機械学習のプロセスを効率化・合理化して精度を上げるためのコードを書くのを迅速に行いたい、ということで従来の分析プロセスとコードの書き方を見直してみることにしました。前回に引き続き「Kaggleで磨く機械学習の実践力」という書籍を参考にしています。
ベースライン作成から特徴量エンジニアリングに進む
特徴量エンジニアリングでは主にデータ前処理・特徴量生成の過程を改善します。特徴量エンジニアリングは一気に行うのではなく、欠損値の補完、説明変数を生成して追加、バリエーション設計の変更などなどの1つ1つの処理がモデル精度に与える影響を検証しながら進めます。今回は前回作成したベースラインに対しどのような変更を加えたかを順に掲載していきます。
インポート
import numpy as np
import pandas as pd
import os
import pickle
import gc
# 分布確認に使う
# import pandas_profiling as pdp
# 可視化
import matplotlib.pyplot as plt
# 前処理、特徴量作成 - sklearnを使う
from sklearn.preprocessing import StandardScaler, MinMaxScaler, LabelEncoder
# モデリング・精度と評価指標
from sklearn.model_selection import train_test_split, KFold, StratifiedKFold
from sklearn.metrics import accuracy_score, roc_auc_score, confusion_matrix
#LGBM
import lightgbm as lgb
#どうでもいい警告は無視
import warnings
warnings.filterwarnings("ignore")
# NOTE matplotでの日本語文字化けを解消
#pip install japanize-matplotlib
import japanize_matplotlib
%matplotlib inline
df_train = pd.read_csv("titanic_datasets/train.csv")
df_train.head()
PassengerId Survived Pclass Name Sex Age SibSp Parch Ticket Fare Cabin Embarked
0 1 0 3 Braund, Mr. Owen Harris male 22.0 1 0 A/5 21171 7.2500 NaN S
1 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1 0 PC 17599 71.2833 C85 C
2 3 1 3 Heikkinen, Miss. Laina female 26.0 0 0 STON/O2. 3101282 7.9250 NaN S
3 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1 0 113803 53.1000 C123 S
4 5 0 3 Allen, Mr. William Henry male 35.0 0 0 373450 8.0500 NaN S
データ確認
print("データ形状:")
print(df_train.shape)
print("データ数:")
print(len(df_train))
print("データのコラム数")
print(len(df_train.columns))
データ形状:
(891, 12)
データ数:
891
データのコラム数
12
print("データ型一覧")
df_train.info()
データ型一覧
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KB
df_train.describe().T
count mean std min 25% 50% 75% max
PassengerId 891.0 446.000000 257.353842 1.00 223.5000 446.0000 668.5 891.0000
Survived 891.0 0.383838 0.486592 0.00 0.0000 0.0000 1.0 1.0000
Pclass 891.0 2.308642 0.836071 1.00 2.0000 3.0000 3.0 3.0000
Age 714.0 29.699118 14.526497 0.42 20.1250 28.0000 38.0 80.0000
SibSp 891.0 0.523008 1.102743 0.00 0.0000 0.0000 1.0 8.0000
Parch 891.0 0.381594 0.806057 0.00 0.0000 0.0000 0.0 6.0000
