
READYFORのシステム基盤部でエンジニアリングマネージャーをしている熊谷です。
この記事は READYFORアドベントカレンダー2021、16日目の記事です。
これなに?
EMの取り組みを紹介
今日は、これまでシステム基盤部のエンジニアリングマネージャーとして、READYFORのシステム開発を推進する上で、検討した事や取り組みについて紹介させていただけたらと思います。正直、まだ取り組み始めたばかりの項目もあり、詰め切れていない部分も多々あるのですが、同様の取り組みを検討・実施されている方で、何か一つでも参考になれば幸いです。
この記事で書かれていること
ざっと以下のような事を記述しています。
- 現状の理解と役割の明確化
-
エンジニアリング組織体制を理解する
- スクワッド体制とは?
- READYFORのスクワッド体制の紹介
-
エンジニアリングマネージャーの役割を理解する
- 考察①:EMの業務範囲について
-
マネージする部署・チームの役割を理解する
- 考察②:部署間での位置付けを理解する。
- 考察③:事業全体での位置付けを理解する。
- 今後の方向性について検討する
- データ駆動型のエンジニアリングに向けて
-
取り組みの紹介
- 取り組み①:DX Criteria
- 取り組み②:LeanとDevOpsの科学
- 取り組み③:SRE (サイト信頼性エンジニアリング)
- おわりに
1. 現状の理解と役割の明確化
1-1. エンジニアリング組織体制を理解する
はじめに。エンジニアリングマネージャーとしての話をする前に、**READYFORの「スクワッド体制」**について、触れておく必要があります。
1-1. スクワッド体制とは?
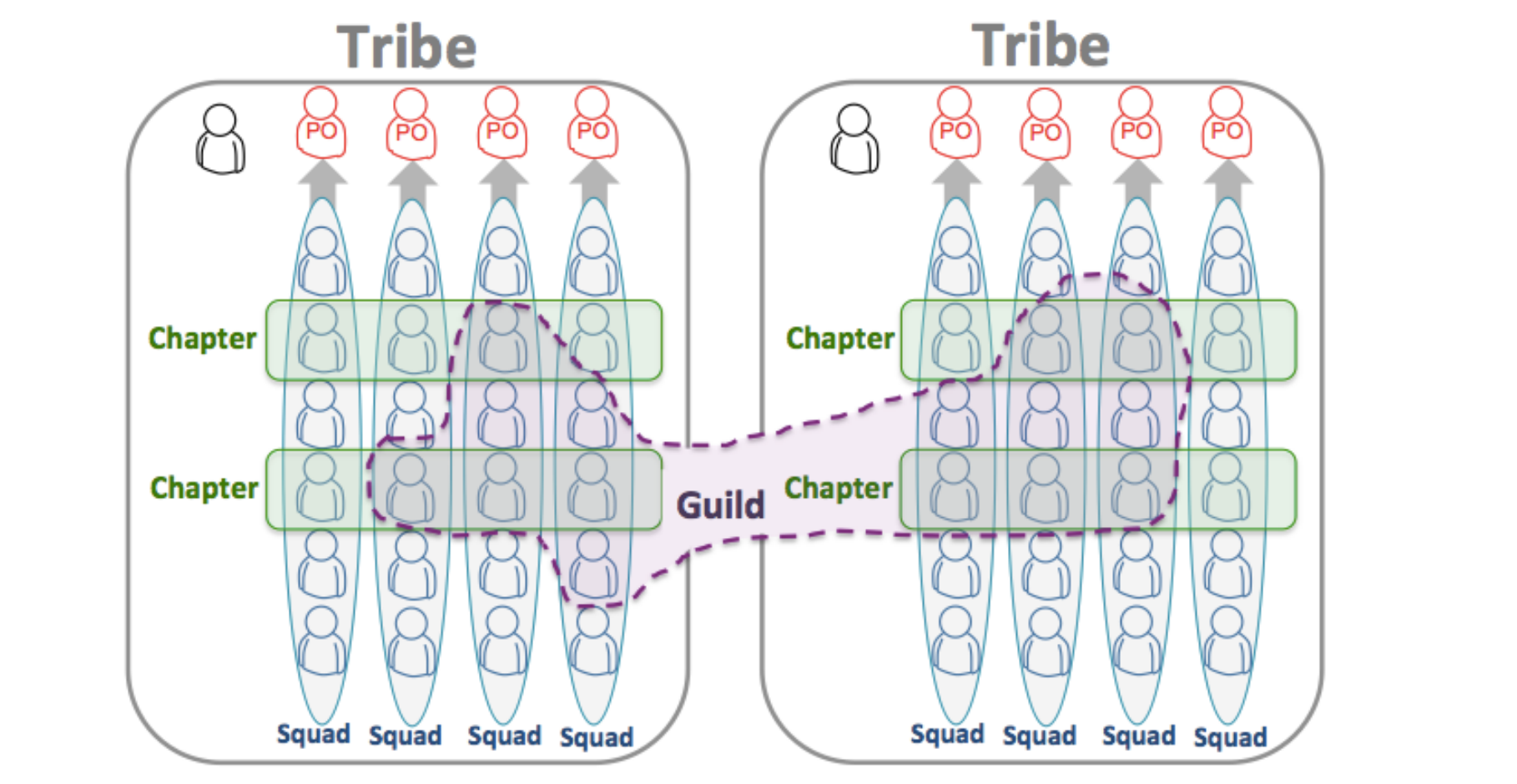
図1. Scaling Agile Spotify [1]
ご存知の方も多いかと思いますが、スクワッドとは少人数で職能横断型のチームで、ミッションに基づき、スクワッド内で意思決定をし、業務を遂行します。スクワッドに与えられるミッションは、抽象度が高く、企業レベルの大きな目的達成に方向付けられます。
また、ミッションに関しては、**「ユニコーン企業のひみつ[2]」**で紹介されている、ミッション/プロジェクトとの比較がわかりやすいと思います。プロジェクトと比べ、より主体的な動きを促すような設計になっていることがわかります。
| プロジェクト | ミッション |
|---|---|
| 予算がある | チームの人数が予算 |
| 終わりがある | 期間に定めがない |
| 短期間 | 長期間 |
| プロジェクトマネージャーがいる | プロジェクトマネージャーがいない |
| 開発だけして引き継ぐ | 開発もメンテナンスもする |
| 完成したら解散する | チームは一緒のまま |
| 計画にフォーカス | 顧客にフォーカス |
| 期待に応じることが価値 | インパクトが価値 |
| トップダウン | ボトムアップ |
