やること
Lineの親会社NAVERのエンジニアが作成したText DetectionのCRAFTを使って、
JetsonNanoのEdge環境でOCRできるか(Recognitionはしていません)を確認します。
CRAFTについて
https://arxiv.org/pdf/1904.01941.pdf
論文をざっくり見たところ、VGG16をベースにしてRegionScoreとAffinityScoreというものを学習、推論していくようです。
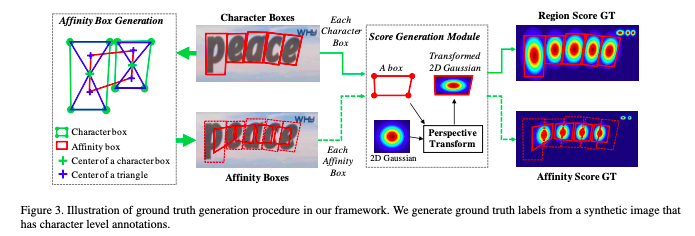
従来の、バウンディングボックスを利用した物体検出からの文字検出とは違い、
CenterNetのようなポイント検出から文字検出をすることで、NMSを飛ばせ比較的早いという利点があるみたいです。
ただ、Scene Text Recognitionの課題である、湾曲したテキストの検知などをするための工夫がされており、
結構後処理に時間がかかりそうな印象を受けました。
環境構築
まずはCRAFTをgithubからダウンロードします。
次にpytorchを入れます。
ちなみに、JetsonNanoにはAnacondaは入らないようです。
wget https://nvidia.box.com/shared/static/phqe92v26cbhqjohwtvxorrwnmrnfx1o.whl -O torch-1.3.0-cp36-cp36m-linux_aarch64.whl
pip3 install numpy torch-1.3.0-cp36-cp36m-linux_aarch64.whl
requirment.txtにpytorchのバージョンが指定されていますが、削除して新しいの入れます。
torchvision==0.2.1
opencv-python==3.4.2.17
scikit-image==0.14.2
scipy==1.1.0
pip3 install -r requirements.txt
scikit-imageインストール中に電源が落ちる現象が起きて、先に進めないので、
Webカメラを外して、下記のコマンドを実行しました。
pip3 install scikit-image==0.14.2 --user
関連ライブラリのバージョンが古いというようなエラーが出たので、pipを新しくします。
pip3 install --upgrade pip setuptools
ImportError: cannot import name mainというエラーが出たので、
下記の記事からpipを再インストール
hash -r
JetsonNanoあるあるかと思いますが、
その辺にある電源アダプター(5V、2.5A)で給電していて、突然電源が落ちることがありました。
電力が足りてない?のか、とりあえず、電力を使ってそうなWebカメラを外して先に進めましたが、
5V、4Aの電源アダプターを用意できればいいという話もあります。
Githubから、Model NameがGeneralのモデルをダウンロードして、作業ディレクトリに配置します。
GPUを使う
python3 test.py --trained_model=craft_mlt_25k.pth --test_folder=./data
バウンディングボックス付きとマスクの画像と、物体位置が書かれたテキストファイルが出力されます。


数字とカタカナを認識してくれてます。
認識にかかった時間:12秒くらい
GPU使わない
python3 test.py --trained_model=craft_mlt_25k.pth --test_folder=./data --cuda=False
認識にかかった時間:111秒くらい
まとめ
Webカメラを使ってガンガン認識する感じで試したかったのですが、JetsonNanoだと厳しいみたいです。
MACのGPUなしで実行した場合に、2.5秒くらいで認識したのでいい感じに動くかと思ったのですが、
Edgeはスペック上がり待ちになりそうです。
Recognitionは同じくclovaaiチームのリポジトリがありますが、
日本語認識のモデルが現状なさそうなので、自分でトレーニングしろってことだと思います。
CRAFTのモデルのトレーニングは提供されていませんが、
Recognitionの方はトレーニング方法が書かれています。
いつか自作の日本語認識OCRを作りたいと思います。