はじめに
今回は、姿勢推定における一般的なアプローチの紹介と、最新論文を1つ紹介する。
紹介する論文は、Cascaded Pyramid Network for Multi-Person Pose Estimation1。
(特に断りのない限り,本記事で使用する画像は、こちらの論文1からの引用。)
姿勢推定の主なアプローチ
姿勢推定モデルには、大きく2つのアプローチがある。
- ボトムアップ型: 画像中のキーポイントを全て洗い出したあと、人物ごとにマッチングさせて繋ぎ合わせていくやり方。
- トップダウン型: まず人物を検知し、その後、それぞれの人物についてsingle person pose estimationを行うやり方。
ボトムアップ型
ボトムアップ型は、最初にキーポイントを洗い出したあと、それらを繋ぎ合わせていくことで、姿勢を推定する。
トップダウン型の手法に比べると、計算量は抑えられるが、画像全体のコンテキストを十分に考慮できていないため、部位間の繋ぎ合わせの精度が低い という欠点がある。
参照:DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation2
トップダウン型
①物体検知アルゴリズムで人物を検出
↓
②それぞれの人物について、姿勢を推定
人数に比例して計算量も増加してしまうのが欠点だが、各人に対して姿勢推定を行う(single person pose estimation)ので、精度高く推定できる。

参照:Multi-Person Pose Estimation with Local Joint-to-Person Associations3
両方に共通する課題