スクワッド体制における留意点として、**「Spotifyは "Spotifyモデル "を使っていない [3]」**で以下のように述べられているように、単に方法論を真似るのではく、自分の組織と向き合い、学習して、進化し続けることが大切であると思います。READYFORにおいても日々、組織体制について議論し、改善を進めています。
ビジネスユニット、部門、チーム、マネージャーは、Spotifyの失敗した方法論に固執してはいけません。彼らはSptifyのモノマネよりも効果的に組織構造の役割と責任を伝えることができるのです。
あなたがSpotify Modelを見つけたのは、自分のチームをどのように構成するかをいつも考えていたからでしょう。でもここで止まってはいけません。学習を続けてください。
1-2. READYFORのスクワッド体制
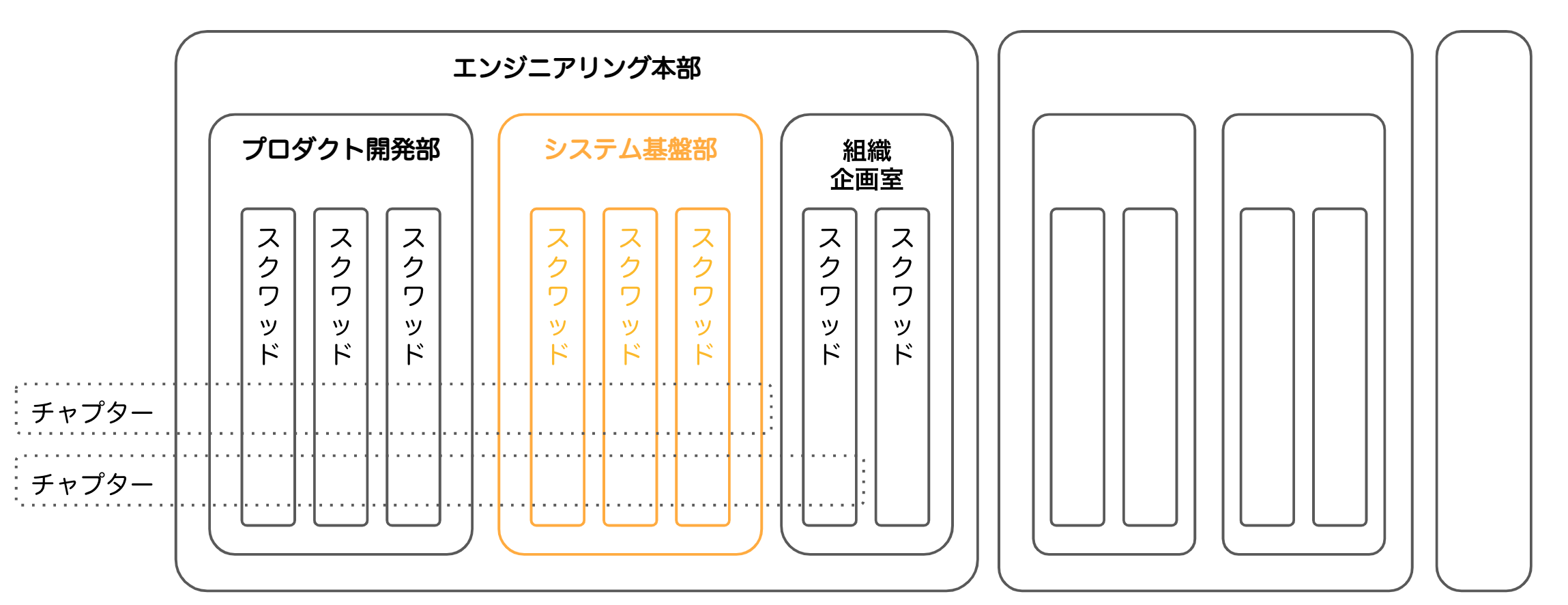
READYFORの場合、どのようなスクワッド体制を敷いているか?
ひとえにスクワッド体制とはいえ、どのように最適なミッション・スクワッドを作るかは悩ましいところです。また、スクワッド体制を採用している企業でもそれぞれで異なっていると思います。
READYFORの場合、エンジニアリング本部に、プロダクト開発部、システム基盤部、組織企画室が配置され、それぞれにスクワッドが所属する体制をとっています。私は、そのエンジニアリング本部のシステム基盤部に所属しています。
プロダクティビティスクワッド
システム基盤部のスクワッドの役割イメージとしては、「ユニコーン企業のひみつ」[2]の「第7章:生産性向上に投資する」で紹介されている以下のプロダクティビティスクワッドに近いと思います。
プロダクティビティスクワッドとは。
他のエンジニアリングチームを早く進めるようにすることをミッションとしたチームだ。
プロダクティビティスクワッドとか開発基盤スクワッドと呼ばれるチームの仕事だ。彼らは他のチームを支援する。例えば、こんな風に、
1. ビルドの自動化
2. 継続的インテグレーションの整備
3. A/Bテスティングフレームワークの構築
4. 本番環境のデプロイメント/監視ツール作成
5. 自動テスティングフレームワークの構築
6. 新機能を簡単に追加できる基盤の用意
7. トレーニングセッションの開催
8. データの変換や移行
9. イテレーションと学習速度の向上
また下記の記述の通り、開発の取り締まりをするのではなく、**「チームができることを増やして、チームが自分達で支援を受けられる手段を提供する」**というのも同様で、重要なポイントだと思います。
プロダクティビティスクワッドの特筆する点として、彼らは他スクワッドが本番環境にデプロイするのを取り締まる「門番」ではないということだ。
プロダクティビティスクワッドは、本番環境とスクワッドとの立ちはだかる壁ではない。チームができることを増やして、チームが自分達で支援を受けられる手段を提供する。
1-2. EMの役割を理解する
組織体制を踏まえた上で、エンジニアリングマネージャーとしてどのような動きが求められるのか?
