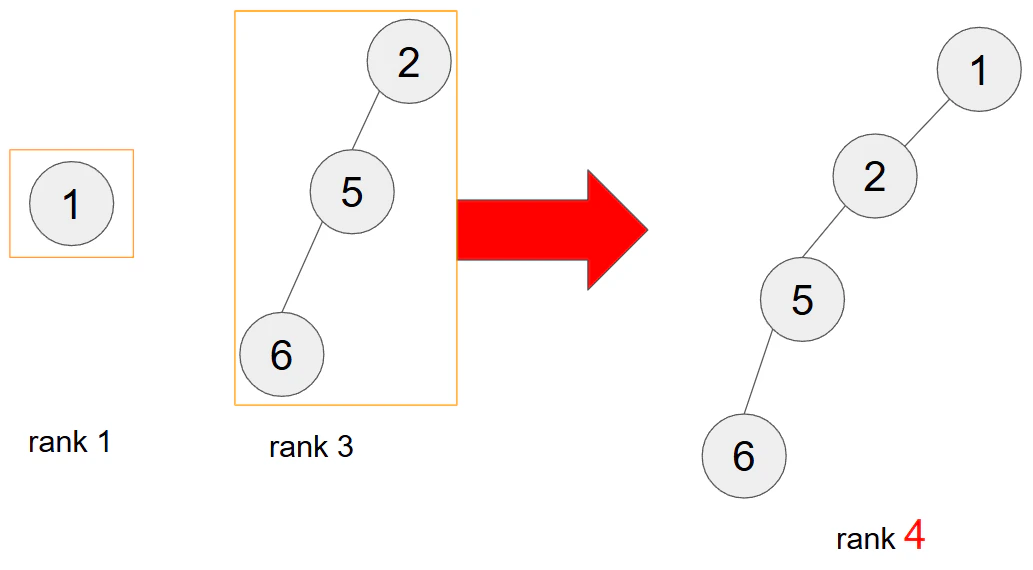
Union-Findの実装
今回実装したコードは以下のようになります。Union-Findは別名、素集合データ構造(Disjoint Set Union)と呼ばれているので、今回クラス名はDSUとしました。
持っているメソッドとしては以下の3つです。
- returnRootNumber そのノードのルートノードを返す
- unite 2つのグラフを連結する
- checkConnect 連結しているかを返す
/**
* Union-Findクラス
*/
class DSU {
// 各ノードのrootノードを格納しておく配列
int[] rootNumberArray;
// 各ノードのランクを格納しておく配列
int[] rankArray;
/**
* コンストラクタ 各ノードを初期化する
*
* @param nodeNum ノードの数
*/
public DSU(int nodeNum) {
rootNumberArray = new int[nodeNum];
rankArray = new int[nodeNum];
for (int i = 0; i < nodeNum; i++) {
rootNumberArray[i] = i;
rankArray[i] = 0;
}
}
/**
* 指定されたノードのルートノードを返す。
* ここで経路圧縮も行う
*
* @param nodeNumber 指定されたノードの番号
* @return 指定されたノードのルートノード
*/
public int returnRootNumber(int nodeNumber) {
//指定されたノードがルートノードだったら番号をそのまま返す
if (rootNumberArray[nodeNumber] == nodeNumber) {
return nodeNumber;
} else {
//指定されたノードのルートノードを関数に入れて再起処理 (経路圧縮)
return rootNumberArray[nodeNumber] = returnRootNumber(rootNumberArray[nodeNumber]);
}
}
/**
* 二つのグラフを連結する。
* ここでランクの工夫も実施している
*
* @param nodeNumber1 連結する一つ目のノード
* @param nodeNumber2 連結する二つ目のノード
*/
public void unite(int nodeNumber1, int nodeNumber2) {
nodeNumber1 = returnRootNumber(nodeNumber1);
nodeNumber2 = returnRootNumber(nodeNumber2);
//二つのノードがすでに連結していれば、何もしない
if (nodeNumber1 == nodeNumber2) {
return;
}
//ランクの高い方に連結する(ルートノードを書き換える)
if (rankArray[nodeNumber1] < rankArray[nodeNumber2]) {
rootNumberArray[nodeNumber1] = nodeNumber2;
} else {
rootNumberArray[nodeNumber2] = nodeNumber1;
//ランクが同じなら一つ目のノードをインクリメントする
if (rankArray[nodeNumber1] == rankArray[nodeNumber2]) {
rankArray[nodeNumber1]++;
}
}
}
/**
* 指定されたノード二つが連結しているかどうかを返す
*
* @param nodeNumber1 指定されたノードの一つ目
* @param nodeNumber2 指定されたノードの二つ目
* @return 連結しているかどうかの真理値
*/
public boolean checkConnect(int nodeNumber1, int nodeNumber2) {
//連結しているかどうかはルートノードが同じかどうかで分かる
