概要
概要
下記のイベントレポートを読んで、メルカリの荒瀬さんの発表中の画像データの特徴ベクトルの足し算引き算がおもしろかったので実験
メルカリ・ヤフー・ZOZO開発者が語る「画像検索」の最前線! Bonfire Data & Science #1 イベントレポート
メルカリにおける写真検索機能(スライド)
Closing the Gap Between Query and Database through Query
Feature Transformation in C2C e-Commerce Visual Search(論文)
特徴変換の概念図(スライドより引用)

実験概要
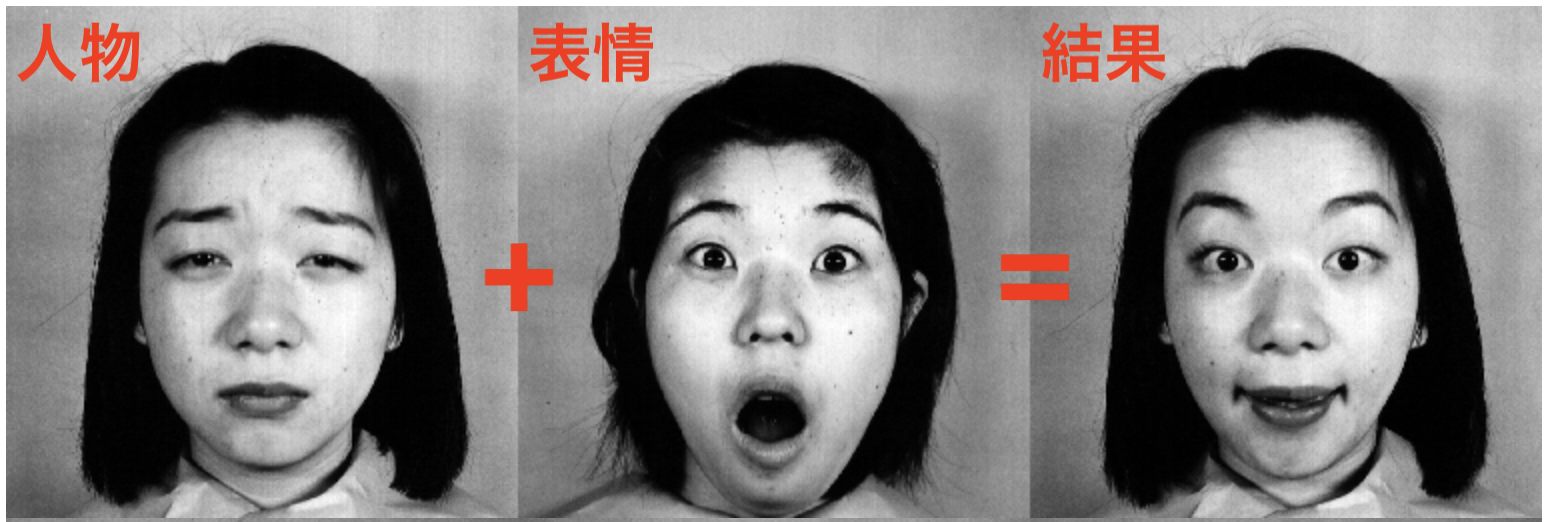
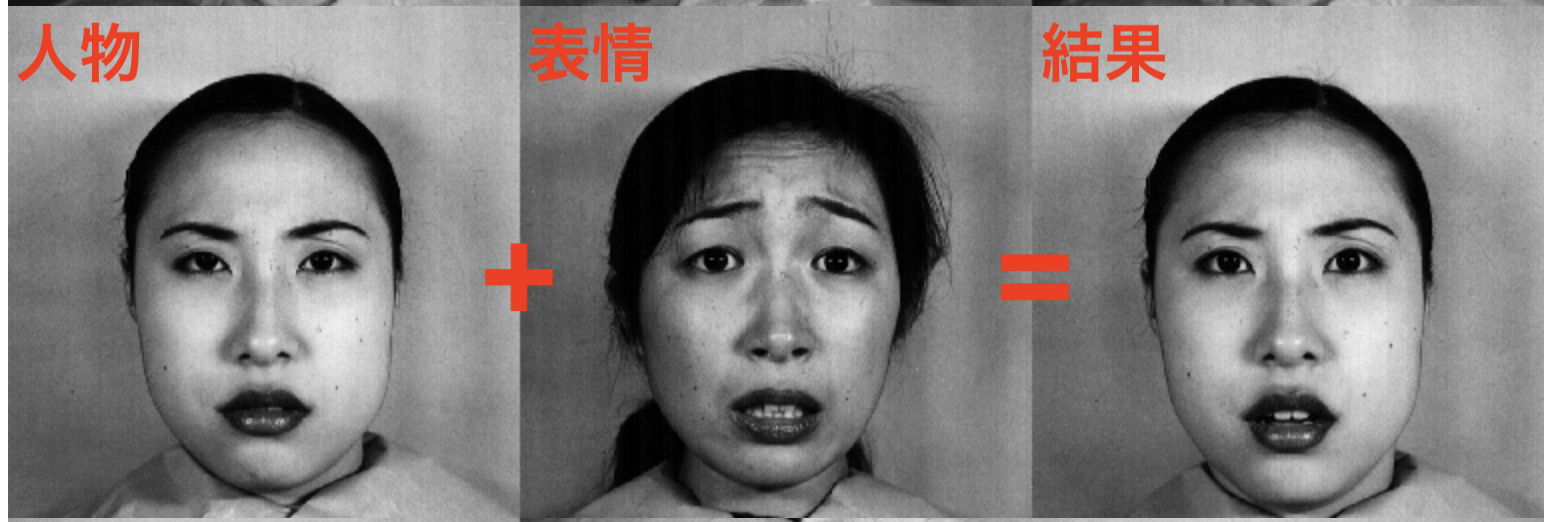
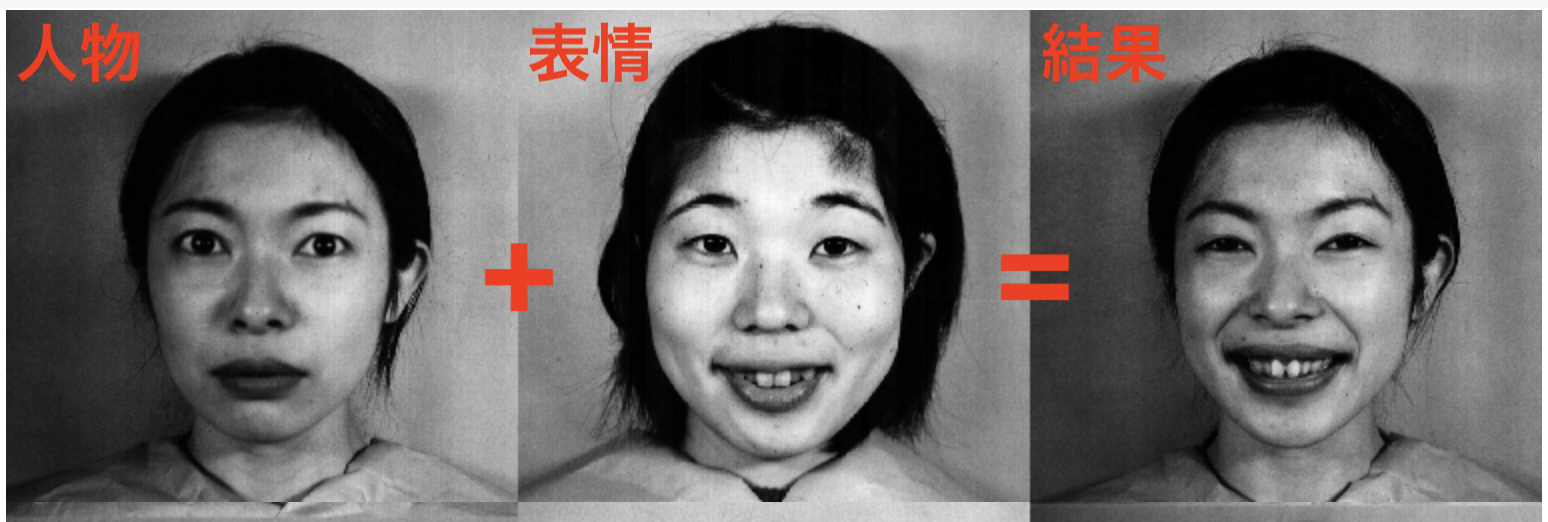
複数人物の表情が含まれるの画像データセットを用いて、
人物 + 表情 = (人物, 表情)
の計算が可能かを実験する。
データ
The Japanese Female Facial Expression (JAFFE) Database
Coding Facial Expressions with Gabor Wavelets(論文)

女性10人の表情7つが入ったデータセット。
人物
['KR', 'NM', 'KM', 'NA', 'KA', 'TM', 'UY', 'MK', 'YM', 'KL']
表情
# FEAR(怖れ)、HAPPY(喜び)、SUPRISE(驚き)
# ANGRY(怒り)、NEUTRAL(無表情)、DISGUST(嫌悪)、SADNESS(悲しみ)
['FE', 'HA', 'SU', 'AN', 'NE', 'DI', 'SA']
(KRさん, 怖)、(KRさん、怒)、(KRさん、喜)、(NMさん、怖)、(NMさん、怒)...という特徴ベクトルから、特徴変換の演算によって
KRさんの特徴ベクトル、NMさんの特徴ベクトル、"怖れ"の特徴ベクトル、"怒り"の特徴ベクトルを取り出すのが目標
損失関数
今回は、TripletLossを利用して、
明示的に同一人物・同表情は近く、別人物・別表情は遠くにする学習を行う
-> 画像データが多くあれば、暗黙的にも学習が可能?
Deep Metric Learning の定番⁈ Triplet Lossを徹底解説(解説記事)
class TripletLoss(nn.Module):
def __init__(self, margin=1.0):
super(TripletLoss, self).__init__()
self.margin = margin
def forward(self, x0, x1, x2):
# x0に対して、x1は同じ人物or同じ表情
# x0に対して、x2は異なる人物or異なる表情
# x0とx1のユークリッド距離を計算
d1 = torch.sqrt(torch.sum(torch.pow(x0 - x1, 2), 1))
# x0とx2のユークリッド距離を計算
d2 = torch.sqrt(torch.sum(torch.pow(x0 - x2, 2), 1))
# d1 - d2 < 0 .. つまり、d1 < d2 .. x0とx1(同じもの)は近い、x0とx2(異なるもの)は遠い なら損失は0 -> 現状維持
# d1 - d2 > 0 .. つまり、d1 > d2 .. x0とx1は遠い、x0とx2は近い なら損失が大きくなる -> 最適化される
loss = torch.clamp(d1 - d2 + self.margin, min=0.0)