大きくは、事業全体を俯瞰しつつ、課題・ボトルネックはどこにあるのか、そして、それをどのように解決するのかを繰り判断し、推進していく事が求められます。要は課題発見と解決ですね。ただ、その前に自身の注力範囲を明確にしておくことが必要だと思います。特に、エンジニアリングマネージャーは定義が曖昧なところがあり、企業や事業フェーズによっても異なるため、そこの理解を深めるところから始めました。
考察①:EMの業務範囲について
エンジニアリングマネージャーの業務に関しては、**広木 大地さんの「エンジニアリングマネージャ/プロダクトマネージャのための知識体系と読書ガイド[5]」**がとてもわかりやすいのため、いつも参考にさせていただいています。
厳密には定義できないですが、今現在、自分の場合は、「ピープルマネジメント」と「テクノロジーマネジメント」が主なスコープになると思います。**「弱いEM定義 + α」**といったところでしょうか。この辺りは、組織体制が「システム基盤部」と「プロダクト開発部」に上手く分かれていることにも起因していると思います。
ただ、これはあくまで自分の場合です。READYFORには、経験豊富で素晴らしいエンジニアリングマネージャーが何人も在籍していますが、各々でスキル・経験や担当業務も異なり、EM定義の範囲もそれぞれです。
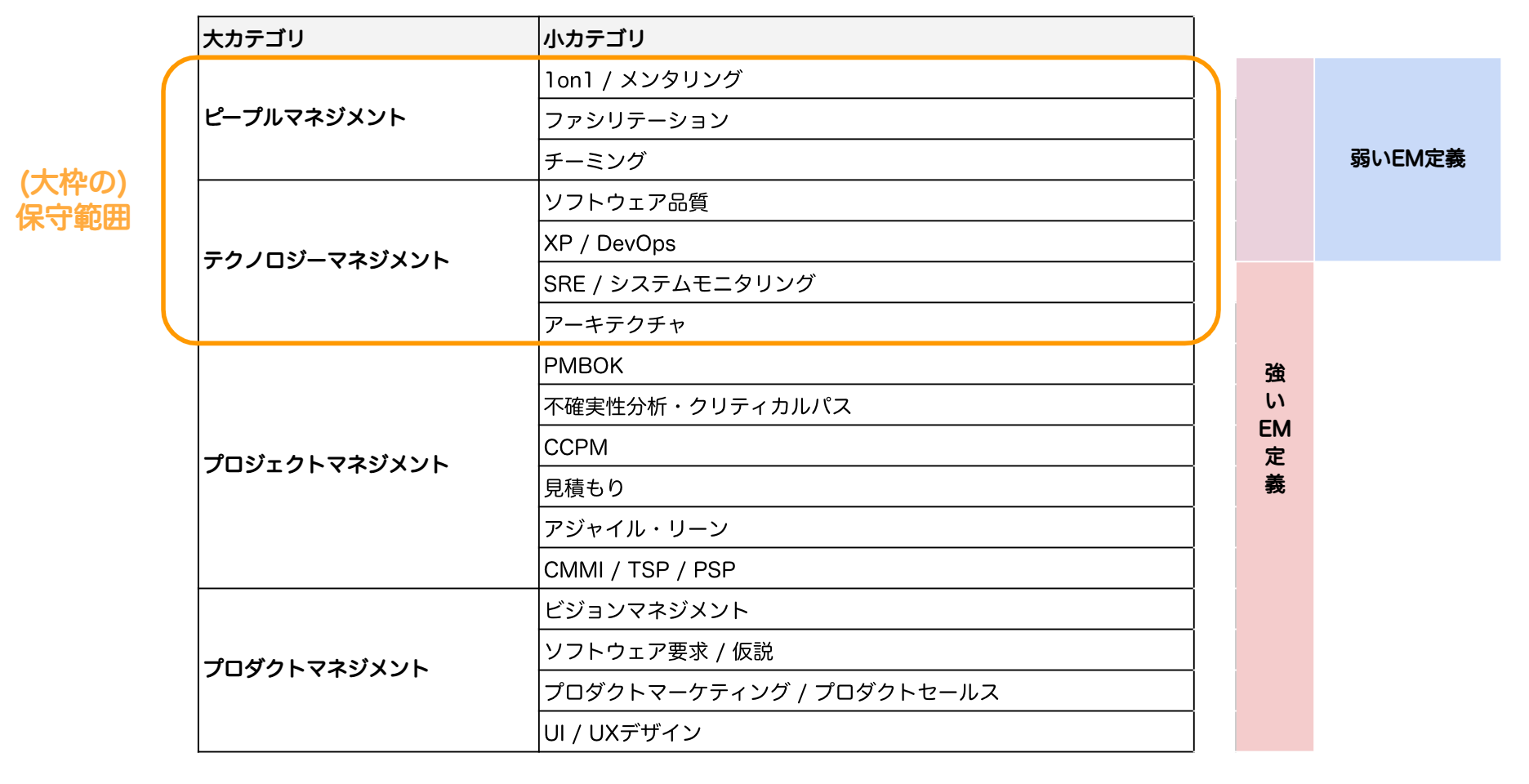
参考:「エンジニアリングマネージャ/プロダクトマネージャのための知識体系と読書ガイド[5]」
また、EMの業務範囲に関しては、以下の記述の通り、各々の得意分野の他、事業や組織のステージにより変化していく必要があると思うので、そこは柔軟に対応していきたいと思っています。
EMもPMも現在は残念ながら、異なる技術や知識体系から自社の今のステージにとって、必要なものを再構成して、適用していく能力が求められることになります。そうであるがゆえに難しく楽しいものではあるのですが。
1-3. マネージ部署・チームの役割の理解
考察②:部署間での位置付け
組織体制とEM定義の他、自分の担当部署に関しても、目的を理解するところから始めました。
各スクワッド名など詳細は割愛させていただきますが、大きくは以下の構成となっています。
- **「プロダクト開発部」のスクワッド:**主に事業数値に直結するプロダクト開発などを担当
- **「システム基盤部」のスクワッド:**主に開発生産性向上や各種基盤構築などを担当
- **「組織企画室」のスクワッド:**主にエンジニアリング組織拡大・文化形成や組織パフォーマンスの最大化などを担当

重ねてになりますが、上記は今現時点での最適だと考えられる体制であり、事業フェーズなどに合わせ、今後も進化していくと思います。また、これは企業共通の解があるわけではなく、各々の事業の状態と向き合い、メンバーと最適な形を模索し、考え抜くことが大切であると思います。
システム基盤部:推進項目の考察
システム基盤部の目的をもう少し分解すると、以下のようになります。各スクワッドごとに多くの施策が検討・実施されていますが、それぞれがどこに貢献するのか明確にしています。そうすることで、全体の方向付けや進捗を確認する際に活用することができます。
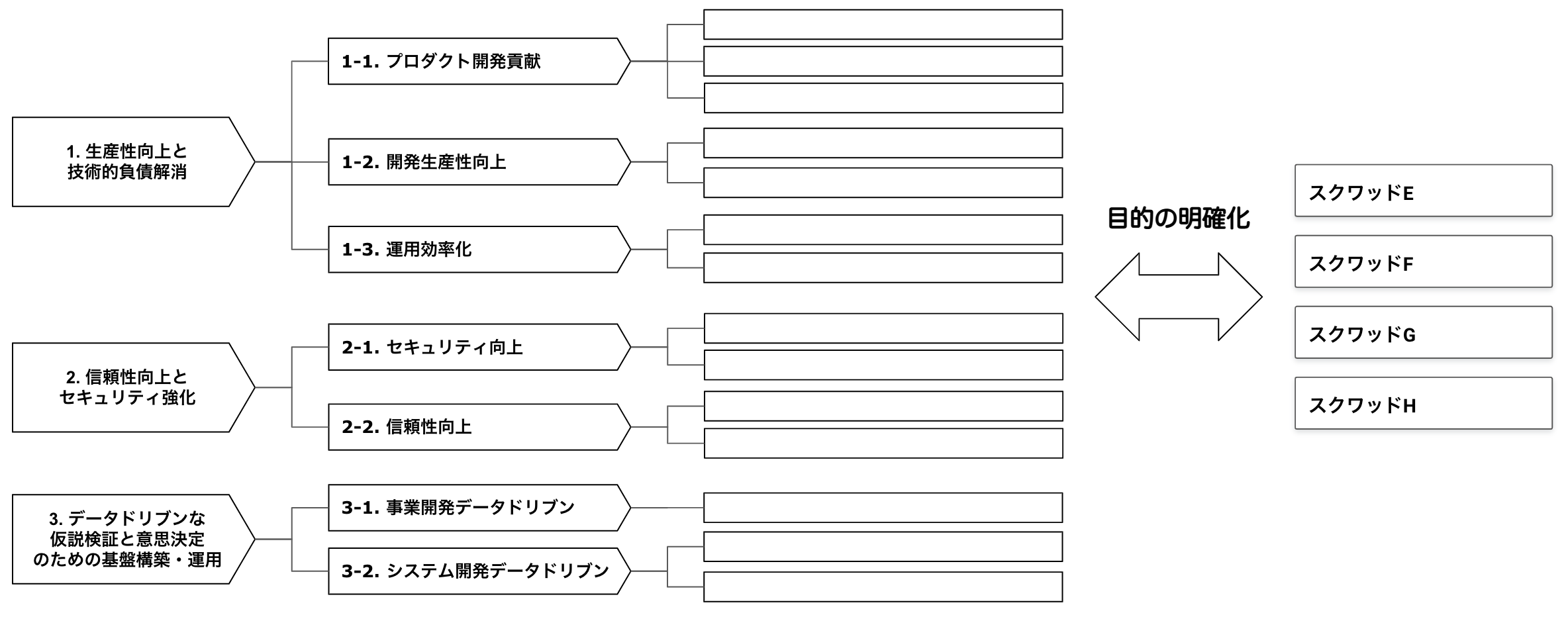