return returnRootNumber(nodeNumber1) == returnRootNumber(nodeNumber2);
}
}
工夫の1つ目を実装するには、ルートノードを調べるときに、親ノードがルートでなければルートノードにつなぎなおすことをすればよいです。
工夫の2つ目を実装するには、ノードを結合するときにランクが高い方にルートノードを書き換えればよいです。
Union-Findの例題
今回用いる例題はこちらの問題を用います。本当にDSUの基礎を実装するという問題になっています。問題文も記述しますが念のためリンクを貼っておきます。
https://atcoder.jp/contests/practice2/tasks/practice2_a
問題文
N 頂点 0 辺の無向グラフに Q 個のクエリが飛んできます。処理してください。
0 u v: 辺(u,v)を追加する。
1 u v: u,v が連結ならば 1、そうでないなら 0 を出力する。
制約
1≤N≤200,000
1≤Q≤200,000
0≤ui,vi<N
ソースコード
ソースコードは以下になり、先程のDSUクラスを用います。クエリに合わせて、頂点を結合するメソッドと、連結しているかどうかのメソッドを呼び出すことで、こちらの問題を高速に解くことができます。
import java.util.Scanner;
public class DsuTest {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int nodeNum = sc.nextInt();
int queryNum = sc.nextInt();
int queryType;
int u;
int v;
DSU dsu = new DSU(nodeNum);
for (int i = 0; i < queryNum; i++) {
queryType = sc.nextInt();
u = sc.nextInt();
v = sc.nextInt();
switch (queryType) {
case 0:
dsu.unite(u, v);
break;
case 1:
if (dsu.checkConnect(u, v)) {
System.out.println(1);
} else {
System.out.println(0);
}
break;
default:
System.out.println("無効なクエリです。");
break;
}
}
}
}
まとめ
今回はUnion-Findをなるべく簡単に解説しました。Union-Findは高速にグラフの連結状態を管理する木構造のアルゴリズムで、経路圧縮とランクの工夫の、2つの高速化する工夫がされていることが伝わってくれれば幸いです。私も理解できていないなぜ計算量がO(log(n))になるのか、アッカーマンの逆関数についてはまた調べなおして、記事の方に追記していきたいと考えています。ここまで閲覧いただきありがとうございました。
おまけ ACLとグラフエディターについて
今回解説したunion-findですが、すでに実装済みのライブラリがあります。AtCoderの公式から出されているものなので計算速度なども安心です。
C++で実装されているので私みたいにJavaで挑戦されてる方は使用できずに残念に思うでしょう。しかしなんと、有志の方がJava版を作ってくれています。大変ありがたいです。今回のUnion-FindはDSUというファイルに実装されています。実際こちらを使って問題を解くことが出来たので、活用してみると良いかもしれません。
https://github.com/NASU41/AtCoderLibraryForJava
グラフを簡単に書けるサイトです。イメージを付けたりどんなグラフなら条件を満たすか、満たさないかを考えるときに便利です。
https://kentakom1213.github.io/graph-editor/
今回最も参考にした動画で、Union-Findの解説では一番分かりやすいと思います。
https://youtu.be/nclfErc9pbE?si=SV_iEktZmg5XJFpU