機械学習のプロセスを効率化・合理化して精度を上げるためのコードを書くのを迅速に行いたい、ということで従来の分析プロセスとコードの書き方を見直してみることにしました。前回に引き続き「Kaggleで磨く機械学習の実践力」という書籍を参考にしています。
前回までに量的変数のみを利用して最低限の精度が出せるベースモデルの作成、ドメイン知識を生かした特徴量エンジニアリングとラッパー法による特徴量選択を行いました。最後にLightGBMを使った予測精度をさらに向上するにはモデルそのものを最適化する・別のモデルとアンサンブル学習する、という手法が残っていますのでそちらに取り組んでいこうと思います。
まずはモデル学習までのプロセスを前回から再現します。
https://qiita.com/K_Nemoto/items/1203512fd78bf38d86b5
インポート
import numpy as np
import pandas as pd
import os
import pickle
import gc
# 分布確認に使う
# import pandas_profiling as pdp
# 可視化
import matplotlib.pyplot as plt
# 前処理、特徴量作成 - sklearnを使う
from sklearn.preprocessing import StandardScaler, MinMaxScaler, LabelEncoder
# モデリング・精度と評価指標
from sklearn.model_selection import train_test_split, KFold, StratifiedKFold
from sklearn.metrics import accuracy_score, roc_auc_score, confusion_matrix
#LGBM
import lightgbm as lgb
#どうでもいい警告は無視
import warnings
warnings.filterwarnings("ignore")
# NOTE matplotでの日本語文字化けを解消
#pip install japanize-matplotlib
import japanize_matplotlib
%matplotlib inline
データ確認
分析・予測に使うデータは"Titanic - Machine Learning from Disaster"の生存者予測問題です。
https://www.kaggle.com/competitions/titanic
df_train = pd.read_csv("titanic_datasets/train.csv")
df_train.head()
print("データ形状:")
print(df_train.shape)
print("データ数:")
print(len(df_train))
print("データのコラム数")
print(len(df_train.columns))
print("データ型一覧")
df_train.info()
# 量的変数の要約統計
df_train.describe().T
#質的変数の度数
df_train.describe(exclude="number").T
データ前処理
df_train.isnull().sum()
#性別(sex)→0,1
# 古典的な男女の質的変数など、ダミー化した情報が1つで十分な場合は多重共線性対策で1つのみ情報を残す
df_train = pd.get_dummies(df_train, columns = ["Sex"], drop_first=True)
#出港地(Embarked)→0,1,2
#df_train['Embarked'].fillna(('S'), inplace=True)
df_train = pd.get_dummies(df_train, columns = ["Embarked"])
#運賃(Fare)→欠損値は平均値にする
df_train['Fare'].fillna(np.mean(df_train['Fare']), inplace=True)
#運賃(Fare)のヒストグラムを描写。ポアソン分布となる説明変数はビニングすると精度が向上する事が分かっている
#df_train['Fare'].hist(bins=50)
# NOTE 境界値を指定したビニング
bins_Fare = [0,50,100,200,300,1000]
# T_Bil列を分割し、0始まりの連番でラベル化した結果をX_cutに格納する
X_cut, bin_indice = pd.cut(df_train["Fare"], bins=bins_Fare, retbins=True, labels=False)
# bin分割した結果をダミー変数化 (prefix=X_Cut.nameは、列名の接頭語を指定している)
X_dummies = pd.get_dummies(X_cut, prefix=X_cut.name)
# 元の説明変数のデータフレーム(X)と、ダミー変数化した結果(X_dummies)を横連結
df_train = pd.concat([df_train, X_dummies], axis=1)
#年齢(Age)→欠損値は平均値・標準偏差を使って正規乱数で埋め合わせる
age_avg = df_train['Age'].mean()
age_std = df_train['Age'].std()
df_train['Age'].fillna(np.random.randint(age_avg - age_std, age_avg + age_std), inplace=True)
# 特徴量:Familysizeを作成(Parch, Sibspを足した値)
df_train['FamilySize'] = df_train['Parch'] + df_train['SibSp'] + 1