次のような状況のときは、ボトムアップ型・トップダウン型を問わず、推定が難しい。
- 物に隠れて見えないとき
- 背景と人が同化(例:白シャツに白い背景)しているとき
最新論文(Cascaded Pyramid Network)の紹介
今回は、Cascaded Pyramid Network(CPN) for Multi-Person Pose Estimation1という論文を紹介する。
この論文では、トップダウン型のアプローチによる姿勢推定手法が提案されている。
トップダウン型なので、ステップは次の2段階:人検出 ➔ 姿勢推定
CPNのブレイクスルー: キーポイントが隠れていたり、背景が紛らわしい場合でも、高い精度で推定が可能!
1. 人検出
人検出には、Feature Pyramid Network(FPN)**4をベースにしたモデルを使っている。ただし、RoI Poolingの部分は、RoI Alignに変更されている。(※RoI PoolingよりRoI Alignのほうが優れている理由は、こちらの記事で解説。)
2. 姿勢推定
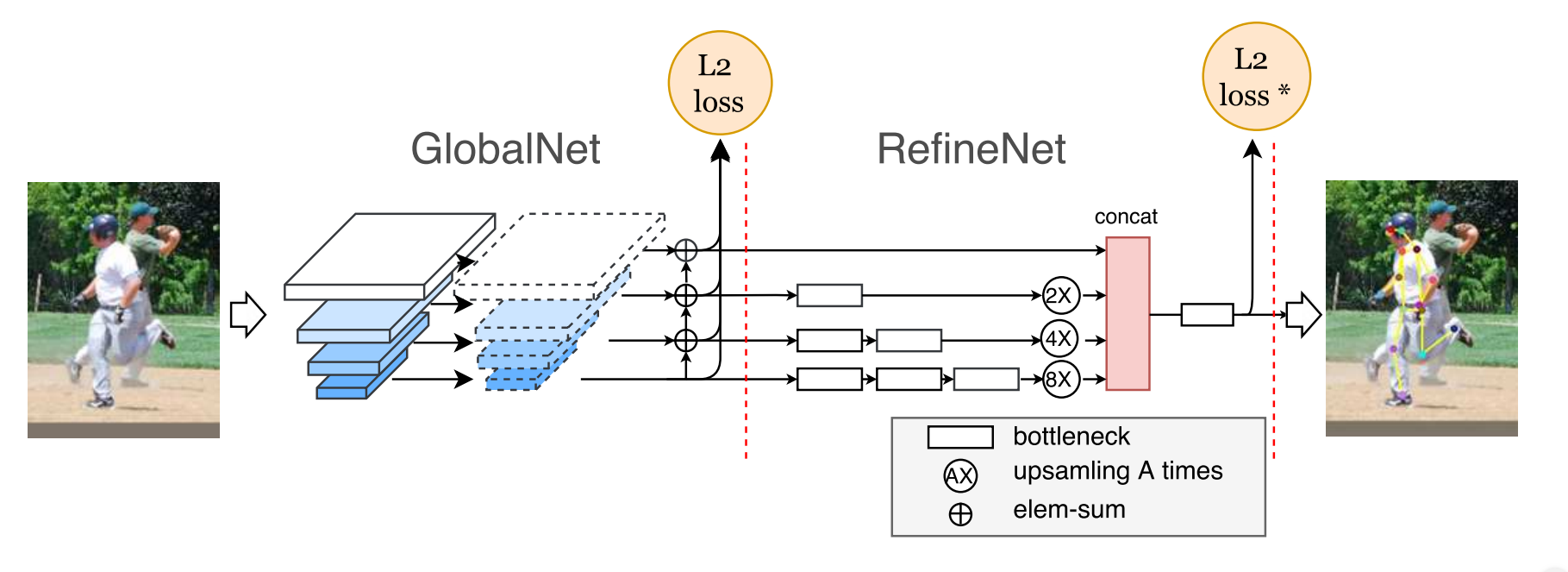
この論文では、Cascaded Pyramid Network(CPN)と呼ばれるネットワーク構造が提案されている。
CPNは、GlobalNetとRefineNetと呼ばれる2つのステージから成っている。
GlobalNetは、ResNet4 backboneをベースにしたFPN5のようなU字型構造をしたネットワークで、"簡単明瞭(simple)"なキーポイントを探すことができる。一方、RefineNetは、GlobalNetで生成したそれぞれの階層の特徴量をアップサンプリングし、HyperNet6のようにconcatenateすることで特徴量の情報を統合するネットワークで、見つけ難いキーポイントの推定を可能にしている。
