はじめに
Google Cloudが提供するCourseraのSite Reliability Engineeringコースを修了したので、その備忘録。
受講理由としては、インフラエンジニアとしてはオンプレ〜クラウドと経験してきて、DevOpsもそれなりに携わってきたものの、SREに関してはGoogle本は掻い摘んで読んだりはしてたものの、しっかり学んだことはなかったため、年末年始を利用して学習してみた。という流れ。(ただ、年末年始に全て終えることはできなかったが・・)
また受講と並行して、適宜、**Googleが無償提供するオンライン書籍**を読み進めていった。
- Coursera : Site Reliability Engineering: Measuring and Managing Reliability by Google Cloud
- Google SRE Books
受講を終えて。
先に受講を終えての所感。
良かった点。
- 全体的に、Google以外の企業でもSREを実践できるように、体系的に学ぶことができる。
- GooglePlayでの実際の運用事例が紹介され、より具体的にイメージしやすい。
- ピアレビューや、理解度チェックの課題があり、インタラクティブに進めら、理解が深まりやすい。
- 最後の修了書(有料)は、何気にモチベーションの維持に繋がる。
SREに関して。
これまで、インフラの構築・運用というと、ユーザーとは一歩引いたところにある感じがあり、信頼性のみ追求して機能開発がおざなりになったり、また逆に、機能開発に注力し信頼性が担保されていない、みたいなケースを過去に経験をしたこともあった。サービスをより良くするという共通目標がある中、そこに線引きされていることに対して、ちょっとした違和感を感じていた。
そのような違和感に対し、SREは、DevOpsにユーザー志向を取り込んだような形で、信頼性も機能開発の一部として捉え、ユーザーの幸福度向上を目指していくスタンスをとっており、その機能開発と信頼性を両立させるための方針・方法論には、とても強い納得感があった。
また、良かった点でも挙げた通り、このコースは、Goolge以外の企業にも実践できるように、体系的にまとめられており、課題やピアレビューなど講義もインタラクティブに進められ、Googleでの具体例など含め、貴重なエッセンスが散りばめられている。エンジニアリングに携わる方であれば、受講して損の無い内容なのではと思う。
その他
- 日本語訳はない(英語・ロシア・スペイン語のみ)
- 無料でも受講可能。修了書を得るためには5000円程度必要。
備忘録
Site Reliability Engineeringコースは、イントロダクション&本編6部構成になっており、
それに沿って、この備忘録も綴っていく。
(留意点として、英語での講座のため誤訳があるかもしれないのと、自分用に五月雨式にメモしているだけで、網羅的に内容整理している訳でないので、そこはご了承ください・・・)
イントロダクション
イントロダクションでは、コース全体の概要と本編6部の説明、そして、SRE/DevOpsの違い、SREに必要性について、述べられている。
● 目次
Site Reliability Engineeringコースは下記6部構成となっている。
-
信頼性の測定と目標:
- ユーザーの満足度を維持するために十分な信頼性を持つことを目指すべき理由の説明。
- サービスの信頼性とユーザーの幸福度の定量化可能な測定基準と信頼できる測定可能な目標定義。
-
信頼性の運用方法:
- どのようにして信頼性のためのバジェットが得られるかの説明。
- 短期および長期的な意思決定のためのエラーバジェットの有用性。
-
良いSLIの選択
- どのような種類のモニタリング・メトリクスが良いサービス・レベル・インジケータになるのか、さまざまな測定戦略の長所と短所についての説明。
- SLI仕様の一般的なタイプ、SLI 仕様の構造化に推奨される方法。
- 細かい粒度の SLI の数と複雑さをより管理しやすいレベルまで減らす方法
-
SLO と SLI を開発する
- SLIとSLOのセットを開発するために使用する4段階のプロセス
- 適切な測定方法、しきい値、および成功基準の選択。
-
SLOに対するリスクの定量化:
- CREのリスク分析スプレッドシートを紹介。
- SLOリスクを見積もり方法の説明。
-
SLO 未達成の結果
- SLOが未達成の場合のSLOと組織内のさまざまな利害関係者の責任。
- 文書化することが不可欠である理由説明。
- エラー・バジェット・ポリシーの作成方法。
● SREとは何か? DevOpsとの違いは?
SREとDevOpsは非常に似ているが、SREの方がよりサービス指向(エンドユーザー指向)である。
- Googleのエンジニアリング担当副社長であるBen Treynor Slossによって造られた用語。
- SREとDevOpsはとても似ている。
- SREの責任は、DevOpsより比較的狭く定義されており、よりサービス指向(エンドユーザー指向)である。
- SREの意思決定は、SLO=サービスレベル目標(Service Level Objectives)に大きく委ねられる。
- クラスSREはインターフェースDevOpsを実装する。ようなイメージ。
class SRE implements DevOps
● CREsとは誰か?
信頼性の三原則。信頼性を決めるのは、モニタリングではなく、ユーザーである。
- CRE = Customer Reliability Engineering
- CRE:信頼性の三原則
- 信頼性が最も重要である。
- 信頼性を決めるのは、モニタリングではなく、ユーザーです。
- よく設計された...
