はじめに
コンピュートとストレージの分離とは、データの処理において、データを処理するクエリーエンジン(コンピュート)とデータを保存するストレージを、物理的あるいは論理的に分けるアーキテクチャのことです。
SnowflakeやBigQueryのような主要なクラウドデータウェアハウスサービスで採用されています。
従来のシステムでは、これらの機能が同じハードウェア上で一体化されていました。
コンピュートとストレージを分離することで、それぞれのリソースをより柔軟に利用することができるようになります。
具体的には、データ処理の要求に応じて異なるクエリーエンジンを選択できるようになります。
そのため、例えば処理速度が重要なタスクでは高性能なクエリーエンジンを使用し、速度がそれほど重要でないタスクでは低スペックなクエリーエンジンを選択することで、効率とコストのバランスを最適化できます。
IBMのデータレイクハウスソリューションである「watsonx.data」でも、このアーキテクチャを採用しています。
本記事ではwatsonx.dataでの挙動をご紹介します。
watsonx.dataでのコンピュートとストレージの分離
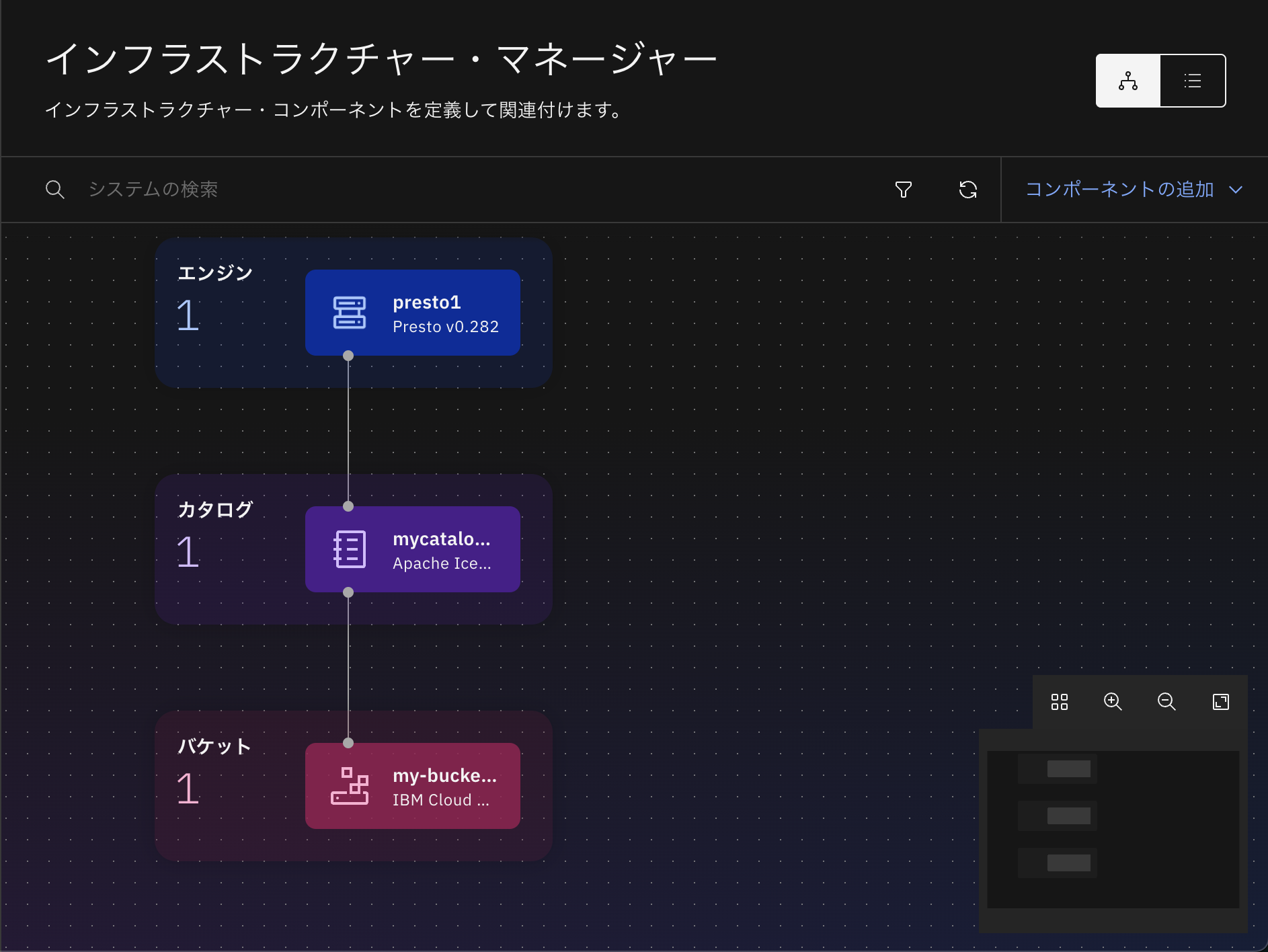
watsonx.dataのアーキテクチャは、下図のように3つの主要な層で構成されています。