Fare 891.0 32.204208 49.693429 0.00 7.9104 14.4542 31.0 512.3292
#質的変数
df_train.describe(exclude="number").T
count unique top freq
Name 891 891 Braund, Mr. Owen Harris 1
Sex 891 2 male 577
Ticket 891 681 347082 7
Cabin 204 147 B96 B98 4
Embarked 889 3 S 644
データ前処理・欠損値の補完
欠損している値に本来の値に近いものを当てはめるとより精度が向上が期待できます。またLightGBM以外のモデルを用いる場合、欠損を保管しないと学習できない場合がほとんどなので必須の処理です。
df_train.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
Age、Cabin、Embarkedに欠損があるのでその補完を目指します。
主に欠損値は量的データの場合0もしくは平均値で、質的データの場合最頻値で補完します。どの補完方法が最適かは場合によるので要検証です。
特徴量生成
生データから新しく説明変数として有力なデータを作成することを、特徴量生成 と呼びます。特徴量生成は「タイタニックでは子供が優先して救助されていたので、子供かどうかを年齢から抽出しよう」といった 仮説ベースの手法 、仮説ベースを用いず説明変数を四則演算する等の 機械的手法 の大きく2つがあります。
どのような特徴量生成が有効かは仮説を立てる データサイエンスの知識 ・物事の本質を見極める ドメイン知識 の双方の活用が必要となります。
特徴量生成の手法
-
単変数(量的変数)
対数変換、累乗・指数・逆数変換、離散化、欠損か否かをワンホットエンコーディング -
単変数(質的変数)
ワンホットエンコーディング、カウントエンコーディング、ラベルエンコーディング、欠損か否かをワンホットエンコーディング -
2変数組み合わせ
数値×数値の四則演算、質的変数×質的変数のワンホットエンコーディング、数値×質的変数で集約値を算出 -
時系列データ
ラグ特徴量、ウィンドウ特徴量、累積特徴量 -
自然言語
テキストのベクトルとその意味を抽出(BoW、TF-IDF、Word2Vec, BERT)
特徴量選択の手法
分析に本質的に役立つ特徴量を抽出するには、適した値を選択する 特徴量選択 を行う必要があります。
- フィルター法
特徴量・目的変数の相関で有効性の有無を判定 - ラッパー法
特徴量でモデルを学習、精度向上するか否かで判定 - 組み込み法
モデル学習時に特徴量の選択を行う。Lasso回帰は組み込み法を用いて有用でない特徴量のウェイトを下げる。
タイタニックレベルのテーブルデータでおすすめなのが、ラッパー法です。今回は前回制作したタイタニック予測で有効だった特徴量エンジニアリングに加え、ラッパー法による精度向上を目指します。
今回の特徴量エンジニアリング
- Parch・SibspをまとめてFamilySizeを算出→alone, small, medium, bigなどの質的変数にする
- 同じチケットを持っている乗客数を特徴量(量化)にする
- Nameの敬称を特徴量にする。性別、既婚者、成人か否かを学習に使える
- 運賃Fareをビニングする。仮に5の質的変数にする
- 客室Classの頭文字を特徴量にする。客室の位置・等級などを特徴量にできる
#性別(sex)→0,1
# 古典的な男女の質的変数など、ダミー化した情報が1つで十分な場合は多重共線性対策で1つのみ情報を残す
df_train = pd.get_dummies(df_train, columns = ["Sex"], drop_first=True)
#出港地(Embarked)→0,1,2
#df_train['Embarked'].fillna(('S'), inplace=True)
df_train = pd.get_dummies(df_train, columns = ["Embarked"])
#運賃(Fare)→欠損値は平均値にする
df_train['Fare'].fillna(np.mean(df_train['Fare']), inplace=True)
#運賃(Fare)のヒストグラムを描写。ポアソン分布となる説明変数はビニングすると精度が向上する事が分かっている
#df_train['Fare'].hist(bins=50)
# NOTE 境界値を指定したビニング
bins_Fare = [0,50,100,200,300,1000]
# T_Bil列を分割し、0始まりの連番でラベル化した結果をX_cutに格納する
X_cut, bin_indice = pd.cut(df_train["Fare"], bins=bins_Fare, retbins=True, labels=False)