- Software 99.9%
- Operation 99.99%
- Business 99.999%
- ユーザーがあなたのサービスを信頼できないと感じているのであれば、あなたのログやメトリックスが何と言おうと、期待に応えていない。
- 誰もが最初はファイブナイン(99.999%)の信頼性が必要だと思うが、このレベルを達成するには、実際には柔軟性やリリース速度など、システムの他の多くの側面を犠牲にする必要がある。
- 大まかな経験則として、信頼性を10倍にするには、コストも10倍かかる。信頼性を最優先事項としてシステム設計するということは、ビジネスに影響する多くの困難な選択をするということになる。ほとんどの場合、費用対効果の分析では納得できない。
- システムがダウンしているときに、スリーナイン(99.9%)やファイブナイン(99.99%)の意味は何か?逆算してエラーバジェットとするとわかりやすい。
- 3ナイン(99.9%) 40分/4週間
- 4ナイン(99.99%) 40分/4週間
- 5ナイン(99.999%) 40分/4週間
● あなたの組織にとって、なぜSLOsが重要か?
SLOは、共通言語と共通理解を提供し、組織全体で取り組む必要がある。
- 下記課題への対応として、**SLO=サービスレベル目標(Service Level Objectives)**の設定が重要。
- 超信頼性の高いシステムを構築すること可能だが、そうすることで収益を上げることは難しい。
- ほとんどのビジネスでは、ユーザー獲得と収益増加のために新機能を常に求めており、この要求とシステムの信頼性を維持する必要性のバランスをとることは非常に難しい。
- 経営陣やチームへの「信頼性が機能である場合、他の機能と比較してどのように優先順位をつけるか?」という質問は有効である。
- SLOは、組織全体に共通言語と共通理解を提供し、具体的なデータに基づいて信頼性の話ができるようになる必要がある。
- SLOは、運用上の関心事と考えがちだが、エンジニアリングチームと製品チームが連携して目標を設定しなければならない。
- SLOは、ユーザーの望ましい体験を正確に表現していることに、誰もが同意しなければなりません。
- SLOを機能させるためには、経営陣のサポートや開発チームとの連携が必要である。
- プロダクトマネージャーが開発者に要件を指示してコード化し、運用サポートエンジニアに要件を投げつけるようなサイロ化された組織ではSLOの運用は困難である。
- 開発者はサービスの信頼性の責任を共有していると感じ、運用チームは新機能をできるだけ早くユーザーに届けるための責任を感じられるような、所有権を共有する感覚を作り出すことが非常に重要です。
1. 信頼性の測定と目標
● SLOs vs SLAs
SLAはサービス利用者・提供者間の合意事項。SLOはサービス提供者側の目標。
- SLO を設定する際に考慮すべきこと
- 何を誰に約束したいのかを把握すること。
- サービスをより良くするためのメトリクスを見つけ出すこと。
- どの程度の信頼性があれば十分なのかを決定すること。
- 信頼できるサービスの特徴はたくさんある。共有テーマとしては、サービス期待に応えられない場合、それが何であれ、ユーザーはそのサービスを信頼できないものだと認識してしまうこと。
- SLOの目標設定のために幸福度テストが役立つ。
- サービスが目標SLOでパフォーマンスを発揮していれば、平均的なユーザーは満足する。
- 課題は顧客の幸福度を数値化して測定すること。
● どのように信頼性を測定するか?
SLOは適応的で反復的なプロセスである。
- 提供されるサービスのレベルを測定するメトリックをSLI=サービスレベル指標(Service Level Indicators)。
- SLIは、ユーザーエクスペリエンスの定量的な測定値またはメトリック。
- SLIには、
- ex) リクエストレイテンシ
- ex) エラー率(リクエストの総数に対するエラーや成功の割合)
- ex) スループット(1秒間に送信されるデータ量)
- 特定のメトリックを測定するさまざまな方法についてトレードオフについて考える。
- SLIの測定方法を選択する際には、それぞれのアプローチの長所と短所を考える。
- SLIは、良好であったイベントの割合で表されるのが最適である。
- ex) リクエストが正常に処理された割合
- ex) xミリ秒以内に処理されたリクエストの割合
- SLOを決めたら、SLIのパフォーマンスを一定期間にわたって測定する。
- SLO
- ex) 「過去4週間でリクエストの99%が300ミリ秒以内に処理される」
- エッジケースについて
- 単一の SLO に適合しないエッジケースが多く存在する。
- ex) 停電
- ex) ブラックフライデー
- 一時的な戦略で対応する。
- 3ナイン → 4ナイン
- ex) リソースの過剰供給
- ex) 変更凍結の実施
- ex) ウォー・ルームの活用
- レイテンシSLOに複数ターゲットを設定するのは合理的。
- 中央値のユーザーとロングテールのターゲットを設定するのが一般的。
- ユーザーのフィードバックに応じて、SLOを調整する必要もある。
- 単一の SLO に適合しないエッジケースが多く存在する。
- SLOの実施は、適応的で反復的なプロセスである。
- 最初に設定したSLOが一年後に変わっているかもしれない。
- 新しい機能が適切にカバーされていないかもしれない。
- ユーザーの期待がSLOに反映されていないかもしれない。
- 企業のリスク・リターン・プロファイルが変わっているかもしれない。
- 結局のところ、SLOをすべて満たしても、顧客が不満であれば、よくない。
- SLOとSLIの定義は数ヶ月ごとに見直し、6ヶ月から12ヶ月ごとにレビューを行う必要がある。
- 常に、モバイル、デスクトップ、異なる地域など、顧客のすべてのグループを考慮し、それに応じてSLOを修正すること。
- 選択したSLIの詳細やSLOターゲットを定期的に再評価すること。
- 特に運用開始から数ヶ月間は、カバレッジ漏れや、SLOとユーザーの期待値に、若干のズレが生じる可能性がある。
● サービスの信頼性はどうあるべきか?