- データに対する処理を実行するエンジン
- データの定義(メタデータ)を保持するカタログ
- データの実体を保存するバケット(ストレージ)
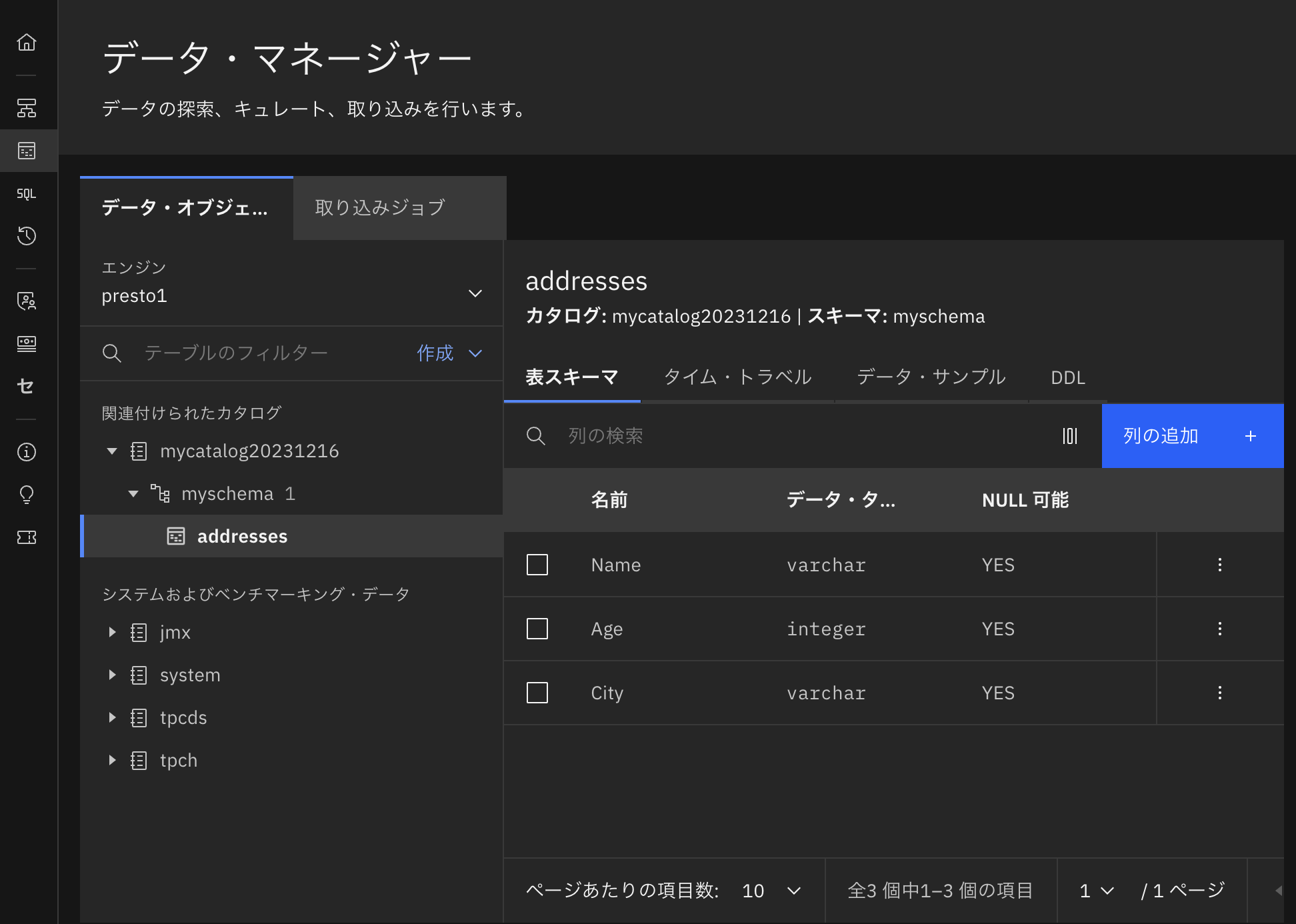
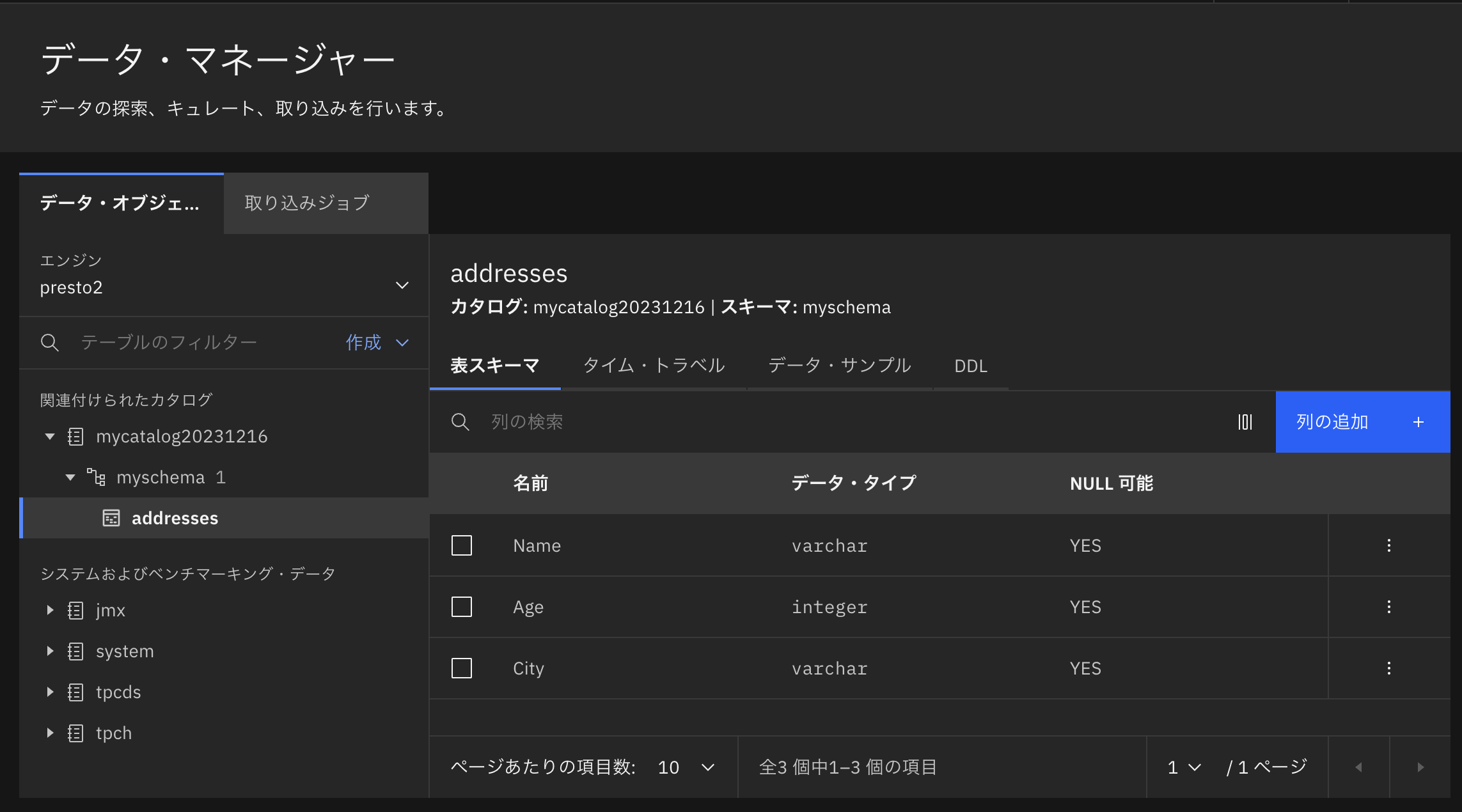
