Odyssey CBTのPython3 エンジニア認定データ分析試験の学習を始めました。今回はScikitLearnを用いた前処理、およびサポートベクターマシーンを用いた機械学習・分類アルゴリズムについて学習しました。
ScikitLearnについて
ScikitLearnは機械学習・データマイニングを行うためのライブラリです。 かなり複雑な深層学習以外の機械学習は、たいていScikitで実行できます。 numpy・pandasと合わせて使うのが一般的です。
前処理
Scikitではデータの前処理を行う事ができます。
機械学習・データマイニングを行うためには、欠損値を埋め合わせる・アルゴリズムに適した値の範囲にデータを収める等々の処理する必要があります。
- 欠損値の対処
- 定性データをワンホットベクトルに変換
- 定量データの正規化・正則化
欠損値の除去・保管
import numpy as np
import pandas as pd
df = pd.DataFrame(
{
"A":[1,np.nan,3,4,5],
"B":[6,7,8,np.nan,10],
"C":[11,12,13,14,15]
}
)
print(df)
# 欠損値かをbool値で返す
df.isnull()
A B C
0 1.0 6.0 11
1 NaN 7.0 12
2 3.0 8.0 13
3 4.0 NaN 14
4 5.0 10.0 15
A B C
0 False False False
1 True False False
2 False False False
3 False True False
4 False False False
欠損値の保管 -SimpleImputerというメソッドで欠損値を平均・中央値などに変換する
# 欠損値の保管 - 値を補完する、SimpleImputerのメソッドを用いる
# mean-平均、median-中央値、most_frequent-最頻値、constant-定数
from sklearn.impute import SimpleImputer
imp = SimpleImputer(strategy="mean")
imp.fit(df)
imp.transform(df)
array([[ 1. , 6. , 11. ],
[ 3.25, 7. , 12. ],
[ 3. , 8. , 13. ],
[ 4. , 7.75, 14. ],
[ 5. , 10. , 15. ]])
from sklearn.impute import SimpleImputer
value = 0
imp = SimpleImputer(strategy="constant", fill_value=value)
imp.fit(df)
imp.transform(df)
array([[ 1., 6., 11.],
[ 0., 7., 12.],
[ 3., 8., 13.],
[ 4., 0., 14.],
[ 5., 10., 15.]])
定性データをワンホットベクトルに変換
LabelEncoder - str型などの定性データを値ごとにワンホットベクトルに変換する。
str型などの定性データはワンホットベクトルにすることでSVM・ニューラルネットワークが分類・回帰のアルゴリズムに利用できるようになる。
# LabelEncoder - str型などの定性データを値ごとにワンホットベクトルに変換する
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame(
{
"A":[1,2,3,4,5],
"B":["a","b","c","a","b"]
}
)
print(df)
#エンコーディング
le = LabelEncoder()
le.fit(df.loc[:,"B"])
#変換後・元の値を確認
print(le.transform(df.loc[:,"B"]))
print(le.classes_ )
A B
0 1 a
1 2 b
2 3 c
3 4 a
4 5 b
[0 1 2 0 1]
['a' 'b' 'c']
# LabelEncoder - str型などの定性データを値ごとにワンホットベクトルに変換する
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from sklearn.compose import ColumnTransformer
#データフレームを複製
df_ohe = df.copy()
#エンコーディング
le = LabelEncoder()
df_ohe.loc[:,"B"] = le.fit_transform(df_ohe.loc[:,"B"])
ohe = ColumnTransformer([("OneHotEncoder", OneHotEncoder(),[1])], remainder="passthrough")
df_ohe = ohe.fit_transform(df_ohe)
df_ohe
array([[1., 0., 0., 1.],
[0., 1., 0., 2.],
[0., 0., 1., 3.],
[1., 0., 0., 4.],
[0., 1., 0., 5.]])