信頼性の目標設定には、多くのトレードオフを考慮する必要がある。
- サービスを必要以上に信頼性の高いものにしている場合、わずかな信頼性の向上のために、顧客をより幸せにする機能の開発速度を遅くしていることになる。
- 100%の信頼性は、基本的にすべてのものに対して間違った信頼性の目標である。
- ただし、ペースメーカーやABSブレーキのような生命に関わるシステムは別。
- 信頼性の目標を正しく選択するには。
- 野心的でありながら達成可能な目標を設定する。
- 製品、開発、運用の関係者全員が目標に合意する必要がある。
- SLIが目標へのパフォーマンスを測定し、目標を少し超えるようにする必要がある。
- 信頼性が高すぎると、ユーザーがSLIに依存するようになる。
- サービスの可用性とユーザーの幸福度の間には、直線的な関係はない。
- 幸福度テストに合格した後に可用性を高めても見返りは少なくなる。
- 可用性が高くなるほど、提供コストが高くなり、変更や新機能リリースが遅くなる。
- 信頼性を損なう最大のトリガーは設定・バイナリの変更時に発生する。
- 信頼性の向上のために、テストを増やす、リリースの頻度を減らす、手動分析を増やす、などで変更を遅らせる必要がある。
2. 信頼性の運用方法
● エラーバジェット
エラーバジェットは開発者・SRE間の共通のインセンティブに。
- SLOの作成時に、プロダクトチームとエラーバジェットのすべてを使わないことに同意する必要がある。
- エラーバジェットは、過剰に使うべきではありませんが、全く使ってはいけないというわけではない。
- エラーバジェットを使い切らずに開発速度とユーザーの幸福度を維持できる幸せな中間点を見つけたい
- エラーバジェットの維持は、開発者とSREの共通のインセンティブになる。
● 機能と信頼性のトレードオフ
SLOを決める際、サービスの信頼性とエンジニアリング機能のバランスを取る必要がある。
- 信頼性を最大化しようとすると、新機能の開発速度を制限することになる。
- 逆もまた然りで、開発速度を優先することで、サービスの可用性を低下させる危険性がある。
- トレードオフコストは直線的ではなく、前の段階の10倍の労力が必要になる。
- 基本的には、開発・SREの両方チームにインセンティブを与え、エラー予算を超えないようにする。
- 開発・SREとのWin-Winの状況が必要で、それがエラーバジェットのトレードオフとなる。
エラーバジェットが残りわずか or 超過した場合の対応方法。
- 一般的に、新機能プッシュのエラーバジェットがなくなると、チームは信頼性を重視するようになる。
- 残りのエラーバジェットに応じて今後のリリースのペースを変更することができる。
- エラーバジェットが予算を超えた場合の銀の弾丸。
- 上級ステークホルダーがリリースを可能にするトークンを保持しており、トークンの1つをSREに渡すことで対応する。これは、本当に重要なときにだけやるべきのもの。
- トークンの使用は一般的に失敗とみなされ、何が悪かったのか、改善点の見直しに使える。
- ポリシーの例外が定期的に発生している場合、何かが正しく機能していない。
- エラーバジェットの閾値に近づいている場合、エンジニアリングへアプローチを指し示す。
- 計画サイクルでバグ対応の優先度をあげる。
- 自動化されたカナリア分析を実装する。
- モニタリングを改善する。
- 自動化を構築し、手間を減らしたり、排除する。
● サービスをより信頼できるものにするには?
エラーバジェットを超えた場合、信頼性目標達成のために、どのようにサービスを改善すればよいか
- SREチームは、SLO達成するために、開発チームの協力を得て多くのことを行える。
- 障害の影響を受けるのが一部のユーザーのみになるように、徐々に変更を展開する。
- システム内の単一障害ポイントを削除することもできる。
- TTD ( time-to-detect ) ( 検出までの時間 )
- ユーザーに影響が出てから、SREなどの誰かに通知されるまでの時間。
- TTR ( time-to-resolution) ( 解決までの時間 )
- 問題が知らされ、修正し、サービスを回復するまでにかかる時間
- TTF ( time-to-failure )
- 障害がどのくらいの頻度で発生するかの予想されるか。
- ※ これをTBFや故障間の時間と表現されている場合もあるが同じ考え方とのこと。
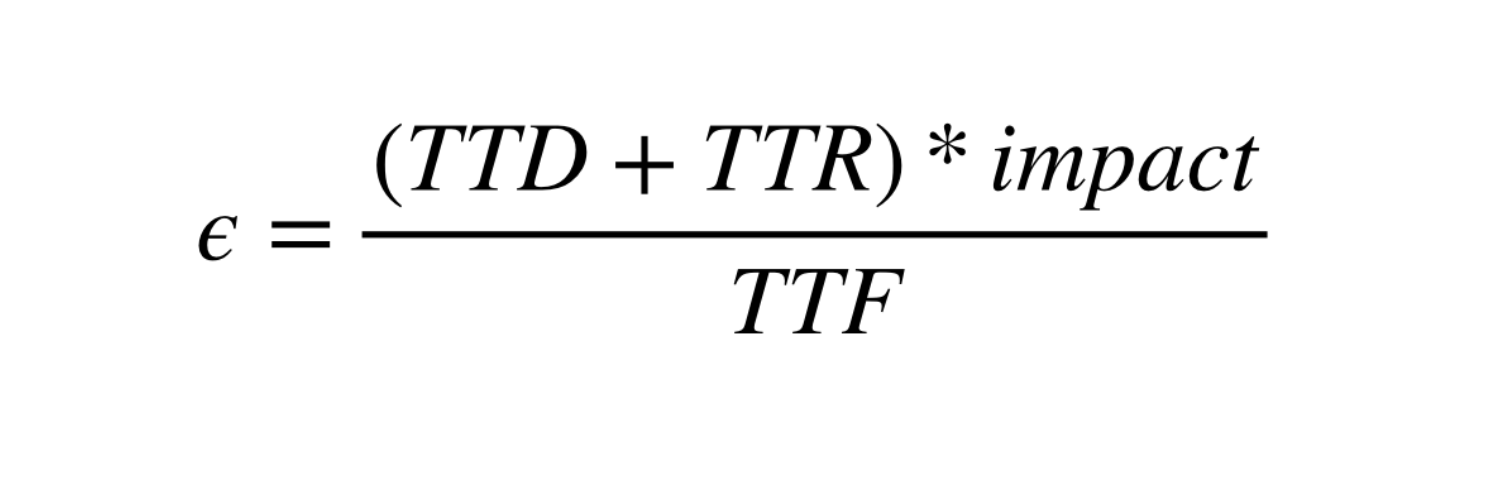
検出時間、解決時間、障害頻度・影響を抑えるには?