return torch.sum(loss) / x0.size()[0]
モデル
論文どおり、mobilenet_v2を利用する
import torch.nn as nn
from cnn_finetune import make_model
class Net(nn.Module):
def __init__(self, C):
super(Net, self).__init__()
self.nn = make_model('mobilenet_v2', num_classes=C, pretrained=True, input_size=(256, 256))
def forward(self, X):
return self.nn(X)
データローダ
TripletLossを適用するために、同じ人物または同じ表情の画像と、異なる人物または異なる表情の画像の3枚1セットの画像を出力する
%matplotlib inline
import matplotlib.pyplot as plt
from glob import glob
from PIL import Image
import torch
from torchvision import transforms
import numpy as np
import pandas as pd
class FaceDataset(torch.utils.data.Dataset):
def __init__(self, files, transform):
self.transform = transform
self.df = pd.DataFrame({
# ファイル名から人物と表情のラベルを取り出す
# 人物のラベル 例) KM.HA1.4.tiff -> KM
'name': list(map(lambda x: x.split('/')[-1].split('.')[0], files)),
# 表情のラベル 例) KM.HA1.4.tiff -> HA
'face': list(map(lambda x: x.split('/')[-1].split('.')[1][:-1], files)),
# ファイル名
'path': files
})
# 同じ人物表情について重複があるので、ユニークにする。
self.df = self.df.groupby(['face', 'name']).head(1)
def __len__(self):
# データの長さ
return len(self.df.index)
def __getitem__(self, idx):
# idxの位置のデータ行を取り出す
row = self.df.iloc[idx]
# ファイルパス
path = row['path']
# ファイルパスから画像データを読み取り
img = self.open_image(path)
# 今回は明示的に人物と表情の距離を分ける
# 50:50の確率で人物と表情の組み合わせとで学習を分ける
if np.random.random() < 0.5:
# 人物
# 人物名を取り出す
name = row['name']
# 同じ人物の別表情画像
path_same = self.df.pipe(lambda df: df[df['name'] == name]).sample(1)['path'].tolist()[0]
img_same = self.open_image(path_same)