# bin分割した結果をダミー変数化 (prefix=X_Cut.nameは、列名の接頭語を指定している)
X_dummies = pd.get_dummies(X_cut, prefix=X_cut.name)
# 元の説明変数のデータフレーム(X)と、ダミー変数化した結果(X_dummies)を横連結
df_train = pd.concat([df_train, X_dummies], axis=1)
#年齢(Age)→欠損値は平均値・標準偏差を使って正規乱数で埋め合わせる
age_avg = df_train['Age'].mean()
age_std = df_train['Age'].std()
df_train['Age'].fillna(np.random.randint(age_avg - age_std, age_avg + age_std), inplace=True)
# 特徴量:Familysizeを作成(Parch, Sibspを足した値)
df_train['FamilySize'] = df_train['Parch'] + df_train['SibSp'] + 1
df_train['FamilySize_bin'] = 'big'
df_train.loc[df_train['FamilySize']==1,'FamilySize_bin'] = 'alone'
df_train.loc[(df_train['FamilySize']>=2) & (df_train["FamilySize"]<=4),'FamilySize_bin'] = 'small'
df_train.loc[(df_train['FamilySize']>=5) & (df_train["FamilySize"]<=7),'FamilySize_bin'] = 'mediam'
# 特徴量:TicketFreq - Ticket頻度をチケットを表す量的変数とする
df_train.loc[:, 'TicketFreq'] = df_train.groupby(['Ticket'])['PassengerId'].transform('count')
# 特徴量:HonorificをNameから抽出
df_train['honorific'] = df_train['Name'].map(lambda x: x.split(', ')[1].split('. ')[0])
df_train['honorific'].replace(['Col','Dr', 'Rev'], 'Rare',inplace=True) #少数派の敬称を統合
df_train['honorific'].replace('Mlle', 'Miss',inplace=True) #Missに統合
df_train['honorific'].replace('Ms', 'Miss',inplace=True) #Missに統合
# 特徴量:Cabin_ini - Cabinの頭文字を抽出
df_train['Cabin_ini'] = df_train['Cabin'].map(lambda x:str(x)[0])
df_train['Cabin_ini'].replace(['G','T'], 'Rare',inplace=True)
# FamilySize_bin, honorific, Cabin_iniをすべてダミー化する
df_train = pd.get_dummies(df_train, columns = ["FamilySize_bin", "honorific", "Cabin_ini"])
print("コラム名:")
print(df_train.columns)
print("コラム数:")
print(len(df_train.columns))
コラム名:
Index(['PassengerId', 'Survived', 'Pclass', 'Name', 'Age', 'SibSp', 'Parch',
'Ticket', 'Fare', 'Cabin', 'Sex_male', 'Embarked_C', 'Embarked_Q',
'Embarked_S', 'Fare_0.0', 'Fare_1.0', 'Fare_2.0', 'Fare_3.0',
'Fare_4.0', 'FamilySize', 'TicketFreq', 'FamilySize_bin_alone',
'FamilySize_bin_big', 'FamilySize_bin_mediam', 'FamilySize_bin_small',
'honorific_Capt', 'honorific_Don', 'honorific_Jonkheer',
'honorific_Lady', 'honorific_Major', 'honorific_Master',
'honorific_Miss', 'honorific_Mme', 'honorific_Mr', 'honorific_Mrs',