定量データの正規化・正則化
- 分散正規化-平均が0,標準偏差を1にする
- 最小最大正規化 - 最小値が0、最大値を1にする
#分散正規化
import pandas as pd
df = pd.DataFrame(
{
"A":[1,2,3,4,5],
"B":[100,200,400,500,800]
}
)
print(df)
#StandardScaler - 分散正規化のインスタンス
from sklearn.preprocessing import StandardScaler
#インスタンスを作成→fit、transformで正規化を実行する
stdsc = StandardScaler()
stdsc.fit(df)
stdsc.transform(df)
A B
0 1 100
1 2 200
2 3 400
3 4 500
4 5 800
array([[-1.41421356, -1.22474487],
[-0.70710678, -0.81649658],
[ 0. , 0. ],
[ 0.70710678, 0.40824829],
[ 1.41421356, 1.63299316]])
#MinMaxScaler - 最大最小正規化のインスタンス
from sklearn.preprocessing import MinMaxScaler
#インスタンスを作成→fit、transformで正規化を実行する
mmsc = MinMaxScaler()
mmsc.fit(df)
mmsc.transform(df)
array([[0. , 0. ],
[0.25 , 0.14285714],
[0.5 , 0.42857143],
[0.75 , 0.57142857],
[1. , 1. ]])
分類アルゴリズム
データをクラスに分類するアルゴリズムを活用します。大量のデータを分類するには、機械学習の中でも教師あり学習が活用されます。 ユーザーを利用履歴などをもとに購入層を分析する、またはサービスから退会する可能性を予測する等々のマーケティング戦略に応用されています。
- サポートベクターマシン(SVM)
- 決定木
- ランダムフォレスト法
分類用のモデルを作成するには、まずデータを学習用・テスト用に分割します。 機械学習の目的は学習用のデータだけに適応するだけでなく、テスト用のデータのような未知の値に対応する性能(汎化能力)を向上することである。 汎化能力を効率よく向上させる方法として、学習・テストデータの分割とモデル構築を複数回繰り返す交差検証が活用されています。
SVM
サポートベクターマシーン(SVM) - 教師あり学習の分類・回帰に使えるアルゴリズム。
SVMは直線・平面などで分類できない(=線形分離できない)データを分類することができます。SVMのアルゴリズムは線形代数を用いて高次元空間でのデータの内積=距離を計算することで、データを高次元の空間上で線形分離するというタスクを要します。これに関しては数学オンチなので(笑)復習してきます。
今回は説明変数が一様乱数で生成した連続値で、2つのベクトルデータ・目的変数が0か1のスカラー値の場合を扱います。
#SVM
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
#まずは学習に使うベクトルデータと目的変数を生成する
#乱数シード
rng = np.random.default_rng(123)
#一様乱数とそのラベルを生成 - ラベルが0か1かで分類する
X0 = rng.uniform(size =(100, 2))
y0 = np.repeat(0, 100)
X1 = rng.uniform(-1, 0, size =(100, 2))
y1 = np.repeat(1, 100)
#乱数をプロット
fig, ax = plt.subplots()
ax.scatter(X0[:,0], X0[:,1], marker="o", label="Class-0")
ax.scatter(X1[:,0], X1[:,1], marker="x", label="Class-1")
ax.set_xlabel("x")
ax.set_xyabel("y")
ax.legend()
plt.show()
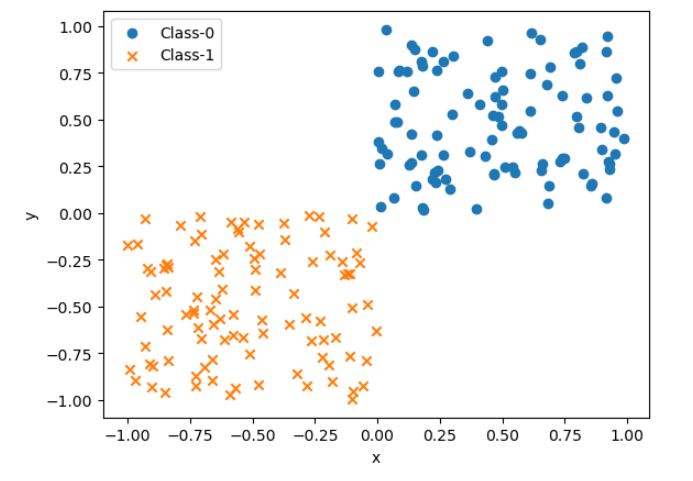