# 別人物の画像
path_other = self.df.pipe(lambda df: df[df['name'] != name]).sample(1)['path'].tolist()[0]
img_other = self.open_image(path_other)
else:
# 表情
# 表情名を取り出す
face = row['face']
# 同じ表情の別人物画像
path_same = self.df.pipe(lambda df: df[df['face'] == face]).sample(1)['path'].tolist()[0]
img_same = self.open_image(path_same)
# 異なる表情の画像
path_other = self.df.pipe(lambda df: df[df['face'] != face]).sample(1)['path'].tolist()[0]
img_other = self.open_image(path_other)
# 個々の画像についてtransformで画像を変形して結果を返す
return self.transform(img), self.transform(img_same), self.transform(img_other), path
def open_image(self, path):
return Image.open(path).convert('RGB')
# 画像を変形する処理
transform = transforms.Compose([
# ランダムにサイズ変更
transforms.RandomResizedCrop((256, 256), scale=(0.75, 1.0)),
# ランダムに色合いを変更
transforms.ColorJitter(brightness=0.3, contrast=0.5, saturation=0.5, hue=0),
# ランダムに水平反転
transforms.RandomHorizontalFlip(0.5),
# ランダムにアフィン・シーア変換
transforms.RandomAffine(0.5, shear=0.5),
# pytorchテンソルに変換
transforms.ToTensor()
])
# wget https://zenodo.org/record/3451524/files/jaffedbase.zip
# unzip jaffedbase.zip
# データセットの画像ファイルを読み込み
files = glob('jaffedbase/*.tiff')
dataset = FaceDataset(files, transform)
dataloader = torch.utils.data.DataLoader(dataset, batch_size=16, shuffle=True)
# 出力の確認
def plot(X):
plt.imshow(np.transpose(X, (1, 2, 0)))
plt.show()
for X0, _, _, path in dataloader:
plot(X0[0].numpy())
break
学習
import torch.optim as optim
import torch.nn.functional as F
from sklearn.metrics import confusion_matrix
# Cは任意の数、今回は人物・表情のパターン分とする
C = dataset.df['face'].nunique() * dataset.df['name'].nunique()