'honorific_Rare', 'honorific_Sir', 'honorific_the Countess',
'Cabin_ini_A', 'Cabin_ini_B', 'Cabin_ini_C', 'Cabin_ini_D',
'Cabin_ini_E', 'Cabin_ini_F', 'Cabin_ini_Rare', 'Cabin_ini_n'],
dtype='object')
コラム数:
46
特徴量選択
分析に使える特徴量が増えました。今回はRFE(Recursive Feature Elimination、再帰的特徴量削減)というラッパー法の手法で学習に使うべき特徴量をさらに選択します。
まずはデータを説明変数・目的変数に分割します。
target_col = 'Survived'
drop_col = ['PassengerId','Survived', 'Name', 'Fare', 'Ticket', 'Cabin', 'Parch', 'FamilySize', 'SibSp']
y = df_train[target_col]
X = df_train.drop(drop_col , axis=1)
今回は有力な特徴量を探索するためのモデルとしてGBDTを使い、45個の説明変数を20個に削減します。
from sklearn.feature_selection import RFE
from sklearn.ensemble import GradientBoostingRegressor
# estimatorとしてGBDTを使用。特徴量を20個選択
selector = RFE(GradientBoostingRegressor(n_estimators=100, random_state=10), n_features_to_select=20)
selector.fit(X, y)
mask = selector.get_support()
#print(X.feature_names)
print(mask)
# 選択した特徴量の列のみ取得
X_selected = selector.transform(X)
print("X.shape={}, X_selected.shape={}".format(X.shape, X_selected.shape))
[ True True True True False True True True False True True True
True False True True False False False False False True False False
True True True False False False False False True True False False
True]
X.shape=(891, 37), X_selected.shape=(891, 20)
list = []
not_selected = []
columns = X.columns
for i in range(0, len(mask)):
value = mask[i]
if (value == True):
list.append(columns[i])
else:
not_selected.append(columns[i])
print("選択された20の特徴量:")
print(list)
print("選択されなかった特徴量:")
print(not_selected)
選択された20の特徴量:
['Pclass', 'Age', 'Sex_male', 'Embarked_C', 'Embarked_S', 'Fare_0.0', 'Fare_1.0', 'Fare_3.0', 'Fare_4.0', 'TicketFreq', 'FamilySize_bin_alone', 'FamilySize_bin_mediam', 'FamilySize_bin_small', 'honorific_Master', 'honorific_Mr', 'honorific_Mrs', 'honorific_Rare', 'Cabin_ini_D', 'Cabin_ini_E', 'Cabin_ini_n']
選択されなかった特徴量:
['Embarked_Q', 'Fare_2.0', 'FamilySize_bin_big', 'honorific_Capt', 'honorific_Don', 'honorific_Jonkheer', 'honorific_Lady', 'honorific_Major', 'honorific_Miss', 'honorific_Mme', 'honorific_Sir', 'honorific_the Countess', 'Cabin_ini_A', 'Cabin_ini_B', 'Cabin_ini_C', 'Cabin_ini_F', 'Cabin_ini_Rare']
これで特徴量の生成・選択が完了しました。あとはベースラインと同じ方法で学習を行い、精度向上の効果があるかを検証します。