df_train['FamilySize_bin'] = 'big'
df_train.loc[df_train['FamilySize']==1,'FamilySize_bin'] = 'alone'
df_train.loc[(df_train['FamilySize']>=2) & (df_train["FamilySize"]<=4),'FamilySize_bin'] = 'small'
df_train.loc[(df_train['FamilySize']>=5) & (df_train["FamilySize"]<=7),'FamilySize_bin'] = 'mediam'
# 特徴量:TicketFreq - Ticket頻度をチケットを表す量的変数とする
df_train.loc[:, 'TicketFreq'] = df_train.groupby(['Ticket'])['PassengerId'].transform('count')
# 特徴量:HonorificをNameから抽出
df_train['honorific'] = df_train['Name'].map(lambda x: x.split(', ')[1].split('. ')[0])
df_train['honorific'].replace(['Col','Dr', 'Rev'], 'Rare',inplace=True) #少数派の敬称を統合
df_train['honorific'].replace('Mlle', 'Miss',inplace=True) #Missに統合
df_train['honorific'].replace('Ms', 'Miss',inplace=True) #Missに統合
# 特徴量:Cabin_ini - Cabinの頭文字を抽出
df_train['Cabin_ini'] = df_train['Cabin'].map(lambda x:str(x)[0])
df_train['Cabin_ini'].replace(['G','T'], 'Rare',inplace=True)
# FamilySize_bin, honorific, Cabin_iniをすべてダミー化する
df_train = pd.get_dummies(df_train, columns = ["FamilySize_bin", "honorific", "Cabin_ini"])
print("コラム名:")
print(df_train.columns)
print("コラム数:")
print(len(df_train.columns))
特徴量選択
target_col = 'Survived'
drop_col = ['PassengerId','Survived', 'Name', 'Fare', 'Ticket', 'Cabin', 'Parch', 'FamilySize', 'SibSp']
y = df_train[target_col]
X = df_train.drop(drop_col , axis=1)
## ラッパー法(GBDT)で説明変数を削減
from sklearn.feature_selection import RFE
from sklearn.ensemble import GradientBoostingRegressor
# estimatorとしてGBDTを使用。特徴量を20個選択 = 約半数に削減
selector = RFE(GradientBoostingRegressor(n_estimators=100, random_state=10), n_features_to_select=20)
selector.fit(X, y)
mask = selector.get_support()
#print(X.feature_names)
print(mask)
# 選択した特徴量の列のみ取得
X_selected = selector.transform(X)
print("X.shape={}, X_selected.shape={}".format(X.shape, X_selected.shape))
list = []
not_selected = []
columns = X.columns
# 学習に使う・使わない特徴量のリストを作成
for i in range(0, len(mask)):
value = mask[i]
if (value == True):
list.append(columns[i])
else:
not_selected.append(columns[i])
print("選択された20の特徴量:")
print(list)
print("選択されなかった特徴量:")
print(not_selected)
選択された20の特徴量:
['Pclass', 'Age', 'Sex_male', 'Embarked_C', 'Embarked_S', 'Fare_1.0', 'Fare_3.0', 'Fare_4.0', 'TicketFreq', 'FamilySize_bin_alone', 'FamilySize_bin_mediam', 'FamilySize_bin_small', 'honorific_Master', 'honorific_Mr', 'honorific_Rare', 'Cabin_ini_A', 'Cabin_ini_B', 'Cabin_ini_D', 'Cabin_ini_E', 'Cabin_ini_n']
選択されなかった特徴量:
['Embarked_Q', 'Fare_0.0', 'Fare_2.0', 'FamilySize_bin_big', 'honorific_Capt', 'honorific_Don', 'honorific_Jonkheer', 'honorific_Lady', 'honorific_Major', 'honorific_Miss', 'honorific_Mme', 'honorific_Mrs', 'honorific_Sir', 'honorific_the Countess', 'Cabin_ini_C', 'Cabin_ini_F', 'Cabin_ini_Rare']