カタログの中にはサンプルデータとして、下図のようにmyschemaスキーマと、3つの列で構成されたaddressesテーブルがあります。
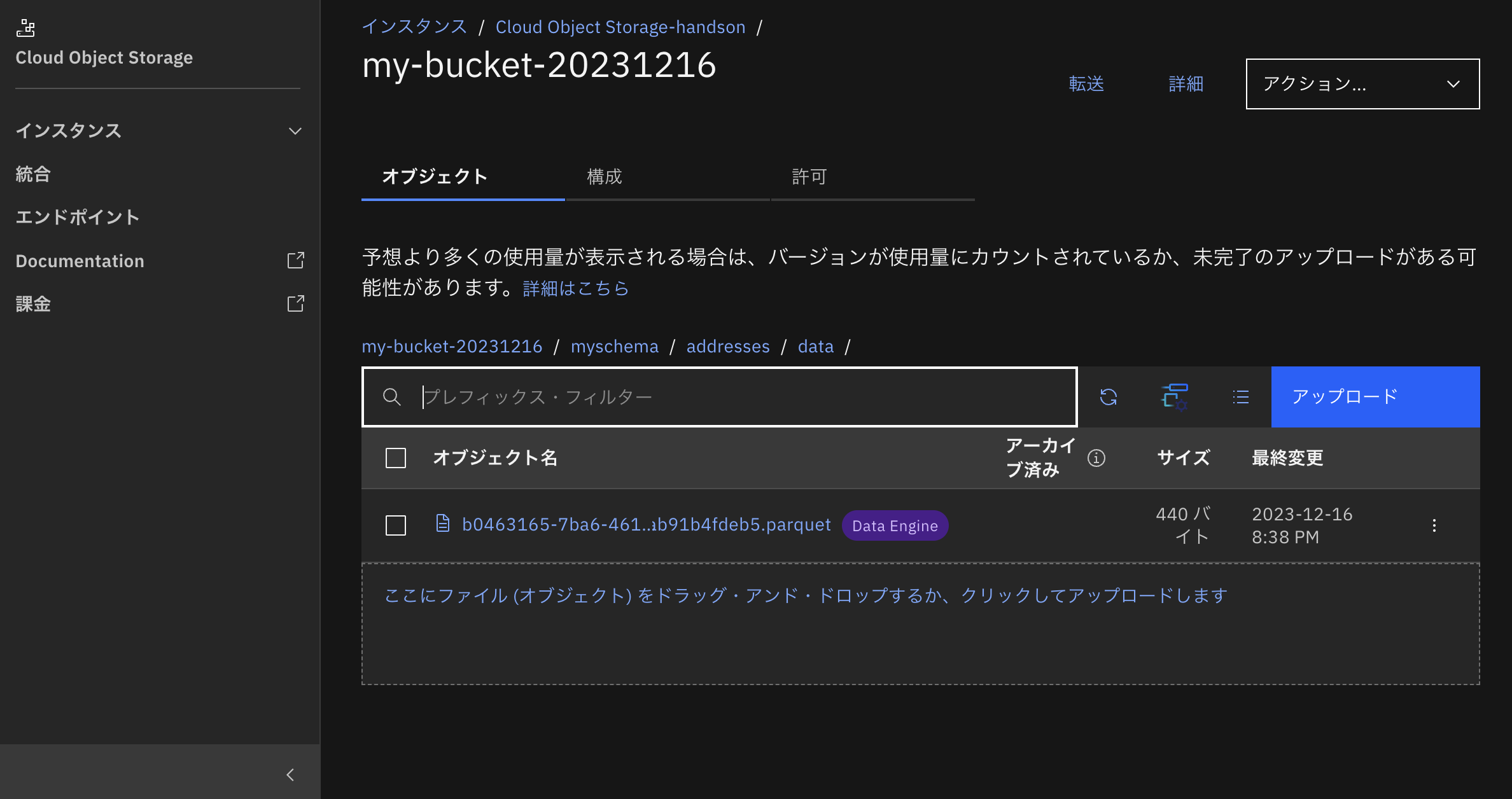
なお、データの実体はバケット(今回はIBM Cloud Object Storage)の中にparquetファイルとして保存されています。
エンジン"presto1"を削除してみます。
