概要
Adversarial Validationとは、学習データとテストデータが大きく異なる場合、
学習データをそのまま使ってもいい検証結果が得られないから、
テストデータに似た学習データを作ろうという手法みたいです。
元ネタ
http://fastml.com/adversarial-validation-part-one/
http://fastml.com/adversarial-validation-part-two/
手順
取り込んだ学習データとテストデータが判別できるラベルを追加します。
train = pd.DataFrame({'A': [1,2,3,4,5,6,7,8,9,10]})
test = pd.DataFrame({'A': [100,200,300,400,3,1,200]})
train['TARGET'] = 1
test['TARGET'] = 0
学習データとテストデータをくっつけます。
data = pd.concat(( train, test ))
x = data.drop( [ 'TARGET' ], axis = 1 )
y = data.TARGET
データを分割します。
from sklearn.model_selection import train_test_split
num_train = 5
x_train, x_test, y_train, y_test = train_test_split( x, y, train_size = num_train )
作成した、テストデータと検証データで、分類モデルを作成、評価します。
from sklearn.ensemble import RandomForestClassifier
clf = RandomForestClassifier(random_state=0)
clf = clf.fit(x_train, y_train)
yy = clf.predict(x_train)
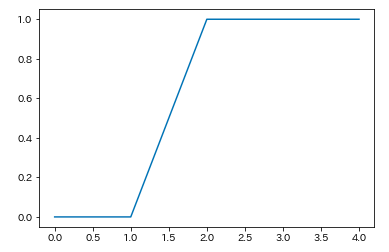
テストデータに似ているスコアでソートします
y_sorted = np.sort(yy, axis=0)
plt.plot(y_sorted)
x_sorted = np.sort(x_train, axis=0)
plt.plot(x_sorted)
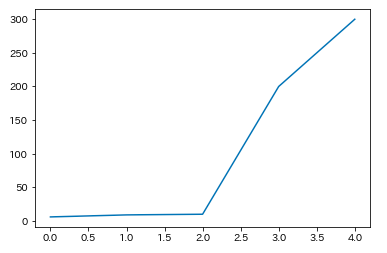
ソートしたデータから60%を学習データとして使用します。
sixty = int(num_train * .6)
sixty = num_train - sixty
thresh = x_sorted[sixty, 0] #このグラフだと200とかになりました
# threshより大きい値を学習データにする
以上、Adversarial Validationの考え方のメモです。
分類モデルはCNNや、他のアルゴリズムでも問題ないです。
KaggleでPublic LBとLocalCVの結果が大幅に違う場合、試してみる価値ありかと。
めっちゃわかりやすい記事ありました!
https://blog.amedama.jp/entry/adversarial-validation