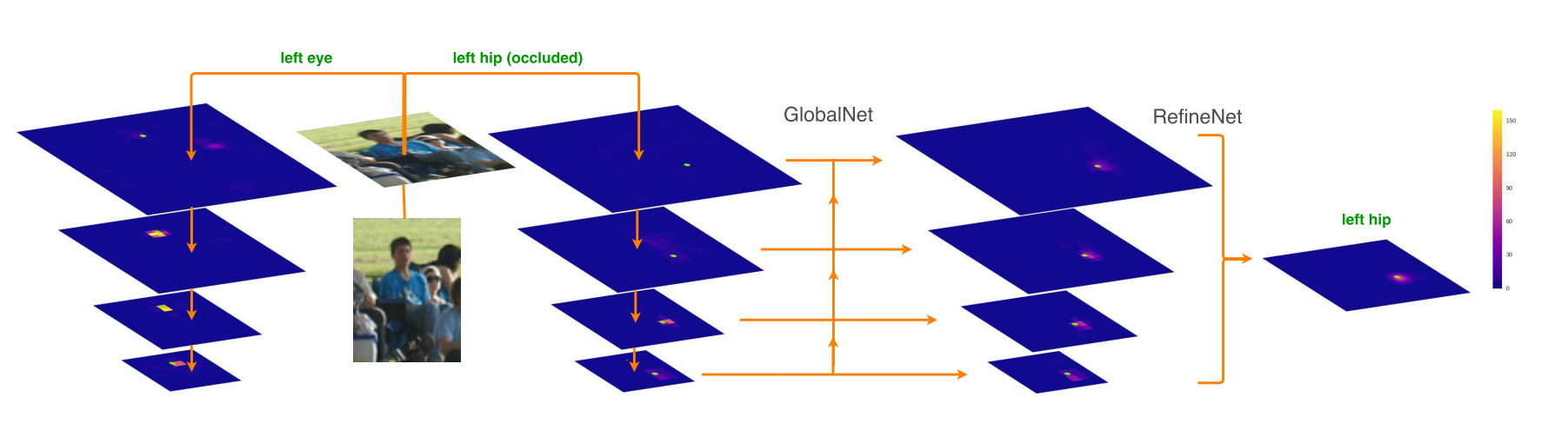
下の画像では、顔や肩ははっきり見えているが、ヒップは映っていないため推定が難しい。

ヒップのように隠れたキーポイントを推定する場合、局所的な特徴量よりも、抽象度が高い意味情報(コンテキスト)が必要で、その役割を担うのがRefineNet。
RefineNetは、Stacked hourglassに似ているが、stacked hourglassのようにアップサンプリングされた最後の特徴量だけを使うのではなく、GlobalNetで生成された全ての層の特徴量を、concatenateして余すとこなく使っている点が異なる。
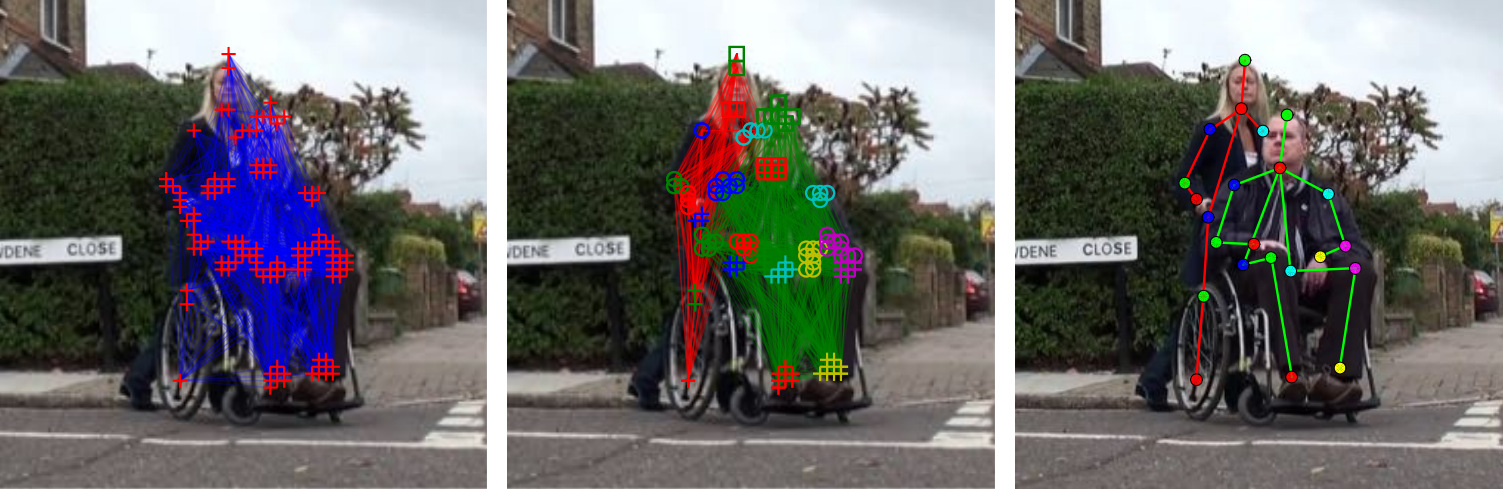
これらによって、以下の画像のように姿勢推定が可能になる。3枚目の右端の男性は、足が一部見えないが、おおよそ正しい位置を推定できている。

まとめ
姿勢推定における一般的なアプローチ2種類の紹介と、最新論文を1つ紹介した。
最新論文では、隠れて推定しづらいキーポイントでも、精度高く推定できる手法を紹介した。
おわりに
ヒトやモノをデータ化&解析してみたい、という方。
3D技術と深層学習を組み合わせて、何か面白いサービスを作ってみたい!、という方。
弊社では一緒に働いてくれる仲間を大募集しています。
ご興味がある方は下記リンクから是非ご応募ください!
https://about.sapeet.com/recruit/