- 検出までの時間を短くする。
- 自動アラートの追加。
- SLOのコンプライアンスを測定するためにモニタリング。
- 解決までの時間を短くする。
- プレイブックの開発。
- デバッグログの解析・照合を簡単にする。
- 障害対応者が、ゼロから何をすべきかを考える必要がないようにする。
- 調査中にゾーン排出やトラフィックのリダイレクトなどの手動タスクを自動化する事もできる。
- トラブルシューティングをより迅速かつ容易にする。
- 影響の割合を減らす。
- 段階的なリリース:新機能を 0.1% のユーザーにのみリリースし、次に 1% のユーザーにリリースし、次に 10% のユーザーにリリースするなど。
- 障害発生時にデグレードモード動作するようなサービス設計。
- 例) サービスが読み取り専用の操作を許可し、書き込みを許可しないようにする、など。
- これらは信頼性を向上させるためにできることのほんの一例である。
信頼性を向上させるには?
- 定期的にワーストカスタマー、ワーストリージョン、または別のカテゴリーについて報告する。
- 目標達成の実現可能性についての意見を提供する。
- システム設計のコンサルティングにより、信頼性設計の問題を早期に発見する。
- 安全なリリース/ロールバックシステムを構築し、プッシュ/ロールバック時のヒューマンエラーを減らす。
- 変更をカナリアにして、サービス全体に影響が出る前に障害を検知して対応する。
3. 良いSLIの選択
SLIを測定する主な5つの方法と、その長所と短所を比較。
- SLIの主な5つの測定方法を理解する。
- 一般的なSLI仕様、適用シナリオ、SLIの特定フォーマット推奨理由を理解する。
- ユーザー・ジャーニーごとのSLI数の制限の理由と、管理可能な数に抑える方法を理解する。
- 向上心のあるSLOと達成可能なSLOを理解し、ビジネスとの関連性維持のために継続的な反復が必要である理由を理解する。
● メトリクスと測定
システム・メトリクスをSLIにするのは良い考えではない。
- SLIが数百個あると、運用が麻痺してしまい、重要なシグナルがノイズの海で失われてしまう。
- 妥当なSLI目標設定の最善の方法は、過去のモニタリングデータから達成可能な目標を知ること。
- データが存在しない場合や、目標から乖離する場合は、繰り返し調整する必要がある。
- 負荷平均、CPU使用率、メモリ使用率、帯域幅などのシステム・メトリクスは、サービス停止に関連しているが、SLIにするのは良い考えではない。
- ユーザーはCPUが100%に設定されているのを直接見ているわけではない。
- ユーザーの幸福度と予測可能な直線的な関係を持っていない。
良いSLIの最も重要な特徴の1つは、ユーザーの幸福度と予測可能な関係を持つ事。
- ユーザーの期待に対してパフォーマンスを直接測定できるようになればなるほど、ユーザーの幸福度の測定値としてSLIがより正確になる。
- SLIは、良好なイベントを有効なイベントで割った2つの数値の比率で表され、0から100パーセントの間の値を与えることがお勧め。
- SLIを適度に長い時間ウィンドウで集計することがお勧め。
- SLIは良いイベントと悪いイベントの明確な定義を提供する必要がある。
- 良いSLIは、閾値を設定が簡単。
- 分散が多く、ユーザー体験との相関性が低い指標は、閾値設定が難しい。
SLI測定のための5つの方法
- Request log
- ◯ サービスにSLOを設定し始めたばかりの場合、リクエストログを遡って処理できる。
- ◯ 過去のパフォーマンスからアイデアを得ることができる。
- ◯ ログにロジックを埋め込み、シンプルなイベントカウンタをして処理できる。
- ◯ ログを抽出し、信頼性の高い処理を行うためには、かなりのエンジニアリング努力が必要。
- × イベントが発生してから SLI で観測されるまでの間に大きなレイテンシがある。
- × アプリケーション・サーバに届かないリクエストは観測できない。
- × 緊急対応のトリガーには適していない。
- Application metrics
- ◯ アプリケーションレベルのメトリクスは簡単に追加できる。
- ◯ ログ処理のような測定レイテンシはない。
- Front-end infra metrics
- ◯ ユーザーに最も近いポイントであり、ほとんどがユーザーのコントロール下にあるため、測定されないリクエストは少なくなる。
- ◯ マルクラウド・プロバイダーは通常、詳細なメトリクスや過去のデータをすぐに利用できるようしている。
- × ロードバランサーはステートレスであるため、セッションを追跡する方法がない。メタデータが正しく設定されているかに頼る。
- Synthetic clients
- Client-side instrumentation
● 一般的に使用されるSLI
- SLIは2つの数値の比率、つまり、良いイベントを有効なイベントで割ったものとして表現されるべき。
- SLIは、0パーセントと100 パーセントの間にあると直感的に理解できる。
- SLO目標とエラー予算のパーセンテージに直接変換することができる。