# cpu/cudaを指定
device = torch.device('cuda')
# モデルを生成
model = Net(C)
model = model.to(device)
# 損失関数
criterion = TripletLoss()
# 最適化関数
optimizer = optim.Adam(model.parameters(), lr=0.0001)
EPOCH = 50
for idx in range(EPOCH):
model.train()
all_loss = 0.0
for X0, X1, X2, path in dataloader:
# テンソルの型をdeviceに合わせて変換
X0 = X0.to(device)
X1 = X1.to(device)
X2 = X2.to(device)
# 損失計算
loss = criterion(model(X0), model(X1), model(X2))
# 勾配計算・学習
optimizer.zero_grad()
loss.backward()
optimizer.step()
all_loss += loss.item()
print(all_loss)
近傍探索
特徴変換
論文中ではL2ノルムが1の非負のベクトルで演算を行っているので、
それに習い、ベクトル変換を行うメソッドを用意する
def norm(ary):
# 非負ベクトルに変換する
func = lambda x: (x - x.min()) / x.max()
if len(ary.shape) > 1:
return np.array([func(row) for row in np.array(ary)])
else:
return func(np.array(ary))
def l2norm(ary):
# ベクトルをベクトルのL2ノルム(ユークリッド距離)で割ることで、ユークリッド距離が1のベクトルに変換する
def underto0(ary):
# 負は0に置き換える
ary[ary < 0] = 0
return ary
func = lambda x: x / np.linalg.norm(x, ord=2)
if len(ary.shape) > 1:
return np.array([func(underto0(row)) for row in np.array(ary)])
else:
return func(underto0(np.array(ary)))
近傍探索
ベクトル同士の距離を高速に測り類似画像を出力するために、近傍探索ツールを利用する。
今回はYahooJapanのNGTを利用する。
NGT
検索対象の特徴ベクトルの作成と保存
import ngtpy
# 評価用の画像は変形を行わない
transform = transforms.Compose([
# 画像を任意のサイズにサイズ変更
transforms.Resize((256, 256)),
# torchのテンソル型に変換
transforms.ToTensor()
])
# 画像変形を行わない評価用のデータセット
eval_dataset = FaceDataset(files, transform)
# バッチサイズは1にして画像を1つずつ取り出す
eval_dataloader = torch.utils.data.DataLoader(eval_dataset, batch_size=1, shuffle=False)
vectors = []
files = []
for X, _, _, path in eval_dataloader:
X = X.to(device)