データの生成が完了 - SVMを使って生成した乱数の決定境界を求める
#SVMを使って生成した乱数の決定境界・マージン・サポートベクターを求める
from sklearn.svm import SVC
def plot_boundary_margin(X0, y0, X1, y1, kernel, C, xmin = -1, xmax = 1, ymin = -1, ymax = 1):
#SVMのインスタンス
#C - マージンの幅。広いほどサポートベクターの数が増える
svc= SVC(kernel=kernel, C=C)
#学習 - 学習に用いるデータをvstack・hstackで結合する
svc.fit(np.vstack((X0,X1)), np.hstack((y0,y1)))
#散布図
fig, ax = plt.subplots()
ax.scatter(X0[:,0], X0[:,1], marker="o", label="Class-0")
ax.scatter(X1[:,0], X1[:,1], marker="x", label="Class-1")
#決定境界とマージンをプロット
xx,yy = np.meshgrid(np.linspace(xmin,xmax,100), np.linspace(ymin,ymax,100))
xy = np.vstack([xx.ravel(), yy.ravel()]).T
p = svc.decision_function(xy).reshape((100, 100))
ax.contour(xx, yy, p, colors="k", levels=[-1,0,1], alpha=0.5, linestyles=["--","-","--"])
#サポートベクター
ax.scatter(svc.support_vectors_[:,0], svc.support_vectors_[:,1], s=250, facecolors="none", edgecolors="black")
ax.set_xlabel("x")
ax.set_ylabel("y")
ax.legend(loc="best")
plt.show()
plot_boundary_margin(X0, y0, X1, y1, kernel="linear", C=1.0)
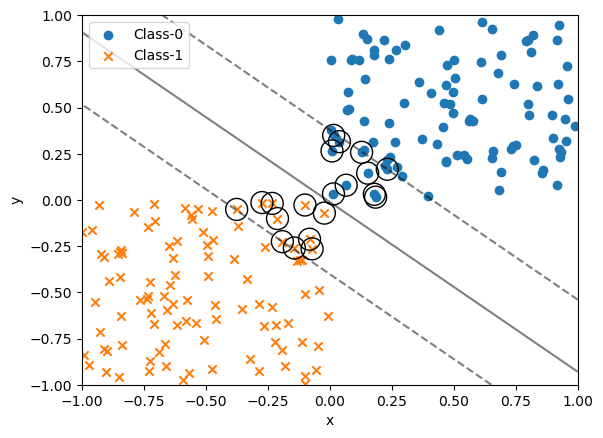
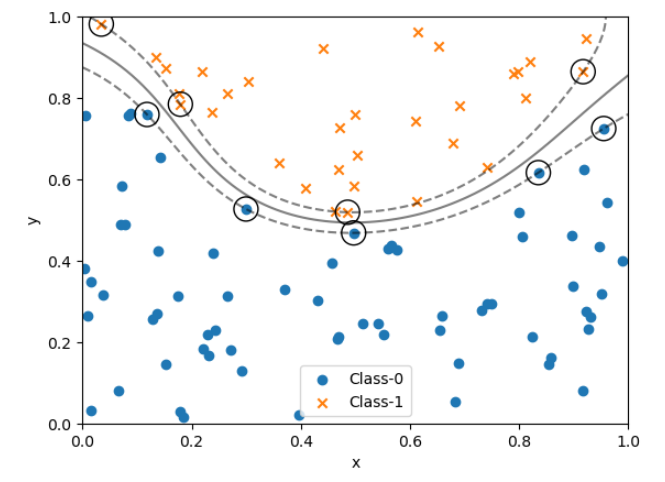
決定境界が非線形となる場合
決定境界が非線形となる分布を分類します。高度な知性の本質とは、非線形的な「難しい」分類ができることです。非線形な決定境界を決めるにはSVMやランダムフォレスト法・ニューラルネットワークが最も適しています。欠点はなぜその決定境界となったのか?という分類の基準が曖昧になりやすいことです。(ブラックボックス化)
# y = 2(x-0.5)^2 + 0.5 が決定境界となる分布をSVMに分類させる
#乱数シード
rng = np.random.default_rng(123)
#一様乱数とそのラベルを生成 - ラベルが0か1かで分類する
#内包表記でラベルの値を多項目式で生成できる
X = rng.random(size=(100,2))
y = (X[:,1] > 2*(X[:,0] - 0.5)**2 + 0.5).astype(int)
#fig, ax = plt.subplots()
#散布図
#ax.scatter(X[y==0, 0], X[y==0, 1], marker="o", label="Class-0")
#ax.scatter(X[y==1, 0], X[y==1, 1], marker="x", label="Class-1")
#内容表記を使った代入 - Y==0等の条件に合う場合、その値のみをリストに代入する
X0, X1 = X[y==0,:],X[y==1,:]
y0, y1 = y[y==0],y[y==1]
plot_boundary_margin(X0, y0, X1, y1, kernel="rbf", C=1e3, xmin=0, ymin=0)
#ax.legend()
#plt.show()
ScikitLearnでデータの前処理、SVMといった比較的高度なアルゴリズムが扱えるようになりました。次回は決定木とランダムフォレスト法を学習していきます。