- アラートロジック エラーバジェット、計算、SLO 分析、およびレポーティングツールは、すべて同じ入力を想定して記述できる。

リクエストレスポンスのインタラクションの信頼性のため、一般的に使用推奨なSLIタイプ
- 可用性SLI
- 推奨仕様は、正常に処理された有効なリクエストの割合。
- 可用性は、リクエストを提供する以外の幅広いシナリオで有用な測定概念である。
- リクエストの成功の定義を考える。
- レイテンシSLI
- リクエストに対応するシステムの待ち時間は、重要な信頼性の尺度である。
- 推奨仕様は、有効なリクエストがある閾値よりも速く提供される割合です。
- どのリクエストが SLI にとって有効なのかを選択する。
- レイテンシを測定の開始・終了タイミングを選択する。
- レイテンシとユーザーの幸福度の関係は線形ではなくS字カーブになる傾向がある。
- レイテンシのしきい値を設定するときに、95%や99%を目標にしてロングテールに照準を合わせるのが一般的。
- レイテンシはデータ処理や非同期のワークキュータスクにおいても同様に重要。
- 品質SLI
- CPUやメモリ使用率など、ユーザーに返されるレスポンスの品質を担保する必要がある場合などに使用。
- 推奨仕様は、品質を低下させずに有効なリクエストが提供された割合。
- 品質SLIでサービスの低下をトレースする必要がある。
ユーザー・ジャーニーの信頼性をトラックするために一般的に利用推奨するSLI種類。
-
フレッシュネスSLI
freshness
- フレッシュネスSLIに提案されている仕様は、しきい値よりも最近更新された有効なデータの割合
- 新しい入力データが生成されると、時間の経過とともに出力の有用性や関連性が低下するのが一般的だが、ユーザーは、システムの出力がそれらの入力に関して最新のものであることを期待する。
- フレッシュネスSLIは、これらの期待値に対するシステムのパフォーマンスを測定し、エンジニアリング上の決定を実行できる。
- データの鮮度を測定するタイミングを定義する必要がある。
- 正確な鮮度測定を行うためには、通常、生成のタイムスタンプを追跡するために処理システムを増強する必要がある。
-
正確性SLI
correctness
- 正確性SLIに提案されている仕様は、正しい出力を生成する有効なデータの割合。
- ユーザーはデータが正しく生成されているか、独自に検証する方法を持っている。
- 継続的に正しさを測定するSLIを持つことは価値あることである。
-
カバレッジSLI
coverage
- カバレッジSLIは、システムでデータを処理する際に、アベイラビリティSLIと同様に機能する。
- データ処理カバレッジSLIの推奨仕様は、正常に処理された有効なデータの割合。
- ほとんどの場合、データ処理中のシステムは、処理を開始したレコードが正常に処理されたかどうかを判断し、成功と失敗のカウントを出力することができるはず。
-
スループットSLI
throughput- スループットSLIのための提案された仕様は、データ処理速度がしきい値よりも速い時間の割合。
- スループットSLIが有効なケースは、(通常はレイテンシSLIが定量化するための最良の方法であるが、)
- ユーザに所定のレベルのスループットを提供することを約束している場合。
- 処理レイテンシの期待が一定ではない場合。
- レイテンシや品質と同様に、スループット・レートは、複数のしきい値が適切である可能性があるスペクトル。
● 複雑さの管理
各ユーザー・ジャーニーをカバーするSLIは1~3個を目標にする。
- システムが複雑になればなるほど守るのは難しくなる。
- 監視メトリクスのすべてが有用なSLIになるわけではない。
- SLIの数が多いほど、運用担当者はサービスについて学び、保守する必要がある。
- SLIの数が多いと、盾するシグナルを発信する可能性が高くなり、解決までの時間が長くなる。
- SLIの測定を開始したら、他の監視システムや観測システムをすべて捨てることを推奨しているわけではない。
- SLIの悪化は何かが間違っていることを示していると考えている。
集計することで複雑さを管理する。
- 同じようなユーザーインタラクションのジャーニーのSLIをまとめることで複雑さを減らすことができる。
- Google Playストアの例では、ストアをブラウズするメタジャーニーの一部として捉えている。
- アベイラビリティとレイテンシーのSLIがある。
- SLI を個別に追跡し、SLOターゲットを個別に設定するのではなく、SLIタイプごとに有効なイベントと良好なイベントをすべて集計して、全体的な閲覧可能性と遅延SLIを取得する。
- コンポーネント・ジャーニーのSLIにトラフィック率や相対的な重要度に基づいた重みを乗算するなど、より複雑な集計戦略をとることで、リスクをある程度軽減できる。
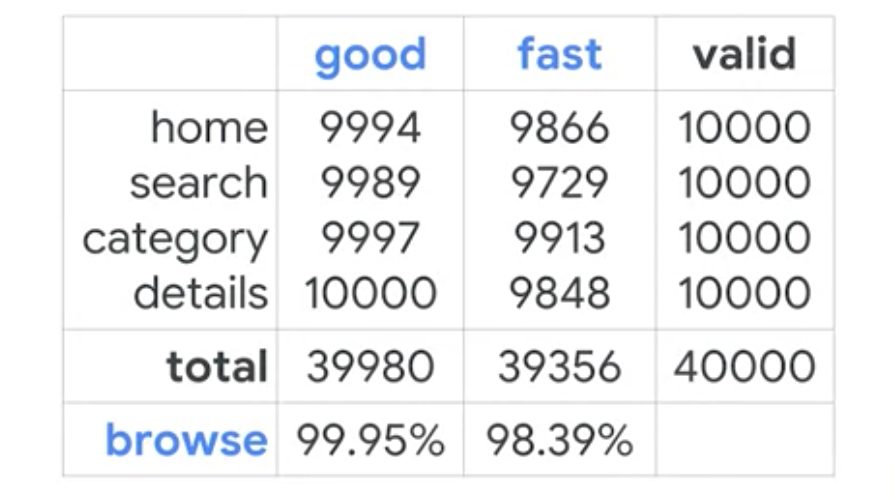
複雑さの原因の一つは、レイテンシ、鮮度、スループット SLOのそれぞれに異なるしきい値を選択することから生じる可能性がある。
- SLOターゲットを設定に「9」を数を用いるように、簡単に認識できるラベルを持もたせるのは良いアイデア。