モデル作成 → 学習
X_train, y_train, id_train = X[list], df_train[["Survived"]], df_train[["PassengerId"]]
# データ形状が問題ないか判定
print(X_train.shape)
print(y_train.shape)
print(id_train.shape)
(891, 20)
(891, 1)
(891, 1)
# ホールドアウト検証 - 学習用・テスト用の分割を1通り決める
X_tr, X_va, y_tr, y_va = train_test_split(X_train, y_train, test_size=0.2, shuffle=True, stratify=y_train, random_state=123)
print("学習用・訓練用データの形状:")
print(X_tr.shape)
print(y_tr.shape)
print(X_va.shape)
print(y_va.shape)
# データのラベルに偏りがないか表示
y_train_mean = y_train["Survived"].mean()
y_tr_mean = y_tr["Survived"].mean()
y_va_mean = y_va["Survived"].mean()
print("全体の生存者割合:")
print(y_train_mean)
print("学習用データの生存者割合:")
print(y_tr_mean)
print("検証用データの生存者割合:")
print(y_va_mean)
学習用・訓練用データの形状:
(712, 20)
(712, 1)
(179, 20)
(179, 1)
全体の生存者割合:
0.3838383838383838
学習用データの生存者割合:
0.38342696629213485
検証用データの生存者割合:
0.3854748603351955
# LGBMのパラメータ
params = {"boosting_type":"gbdt",
"objective":"binary",
"metric":"auc",
"learning_rate":0.1,
"num_leaves":16,
"n_estimators":1000,
"random_state":123,
"importance_type":"gain",
"early_stopping_round":100,
"verbose":10
}
# LGBMのモデル
model = lgb.LGBMClassifier(**params)
model.fit(X_tr, y_tr, eval_set=[(X_tr, y_tr),(X_va, y_va)])
Early stopping, best iteration is:
[16] training's auc: 0.912818 valid_1's auc: 0.88004
学習段階での検証データのAUC率は0.88と、かなり高い値に改善することができました。
# AUC値に加え精度を算出する
y_tr_pred = model.predict(X_tr)
y_va_pred = model.predict(X_va)
metric_tr = accuracy_score(y_tr, y_tr_pred)
metric_va = accuracy_score(y_va, y_va_pred)
print("モデル精度:")
print("学習精度")
print(metric_tr)
print("検証精度")
print(metric_va)
モデル精度:
学習精度
0.8553370786516854
検証精度
0.8324022346368715
正答率の値も83%程と、かなり向上しました。特徴量生成と特徴量選択は精度向上にとても効くことが分かります。
モデル学習 - LazyPredict
最後に、LazyPredictでモデルを作成します。
import lazypredict
from lazypredict.Supervised import LazyClassifier
reg = LazyClassifier(ignore_warnings=True, random_state=1121, verbose=False,predictions=True)
models, predictions = reg.fit(X_tr, X_va, y_tr, y_va)
print("モデルの精度・評価指標:")
display(models)
print("テストデータの予測値:")
display(predictions)
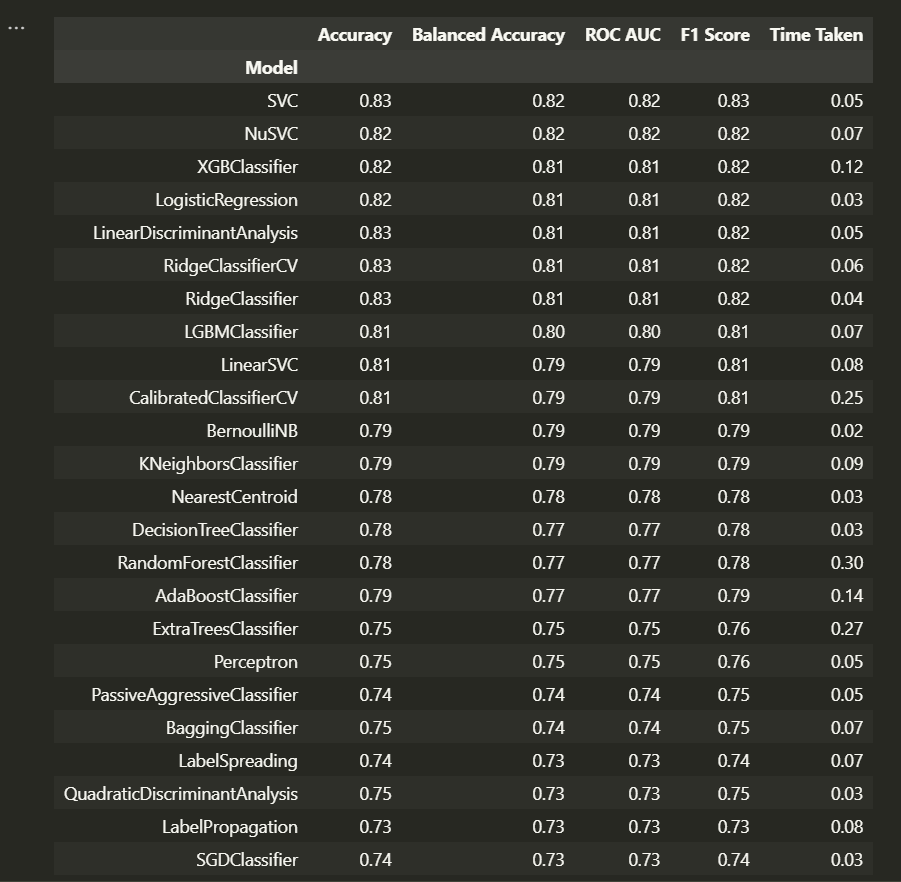
特徴量生成・選択をした状態ではSVC・NuSVCなどサポートベクターマシン系のモデルの精度が向上していることが分かります。
次回はモデルのファインチューニングによる精度向上を目指します。乞うご期待。