システム基盤部:開発サイクルの関係
また、上記の推進項目を別の角度でみると、システム基盤部は「開発サイクルの質・スピードの向上」を目指していると捉えることができます。いかにサイクルを高速に回すにはどうすればいいか、そのためにはボトルネックを明確にし、適切なアプローチを選択し続ける必要があると思います。そこに関しては後述させていただきます。

考察③:事業全体の位置付け
システム基盤部を担当するとはいえ、システム基盤部の事業全体における位置付けと影響範囲は、最低限理解する必要があります。**「エンジニアリング組織論への招待 [6]」**に以下の言及がありますが、事業全体を俯瞰し、システム基盤は何を解決しようとしているのか、という観点は常に意識しておくことが大切だと思います。
... 問題の解決よりも問題の明晰化の方が難しい
1-6. 全体論とシステム思考
.... システムとは全体の関係性を捉えること
... 部分だけしか見ないことで対立が起きる
流石にこれは公開できないのですが、事業上の主要な数値を整理し、全体と各部署・スクワッドとの関係性の分析を行いました。予め、全体感を理解していくことで、部分最適を避け、他部署との対立を避けることにも繋がると思います。事業数値に対して、システム基盤部の施策はその特性上、どうしても間接的なものが多くなりがちですが、最終的にどのように事業価値に繋がるのかを理解することは、今後の意思決定の確度を高める上でも必要だと感じています。

**「エンジニアリング組織論への招待[6]」では、「ロジックツリーによる分析」と「システム思考による分析」**が紹介されていますが、自分の場合は、前者を使用することが多いです。
また、**「全体の関係性を捉える」**という観点で、他部署との関係性を知ることも大切だと思います。各部署がどのような業務を担っているのか、例えば、**バリューチェーン(組織が生み出す価値の流れ)**を考えながら、システムにおける役割・関連度合いを紐付けていくなどすると、わかりやすいように思います。
**「全体の関係性を捉える」**ためには、他にも様々なフレームワークがありますし、深堀りするとどこまでもできてしまうと思います。ただ最低でも、事業全体の主要指標や関連部署の理解は深めていきたいものです。
※ 少し話は逸れますが、部署間の関係や取り組み強化という観点で、READYFORでは 「乳化」という取り組みを全社的に推進しており、「組織の中にエンジニアリングが自然に溶け込んでいる状態」を目指しています。
2. 今後の方向性について検討する
2-1. データ駆動型のエンジニアリング
システム基盤部の目的や位置付けを明確にした後、次に考えなければいけないことは、システム基盤部の取り組みをどのように最大化させるかです。
当たり前ですが、リソースには限りがありますし、大変貴重です。また、組織が拡大するにつれ、チームやプロジェクトも増えていきます。事業に大きく貢献するには、適切な方向に、それぞれが最大限パフォーマンスを発揮し、自走することが必要不可欠であると思います。
大小様々な施策が考えられる中、改善効果の高い施策に選択と集中するにはどうすれば良いか。他企業の取り組みなどを参考にさせていただきつつ、以下の取り組みを検討・実施しています。