- レイテンシーのしきい値はおそらく3~5つ以上は必要ない。
- インタラクティブ、ライト、バックグラウンドの3つのバケットで、通常、ほとんどの単純なレイテンシSLIをカバーするのに十分。
- 書き込みは、読み込みとでは異なるレイテンシ特性を持っている。
- ユーザーは送信ボタンをクリックしたときの遅いレスポンスに慣れている傾向がある。
● 信頼性の高い目標設定
Achieveable SLOs(達成可能なSLOs)
- ユーザーの幸福度を直接測定することは不可能であり、信頼性目標が適切な位置にあるかどうかを見極めるのは非常に困難。
- ユーザーがソーシャルメディア上であなたに苦言を呈していないのであれば、彼らが広く幸せであるという前提から始めることができる。
- Googleの格言として、ユーザーの期待は、過去のパフォーマンスと強く結びついている。
- 過去のデータに基づいて設定されたSLOを達成可能なSLOと呼んでいる。
- この目標の欠点は、ユーザーが現在および過去のパフォーマンスに満足していることを前提としていること。
Aspirational SLOs(野心的なSLOs)
- ビジネス要件に基づくSLOをaspirational SLOと呼んでいる。
- 過去のデータがない場合や、サービスがユーザーが満足するよりもはるかに優れている場合、ユーザーに悪影響を与えずに目標を緩和して開発速度を上げることができるかもしれない。それらは達成しようとしているSLOの目標が、ビジネスが必要としているものとは異なる場合になる。
- 過去のデータが全くない場合、潜在的なユーザーを満足させるためには何が必要か、製品チームの最善の推測から始めるのが最善の方法。
- リリース後に、データを収集し、達成可能な目標を設定することができる。
- 妥当な目標を設定し、できるだけ早く測定を開始することは、最初に目標を正確に設定するよりも重要。
継続的な改善
- 理想的には、Aspirational SLOsとAchieveable SLOsが同じ目標数値であること。
- 目標を設定したら、ユーザーベースの幸福度、あるいはより可能性の高い、不満を示すいくつかの外部信号を探してみる。
- 一般的に、サポートチーム、ソーシャルメディア、ユーザーフォーラムを通じて寄せられた苦情の割合は、良い指標となる。
- SLOを見直す時、ユーザーの満足度が低かった時間と、目標に対するパフォーマンスを比較することができる。
- SLO運用初期は、これらのシグナルに対してSLOをより頻繁にチェックするのは良いアイデアである。
- 目標が正しい位置にあると確信を持てるようになれば、目標を見直す頻度を減らすことができる。
- ユーザーベースが劇的に成長するかもしれないし、新しい市場にビジネスが移行するかもれない、継続的な改善は怠らないこと。
4. SLO と SLI を開発する
SLOとSLIを開発するための4段階のプロセス。
- SLIメニューからSLI仕様を選択する。
- SLI仕様を洗練させ、詳細なSLI実装を作成する。
- ユーザー・ジャーニーを確認し、カバレッジギャップを見つける。
- ビジネス要件に基づいた、野心的なSLO目標をセットする。
● Googleの実例ゲームのご紹介
- ( )
● SLIの仕様を絞り込む
- ユーザーの期待に対してサービスのパフォーマンスをどのように測定したいかを、明確に言語化する。
- 例えば、プレイヤーがプロファイル・ページをロードしたときの可用性と遅延を測定したい。
- つまり、ユーザーはプロフィール・ページの読み込みが正常かつ迅速に行われることを期待する。
- 「正常」や「迅速」とは本当に何を意味するのか、疑問を投げかけてみる。
- どのように測定するのか?正確であることが本当に重要である。
- どこで測定するのか、単位を含めて何を測定するのか、基礎となるモニタリング・メトリクスのどのような属性が含まれるのか、または除外されるのかを明確にする。
● SLIはサービスの障害モードをカバーしているか?
可観測性のギャップを探す
-
フロントエンドインフラストラクチャの大きな欠点としては、プロトコルのメタデータにしかアクセスできないこと。そのメタデータがレスポンスの正しい状態を反映していない場合、SLIが嘘をついている可能性がある。
-
ユーザー・ジャーニーを巡り、選択した測定戦略がSLIメトリクスで何を観察しているかを検討しないと、インフラストラクチャに障害が発生したときに、このようなギャップに陥る危険性がある。
-
観測可能性のギャップを埋めるために私が選択した方法は、ロードバランサのメトリクスを、レスポンスボディを検査して検証できるブラックボックスプローバで増強すること。
-
プローバはまた、フロントエンド インフラストラクチャがリクエスト ルーティングで正しいことをしているかどうかを検証し、CDN が正しくコンテンツを提供しているかどうかをテストできる。
-
測定戦略で、SLIメトリクスで何を観察すか検討しないと、インフラストラクチャ障害時にギャップに陥る危険性がある。
-
ユーザーージャーニーを考慮し、インフラストラクチャの障害モードを考えるときの以下の三つの質問に答えようとする。
- SLIはユーザー・ジャーニーとその障害モードを適切に捉えているか?