モデル学習のプロセスを改善
ベイズ最適化によるハイパーパラメータチューニングを追加
今回は学習段階でのハイパーパラメータを最適化し,汎用精度の向上を目指します。
モデルの最適化には、大きく2つの手法があります:
- 手動チューニング - カンを頼りにパラメータを変える
- 自動チューニング - optuna, scikit-optimizeなどを利用して自動で分類精度の高いパラメータを探索する
optunaではこれまでに求めた値からベイズ定理を用いて最適解を捻出するベイズ最適化によるチューニング、scikit-optimizeではしらみつぶしに指定した値の検証を行うグリッドサーチによるチューニングが実行できます。一般に変更するべきパラメータが多数(5~10以上)、かつfloat値が半数以上である場合はベイズ最適化を用いる必要があります。
また、ベイズ最適化をする際は実際に目的のモデルを学習させ評価指標を算出できるようにしないといけません。ここでは実際のモデル学習と同様、学習目標となるLGBMと同じモデルとホールドアウト検証を行えるよう学習用・検証用に分割したデータを用意します。
X_train, y_train, id_train = X[list], df_train[["Survived"]], df_train[["PassengerId"]]
# データ形状が問題ないか判定
print(X_train.shape)
print(y_train.shape)
print(id_train.shape)
# ホールドアウト検証 - 学習用・テスト用に分割
X_tr, X_va, y_tr, y_va = train_test_split(X_train, y_train, test_size=0.2, shuffle=True, stratify=y_train, random_state=123)
print("学習用・訓練用データの形状:")
print(X_tr.shape)
print(y_tr.shape)
print(X_va.shape)
print(y_va.shape)
# データのラベルに偏りがないか表示
y_train_mean = y_train["Survived"].mean()
y_tr_mean = y_tr["Survived"].mean()
y_va_mean = y_va["Survived"].mean()
ハイパーパラメータチューニング - 最適パラメータの探索
検証用データを用意できたので、次にoptunaをインポートし最適パラメータの探索を行います。study.optimizeを実行すると10分ほどの時間で探索が完了します。
import optuna
# LGBMのパラメータ(学習しないパラメータのみこの段階で定義する)
params_base = {"boosting_type":"gbdt",
"objective":"binary",
"metric":"auc",
"learning_rate":0.02,
"num_leaves":16,
"n_estimators":100000,
"bagging_freq:":1,
"seed": 12
def objective(trial):
# チューニングで探索する最適パラメータ
params_tuning = {
"num_leaves": trial.suggest_int("num_leaves", 8, 256),
"min_data_in_leaf":trial.suggest_int("min_data_in_leaf", 5,200),
"min_sum_hessian_in_leaf":trial.suggest_float("min_sum_hessian_in_leaf", 0.00001, 0.01, log = True),
"feature_fraction":trial.suggest_float("feature_fraction", 0.5, 1.0),
"bagging_fraction":trial.suggest_float("bagging_fraction", 0.5, 1.0),
"lambda_l1":trial.suggest_float("lambda_l1", 0.01, 10.0, log = True),
"lambda_l2":trial.suggest_float("lambda_l2", 0.01, 10.0, log = True)
}
#tuningにbaseの値を加える
params_tuning.update(params_base)
#モデル学習(ベイズ最適化)
list_metrics=[]
# ホールドアウト検証 - 学習用・テスト用の分割を1通り決める
X_tr, X_va, y_tr, y_va = train_test_split(X_train, y_train, test_size=0.2, shuffle=True, stratify=y_train, random_state=123)
model = lgb.LGBMClassifier(**params_tuning)
model.fit(X_tr, y_tr, eval_set=[(X_tr, y_tr),(X_va, y_va)],
#early_stopping_rounds=100,
#verbose=0
)
y_va_pred = model.predict_proba(X_va)[:, 1]
metric_va = accuracy_score(y_va, np.where(y_va_pred >= 0.5, 1, 0))
return metric_va