-
DX Criteria アセスメントシート
- 市場比較しながら俯瞰的に問題点を見出し、方針を検討する時の判断材料として活用しています。メンバー全体で課題認識の強化や期末の振り返りなどにも有効です。あまり気軽には実施はできないため、半期 or 1年くらいの実施が妥当だなと考えています。
-
LeanとDevOpsの科学「パフォーマンス計測指標」
- 「開発の質とスピード」が改善されているか計測するための指標。書籍に記載されている「改善効果の高いケイパビリティ」は、統計的に優位な改善項目が整理されており、DX Criteriaのアセスメントシートと併用しながら、施策の検討フェーズや意思決定時に判断材料として利用すると、より効果的だと思います。
-
SRE (サイト信頼性エンジニアリング)
- SREは、上二つとは少しアプローチが異なりますが、SREも事実に基づくアプローチを拠り所としており、取り組みも似通っているため、とても親和性が高いと思っています。SREのプラクティスは有用なものが多く、それぞれ融合させながら最適解を導き出せたらと考えています。
2-2. READYFORの取り組みの紹介
取り組み①:DX Criteria
まず最初に、DX Criteriaアセスメントシートをどういう枠組みで実施するか悩みました。
他社の事例では、CTOやリードのみなど実施者を絞っている企業が多いように思いましたが、READYFORでは、「system」カテゴリのみに絞り、バックエンドのエンジニア全員で実施しました。全員野球ではないですが、現場のメンバ全員が以下の観点を持ち、取り組めた方が、結果的に全体の問題解決の速度が上がるのではと考えました。
- **全体共有:**課題感の認識と全体の方向性をチーム内で共有して、進められるようにする。
- **振り返り:**定期的に、何がどのように良くなったのか、改善項目を振り返られるようにする。
- **問題解決:**個々でも、MECEに全体を意識しながら、問題解決に取り組めている状態になる。
- **市場比較:**自社の強み・弱みを理解することができ、他社との市場比較をすることできる。
包み隠さず、アセスメントシートの実施結果を公開しますが、以下の結果となりました。
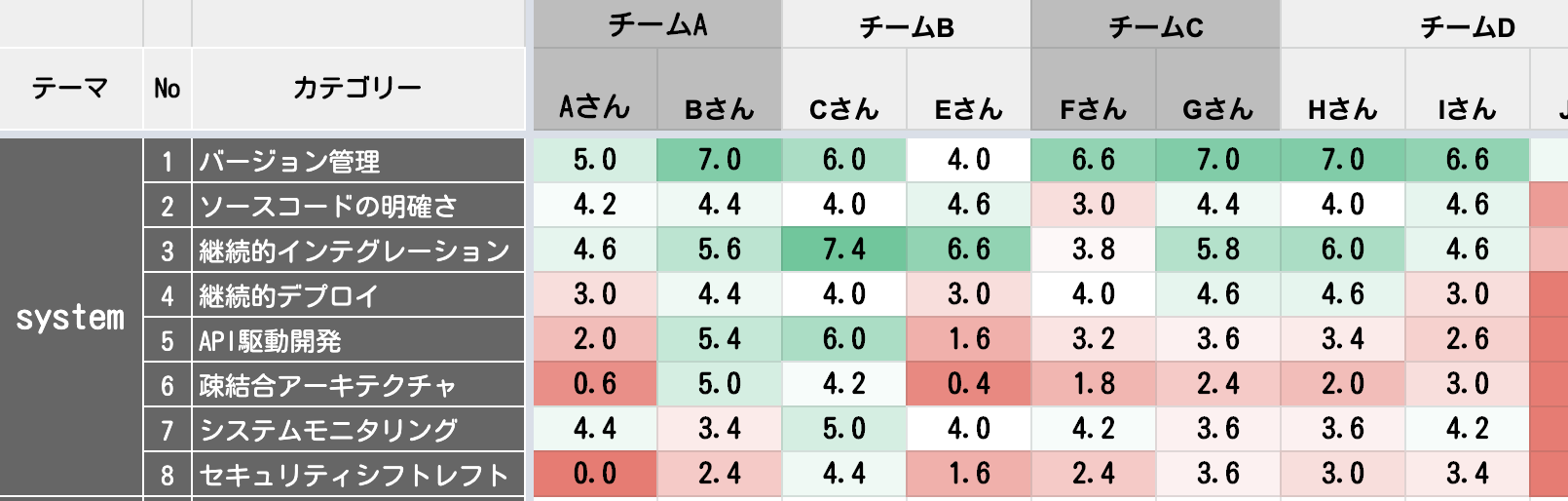
点数にばらつきはあるものの、ある程度傾向が見えてきます。点数のばらつきの要因としては、アセスメントシートの質問自体が抽象的で判断がしずらい項目があるのと、チーム・メンバによって扱うシステムや体制が微妙に異なることに起因していると思います。
各項目の平均点と順位は以下のようになります。(ちなみに当時は「継続的デプロイ」の開発者体験は良くなかったのですが、その後、SREチームの尽力もあり、大幅に点数が向上しています。そういった事を振り返られることもこの取り組みの利点だと思います。)

DX Criteriaアセスメントシートの実施にあたり、以下を参考にさせていただきました。
取り組み②:LeanとDevOpsの科学
パフォーマンス計測指標とは?
「LeanとDevOpsの科学 [12]」には、「望ましい尺度」の二つの特徴 として以下のように述べられ、開発組織のパフォーマンスを測定する四つの有効な指標が挙げられています。