- 考慮すべき例外やエッジケースはあるか?
- SLI は異なる要件を持つ複数のジャーニーを捉えていますか?
-
すべての故障モードを100%カバーするというのは、またしても間違った目標である。
- 分散システムは複雑で意外な方法で故障するので、100%というのは非現実的な目標であることが多い。
- エラーバジェットの何分の一も食わないほどのレアなものであれば、SLIが障害モードを捕捉しないのは安全であると主張するのが妥当。
- 自分でコントロールできない故障モードや、ユーザーが非難する可能性が低い故障モードは、SLI から除外するのがベストである。
- しかし、それらをある程度観察できることは、まだ価値がある。
- 消費者向け ISP や携帯電話キャリアの障害など。
- サポートチームが障害が発生したことを知っていることが役に立つこともある。
-
何らかの形でコスト・ベネフィット分析行う必要がある。
- クライアント側の詳細な計装をゼロから構築するには、費用がかかる場合がある。
- その代わりに、SLIが特定の障害モードを捕捉していないことを文書化する選択肢もある。
- インフラストラクチャがどのように故障する可能性があるかを分析する必要がある。
-
まとめ。
- 複雑なシステムでのカバレッジ100%は現実的ではない。
- 稀な障害はエラーバジェットから支払う。
- 自身のコントロール外の要因はSLIから除外する。
- コスト・ベネフィット分析は加算されるか。
5. SLOのリスクの定量化
- サービスに対するリスクを列挙したら、エラー・バジェットに対するそれらのコストを推定する。
- 累積コストがSLO目標の全体的な予算よりも大きい場合、リスク防止・緩和のためのエンジニアリング作業に優先順位をつけることができる。
- 誤差予算のごく一部しか消費しないサブクリティカルなリスクは無視することができる。
- サブクリティカルなリスクセット受け入れることで、エンジニアリング努力を最適化できる。
● 信頼性リスク
SLO目標とエラー予算は現実的か?
- (金融の古い格言を借りると、)過去のパフォーマンスは将来の信頼性を示すものではない。
- エラー予算は現実的か?
- 大規模なロングテール・イベントを考慮した場合、数週間や数ヶ月ではなく、数年単位でより長い時間軸を考慮した場合、予算よりも少ない消費量で済むと期待できるか?
- 第二に、誤差予算の最大の原因か?
- もし修正されれば、より少ないエンジニアリング労力でサービスをより高いレベルの可用性を達成できないか?
- 依存関係、サービスインフラ、アプリケーション、およびユーザーの行動について知っていることに基づいて、SLO に対するリスクを列挙する。
- 建設的な悲観論のプラクティスする。
- SREは多くの経験があり、大抵の場合、非常に具体的な潜在的なリスクを思いつくのは簡単である。
- 細部にこだわるよりも、サービング・ゾーンの1つが利用できないというような粒度を考えた方が良い。
- リスクを分類しても、異質なクラスが多数存在することはよくあること。
● リスクの特性化
リスクをモデリングする。
- リストを作成は思考の訓練になる。
- 必要なのは、SLOへの予想される影響に基づいて、リスクリストに優先順位付け。
- リスクを比較可能にするためには、定量化するための共通のメトリックを見つける必要がある。
- 分散型システムのリスクやデータベース破損など、稀なリスクは時間を長くし、平滑化することで、エラー予算を抑える。
- フェルミ推定値は集合体ではほぼ正しいことを覚えておく。
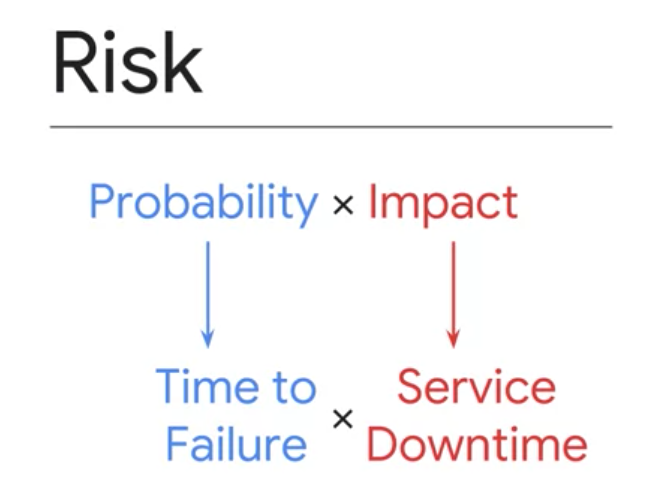
● リスクの分析
- ETTD : Estimated Time To Detection - リスクが発生したことを人(またはロボット)が検知して通知するまでにかかる時間。
- ETTR : Estimated Time To Resolution - 人(またはロボット)が通知を受けてからインシデントを解決するまでにかかる時間。
- ETTF : Estimated Time To Failure - このリスクが発生するまでの推定頻度
- incidents/year : ETTF(日)/365 - このリスクが一年間に発生する回数
- bad mins/year : (ETTD+ETTR) x %impact) x (incidents/year) - このリスクが一年間に発生する推定時間
6. SLOミスの結果
- SLOの文書化が組織での成功に不可欠である理由を理解する。
- SLOを見落とした結果を文書化することが重要な理由と、エラー予算方針とは何かを理解する。
● なぜSLOを文書化する必要があるのか?