# 探索を実行
sampler = optuna.samplers.TPESampler(seed=123)
study = optuna.create_study(sampler=sampler, direction="maximize")
study.optimize(objective, n_trials=10)
# 探索で得られた結果を確認
trial = study.best_trial
print("最も高い精度:")
print(trial.value)
print("最も高い精度となるパラメータ:")
print(trial.params)
最も高い精度:
0.8547486033519553
最も高い精度となるパラメータ:
{'num_leaves': 219, 'min_data_in_leaf': 146, 'min_sum_hessian_in_leaf': 0.0006808799287054756, 'feature_fraction': 0.8612216912851107, 'bagging_fraction': 0.6614794569265892, 'lambda_l1': 0.1217211275847546, 'lambda_l2': 0.048393796358465295}
ベイズ最適化の結果得られたパラメータを学習を必要としないパラメータに加えます。
#param_best = trial.params
params_best = {'num_leaves': 219, 'min_data_in_leaf': 146, 'min_sum_hessian_in_leaf': 0.0006808799287054756, 'feature_fraction': 0.8612216912851107, 'bagging_fraction': 0.6614794569265892, 'lambda_l1': 0.1217211275847546, 'lambda_l2': 0.048393796358465295}
params_best.update(params_base)
display(params_best)
これでLGBMを使ったモデルでは最高に近い精度が出せる状態が準備できました。
モデル学習
予測に使用するLGBMのモデルを学習開始します。これに最適化の結果得られたパラメータを活用します。
model = lgb.LGBMClassifier(**params_best)
model.fit(X_tr, y_tr, eval_set=[(X_tr, y_tr),(X_va, y_va)])
# AUC値に加え精度を算出する
y_tr_pred = model.predict(X_tr)
y_va_pred = model.predict(X_va)
metric_tr = accuracy_score(y_tr, y_tr_pred)
metric_va = accuracy_score(y_va, y_va_pred)
print("モデル精度:")
print("学習精度")
print(metric_tr)
print("検証精度")
print(metric_va)
モデル精度:
学習精度
0.8721910112359551
検証精度
0.8547486033519553
ベースライン時は66%、特徴量エンジニアリング後は83%ほどだったAUC率は85.4%まで向上させることができました。特徴量エンジニアリングとベイズ最適化の2つを駆使するとLGBMによる機械学習をかなり効率化できます。
最後に混合行列・評価指標の算出と提出用データの作成を行います。
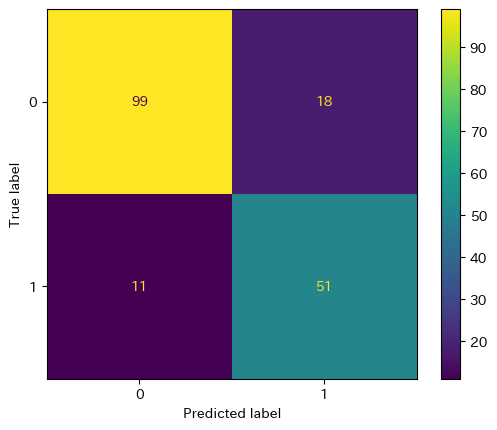
混合行列・評価指標の算出
# 混合行列 - ラベルの正誤の分類数をまとめる
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
cm = confusion_matrix(y_pred, y_va)
print("混合行列:")
print(cm)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=["0","1"])
disp.plot()
plt.show()
from sklearn.metrics import accuracy_score
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
"""
適合率は予測されたラベルのうち、どれだけが正解だったか
再現率は正解のラベルのうち、どれだけそのラベルを予測できたか
一般的に誤検出を少なくしたい場合には適合率。取りこぼしを少なくしたい場合には再現率を重視します。
医療等に機械学習を活用する等「取りこぼしが多いと命に関わるような重大な問題に繋がる」といったような場合には、再現率を評価指標に使用するのが適切です。
"""
#適合率 - TP+TN / (TP+FP+TN+FN) - 単純な正答率
print("正答率")
print(accuracy_score(y_pred, y_va))
#適合率 - TP / (TP+FP) - 予測されたラベルに対する実際に正解となるサンプル
print("適合率")
print(precision_score(y_pred, y_va))
#再現率 - TP / (TP+FN) - 本来正しく予測した場合に対し実際に正解となるサンプル
print("再現率")
print(recall_score(y_pred, y_va))
print("F値")
print(f1_score(y_pred, y_va))
正答率
0.8379888268156425
適合率
0.7391304347826086
再現率
0.8225806451612904
F値
0.7786259541984734
提出用データの作成
df_test = pd.read_csv("titanic_datasets/test.csv")
