はじめに
背景
構築された機械学習モデルの精度向上は最も重要である。精度向上のためには、データから特徴量を選ぶ特徴選択、データに適した機械学習技術の選択、選択した機械学習技術のチューニングが必要である。ただし、近年では機械学習モデルへの説明も求められる側面もある。これらの中でも特徴選択は精度向上に非常に重要である。しかし、一般的に、特徴量の数 n に対して 特徴量の組み合わせは約 2^n となりの現実的には計算困難である。
内容
本ページでは Boruta パッケージを利用して次の内容を検証します。
- 本当に精度が向上されるのか?
- どこまでのデータ量が許容範囲なのか?
本ページの内容のソースコードはランダムフォレストと検定を用いた特徴量選択手法 Borutaを参考にしました。
学術的な背景
-
Feature Selection with the Boruta Package
- 本ページで検証する内容
参考にしたリンク
役立つと思う本
- Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
インストール
import numpy as np
import pandas as pd
import time
from sklearn.datasets import make_classification
from imblearn.ensemble import BalancedRandomForestClassifier
from sklearn.model_selection import StratifiedKFold, cross_validate
from sklearn.metrics import accuracy_score, cohen_kappa_score, balanced_accuracy_score, make_scorer, f1_score, recall_score
from sklearn.ensemble import RandomForestClassifier
from boruta_py import BorutaPy
実験
次の機能を持った関数(my_rf_b_rf)を作成する。
- ベースラインの精度を測定
- 特徴選択前のランダムフォレストを利用して精度を計算する
- Boruta を利用して特徴量を減らす
- 特徴量を減らした data_set_sf を用意する
- data_set_sf を利用して特徴選択後のランダムフォレストの精度を計算する。
以上の三つのタイミングで計算時間を測る。
利用するモデルの定義
def my_rf_b_rf(data_set, target_set,name):
start = time.time()
model = BalancedRandomForestClassifier(random_state = 43,
n_jobs = 1,
n_estimators = 1000,
max_features = "log2",
class_weight = 'balanced',
sampling_strategy = 'all',
max_depth = None,
oob_score=False)
scoring = {'accuracy': make_scorer(accuracy_score),
'kappa': make_scorer(cohen_kappa_score),
'blanced_accuracy': make_scorer(balanced_accuracy_score) }
skf = StratifiedKFold(n_splits=5,shuffle=True,random_state=0)
scores_or = cross_validate(model, data_set, target_set,n_jobs = -1,
cv=skf, return_train_score=True,scoring=scoring)
elapsed_time_or = time.time() - start
#Boruta
feat_selector = BorutaPy(model, n_estimators='auto',perc = 80,max_iter=500,
two_step=False,verbose=2, random_state=42)
feat_selector.fit(data_set,target_set)
data_set_sf = data_set[:,feat_selector.support_]
elapsed_time_b = time.time() - start - elapsed_time_or
model = BalancedRandomForestClassifier(random_state = 43,
n_jobs = 1,
n_estimators = 1000,
max_features = "log2",
class_weight = 'balanced',
sampling_strategy = 'all',
max_depth = None,
oob_score=False)
# Borutaを終えた後のRF
skf = StratifiedKFold(n_splits=5,shuffle=True,random_state=0)
scores = cross_validate(model, data_set_sf, target_set,n_jobs = -1,
cv=skf, return_train_score=True,scoring=scoring)
elapsed_time = time.time() - start - elapsed_time_b - elapsed_time_or
print("RFだけの実行時間:{0}".format(elapsed_time_or) + "[sec]")
print("RFだけの実行時間:{0}".format(elapsed_time_or/60) + "[min.]")
print("RFだけ正解率::{0}".format(scores_or["test_accuracy"].mean()))
print("RFだけKappa::{0}".format(scores_or["test_kappa"].mean()))
print("RFだけバランシング正解率::{0}".format(scores_or["test_blanced_accuracy"].mean()))
print()
print("Borutaだけの実行時間:{0}".format(elapsed_time_b) + "[sec]")
print("Borutaだけの実行時間:{0}".format(elapsed_time_b/60) + "[min.]")
print()
print("Borutaの後のRFの実行時間:{0}".format(elapsed_time) + "[sec]")
print("Borutaの後のRFの実行時間:{0}".format(elapsed_time/60) + "[min.]")