# mobilenet_v2のGAP層のベクトルを取り出す。その際に、axis=2方向にmedianを行い値をつぶす。
# =>不要かも?
a_vector = np.median(np.median(model.nn._features(X).cpu().tolist(), axis=2), axis=2)[0].tolist()
vectors.append(a_vector)
files.append(path[0])
# L2ノルムが1の非負のベクトルに変換する
features = l2norm(norm(np.array(vectors)))
# 近傍探索ライブラリにベクトルを保管する
dim = features.shape[1]
ngtpy.create("images", dim)
index = ngtpy.Index("images")
index.batch_insert(features)
index.save()
検索クエリ特徴ベクトルの作成
from PIL import Image
import random
class Feature:
# 特徴量を作り出すクラス
def __init__(self, features, df_dataset):
# 非負かつL2ノルム=1に変換済みの特徴ベクトル
self.features = features
# ファイルパスと、人物・表情ラベルがついたpandasデータフレーム
# => データローダのを使う
self.df_dataset = df_dataset
self.files = df_dataset['path']
def get_feature_face(self, face):
# 指定した表情の特徴ベクトルを取り出す。
if face in self.df_dataset['face'].unique():
# 指定された表情の特徴ベクトルだけをフィルタリングで取り出す。
# 特徴ベクトルの中央値を非負L2ノルム1変換をかけたベクトルを、その表情の特徴ベクトルとする
return l2norm(np.median(self.features[self.df_dataset['face'] == face], axis=0))
else:
raise Exception('存在しない表情です:', face)
def get_feature_name(self, name):
# 指定した人物の特徴ベクトルを取り出す。
if name in self.df_dataset['name'].unique():
# 指定された人物の特徴ベクトルだけをフィルタリングで取り出す。
# 特徴ベクトルの中央値を非負L2ノルム1変換をかけたベクトルを、その人物の特徴ベクトルとする
return l2norm(np.median(self.features[self.df_dataset['name'] == name], axis=0))
else:
raise Exception('存在しない名前です:', name)
def plot(self, l_idx):
# 検索結果を表示するためのメソッド
def get_concat_h(im1, im2):
# 画像を横つなぎにする
dst = Image.new('RGB', (im1.width + im2.width, im1.height))
dst.paste(im1, (0, 0))
dst.paste(im2, (im1.width, 0))
return dst
idx = l_idx[0]
img = Image.open(self.files[idx])
for idx in l_idx[1:]:
img = get_concat_h(img, Image.open(self.files[idx]))
display(img)
obj_f = Feature(features, eval_dataset.df.reset_index(drop=True))
NAME = ['KL', 'NM', 'KR', 'KA', 'YM', 'MK', 'UY', 'TM', 'NA', 'KM']
FACE = ['HA', 'NE', 'SU', 'AN', 'FE', 'DI', 'SA']
get_name = lambda x: x.split('/')[-1].split('.')[0]
get_face = lambda x: x.split('/')[-1].split('.')[1][:-1]
N = 100
SUCCESS = 0
for num in range(N):
# ランダムに人物と表情の識別子を取り出す
name = random.choice(NAME)
face = random.choice(FACE)
# 個々の特徴ベクトルを計算する
feature_name = obj_f.get_feature_name(name)
feature_face = obj_f.get_feature_face(face)
# 人物ベクトルと表情ベクトルを足し合わせる
search_x = l2norm(feature_name + feature_face)
# 近傍探索を実施する
# search_xに最も近い特徴ベクトルが取り出される
result = index.search(search_x, 1)
for idx, d in result:
filename = obj_f.files[idx]
if get_face(filename) == face and get_name(filename) == name:
SUCCESS += 1
print('正答率:%f' % SUCCESS / N)
正答率は0.83で、特徴ベクトルを学習できた。