- チーム同士が対立するような状況を防ぐ機能を持つことである。「混乱の壁」=開発側と運用側に隔てる縦割りの壁があってはならない。
- 「生産量」ではなく「成果」に焦点を当てる。「忙しいが価値のない、見せかけの作業」を重ねて大量の仕事をすることが評価されてはならない。
四つの有効な指標の説明を抜粋すると以下の通りです。簡単に説明させていただきます。
-
「リードタイム」
- **概要:**リードタイムは以下に大別されるが、前者は計測開始時期が不明確で変動が非常に多いのに対し、後者は変動も比較的小さく測定も比較的容易である。
-
- 機能の設計と検証にかかる時間
-
- 機能を顧客に納品するまでの時間 ← こちらを測定する。
-
-
期待する効果:
- 「顧客のフィードバックを受け、高速に対応できる。」
- 「不具合対応や稼働停止からの復旧も迅速になる。」
- **概要:**リードタイムは以下に大別されるが、前者は計測開始時期が不明確で変動が非常に多いのに対し、後者は変動も比較的小さく測定も比較的容易である。
-
「デプロイ頻度」
- **概要:**本来はバッチサイズの削減によって得られる効果を測定したかったようだが、バッチサイズの測定は難しいため、代替としてデプロイ頻度を測定基準に決めたとある。
-
期待する効果:
- サイクルタイムの削減
- フローによる変動の低減
- フィードバックの高速化
- リスクを諸経費の低減
- 効率、モチベーションの向上
- コストとスケジュールの膨張の抑制
-
「平均修復期間(MTTR:Mean Time To Repair)」
- 概要:「リードタイム」「デプロイ頻度」は速度に関する指標であるが、これは 「システムの安定性を犠牲にして改善を実現したのか」 を測るための指標。
-
期待する効果
- TTD:認知までの時間を最小化
- TTE:エスカレーションとアサインの自動化
- TTF:高速なロールバック、フェイルオーバー、再構築、増強
-
「変更失敗率」
- **概要:**本番環境での稼働に失敗したケースの発生率。主要なサービスに施した変更のうち、サービス低下を招いたケースや修正作業が必要となったケース(サービス機能の障害や稼働停止を招いてしまったケース、ホットフィックス、ロールバックなど)
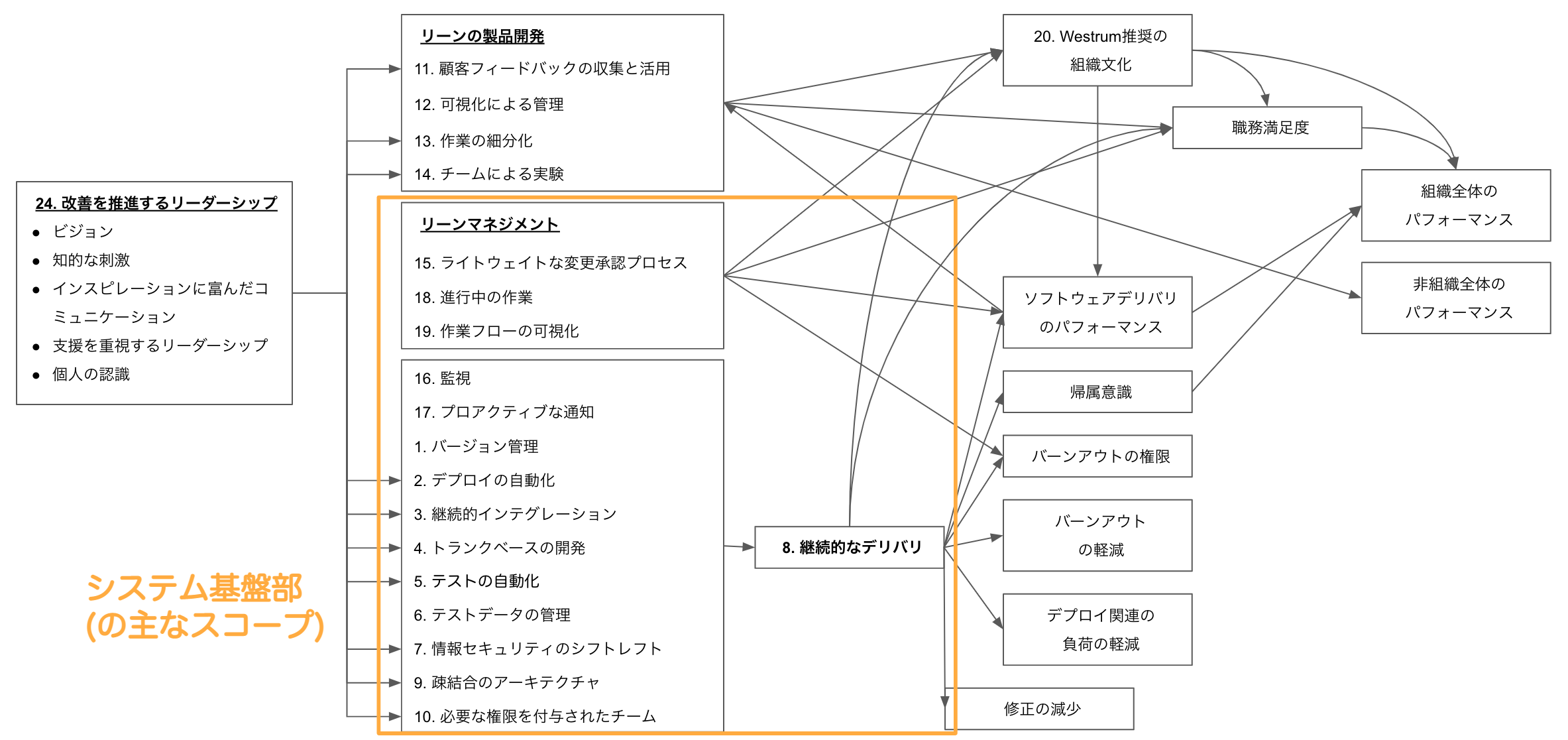
「改善効果の高いケイパビリティ」
**「LeanとDevOpsの科学 [12]」の「改善効果の高いケイパビリティ」**として以下のカテゴリ・項目が記されています。**システム基盤部の主なスコープとしては「継続デリバリ」〜「リーンマネジメント」**だと考えています。書籍の中で、それぞれの項目がなぜパフォーマンス指標に効果的であるのか詳細も記載されているため、一読しておくと良いのではと思います。
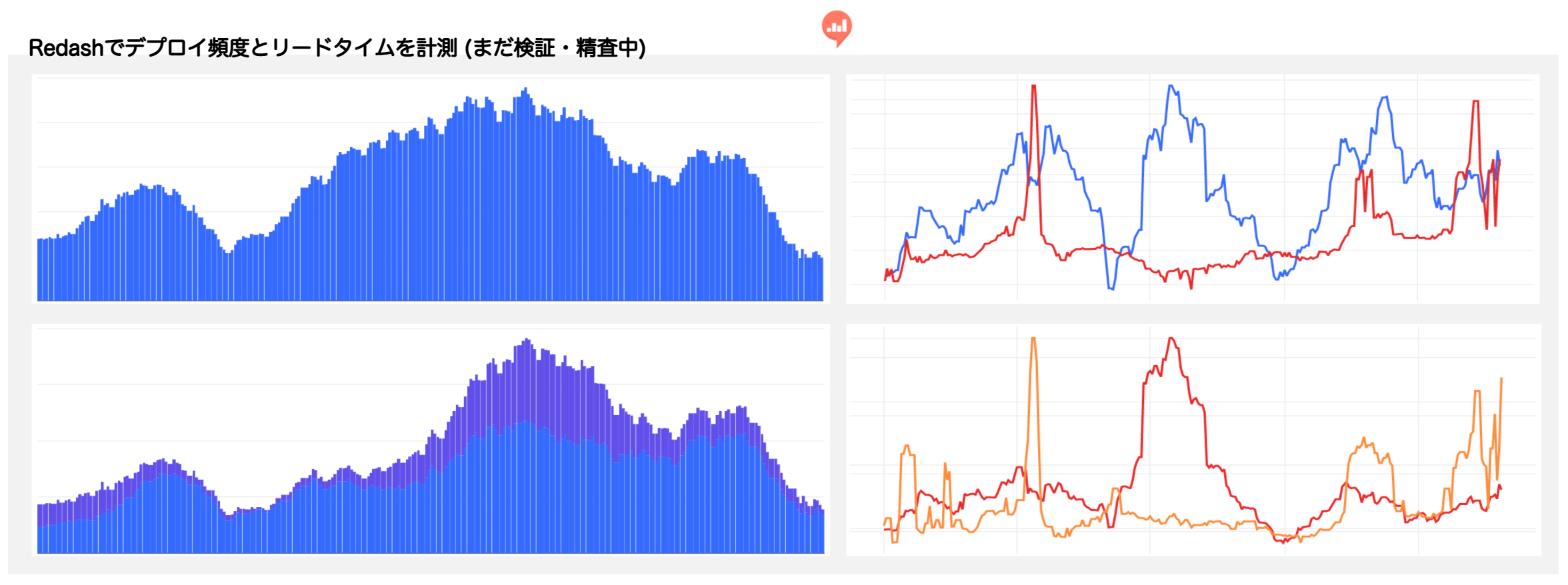
デプロイ回数とリードタイムの可視化
READYFORでは、GithubのデータをBigQueryにインポートして、そこからデプロイ頻度やリードタイムをRedashで可視化しています。ただ、まだ精査・検討中ということもあり、詳細はお見せできないのですが、以下のように可視化し、定期的に観測・振り返りをしながら、改善に活用していこうとしています。