- SLOを、ユーザーが不満を持ち始めるであろうラインで線引きする。
- あなたの組織でサービスに従事するすべての人、プロダクトマネージャー、開発者、SRE、および幹部は、そのラインを超えたときに何が起きるは知っておく必要がある。
- SLOの根拠と実装に関するメタデータを記録することは、サービスで作業するすべての人がSLOの失敗による影響を理解し、推論できるようにするために不可欠。
- 新しいSLOは、コミットされるまでに数サイクルの改良が必要になることがよくある。
- そのため、開発中のSLOが測定されているのか、テストされているのか、誰かにメッセージを送っているのかを記録しておく必要がある。
- SLOは時間の経過とともに変化することを意図しており、以前のデータやしきい値や正当化の理由を記録しておくことも非常に便利。
- モニタリングシステムの設定をバージョン管理システムに保存。
SLOダッシュボード
- どのようにしてSLOに関するより良いコンテキストと意思決定するか。
- お勧めする非常に便利なことの1つは、組織のダッシュボードにSLOメタデータを組み込むこと。
- ( SLIとSLOをメタデータと一緒に表示する模擬ダッシュボードの例について )
- SLOメタデータをダッシュボードに直接組み込んで、コンテキストのためにライブSLOグラフと一緒に表示する。
● エラーバジェットポリシーが必要な理由
Fixing chronic reliability issues + inporiving organizational alignment + reducing finger pointing = Happy users
- エラーバジェットと同様に、チームや組織のエラーバジェットポリシーを持つことは重要。
- SLOの中心的な原則の1つは、
- SLOを満たさないとユーザーが不満を持っていることを示し、
- 新しい機能を構築するのではなく、サービスの信頼性にエンジニアリングの時間を投資する必要があることを示すこと。
- 例) 28日間のエラーバジェットが完全に燃え尽きた場合、信頼性の高い作業にエンジニアリング時間を投資するように強制するメカニズムがある。
- 信頼性は機能であることを忘れてはならない。
- ユーザーにとって最も重要な機能である。
- エラーバジェットポリシーは、SLOがサービスの信頼性が十分でない場合、信頼性向上と機能開発をトレードオフすることを、ビジネスがどのように決定するかを説明します。
- このようなポリシーの目的は、サービスの信頼性が脅かされている場合に、組織を意味のある適切な行動に導くこと。
- ポリシーはどこに保管するか?
- エラーバジェットポリシーをSLO設定と一緒にメタデータとして保存すべきかどうかはあまり明確ではないが、
- 広くて高レベルのどこかに文書化しておくのがベストだろう。
- ポリシーは、ほとんどの場合、組織全体の多くのサービスに適用される。
- ポリシーを単一のサービスに結びつけても意味がないかもしれない。
- 文書化されたポリシーの良いところは、大規模な障害が発生する前に、その内容についての議論ができる。
● エラーバジェットポリシーの書き方
エラー予算ポリシーの基本について
- エラー予算方針の七つの考慮事項
- 信頼性を向上させるためのエンジニアリングの結果
- これがいつ発生したかの説明
- どのようにしてこのようなことが起こるかの説明
- このようなことが起こらないようにするための結論を含む
- 一貫して適用させる
- 意見の相違を誰にエスカレートさせるかを文書化
- すべての関係者が合意し、署名すること。
- 優れたエラーバジェットポリシーは、開発チームやSREチームに、サービスの信頼性を向上させるための作業や機能の優先順位を再設定する権限を与えるべき。
- エラーバジェットポリシーは、いつ発効するかを明確にしておく必要がある。
- 重要なのは、エラー予算ポリシーがどの時点で有効になるのかを明確にすること。
- 効果的なエラーバジェットポリシーには、開発チームとSREチームがどのように信頼性機能を優先させるかの詳細が記載されている。
- 多くの場合、これはエラーバジェットの見逃しの深刻度と関連している。
- エラーバジェットの枯渇が続いている場合、開発者とSREチーム全体が信頼性の高い機能のみに取り組むという方針も考えらる。
- また、信頼性の高い作業が行われていない場合の結果についても方針に含めるべきである。
- ポリシーに本当の意味を持たせるためには、SL0を達成できなかった場合に、意味のある結果を出す必要がある。
- 信頼性を犠牲にして機能のみに焦点を当てている開発チームは、ユーザーのために最善のことをしていない。
- Googleはコードイエローと呼ばれる本番問題の修正を優先するための緊急プロトコルを持っている。
- 年に一度か二度、サービスがSL0から外れていても、開発チームが機能をプッシュし続けることができるように、少数の銀の弾丸についての議論の余地はあり。
- 銀の弾丸は常に、銀の弾丸は常に、なぜ必要だったのかに焦点を当てた事後検分が続くべき。
- エンジニアやプロダクトマネージャーはあくまでも人間で、チーム間の意見の相違が生じることはほぼ避けられない。
- 意思決定者が誰であるかについても、ポリシーを明確にしておく必要がある。
- ポリシーがエスカレートした場合には、そのポリシーを支持し、その結果を強制する必要がある。
- ポリシーには、このような状況における意思決定者の名前が記載されていることを確認する。
- ポリシーの最も重要な部分は、その内容ではなく、すべての関係者、プロダクトマネージャ、開発者、SRE、および幹部が知っていること。
- ポリシーについて知っていて、それに従うことに同意していること。
- 一度も同意したことのないポリシーを遵守させるのは難しいことである。
● エラーバジェットポリシー例
( Googleの実際のSRE チームから取得した SLO ポリシーのしきい値 )