print("RF+Boruta_正解率::{0}".format(scores["test_accuracy"].mean()))
print("RF+Boruta_Kappa::{0}".format(scores["test_kappa"].mean()))
print("RF+Boruta_バランシング正解率::{0}".format(scores["test_blanced_accuracy"].mean()))
return pd.DataFrame({name:[elapsed_time_or,
elapsed_time_or/60,
scores_or["test_accuracy"].mean(),
scores_or["test_kappa"].mean(),
scores_or["test_blanced_accuracy"].mean(),
elapsed_time_b,
elapsed_time_b/60,
elapsed_time,
elapsed_time/60,
scores["test_accuracy"].mean(),
scores["test_kappa"].mean(),
scores["test_blanced_accuracy"].mean()
]},index=["RF実行時間(sec)","RF実行時間(min)",
"RFだけ正解率","RFだけKapp","RFだけバランシング正解率",
"Borutaだけの実行時間","Borutaだけの実行時間",
"Borutaの後のRFの実行時間(sec)","Borutaの後のRFの実行時間(min)",
"RF+Boruta_正解率","RF+Boruta_Kappa","RF+Boruta_バランシング正解率"
])
実験1
- サンプル数1000 は s=1000と表記する
- 特徴量100 は n=100と表記する
- 100の特徴量のうち分類に有効な特徴量10 はi=10と表記する
s=1000;n=100;i=10
data = make_classification(n_samples=s, n_features=n,n_informative=i, weights=[0.7,0.3],n_classes=2,random_state=43)
tmp1 = my_rf_b_rf(data[0],# 特徴量
data[1], # クラスラベル
"s"+str(s)+"_f"+str(n)+"_i"+str(i))
以降細かなプログラムを省略する。s=1000;n=100;i=10の値を変化さえれば、異なるデータセットで実行することができる。
display(tmp.T.sort_values('Borutaの後のRFの実行時間(min)').round(2))
結果
サンプル数、特徴量、有効な特徴量の増加と計算時間
- 計算量増加: サンプル数1000,特徴量100,有効な特徴量10に対して、それぞれの項目が2倍、4倍、8倍、16倍になると、計算時間は3.32倍、17.8倍、75.97倍、482.99倍となる。
- 計算量の比較:RandomForest 単体の最悪の計算時間は約6分に対して、Borutaの計算時間は約333分である。おおよそ、二桁異なる。
- 精度の向上:Borutaの利用により10%程度精度が向上する。

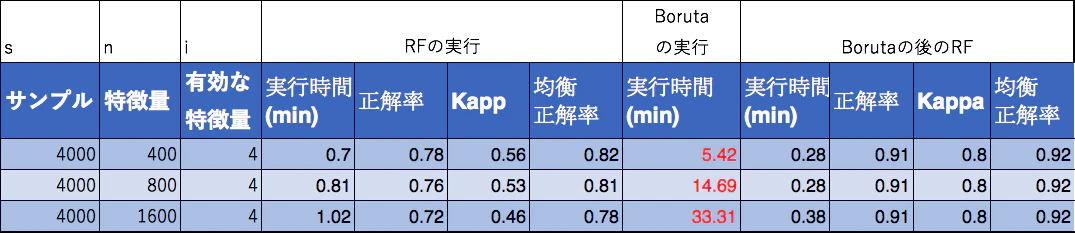
特徴量のみの増加と計算時間の変化
特徴量のみの増加でも計算時間は大きく増加する。
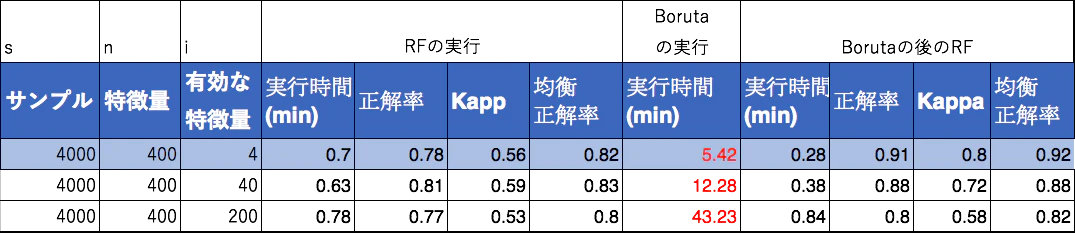
有効な特徴量のみの増加と計算時間の変化
有効な特徴量が増加すればするほど、劇的に計算量が増加する。
個人PCでの動作限界
私のPCでは16000サンプル、4800特徴量、480有効特徴量では20 Iteration が終わるのにおおよそ、14時間程度かかった。500 Iteration 終わるまでに おおよそ14日かかる計算となる。
計測したPCの性能(一般的なPCよりも少し性能が高い)
- MacBook Pro (13-inch, 2017, Two Thunderbolt 3 ports)
- プロセッサ 2.5 GHz Intel Core i7
- メモリ 16 GB 2133 MHz LPDDR3
まとめ
- Borutaは精度の向上には効果的に思える。
- おそらく 1万サンプル、1000から2000までの特徴量、100~200の有効な特徴量では、Borutaは有効に機能すると思われる。
- Borutaは一定以上のデータセットでは計算量が膨大になる
- 有効な特徴変数が多ければ多いほど、計算時間が膨大になる。
- 原文の論文では線形的に計算量が増加すると書かれていたが、メモリなどの制限からどこかで計算量が急激に増加する。
- 大規模なデータでは計算が終わらない。