df_test.head(5)
#性別(sex)→0,1
# 古典的な男女の質的変数など、ダミー化した情報が1つで十分な場合は多重共線性対策で1つのみ情報を残す
df_test = pd.get_dummies(df_test, columns = ["Sex"], drop_first=True)
#出港地(Embarked)→0,1,2、不明の値は仮にS=0にする
df_test['Embarked'].fillna(('S'), inplace=True)
df_test = pd.get_dummies(df_test, columns = ["Embarked"])
#運賃(Fare)→欠損値は平均値にする
df_test['Fare'].fillna(np.mean(df_test['Fare']), inplace=True)
#運賃(Fare)のヒストグラムを描写。ポアソン分布となる説明変数はビニングすると精度が向上する事が分かっている
df_test['Fare'].hist(bins=50)
# NOTE 境界値を指定したビニング
bins_Fare = [0,50,100,200,300,1000]
# T_Bil列を分割し、0始まりの連番でラベル化した結果をX_cutに格納する
X_cut, bin_indice = pd.cut(df_test["Fare"], bins=bins_Fare, retbins=True, labels=False)
# bin分割した結果をダミー変数化 (prefix=X_Cut.nameは、列名の接頭語を指定している)
X_dummies = pd.get_dummies(X_cut, prefix=X_cut.name)
# 元の説明変数のデータフレーム(X)と、ダミー変数化した結果(X_dummies)を横連結
df_test = pd.concat([df_test, X_dummies], axis=1)
#年齢(Age)→欠損値は平均値・標準偏差を使って正規乱数で埋め合わせる
age_avg = df_test['Age'].mean()
age_std = df_test['Age'].std()
df_test['Age'].fillna(np.random.randint(age_avg - age_std, age_avg + age_std), inplace=True)
# 特徴量:Familysizeを作成(Parch, Sibspを足した値)
df_test['FamilySize'] = df_test['Parch'] + df_test['SibSp'] + 1 #ALLデータ
# FamilySizeを離散化
df_test['FamilySize_bin'] = 'big'
df_test.loc[df_test['FamilySize']==1,'FamilySize_bin'] = 'alone'
df_test.loc[(df_test['FamilySize']>=2) & (df_test["FamilySize"]<=4),'FamilySize_bin'] = 'small'
df_test.loc[(df_test['FamilySize']>=5) & (df_test["FamilySize"]<=7),'FamilySize_bin'] = 'mediam'
# 特徴量:TicketFreq - Ticket頻度をチケットを表す量的変数とする
df_test.loc[:, 'TicketFreq'] = df_test.groupby(['Ticket'])['PassengerId'].transform('count')
# 特徴量:HonorificをNameから抽出
df_test['honorific'] = df_test['Name'].map(lambda x: x.split(', ')[1].split('. ')[0])
df_test['honorific'].replace(['Col','Dr', 'Rev'], 'Rare',inplace=True) #少数派の敬称を統合
df_test['honorific'].replace('Mlle', 'Miss',inplace=True) #Missに統合
df_test['honorific'].replace('Ms', 'Miss',inplace=True) #Missに統合
# 特徴量:Cabin_ini - Cabinの頭文字を抽出
df_test['Cabin_ini'] = df_test['Cabin'].map(lambda x:str(x)[0])
df_test['Cabin_ini'].replace(['G','T'], 'Rare',inplace=True) #少数派のCabin_iniを統合
df_test = pd.get_dummies(df_test, columns = ["FamilySize_bin", "honorific", "Cabin_ini"])
test_feature = df_test[list]
test_feature.columns
y_pred = model.predict(test_feature)
# NOTE 予測結果を1次元ベクトルにする
y_pred = np.squeeze(y_pred)
y_pred.shape
y_pred[(y_pred >= 0.5)] = 1
y_pred[(y_pred < 0.5)] = 0
y_pred = np.array(y_pred, dtype='int')
output = pd.DataFrame({'PassengerId': df_test.PassengerId, 'Survived': y_pred})
output.to_csv('submission_LGBM_bayes_optimized_.csv', index=False)