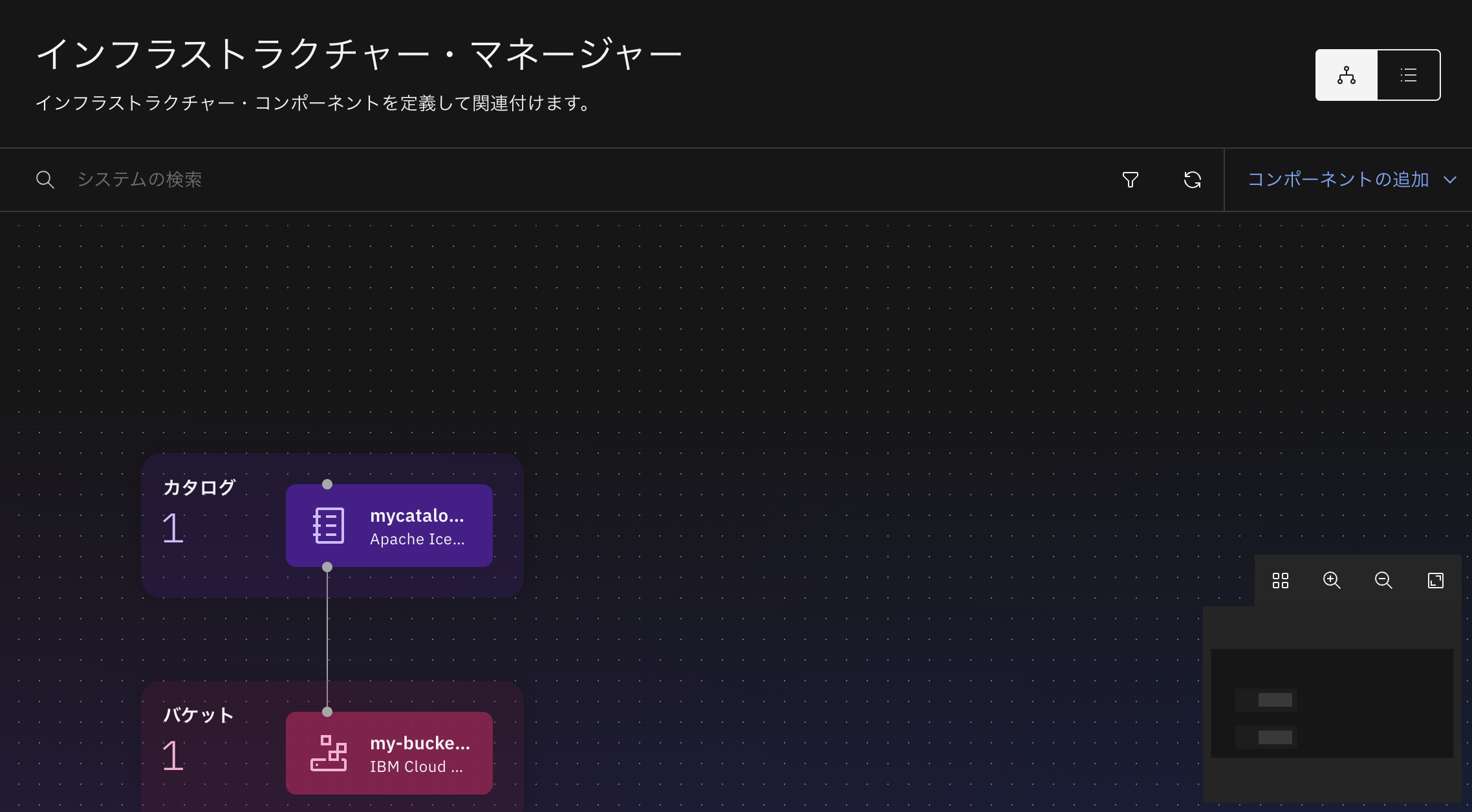
新しいエンジン"presto2"を追加します。
エンジンとカタログ間の接続を示す線を繋げていないことにご注目ください。
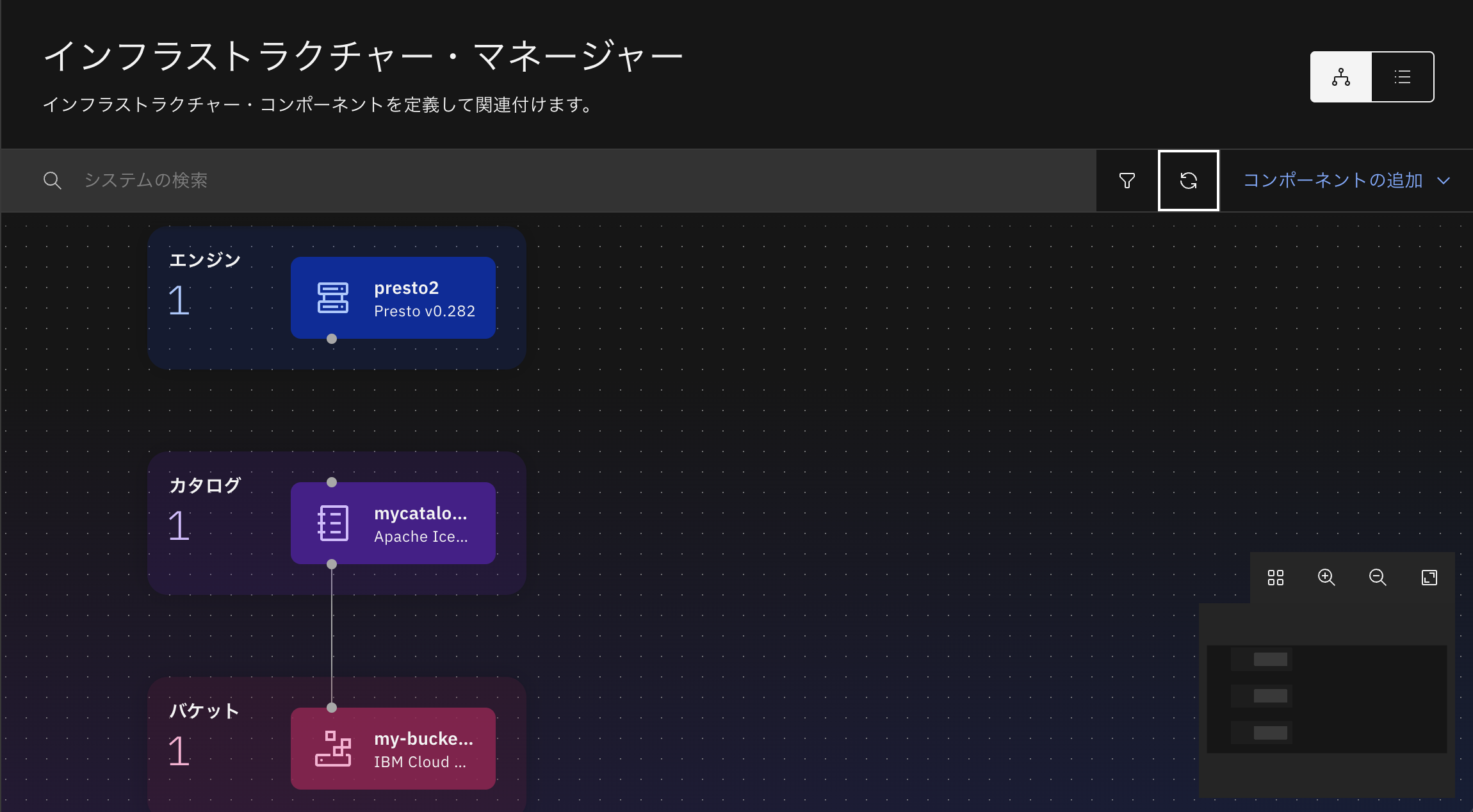
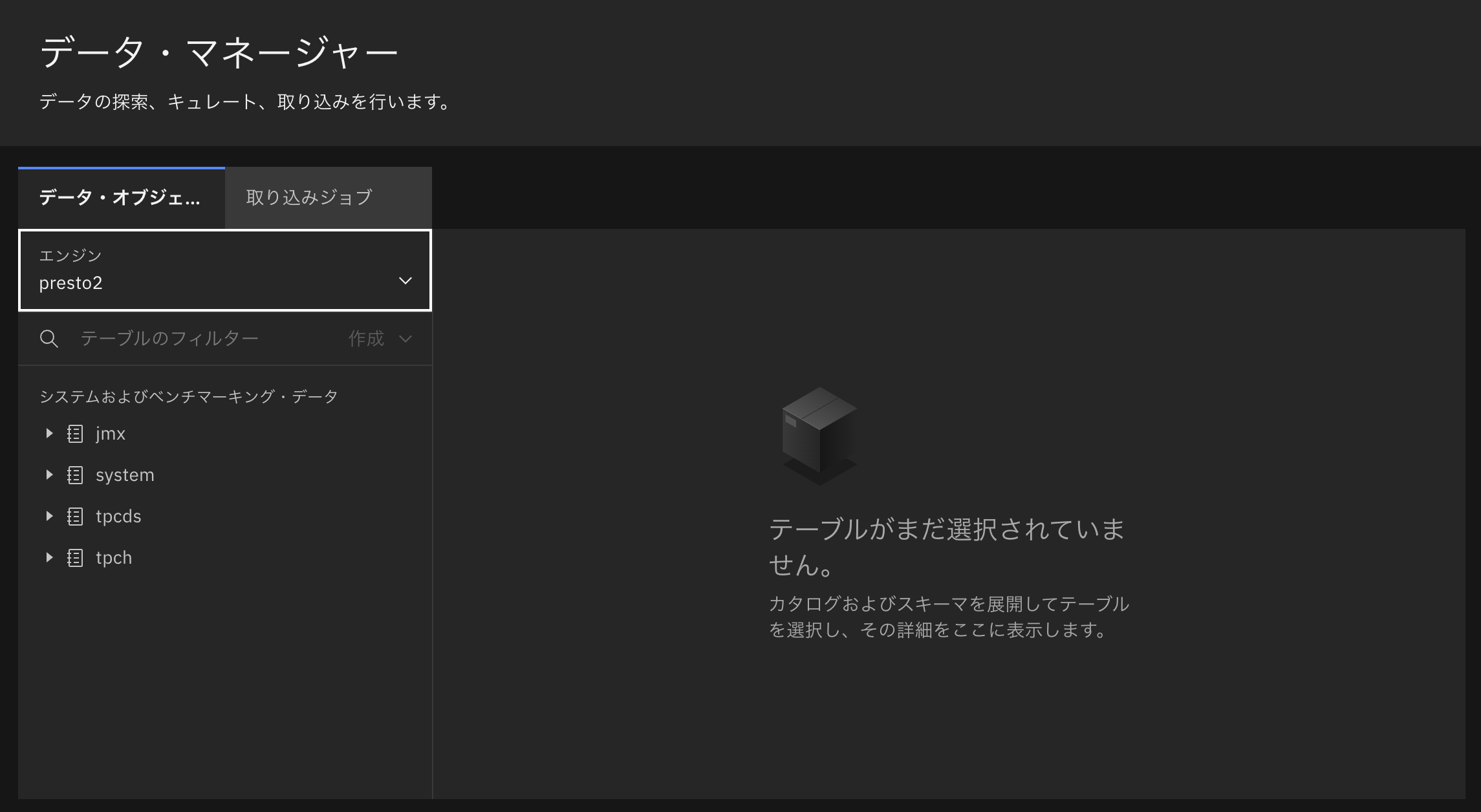