※ 余談ですが、Github上の指標計測に関しては、「LeanとDevOpsの科学」の著者ニコール フォースグレン氏が2020年にGitHubリサーチ&ストラテジーのバイスプレジデントとして任命され、Githubロードマップに以下のようなIssueも起票されているので、今後の機能拡張に期待です。
取り組み③: サイト信頼性エンジニアリング
SLI/SLOの導入・運用
**パフォーマンス計測指標の「平均修復期間(MTTR)」に関連するところで、サイト信頼性エンジニアリング(SRE)の本格的な導入・運用を目指し、絶賛検討中です。MTTRの中で、特に「TTD:認知までの時間を最小化」「TTE:エスカレーションとアサインの自動化」**は現状、課題感が強く、改善の伸び代も大きいのでは考えています。そして、その解決策の一つとしてSREのプラクティスを取り入れていこうと考えています。
またSREの取り組みは、**「SREの探求」[15]**の以下の記述があるように、データ駆動なアプローチを目指す上で、非常に相性の良い取り組みであると思います。
ここでのポイントは、組織は事実とデータによって動く場合のみ、SREと親和性がある点を意識することです。
....エンジニアリングの問題に感情論で反応する組織は、SREを導入する準備ができていません。
....SREは、ハードサイエンスのような事実に基づくアプローチを拠り所としています。
SLOは、Datadogを用いて管理していく予定ですが、いまいち使い勝手が良くはなく、調査・検証を進めています。
SRE勉強会のススメ
サイト信頼性エンジニアリング(SRE)の本格導入にあたり、SRE自体が概念として難しいため、メンバー間の認識も合わせ、より理解を深めるため、以下のコンテンツを使い、社内で勉強会を行っています。各章ごとに多くの気付きが得られ、おすすめです。
- Google SRE Books [16]
- SREの探求 [15]
おわりに
まだ取り組みとしては道半ばで、改善の余地が多々あるのですが、逆を言えば、まだ大いに伸び代があると思っています。今度、開発者体験を向上させ、システム開発の質とスピードを高め、プロダクト・事業価値を最大化させるにはどうすればよいか、メンバーと共に、日々模索・奮闘しながら、取り組んでいきたいと思います。
昨日の記事は laura_ko さんの 「READYFOR Updates #3: より簡単にプロジェクトページの準備ができるようになりました」、明日の記事は @t2-kob さんの予定です!
参考
- Scaling Agile Spotify, URI: https://blog.crisp.se/wp-content/uploads/2012/11/SpotifyScaling.pdf
- "ユニコーン企業のひみつ Spotifyで学んだソフトウェアづくりと働き方", https://www.oreilly.co.jp/books/9784873119465/
- "Spotifyは "Spotifyモデル "を使っていない", https://agile.quora.com/Spotify%E3%81%AF-Spotify%E3%83%A2%E3%83%87%E3%83%AB-%E3%82%92%E4%BD%BF%E3%81%A3%E3%81%A6%E3%81%84%E3%81%AA%E3%81%84
- "組織の「乳化」を目指す。職種を超えた連携を生み出す「スクワッド組織」運営とは", https://tech.readyfor.jp/entry/2021/12/08/185152
- "エンジニアリングマネージャ/プロダクトマネージャのための知識体系と読書ガイド", https://qiita.com/hirokidaichi/items/95678bb1cef32629c317
- "エンジニアリング組織論への招待 ~不確実性に向き合う思考と組織のリファクタリング", https://www.amazon.co.jp/dp/4774196053
- "READYFORが目指す「乳化」 への取り組み", https://tech.readyfor.jp/entry/2020/12/01/162301
- "「強いエンジニア組織を作りたい」野望を胸に、READYFORが取り組んだ「組織の乳化」と「スクワッド体制」とは?", https://codezine.jp/article/detail/14021
- "DX Criteria( DX基準 )", https://dxcriteria.cto-a.org/
- "NewsPicksにCTOとして入社して1年でDX Criteriaを大幅改善した話", https://tech.uzabase.com/entry/2021/01/28/190209
- "DX Criteriaの実践とその活用について
", https://tech.pepabo.com/2020/02/19/dx-criteria/ - "LeanとDevOpsの科学", https://www.amazon.co.jp/dp/B07L2R3LTN
- "Pull Requestから社内全チームの開発パフォーマンス指標を可視化し、開発チーム改善に活かそう", https://developer.hatenastaff.com/entry/2021/03/04/093000
- "Insights: Engineering Leader and Organizational DORA Reports", https://github.com/github/roadmap/issues/127
- "SREの探求 ―様々な企業におけるサイトリライアビリティエンジニアリングの導入と実践", https://www.amazon.co.jp/dp/4873119618
- "Google SRE Books", https://sre.google/books/
- "NAVITIME:DX Criteriaを現場で読み合わせしてみた", https://note.com/navitime_tech/n/nb006af03adcf
- "Site Reliability Engineering", https://translate.google.com/translate?hl=&sl=auto&tl=ja&u=https%3A%2F%2Fsre.google%2Fsre-book%2Ftable-of-contents%2F&anno=2&sandbox=1