カタログへの接続を行っていないため、データ・マネージャー画面ではまだカタログのデータを参照することができず、空になっています。
エンジン"presto2"をカタログに接続します。
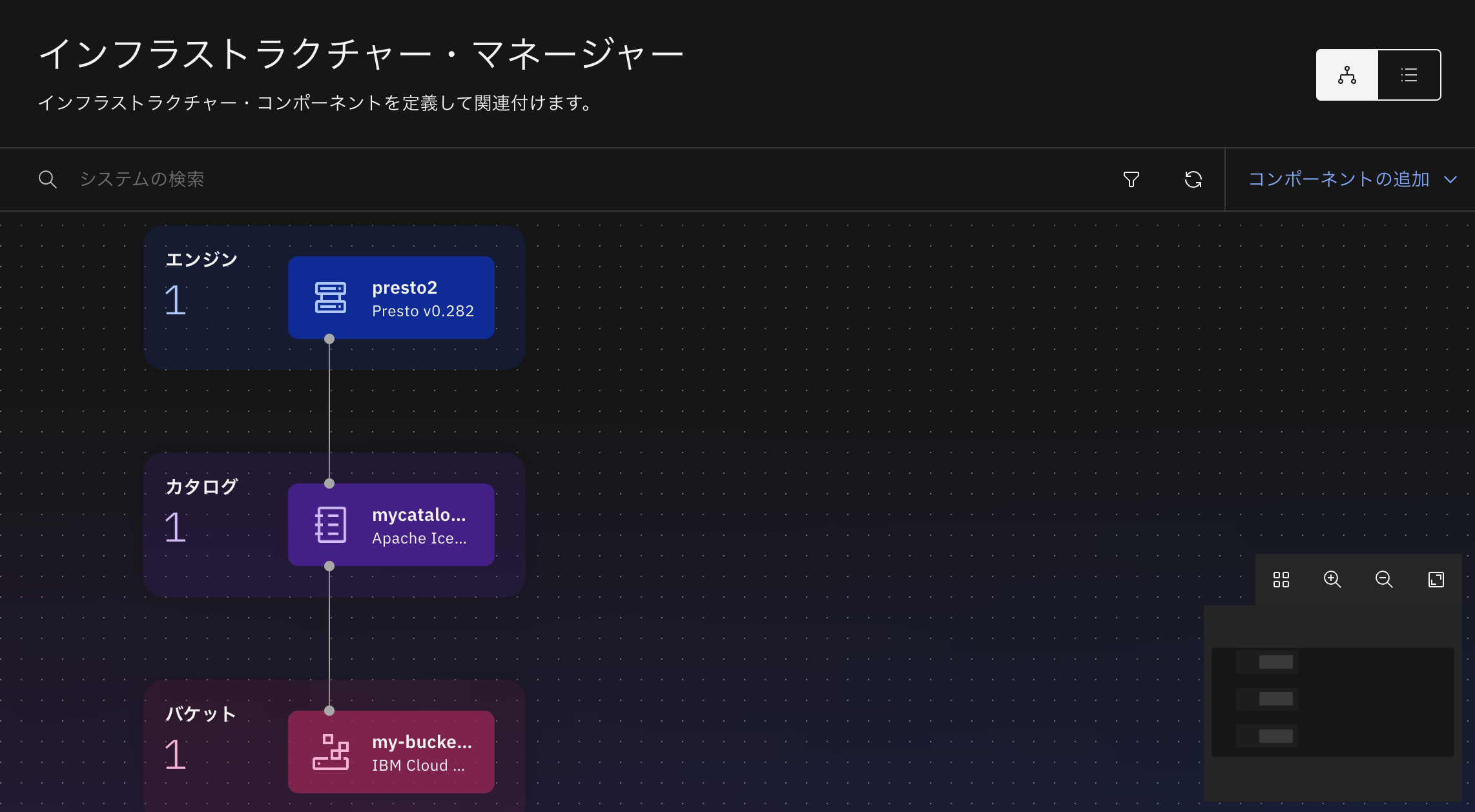
エンジン"presto1"を接続していたときと同様に、エンジン"presto2"でもカタログ内のデータを見ることができるようになりました。
まとめ
このように、watsonx.dataでもコンピュートとストレージの分離により、同じデータに対してエンジンを切り替えることが可能であり、エンジンの柔軟な選択や、処理速度とコストの最適化が実現されます。
さらにwatsonx.data固有の特徴として、PrestoやSparkといった異なる種類のエンジンをサポートすることで、目的に応じたエンジンの使い分けをより柔軟に行うことができるようになります。